Conditioning Probabilistic Databases
Past research on probabilistic databases has studied the problem of answering queries on a static database. Application scenarios of probabilistic databases however often involve the conditioning of a database using additional information in the form…
Authors: Christoph Koch, Dan Olteanu
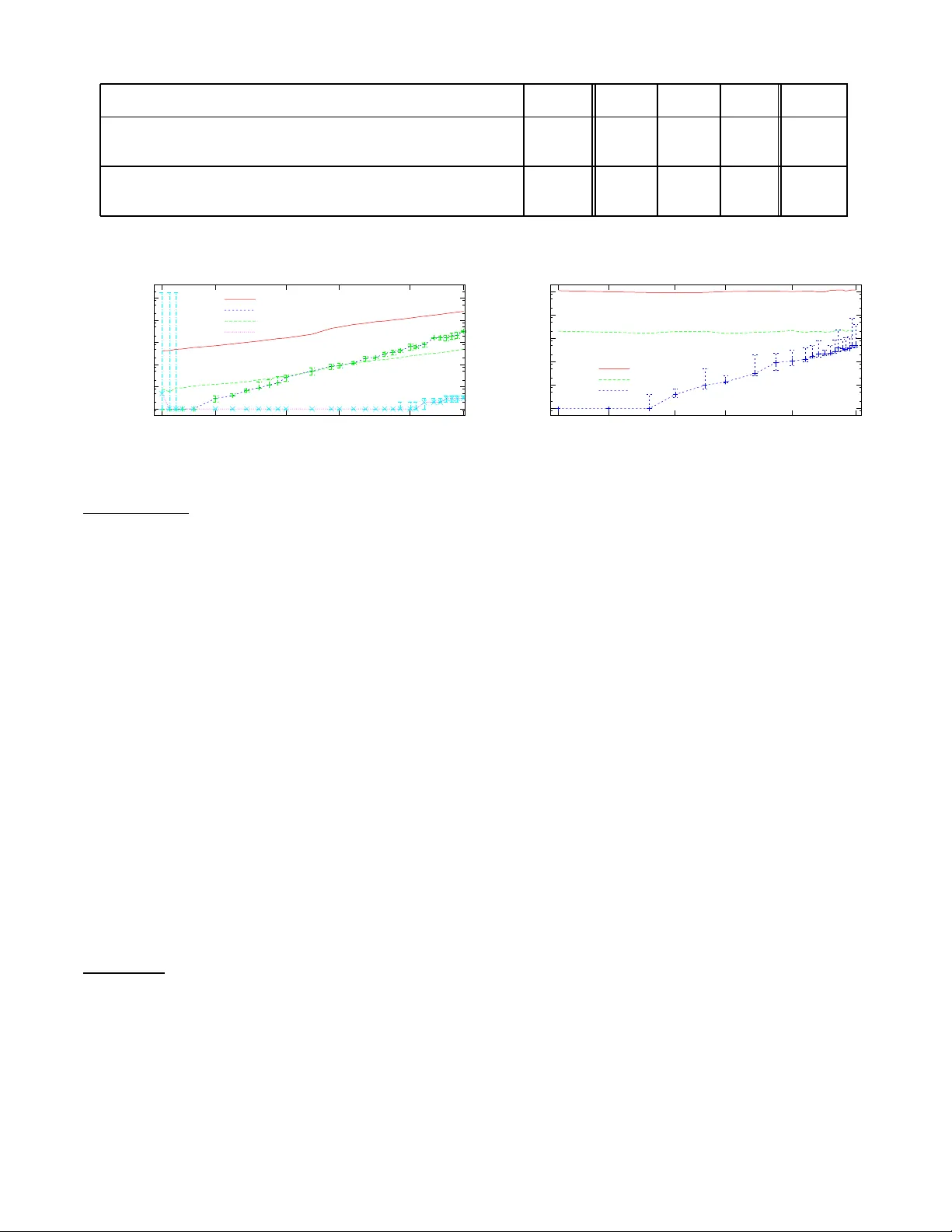
Conditioning Pr obabilistic Databases Christoph K och Depar tment of Computer Science Cor nell Univ ersity Ithaca, NY 14853, USA koch@cs.cornell.edu Dan Olteanu Computing Laboratory Oxford Unive rsity Oxford, O X 1 3QD , UK dan.oltean u@comlab .ox.ac.uk ABSTRA CT P ast researc h on probabilistic databases has studied the problem of a nsweri ng q ueries on a static database. Ap- plication scenarios of probabili stic databases ho wev er often inv olve the conditioning of a database u sing add itional in- formation in the form of n ew evidence. The cond itioning problem is thus to transform a probabilistic database of pri- ors into a posterior probabilistic database which is material- ized for subsequent q uery processing or further refinemen t. It turns out that the conditioning problem is closely related to the problem of compu ting exact t uple confid ence v alues. It is kno wn that exact confidence computation is an N P- hard problem. This has led researchers to consider app rox- imation techniques for confiden ce compu tation. How ever, neither conditioning nor exact confidence computation can b e solv ed using suc h tec hniques. In this pap er w e present ef- ficient techniques for b oth problems. W e study several prob- lem decomposition metho ds and heuristics that are based on the most successful searc h tec hniques from constraint satis- faction, such as the Davis-Putnam algorithm. W e comple- ment this with a thorough exp erimental ev aluation of th e algorithms prop osed. Our ex periments show that our ex- act algorithms scale w ell to realistic database sizes and can in some scenarios compete with the most efficient previous approximatio n algorithms. 1. INTR ODUCTION Queries on probabilistic databases ha ve numerous applica- tions at the interface of d atabases and in formation retriev al [13], data cleaning [4 ], sensor data, trac king moving ob jects, crime fighting [5], and compu tational science [9]. A core operation of qu eries on prob ab ilistic databases is the computation of confi d ence v alues of tu ples in th e result of a q uery . In short, the confi dence in a tuple t b eing in the result of a qu ery on a probabilistic d atabase is t h e com bined probabilit y weigh t of all p ossible wo rlds in which t is in the result of the qu ery . By extending the p ow er of query languages for probabilis- tic d atabases, new applications b eyond the mere retriev al of tuples and their confidence b ecome p ossible. An essen tial operation th at allows for new applications is c onditioning , the op eration of remo ving p ossible worl ds which do not sat- isfy a given cond ition from a probabilistic database. Sub se- quent qu ery op erations will apply to the reduced database, and a confidence computation will retu rn c onditional pr ob- abilities in the Bay esian sense with resp ect to the original database. Computing conditioned probabilistic databases has natural and imp ortan t app lications in virtu ally all areas in which probabilistic databases are useful. F or example, in data cleaning, it is only natural to start with an u ncertain database and then clean it – reduce u ncertain ty – by adding constrain ts or additional information. More generally , con- ditioning allow s us to start with a database of prior proba- bilities, to add in some evidenc e , and take it to a p osterior probabilistic database that takes the evid en ce into account. Consider the ex ample of a p robabilistic database of so cial securit y numbers (S SN) and n ames of ind ividuals extracted from pap er forms u sing O CR soft w are. If a sy m b ol or w ord cannot be clearly iden tified, this soft ware will offer a num b er of wei ghted alternativ es. The database R SSN NAME { 1 (p=.2) | 7 (p=.8) } John { 4 (p=.3) | 7 (p=.7) } Bill represents four p ossible wo rlds (shown in Figure 1), mod- elling that John has either SSN 1 or 7, with probabilit y .2 and .8 (the pap er form may contain a hand-written symb ol that can either b e read as a Europ ean “1” or an Ameri- can “7”), resp ectivel y , and Bill has either SSN 4 or 7, with probabilit y .3 and .7, resp ectively . W e assume indep endence b et w een John’s and Bill’s alternatives, thus the world in whic h John has SSN 1 and Bill has SSN 7 has probabilit y . 2 · . 7 = . 14. If A x denotes the even t that Bill has SSN x , then P ( A 4 ) = . 3 and P ( A 7 ) = . 7. W e can compute th ese probabilities in a probabilistic database b y asking for the confidence va lues of the tuples in the result of the query select SSN, conf(SSN) from R where N AME = ’Bill’; whic h will result in the table Q SSN CONF 4 .3 7 .7 Now sup pose we w ant to u se the additional kn o wledge that so cial securit y n umbers are unique. W e can express this R 1 SSN NAME 1 John 4 Bill R 2 SSN NAME 7 John 4 Bill P = .06 P = .24 R 3 SSN NAME 1 John 7 Bill R 4 SSN NAME 7 John 7 Bill P = .14 P = .56 Figure 1: The four w orlds of the input database. using a fun ctional dep endency SSN → NAME. Asserting this constraint, or conditioning the probabilistic d atabase using the constraint, means to eliminate all those w orlds in whic h the functional dep endency d o es not h old. Let B b e th e event that t he funct ional dep enden cy holds. Conceptually , the d atabase conditioned with B is obtained by removing worl d R 4 (in which John and Bill h a ve th e same SSN) and renormalizing th e p robabilities of the remaining w orlds to ha ve th em again sum up to 1, in this case by divid- ing by . 06 + . 24 + . 14 = . 