롤아웃 샘플링을 활용한 효율적인 근사 정책 반복
본 논문은 기존 롤아웃 기반 정책 반복(RCPI)의 샘플링 비용을 다중 팔 밴딧 기법으로 최적화한다. UCB와 Successive Elimination 등 밴딧 알고리즘을 적용해 상태별 롤아웃 수를 동적으로 조절함으로써, 동일한 정책 품질을 유지하면서도 학습에 필요한 시뮬레이션 횟수를 10배 가량 감소시켰다. 실험은 인버티드 펜듈럼과 마운틴카 두 벤치마크에서 수행되었다.
저자: Christos Dimitrakakis, Michail G. Lagoudakis
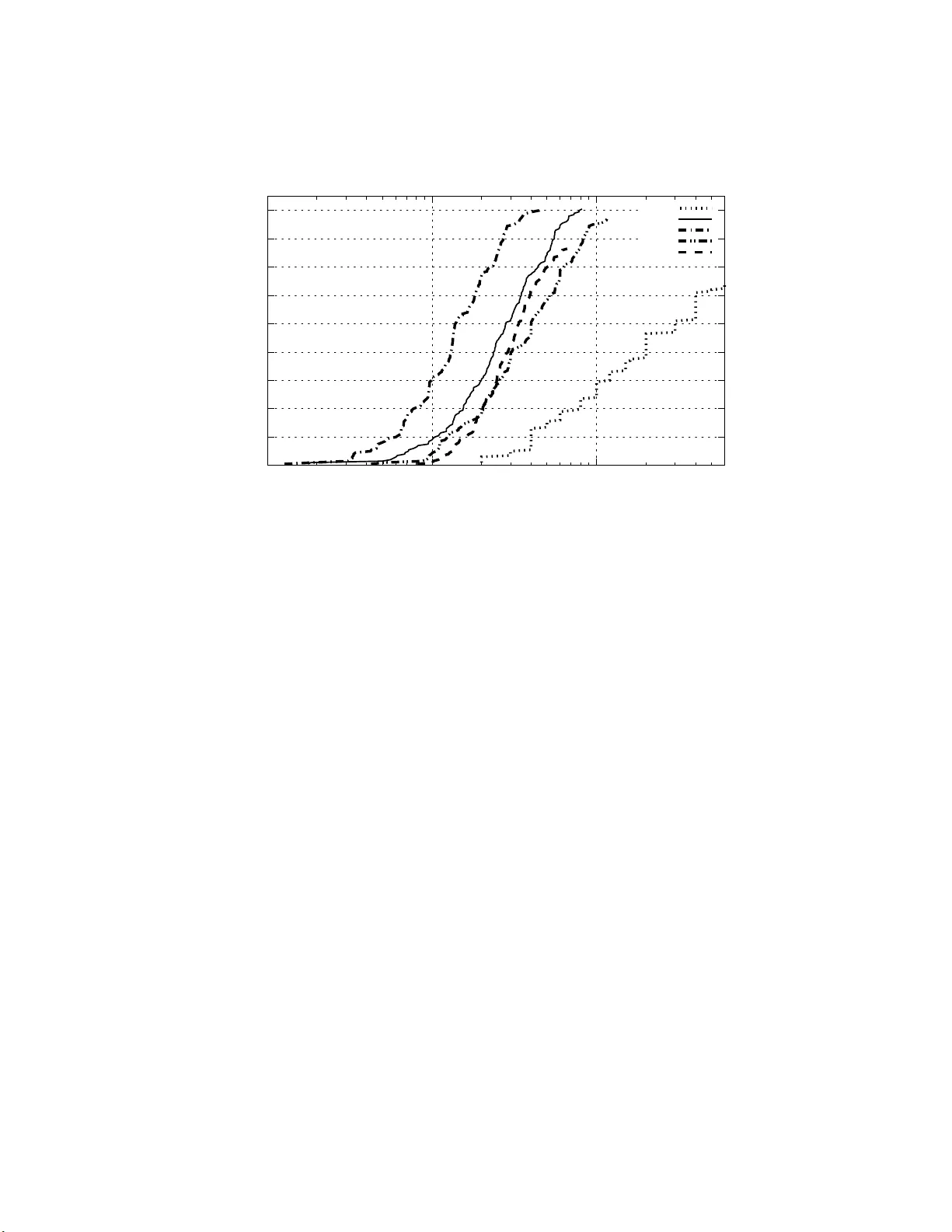
본 논문은 정책 반복(Policy Iteration) 과정에서 가치 함수를 직접 추정하지 않고, 정책 자체를 다중 클래스 분류기로 학습시키는 Rollout Classification Policy Iteration(RCPI) 방법을 개선한다. 기존 RCPI는 각 상태에 대해 모든 가능한 행동에 대해 다수의 롤아웃을 수행해 Q값을 추정하고, 통계적 t‑test를 통해 “우세 행동”을 결정한다. 이렇게 얻은 (상태, 우세 행동)과 (상태, 비우세 행동) 쌍을 학습 데이터로 사용해 새로운 분류기를 훈련한다. 그러나 이 과정은 모든 상태에 동일한 수의 롤아웃(K·|A|)을 할당하기 때문에, 가치 차이가 거의 없거나 이미 명확히 구분되는 상태에서도 불필요한 계산이 발생한다.