44. W e will thin k of conditioning as an operation assert[ B ] th at redu ces un certain ty by declaring w orlds in whic h B do es not hold impossible. Computing tuple confi dences for the above q uery on the original database will giv e us, for eac h p ossible SSN val ue x for Bill, the probabilities P ( A x ), while on the database conditioned with B it will give a table of so cial security num bers x and conditional probabilities P ( A x | B ) . F or example, the conditional probability of Bill having SSN 4 giv en th at so cial security numbers are unique is P ( A 4 | B ) = P ( A 4 ∧ B ) P ( B ) = . 3 . 44 ≈ . 68 . Using this definition, we could alternatively hav e com- puted the cond itional probabilities by combining th e results of tw o confidence compu tations, select SSN, P1/P2 from (select SSN, conf(SSN) P1 from R , B where NAME = ’Bill’), (select conf() P2 from B); where B is a Boolean query that is tru e if the functional dep endency holds on R . Unfortunately , b oth conditioning and confidence compu- tation are NP-hard problems. Nevertheless, their study is justified by th eir obvious relev ance and applications. While conditioning has not b een prev iously studied in the con- text of p robabilistic databases, p revious work on confiden ce computation has aimed at cases that admit polyn omial-time query eva luation and at app ro ximating confiden ce v alues [9 ]. Previous work often assumes that confid ence va lues are computed at the end of a qu ery , closing the p ossible worlds seman tics of t h e probabilistic database and retu rning a com- plete, nonprobabilistic relation of tuples with numeric al con- fidence val ues th at can b e used for decision making. In such a con text, techniques that return a reasonable approxima- tion of confid ence v alues may b e acceptable. In other scenarios w e do not wan t to accept approxi- mate confidence v alues b ecause errors mad e while comput- ing these estimates aggregate and gro w, causing users to make wrong decisions based on th e query results. This is particularly t ru e in comp ositional query languages for p rob - abilistic databases, where confidence val ues computed in a sub query form part of an intermediate result that can b e accessed and used for filtering the data in subseq u en t query operations [19]. Similar issues arise when confidence v alues can b e inserted into the probabilistic d atabase through up dates and m ay b e used in subsequent queries. F or example, data cleaning is a scenario where we, on one hand, wan t to materialize the result of a data transformatio n in the d atabase once and for all (rather than having to redo the cleaning steps every time a query is asked) and on the other hand do not wan t to store incorrect probabilities that ma y affect a very large num ber of subsequent q ueries. H ere w e need techniques for conditioning and exactly comput in g confidence v alues. Exact confid ence computation is particularly imp ortan t in queries in which confidence v alues are u sed in compariso n predicates. F or an example, let us add a th ird p erson, F red, to the database whose S SN is either 1 or 4, with eq ual proba- bilit y . If we again condition using the functional depen dency SSN → N AM E , w e h ave only tw o p ossible worlds, one in whic h John, Bill, and F red h ave social security numbers 1, 7, and 4, resp ectively , and one in which their SS N are 7, 4, and 1. If w e now ask for the so cial securit y numbers t hat are in the database for certain, select SSN from R where conf(SSN) = 1; w e should get three tuples in the result. Monte Carlo simu- lation based ap p ro ximation algorithms will do v ery badly on such queries. Confidence appro ximation using a Karp-Luby- style algorithm [17, 9, 21] will indep endently u nderestimate eac h tuple’s confid en ce with probability ≈ .5. Thus the p rob- abilit y that at least one tuple is missing from the result of such a query is very high ( see also [19]. In this pap er, w e d evelop efficien t algorithms for com- puting exact confidences and for conditioning probabilistic databases. The detailed contributions are as follo ws. • In most previous mo dels of probabilistic databases ov er finite world-sets, computing tup le confidence v alues es- senti ally means the w eigh ted coun ting of solutions to constrain t structures closely related to disjunctive nor- mal form form ulas. Our notion of such structures are the world-set descriptor sets, or ws-sets for short. W e formally introduce a p robabilistic database model that is known to cleanly and d irectly generalize man y pre- viously considered probabilistic database mo dels (cf. [3]) includin g, among others, v arious forms of tup le- indep endence mo dels [9, 2 ], ULDBs [5], pro duct de- composition [4], and c-table-based mo dels [3]. W e u se this framew ork to stud y exact confidence comput ation and conditioning. The results obtained are thus of im- mediate relev ance t o all th ese m o dels. • W e study prop erties of ws-sets that are essen tial to relational algebra query ev aluation and to the design of algorithms for the tw o main problems of the p aper. • W e exhibit th e fundamental, close relationship b etw een the tw o problems. • W e develop ws-tr e es , which capture notions of struc- tural decomp osition of ws-sets based on probabilistic indep endence and w orld-set disjoin t ness. Once a ws- tree has b een ob t ained for a given ws-set, b oth exact confidence computation and conditioning are feasible in linear time. The main problem is thus to efficiently find small ws-tree decomp ositions. W V ar Dom P j 1 .2 j 7 .8 b 4 .3 b 7 .7 U R WSD SSN NAME { j 7→ 1 } 1 John { j 7→ 7 } 7 John { b 7→ 4 } 4 Bill { b 7→ 7 } 7 Bill Figure 2: Probabilistic database with ws-des criptors made ex plicit and defined b y world-t able W . • T o this end, we develop a decomp osition pro cedure motiv ated by th e Davis-Putnam (DP) procedure for chec kin g Prop ositional Satisfiabilit y [12]. DP , while many decades old, is still the basis of th e b est exact solution techniques for the NP-complete Satisfiabilit y problem. W e introduce tw o d ecomposition ru les, v ari- able eliminatio n (t h e main rule of DP) and a new in- dep endence d ecomposition rule, and develop heuristics for chosing among the rules. • W e develop a database cond itioning algo rithm based on ws-tree decomp ositions and p rove its correctness. • W e study ws-set simplification and elimination tec h- niques that can b e either used as an alternative to the DP-based pro cedure or combined with it. • W e provide a t horough exp erimental ev aluation of the algorithms presented in this pap er. W e also exp eri- mental ly compare our exact t echniques for confidence computation with approximatio n based on Monte Carlo sim ulation. The structure of the pap er follow s the list of contributions. 2. PR OB ABILISTIC D A T AB ASES W e defi n e sets of p ossible worlds follo wing U - relational databases [3]. Consider a finite set of indep endent random v ariables ranging ov er fi nite domains. Probabilit y d istri- butions ov er the possible worlds are defined by assigning a probabilit y P ( { x 7→ i } ) to eac h assignment of a v ariable x to a constant of its domain, i ∈ Dom x , such th at t he probabili- ties of all assignments of a giv en v ariable sum up to one. W e represent the set of v ariables, t heir d omains, and probabil- it y d istributions relationally by a world-table W consisting of all triples ( x , i, p ) of v ariables x , va lues i in the domain of x , and the associated probabilities p = P ( { x 7→ i } ). A world-set descriptor is a set of assignments x 7→ i with i ∈ Dom x that is functional, i.e. a partial function from v ari- ables to d omain v alues. If suc h a w orld-set descriptor d is a total function, then it iden tifies a possible w orld. Otherwise, it denotes all those p ossible w orlds ω ( d ) identified by total functions f that can b e obtained b y extension of d . (That is, for all x on which d is d efined, d ( x ) = f ( x ).) Because of the indep endence of the v ariables, the aggregate probabilit y of these worlds is P ( d ) = Y { x 7→ i }⊆ d P ( { x 7→ i } ) . If d = ∅ , then d d enotes the set of all p ossible wo rlds. W e sa y that tw o ws-descriptors d 1 and d 2 are c onsistent iff their union (as sets of assignmen ts) is functional. A ws-set is a set of ws-descriptors S and represents the w orld-set computed as the union of the worl d-sets repre- sented by th e ws-descriptors in t h e set. W e define the se- mantics of ws-sets using the (herewith ov erloaded) funct ion ω extended to ws-sets, ω ( S ) := S d ∈ S ( ω ( d )). A U-r elation ov er schema Σ and worl d-table W is a set of tup les o ver Σ, where we associate to each tu ple a ws- descriptor o ver W . A pr ob abili stic datab ase ov er schema { Σ 1 , . . . , Σ n } and wo rld-table W is a set of n U-relations, eac h ov er one sc hema Σ i and W . A probabilistic database represents a set of databases, one database for eac h p ossible w orld d efi ned by W . T o obtain a possible w orld in the rep- resen ted set, we first choose a total v aluation f ov er W . W e then pro cess eac h probabilistic relation R i tuple by tuple. If f extends th e ws-descriptor d of a tu p le t , then t is in the relation R i of that database. Example 2.1. Consider again th e probabilistic database of social securit y num b ers and names given in Figure 1. Its representa tion in our formali sm is give n in Figure 2. The w orld-table W of Figure 2 defines tw o v ariables j and b mod eling the so cial security num b ers of John and Bill, with domains { 1 , 7 } and { 4 , 7 } respectively . The probabilit y of the world d efined by f = { j 7→ 7 , b 7→ 7 } is . 8 · . 7 = . 56. The total v aluation f ext ends the ws-descriptors of the second and fourth tuple of relation U R , thus the relation R in worl d f is { (7, John), (7, Bill) } . ✷ Remark 2.2. Leaving aside the probability distributions of the va riables whic h are represented by the W table, U- relations are essentia lly restricted c-tables [16] in whic h the global condition is “true”, v ariables m ust not o ccur in the tuples, and each lo cal condition must be a conjunction of conditions of the form x = v where x is a v ariable and v is a constant. Nevertheless, it is k n o wn that U-relations are a complete represen tation system for probabilistic databases o ver n on emp t y fi nite sets of possible w orlds. U-relations can b e used to represent attribute-level uncer- taint y using v ertically decomp osed relations. F or details on this, we refer to [3]. All results in this pap er w ork in the context of attribut e-lev el u ncertain ty . The efficien t execution of th e op erations of p ositiv e rela- tional algebra on suc h d atabases was describ ed in that paper as wel l. Briefly , if U-relations U R and U S represent relations R and S , th en selections σ φ R and pro jections π A R sim- ply translate into σ φ U R and π W S D , A U R , resp ectively . Joins R ⊲ ⊳ φ S translate into U R ⊲ ⊳ φ ∧ ψ U S where ψ is the condi- tion t h at the ws-descriptors of the tw o tuples compared are consisten t with each other (i.e., hav e a common extension into a total v aluation). The set op erations easily follo w from the an alogous operations on ws-sets that will b e describ ed b elo w, in Section 3.2. ✷ Example 2.3. The functional dep endency SSN → NAME on th e probabilistic database of Figure 2 can b e ex pressed as a bo olean relational algebra q uery as the complement of π ∅ ( R ⊲ ⊳ φ R ) where φ := (1 .S S N = 2 .S S N ∧ 1 .N AM E 6 = 2 .N A M E ). W e tu rn this into the query π W S D ( U R ⊲ ⊳ φ ∧ 1 .W S D consistent with 2 .W S D U R ) . o ver our represen tation, which results in t he ws-set { j 7→ 7 , b 7→ 7 } . The complement of this with th e world-set given by th e W relation, {{ j 7→ 1 } , { j 7→ 7 } , { b 7→ 4 } , { b 7→ 7 }} , is {{ j 7→ 1 } , { j 7→ 7 , b 7→ 4 }} . (Note that this is just one among a set of equ iv alent solutions.) ✷ 3. PR OPER TIES OF WS-DESCRIPT ORS In th is section we inv estigate prop erties of ws-descriptors and show how t hey can b e used to efficiently imp lemen t v arious set op erations on wo rld-sets without having to enu- merate the worlds. This is imp ortant, for such sets can be extremely large in practice: [4, 3] rep ort on ex periments with 10 10 6 w orlds. 