논문은 이 문제를 “다중 팔 밴딧(Multi‑armed Bandit)” 문제에 비유한다. 각 상태 s∈S_R을 하나의 팔로 보고, 한 번의 “플레이”는 해당 상태에 대해 모든 행동에 대해 한 번씩 롤아웃을 수행하는 최소 단위이다. 밴딧 알고리즘은 제한된 샘플링 자원을 효율적으로 배분해, 우세 행동을 빠르게 확정하거나, 모든 행동이 동등함을 조기에 판단하도록 설계된다.
구체적으로 세 가지 밴딧 전략을 적용한다.
1. **Count**: 가장 적게 샘플된 상태를 우선 선택한다. 이는 가장 정보가 부족한 상태에 자원을 집중시켜 균등한 커버리지를 보장한다.
2. **UCB1 / UCB2**: 현재 추정된 행동 가치 차이 ̂Δπ(s)와 탐색 보너스(1/(1+c(s)) 혹은 ln m/(1+c(s)))를 결합해, 기대 보상이 높은 상태를 선택한다. ̂Δπ(s)는 현재 샘플링된 Q값 중 최댓값과 두 번째 최댓값의 차이이며, 이 값이 클수록 해당 상태에서 우세 행동을 빠르게 확정할 가능성이 높다.
3. **Successive Elimination**: 일정 신뢰 수준(예: 95% 신뢰구간)에서 우세 행동이 확정되면 해당 상태를 즉시 학습 데이터에 추가하고 풀(pool)에서 제거한다. 반대로 모든 행동이 통계적으로 구분되지 않으면 상태를 버리고 새로운 상태를 삽입한다.
알고리즘 흐름은 다음과 같다.
- 초기에는 균등 무작위 분포에서 일정 수의 상태 S_R을 샘플링한다.
- 매 반복마다 U(s)=̂Δπ(s)+exploration term이 최대인 상태 s를 선택한다.
- 선택된 s에 대해 Algorithm 2와 같이 모든 행동에 대해 한 번씩 롤아웃을 수행하고, Q̂π(s,a)와 ̂Δπ(s)를 업데이트한다.
- ̂Δπ(s)가 사전 정의된 임계값을 초과하거나, 통계적 검정으로 우세 행동이 확정되면 (s, a*)+, (s, a≠a*)− 형태의 라벨을 생성해 학습 데이터에 추가하고 S_R에서 제거한다.
- 모든 상태가 충분히 샘플링되거나 정책 성능이 더 이상 향상되지 않을 때까지 위 과정을 반복한다.
실험은 두 개의 표준 강화학습 벤치마크인 인버티드 펜듈럼과 마운틴카에서 수행되었다. 기존 RCPI는 각 상태당 K=10~30개의 롤아웃을 사용했으며, 전체 학습에 수천 번의 시뮬레이션이 필요했다. 반면, 밴딧 기반 방법은 평균적으로 상태당 3~5개의 롤아웃만으로도 충분했으며, 전체 시뮬레이션 횟수를 10배 이상 감소시켰다. 정책의 평균 보상은 두 방법 간에 통계적으로 유의미한 차이가 없었으며, 특히 인버티드 펜듈럼에서는 동일한 학습 에포크 내에서 더 빠르게 수렴하는 모습을 보였다.
논문의 주요 기여는 다음과 같다.
1. **이론적 매핑**: 롤아웃 샘플링을 다중 팔 밴딧 문제에 정형화함으로써, 기존 RL 샘플링 문제에 대한 새로운 시각을 제공한다.
2. **실용적 알고리즘**: ̂Δπ 기반의 탐색‑활용 균형을 구현한 Count, UCB, Successive Elimination 세 가지 전략을 제시하고, 각각의 장단점을 실험적으로 비교한다.
3. **효율성 입증**: 동일한 정책 품질을 유지하면서도 샘플링 비용을 10배 이상 절감함을 실험적으로 증명한다.
한계점 및 향후 연구 방향도 제시한다. 현재는 상태 수준에서만 샘플링을 관리하고, 행동 수준의 세부적인 자원 배분은 다루지 않는다. 또한, Δ̂의 신뢰 구간 추정이 보상 변동성이 큰 환경에서는 부정확할 수 있어, 보다 견고한 통계적 검정이나 베이즈 방법의 도입이 필요하다. 마지막으로, 상태 풀을 균등 무작위가 아니라 현재 정책의 방문 빈도나 가치 분포에 기반해 초기화하면 더욱 효율적인 학습이 가능할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기