3.1 Mutex, Independ ence, a nd Containment Tw o ws-descriptors d 1 and d 2 are (1) mutual ly exclusive (mutex for short) if they represen t disjunct world-sets, i.e., ω ( d 1 ) ∩ ω ( d 2 ) = ∅ , and (2) indep endent if there is no val u- ation of th e vari ables in one of the ws-descriptors th at re- stricts the set of possible v aluations of the v ariables in the other ws-descriptor (t hat is, d 1 and d 2 are defin ed only on disjoin t sets of v ariables). A ws-descriptor d 1 is c ontaine d in d 2 if the worl d-set of d 1 is contai ned in the w orld-set of d 2 , i.e., ω ( d 1 ) ⊆ ω ( d 2 ). Equivalenc e is mutual conta inment. Although ws-descriptors represent v ery succinctly possi- bly very large w orld-sets, all aforementioned prop erties can b e efficiently c heck ed at the syntactical level: d 1 and d 2 , where all v ariables with singleton domains are eliminated, are (1) m utex if th ere is a vari able with a different assig n- ment in eac h of th em, and (2) indep endent if th ey have n o v ariables in common; d 1 is conta ined in d 2 if d 1 extends d 2 . Example 3.1. Consider th e wo rld-table of Figure 2 and the ws-descriptors d 1 = { j 7→ 1 } , d 2 = { j 7→ 7 } , d 3 = { j 7→ 1 , b 7→ 4 } , and d 4 = { b 7→ 4 } . Then, the pairs ( d 1 , d 2 ) and ( d 2 , d 3 ) are m utex, d 3 is contained in d 1 , and the pairs ( d 1 , d 4 ) and ( d 2 , d 4 ) are indep endent. ✷ W e also consider the mutex, ind epend ence, and equiva - lence prop erties for ws-sets. Two ws-sets S 1 and S 2 are mutex (indep endent) iff d 1 and d 2 are mutex (indep endent) for any d 1 ∈ S 1 and d 2 ∈ S 2 . Two ws-sets are equiv alent if they represent th e same world-set. Example 3.2. W e continue Examp le 3.1. The ws-set { d 1 } is mutex with { d 2 } . { d 1 , d 2 } is indep endent from { d 4 } . At a first glance, it lo oks like { d 1 , d 2 } and { d 3 , d 4 } are nei- ther mutex nor indep endent, b ecause d 1 and d 3 o verlap. How ever, we note that d 3 ⊆ d 4 and then ω ( { d 3 , d 4 } ) = ω ( { d 4 } ) and { d 4 } is indep endent from { d 1 , d 2 } . ✷ 3.2 Set Operations on ws-sets V arious relev an t comp u tation tasks, ranging from d eci- sion procedures lik e tuple p ossibilit y [1] to confidence com- putation of answer tuples, and conditioning of p robab ilistic databases, require symbolic manipulations of ws-sets. F or example, chec k ing whether t wo tu ples of a p robabilistic re- lation can co-o ccur in some w orlds can b e done by interse ct- ing their ws-descriptors; b oth tuples co-o ccur in the worlds defined by th e intersection of the corresp onding w orld-sets. W e next d efine set operations on ws-sets. • Interse ction . Intersect( S 1 , S 2 ) := { d 1 ∩ d 2 | d 1 ∈ S 1 , d 2 ∈ S 2 , d 1 is consistent with d 2 } . • Union . Union( S 1 , S 2 ) := S 1 ∪ S 2 . • Differ enc e . The definition is inductive, starting with singleton ws-sets. If ws-descriptors d 1 and d 2 are in- consisten t, Diff( { d 1 } , { d 2 } ) := { d 1 } . Otherwise, Diff( { d 1 } , { d 2 } ) := { d 1 ∪ { x 1 7→ w 1 , . . . , x i − 1 7→ w i − 1 , x i 7→ w ′ i } | d 2 − d 1 = { x 1 7→ w 1 , . . . , x k 7→ w k } , 1 ≤ i ≤ k , w ′ i ∈ dom x i , w i 6 = w ′ i } . Diff( { d 1 } , S ∪ { d 2 } ) := Diff(Diff( { d 1 } , S ) , { d 2 } ) . Diff( { d 1 , . . . , d n } , S ) := [ 1 ≤ i ≤ n Diff( { d i } , S ) . Example 3.3. Consider d 1 = { j 7→ 1 } , d 2 = { j 7→ 7 } , and d 3 = { j 7→ 1 , b 7→ 4 } . Then, Intersect( { d 1 } , { d 2 } ) = Intersect( { d 2 } , { d 3 } ) = ∅ because d 2 is inconsistent with d 1 and d 3 . Intersect( { d 1 } , { d 3 } ) = { d 3 } , b ecause d 3 is con- tained in d 1 . D iff( { d 2 } , { d 1 } ) = Diff( { d 2 } , { d 3 } ) = { d 2 } b e- cause d 2 is mutex with d 1 and d 3 . D iff( { d 1 } , { d 3 } ) = {{ j 7→ 1 , b 7→ 7 }} . Diff( { d 3 } , { d 1 } ) = { d 3 } , b ecause d 3 and d 1 are inconsisten t. ✷ Pr oposition 3.4. The ab ove definitions of set op er ations on ws-set s ar e c orr e ct: 1. ω ( Union ( S 1 , S 2 )) = ω ( S 1 ) ∪ ω ( S 2 ) . 2. ω ( Interse ct ( S 1 , S 2 )) = ω ( S 1 ) ∩ ω ( S 2 ) . 3. ω ( Diff ( S 1 , S 2 )) = ω ( S 1 ) − ω ( S 2 ) . The ws-desc riptors in Diff ( S 1 , S 2 ) ar e p ai rwi se mutex. 4. WORLD-SE T TREES The ws-sets hav e imp ortan t p roperties, lik e su ccinctness, closure und er set op erations, and natural relational en cod- ing, and [3] emplo yed t hem to achiev e the p urely relational processing of p ositiv e relational algebra on U-relational d a- tabases. When it comes to the manip u lation of probabilities of query answers or of worl ds violating given constraints, how ever, ws-sets are in most cases inadeq u ate. This is be- cause ws-descriptors in a ws-set may represent non- d isjoi nt w orld-sets, and for most manipulations of p robabilities a substantial computational effort is needed to identify com- mon wor ld-subsets across possibly many ws-descriptors. W e n ext introdu ce a new compact representation of world- sets, called world-set tr e e representation, or ws-tree for short, that makes the structu re in the ws-sets explicit. This rep - resen tation formalism allo ws for efficient exact probability computation and conditioning and h as strong conn ections to know l e dge c ompilation , as it is used in system mo delling and veri fication [11]. There, too, va rious kinds of decision diagrams, like binary decision diagrams (BDD s) [7], are em- plo yed for th e efficient manipulation of prop ositional formu- las. Definition 4.1. Given a w orld-table W , a ws-tree ov er W is a tree with inner nodes ⊗ and ⊕ , leav es h olding th e ws-descriptor ∅ , and edges ann otated with weigh ted v ariable assignmen ts consistent with W . The follo wing constraints hold for a ws-tree: • A v ariable defined in W occu rs at most once on eac h root-t o- leaf p ath. W V D P x 1 .1 x 2 .4 x 3 .5 y 1 .2 y 2 .8 z 1 .4 z 2 .6 u 1 .7 u 2 .3 v 1 .5 v 2 .5 ⊗ ⊕ ∅ x 7→ 1 ⊗ x 7→ 2 ⊕ ∅ y 7→ 1 ⊕ ∅ z 7→ 1 ⊕ ⊕ u 7→ 1 ∅ v 7→ 1 ∅ u 7→ 2 S = { { x 7→ 1 } , { x 7→ 2 , y 7→ 1 } , { x 7→ 2 , z 7→ 1 } , { u 7→ 1 , v 7→ 1 } , { u 7→ 2 } } Figure 3: W orld-set table W , a ws-tree R ov er W , and an e quiv alent ws-set S . • Each of its ⊕ - nodes is asso ciated with a v ariable v such that eac h outgoing edge is annotated with a different assignmen t of v . • The sets of v ariables occu rring in the subtrees rooted at the children of any ⊗ -no de are d isjoi nt. ✷ W e define the semantic s of ws-trees in strict analogy to that of ws-sets based on the observa tion that the set of edge annotations on eac h ro ot-to-leaf path in a ws-tree represen ts a ws-descriptor. The w orld-set represen ted by a ws-tree is precisely represen ted by the ws-set consis ting of the anno- tation sets of all ro ot-to-leaf paths. The inner n o des hav e a sp ecial seman tics: the c hildren of a ⊗ -no de use disjoin t v ariable sets and are thus indep endent, and the children of a ⊕ -no de follow branc hes with different assignments of th e same v ariable and are thus mutually exclusive. Example 4.2. Figure 3 sho ws a ws-tree and the ws-set consisting of all its ro ot-to-leaf p aths. ✷ 4.1 Constructing world-set tr ees The key idea underlyin g our translation of ws-sets into ws-trees is a divide-and-conqu er approach th at exploits the relationships b et we en ws-d escriptors, like indep endence and v ariable sharing. Figure 4 gives our translation algori thm. W e pro ceed re- cursivel y by p artitioning the ws-sets in to indepen dent dis- join t partitions (when p ossible) or into (p ossibly ov erlap- ping) partitions th at are consistent with different assign- ments of a v ariable. In th e case of indep endent partitioning, w e create ⊗ -nod es whose children are the translations of the indep endent partitions. In the second case, we simplify the problem b y eliminating a v ariable: w e c ho ose a v ariable x and create an ⊕ -no de whose outgoing edges are annotated with different assignmen ts x 7→ i of x and whose children are translations of the subsets of the ws-set consisting of ws- descriptors consisten t with x 7→ i 1 . I f at any recursion step the input ws-set contains t he nulla ry ws-descriptor, whic h by defi nition represen ts the whole wo rld-set, then w e stop from recursion and create a ws-tree leaf ∅ . This can happ en after several v ariable elimination steps that red u ced some of the input ws-descriptors to ∅ . 1 Our translation abstracts out implemen tation details. F or instance, for those assignmen t s of x th at do not o ccur in S w e hav e T ∪ S x 7→ i = T and can translate T only once. ComputeT ree (WS-Set S) returns WS-T ree if ( S = ∅ ) then return ⊥ else if ( ∅ ∈ S ) //S contains a universal ws-desc then return ∅ else choose one of the follo wing: (indep endent partitioning) if there are non-emp t y and indep endent ws-sets S 1 , . . . , S | I | suc h that S = S 1 ∪ · · · ∪ S | I | then return O i ∈ I ` ComputeT ree( S i ) ´ (v ariable elimination) choose a v ariable x in S ; T := { d | d ∈ S, 6 ∃ i ∈ dom x : { x 7→ i } ⊆ d } ; ∀ i ∈ dom x : S x 7→ i := {{ y 1 7→ j 1 , . . . , y m 7→ j m } | { x 7→ i, y 1 7→ j 1 , . . . , y m 7→ j m } ∈ S } ; return M i ∈ dom x ` x 7→ i : Comput eT ree( S x 7→ i ∪ T ) ´ Figure 4: T ranslating ws-sets in to ws-trees. Example 4.3. W e sho w how to translate t h e ws-set S into the ws-tree R (Figure 3). W e first partition S into tw o (minimally) ind epend en t ws-sets S 1 and S 2 : S 1 consists of the first three ws-descriptors of S , and S 2 consists of the remaining t wo . F or S 1 , w e can eliminate any of the v ariables x , y , or z . Consider we choose x and create tw o branches for x 7→ 1 and x 7→ 2 resp ectiv ely (there is no ws-descriptor consisten t with x 7→ 3). F or the first branch, we stop with the ws-set {∅} , whereas for the second branch we continue with the ws-set {{ y 7→ 1 } , { z 7→ 1 }} . The latter ws-set can b e p artitioned in to indepen dent subsets in the c ontext of the assignmen t x 7→ 2. W e p roceed similarly for S 2 and choose to eliminate varia ble u . W e create an ⊕ -no de with outgoing edges for assig nments u 7→ 1 and u 7→ 2 respectively . W e are left in t h e former case with the ws-set {{ v 7→ 1 }} and in the latter case with {∅} . Different v ariable c hoices can lead to different ws-trees. This is t he so-called variable or dering pr oblem that applies to t he construction of bin ary decision d iagrams . Later in ⊕ ⊕ y 7→ 1 ⊗ u 7→ 1 ⊕ ∅ v 7→ 1 ⊕ ⊕ ( α ) z 7→ 2 ∅ x 7→ 1 ∅ x 7→ 2 α ∅ u 7→ 2 ⊕ y 7→ 2 ∅ x 7→ 1 ⊗ x 7→ 2 ⊕ ∅ z 7→ 1 ⊕ ( β ) ∅ u 7→ 2 ⊕ u 7→ 1 ∅ v 7→ 1 β x 7→ 3 Figure 5: A ws-tree equiv al ent to R of Figure 3. this section we d iscuss h eu ristics for vari able orderings. ✷ Theorem 4.4. Gi ven a ws-set S , ComputeT r e e ( S ) and S r epr esent the same world-set. Our translation can yield ws-trees of ex ponential size (sim- ilar to BDDs). This rather h igh wo rst-case complexity needs to b e paid for efficien t exact probabilit y computation and conditioning. It is known that counting mo dels of prop osi- tional formulas and exact probabilit y computation are # P- hard problems [9]. This complexity result does not preclude, how ever, BDDs from b eing very successful in practice. W e exp ect the same for ws-trees. The key observ ation for a go od b eha viour in practice is t h at we should partition ws-sets into indep endent subsets whenever p ossible and w e sh ould care- fully choose a goo d ordering for v ariable eliminations. Both metho d s greatly influence the size of the ws-trees and the translation time, as sh own in the next example. Example 4.5. Consider again the ws-set S of Figure 3 and a different ordering for va riable eliminations th at leads to th e ws-tree of Figure 5. W e shortly discuss the construc- tion of this ws-tree. Assume w e c ho ose to eliminate th e v ariable y and obtain the ws-sets S y 7→ 2 = {{ x 7→ 1 } , { x 7→ 2 , z 7→ 1 } , { u 7→ 1 , v 7→ 1 } , { u 7→ 2 }} S y 7→ 1 = S y 7→ 2 ∪ {{ x 7→ 2 }} In contrast to th e computation of the ws-tree R of Figure 3, our v ariable choi ce creates intermedia ry ws-sets that o verl ap at large , which ultimately leads to a large increase in the size of the ws-tree. This bad choice need not necessarily lead t o r e dundant computation, whic h we could easily detect. In fact, the only ma jor savings in case we detect and eliminate redundancy here are the subtrees α and β , which still leav e a graph larger than R . ✷ 4.2 Heuristics W e next study heuristics for v ariable elimination and in- dep endent partitioning that are compared exp erimental ly in Section 7. W e d evise a simple cost estimate, whic h we u se to decide at each step whether to p artition or whic h v ari- able to eliminate. W e assume th at, in worst case, th e cost of translating a ws-set S is 2 | S | (follo wing the exponential form ula of the inclusion-exclu sion principle). In case of ind ep endent partitioning, the p artitions S 1 , . . . , S n are disjoin t and can b e computed in p olynomial time (by Estimate (WS-Set S , va riable x in S ) returns Real missing assignmen t := false; foreac h i ∈ dom x do compute S x 7→ i and T as sho wn in Figure 4 if | S x 7→ i | > 0 then s i = | S x 7→ i ∪ T | else s i = 0; missing assignmen t = tru e; endif if (missing assignmen t) then e = | T | el se e = 0 foreac h j ∈ dom x suc h that s j > 0 do e = e + log k (1 + k s j − e ) return e Figure 6: Log cost estimate for a v ariable c hoice . computing the connected comp onents of the graph of v ari- ables co-occurring within ws-descriptors). W e th us reduce the computation cost from 2 | S | to 2 | S 1 | + · · · + 2 | S n | . This metho d is, how ever, not alwa ys applicable and w e need t o apply v ariable elimination. The main adv antage of v ariable elimination is that S is divided into su bsets T ∪ S x 7→ i without the dep endencies en- forced by v ariable x and thus sub ject to indep endent parti- tioning in the context of x 7→ i . Consider s i the size of the ws-set T ∪ S x 7→ i . Then, the cost of choosing x is Σ i ∈ dom x 2 s i . Of course, for th ose assignmen ts of x that do n ot occur in S w e h a ve T ∪ S x 7→ i = T and can translate T only once. The compu tation cost using v ariable elimination can match that of indep endent partitioning only in the case that the assignmen ts of th e chosen v ariable partition the input ws-set S and thus T is empty . Our first heuristic, called mi nl o g , c ho oses a va riable that minimizes log( dom x Σ i =1 2 s i ). Figure 6 shows how to compute incremental ly t h e cost estimate by a vo iding summation of p oten tially large numbers. The v ariable missing assignmen t is used to detect wheth er there is at least one assignment of x not o ccuring in S for whic h T will b e translated; in th is case, T is only translated once (and not for every missing assignmen t). The second heuristic, called mi nmax , approximates t he cost estimate and chooses a v ariable that minimizes t h e max- imal ws-set T ∪ S x 7→ i . Both heuristics need time linear in th e sizes of all vari able d omains plus of the ws-set. In addition to minmax, minlog n eeds to p erform log and exp op erations. Remark 4.6. T o b etter un derstand our h euristics, we giv e one scenario where minmax b ehav es sub optimal. Con- sider S of size n and tw o v ariables. V ariable x o ccurs with the same assignment in n − 1 ws-descriptors and thus its min- max estimate is n , and v ariable y o ccurs twice with differen t assignmen ts, and thus its minmax estimate is n − 1. U sing minmax, w e c ho ose y , although the minlog would choose dif- feren tly: e ( y ) = log(2 · 2 n − 1 + 2 n − 2 ) > log(2 · 2 n − 1 ) = e ( x ). ✷ 4.3 Pr obability computation W e next giv e an alg orithm for computing the exact p roba- bilit y of a ws-set by employing the translation of ws-sets in to ws-trees d iscussed in Section 4. Figure 7 defines the func- tion P to this effect. This function is defined using pattern matc hing on the no de types of ws-trees. The probability of an ⊗ - node is t he join t p robabilit y of its indep endent children S 1 , . . . , S | I | . The probability of an ⊕ -nod e is the joint p rob- P ` O i ∈ I S i ´ = 1 − Y i ∈ I (1 − P ( S i )) P ` M i ∈ I ( x 7→ i : S i ) ´ = X i ∈ I P ( { x 7→ i } ) · P ( S i ) P ( ∅ ) = 1 P ( ⊥ ) = 0 Figure 7: Probability computation for ws-trees. abilit y of its mutually exclusive c hildren, where the proba- bilit y of eac h child S i is weigh ted by the probability of the v ariable assignmen t x 7→ i annotating the incoming edge of S i . Finally , the probabilit y of a leaf represen ted by the nulla ry ws-descriptor is 1 and of ⊥ is 0. Example 4.7. The p robab ility of the ws-tree R of Fig- ure 3 can b e comput ed as follo ws (w e lab el the inner no d es with l for left c hild and r for right child): P ( R ) = 1 − (1 − P ( l ) ) · (1 − P ( r )) P ( l ) = P ( { x 7→ 1 } ) · P ( ∅ ) + P ( { x 7→ 2 } ) · P ( l r ) P ( l r ) = 1 − (1 − P ( { y 7→ 1 } ) · P ( ∅ )) · (1 − P ( { z 7→ 1 } ) · P ( ∅ )) P ( r ) = P ( { u 7→ 1 } ) · P ( { v 7→ 1 } ) · P ( ∅ ) + P ( { u 7→ 2 } ) · P ( ∅ ) W e can n ow replace t he p rob ab ilities for v ariable assign- ments and ws-descriptor ∅ an d ob t ain P ( r ) = 0 . 7 · 0 . 5 · 1 + 0 . 3 = 0 . 65 P ( l r ) = 1 − (1 − 0 . 2 · 1) · (1 − 0 . 4 · 1) = 0 . 52 P ( l ) = 0 . 1 · 1 + 0 . 4 · 0 . 52 = 0 . 308 P ( R ) = 1 − (1 − 0 . 308) · (1 − 0 . 65) = 0 . 7578 ✷ The probabilit y of a ws-tree R can b e compu ted in one b ottom-up trav ersal of R and do es not require the precom- putation of R . The t ranslation and probability compu ta- tion functions can be easily comp osed to obtain th e func- tion ComputeT ree ◦ P by inlining P in ComputeT ree. As a result, the construction of the n odes ⊕ , ⊗ , and ∅ is replaced by the corresp onding probability computation give n by P . 5. CONDITIONING In t h is section we study th e problem of conditioning a probabilistic database, i.e., the problem of remo ving all p os- sible wo rlds th at do not satisfy a given condition (sa y , b y a Boolean relatio nal calculus query) and renormalizing the database such that, if there is at least one world left, the probabilit y weigh ts of all worlds sum up to one. W e will think of conditioning as a query or u pd ate op- eration assert φ , where φ is the condition, i.e., a Boolean query . Processing relational algebra queries on probabilistic databases was discussed in Section 2. W e will now assume the result of the Bo olean query given as a ws-set defining the worlds on which φ is true. Example 5.1. Consider again the data cleaning exam- ple from the Introd u ction, formalized by the U-relational database of Figure 2. Relation W represen ts the set of p os- sible worl ds and U represents the tuples in these w orlds. As discussed in Example 2.3 , the set of ws-descriptors S = {{ j 7→ 1 } , { j 7→ 7 , b 7→ 4 }} represents the three worlds on which the functional dep endency SSN → NAME holds. cond : conditioning algorithm In: ws-tree R representing th e new nonemp t y wo rld-set, ws-set U from the U-relations Out: (confi d ence va lue, ws-set U ′ ) if R = ∅ then return (1 , U ); if R = N i ∈ I ` R i ´ then foreac h i ∈ I do ( c i , U i ) := cond( R i , U ); return (1 − Q i (1 − c i ) , S i ∈ I U i ); if R = L i ∈ dom x ` x 7→ i : R i ´ then foreac h i ∈ d om x do U i := t h e subset of U consisten t with x 7→ i ; ( c i , U ′ i ) := cond( R i , U i ); c := P i ∈ I P ( { x 7→ i } ) · c i ; let x ′ b e a new vari able; foreac h i ∈ d om x suc h that c i 6 = 0 do add h x ′ , i, P ( { x 7→ i } ) · c i c i to the W relation; replace eac h o ccurrence of x in U ′ i by x ′ ; return ( c, S i ∈ dom x U ′ i ); Figure 8: The conditioning algorithm. The w orld { j 7→ 7 , b 7→ 7 } is ex cluded and thus the confi- dence of S do es not add up to one b ut to . 2 + . 8 · . 3 = . 44. What w e now w ant to do is transform th is database into one that represents t h e three w orlds identified b y S and preserves their tup les as w ell as their relative wei ghts, b ut with a sum of world w eights of one. This can of course be easily achiev ed by multiplying th e weigh t of eac h of the three remaining w orlds by 1/.44. How ever, w e wan t to d o this in a smart wa y t hat in general do es not req u ire to consider each p ossible w orld individ u ally , bu t instead preserves a succinct representa tion of t he data an d ru ns efficientl y . Such a technique exists and is presented in this section. It is based on runn ing our confid ence computation algorithm for ws-trees and , while return in g from the recursion, renor- malizing the w orld-set by introdu cing new v ariables whose assignmen ts are normalized using the confiden ce val ues ob- tained. F or this examp le, th e conditioned database will b e W V ar Dom P b 4 .3 b 7 .7 j ′ 1 .2/.44 j ′ 7 . 8 · . 3 /. 44 U WSD SSN NAME { j ′ 7→ 1 } 1 John { j ′ 7→ 7 } 7 John { j ′ 7→ 1 , b 7→ 4 } 4 Bi ll { j ′ 7→ 1 , b 7→ 7 } 7 Bi ll { j ′ 7→ 7 } 4 Bill Note th at the W relation actu ally models four p ossible worlds, but tw o of them, { j ′ 7→ 7 , b 7→ 4 } and { j ′ 7→ 7 , b 7→ 7 } are equal (contain the same tuples). Example 5.2 wil l show in detail how conditioning w orks. ✷ Figure 8 giv es our efficien t algorithm for conditioning a U-relational database. The inpu t is a U-relational database U WSD A { y 7→ 2 , u 7→ 1 } a 1 { u 7→ 1 , v 7→ 2 } a 2 ∆ W V ar Dom P x ′ 1 .1/.308 x ′ 2 .208/.308 y ′ 1 1 z ′ 1 1 u ′ 1 .35/.65 u ′ 2 .3/.65 v ′ 1 1 ⊗ ⊕ ∅ x ′ . 1 . 308 7→ 1 ⊗ x ′ . 208 . 308 7→ 2 ⊕ ∅ y ′ 1 7→ 1 ⊕ ∅ z ′ 1 7→ 1 ⊕ ⊕ u ′ . 35 . 65 7→ 1 ∅ v ′ 1 7→ 1 ∅ u ′ . 3 . 65 7→ 2 Figure 9: U-relation U , additions ∆ W to the W -relation, and a renormalized w s-tree. and a ws-tree R that describ es the subset of the p ossible w orlds of the database th at we wan t to condition it to. The output is a mo dified U-relational database and, as a by- prod uct, since w e recursiv ely need to comput e confi dences for the renormalization, the confidence of R in the input database. The confidence of R in the output database will of course b e 1. The renormalization works as follow s. The probabilit y of eac h branc h of an inner node n of R is re- w eighted su c h t h at t he probability of n b ecomes 1. W e re- flect this re-weigh ting b y in trod ucing n ew v ariable whose assignmen ts reflect the n ew weigh ts of the branches of n . This algorithm is essen tially th e confidence computation algorithm of Figure 7. W e just add some lines of co de along the line of recursively computing confidence t hat renormal- ize the weigh ts of alternative assig nments of v ariables for whic h some assignments become imp ossible. A dditionally , w e pass around a set of ws-descriptors (associated with tu- ples from the input U-relational d atabase) and ext end each ws-descriptor in that set by x 7→ i wheneve r we eliminate v ariable x , for each of its alternatives i . Example 5.2. Consider the U-relational database con- sisting of th e W -relation of Figure 3 and th e U-relation U of Figure 9. Let us run the algori thm to condition the database on th e ws-tree R of Figure 3 ( R need not b e p recompu ted for conditioning). W e recursively call function cond at each no de in the ws- tree R starting at the ro ot. T o simplify th e explanation, let us assume a num b ering of the no des and of the ws-sets w e pass around: If R w is a (sub)tree then R w,i is its i -th child. The ws-set passed in the recursion with R w is U w and the ws-set returned is U ′ w . The ws-sets passed on at the nod es of R are: U 1 = U 2 = U U 1 , 1 = x 7→ 1 : U = {{ x 7→ 1 , y 7→ 2 , u 7→ 1 } , { x 7→ 1 , u 7→ 1 , v 7→ 2 }} U 1 , 2 = x 7→ 2 : U = {{ x 7→ 2 , y 7→ 2 , u 7→ 1 } , { x 7→ 2 , u 7→ 1 , v 7→ 2 }} U 1 , 2 , 1 , 1 = y 7→ 1 : U 1 , 2 = {{ y 7→ 1 , x 7→ 2 , u 7→ 1 , v 7→ 2 }} U 1 , 2 , 2 , 1 = z 7→ 1 : U 1 , 2 = {{ z 7→ 1 , x 7→ 2 , y 7→ 2 , u 7→ 1 } , { z 7→ 1 , x 7→ 2 , u 7→ 1 , v 7→ 2 }} U 2 , 1 = u 7→ 1 : U 2 = U 2 U 2 , 2 = u 7→ 2 : U 2 = ∅ U 2 , 1 , 1 = v 7→ 1 : U 2 , 1 = {{ v 7→ 1 , y 7→ 2 , u 7→ 1 }} When we reac h the lea ves of R , w e start returning from recursion and do the follo wing. W e first compute the prob- abilities of th e n odes of R – in this case, they are already computed in Example 4.7. Next, for each ⊕ -no de represent- ing the elimination of a v ariable, say α , we create a new v ariable α ′ with the assignments of α present at that no de. In contras t to α , the assignments of α ′ are re-w eighted by t h e probabilit y of th at ⊕ -no de so th at t he sum of their w eigh ts is 1. The new v ariables and their weigh ted assignments are giv en in Figure 9 along the original ws-tree R and in the ∆ W relation to b e added to t he world table W . When we return from recursion, we also compute th e new ws-sets U ′ i from U i . These ws-sets are equ al in case of lea ves and ⊗ -no des, bu t, in case of ⊕ -no des, t he v ariable elimi- nated at th at nod e is replaced by the new one we created. In case of ⊕ and ⊗ no des, we also return the union of all U ′ i of their children. W e finally return from th e fi rst call with the follo wing ws-set U ′ : {{ x ′ 7→ 1 , y 7→ 2 , u 7→ 1 } , { x ′ 7→ 1 , u 7→ 1 , v 7→ 2 } , { x ′ 7→ 2 , y ′ 7→ 1 , u 7→ 1 , v 7→ 2 } , { x ′ 7→ 2 , z ′ 7→ 1 , y 7→ 2 , u 7→ 1 } , { x ′ 7→ 2 , z ′ 7→ 1 , u 7→ 1 , v 7→ 2 } , { u ′ 7→ 1 , v ′ 7→ 1 , y 7→ 2 }} . ✷ Let us view a probabilistic database semanti cally , as a set of pairs ( I , p ) of instances I with probabilit y weigh ts p . Theorem 5.3. Gi ven a r epr esentation of pr ob abilistic da- tab ase W = { ( I 1 , p 1 ) , . . . , ( I n , p n ) } and a ws-tr e e R i dentify- ing a nonempty subset of the worlds of W , the algorithm of Figur e 8 c omputes a r epr esentation of pr ob abilistic datab ase { ( I j , p j c ) | ( I j , p j ) ∈ W , I j ∈ ω ( R ) } such that the pr ob abilities p j add up to 1. Thus, of course, c is th e confid en ce of R . Three simple optimizations of this algori thm that simplify the world table W and the output ws-d escriptors are wo rth mentio ning. 1. V ariables that do not app ear anywhere in the U-relations can b e d ropped from W . 2. V ariables with a single domain v alue (obviously of weigh t 1) can b e dropp ed ever ywhere from the database. 3. V ariables x ′ and x ′′ obtained from the same v ariable x (by creation of a new vari able in the case of vari - able elimi nation on x in t wo distinct branc hes of the recursion) can b e merged into the same va riable if th e alternativ es and their weigh ts in the W relation are the same. In that case we can replace x ′′ by x ′ everywhere in the database. Example 5.4. In the previous example, we can remov e the v ariables y ′ , z ′ , and v ′ from the W -relation and all v ari- able assignmen ts inv olving these v ariables from the U- relation b ecause of ( 1). F urth ermore, we can remov e the vari ables x and z b ecause of (1). The resulting d atabase is U ′ WSD A { x ′ 7→ 1 , y 7→ 2 , u 7→ 1 } a 1 { x ′ 7→ 1 , u 7→ 1 , v 7→ 2 } a 2 { x ′ 7→ 2 , u 7→ 1 , v 7→ 2 } a 2 { x ′ 7→ 2 , y 7→ 2 , u 7→ 1 } a 1 { x ′ 7→ 2 , u 7→ 1 , v 7→ 2 } a 2 { u ′ 7→ 1 , y 7→ 2 } a 1 W ′ V ar Dom P x ′ 1 .1/.308 x ′ 2 .208/.3 08 y 1 . 2 y 2 . 8 u 1 .7 u 2 .3 u ′ 1 .35/.65 u ′ 2 .3/.65 v 1 .5 v 2 .5 Finally , w e state an important prop erty of conditioning (expressed by the assert op eration) useful for query opti- mization. Theorem 5.5. Assert-op er ations c ommute with other as- serts and the op er ations of p ositive r elational algebr a. 6. WS-DESCRIPT OR ELIMINA TION W e next present an alternativ e to ex act probabilit y com- putation u sing ws-trees based on the difference op eration on ws-sets, called here ws-descriptor elimination. The idea is to incremen tally eliminate ws-descriptors from the input ws-set. Given a ws-set S and a ws-descriptor d 1 in S , w e compute tw o ws-sets: the original ws-set S without d 1 , and the ws-set representing the difference of { d 1 } and the fi rst ws-set. The probability of S is then the sum of the probabil- ities of th e tw o computed ws-sets, b ecause the tw o ws-sets are mutex, as stated below by function P w : P w ( ∅ ) = 0 P w ( {∅} ) = 1 P w ( S ) = P w ( { d 2 , . . . , d n } ) + X d ∈ ( { d 1 }−{ d 2 ,...,d n } ) P ( d ) The function P computes here the probability of a ws-descriptor. Example 6.1. Consider the ws-set { d 1 , d 2 , d 3 } of Exam- ple 3.1. The ws-descriptor d 2 is mutex with b oth d 1 and d 3 and w e can eliminate it: P w ( { d 1 , d 2 , d 3 } ) = P w ( { d 1 , d 3 } ) + P ( d 2 ). W e now c ho ose any to eliminate d 3 and obtain P w ( { d 1 , d 3 } ) = P w ( { d 3 } − { d 1 } ) + P ( d 1 ) = P ( d 1 ), as ex- plained in Example 3.3. Thus P w ( { d 1 , d 2 , d 3 } ) = P ( d 2 ) + P ( d 1 ) = 1. ✷ This m eth od exploits the fact that the difference op eration preserves the mutex p roperty and is world-set monotone. Lemma 6.2. T he f ol lowi ng e quations hold for any ws-sets S 1 , S 2 , and S 3 : ω ( S 1 − S 2 ) ⊆ ω ( S 1 ) ω ( S 1 ) ∪ ω ( S 2 ) = ω ( S 1 − S 2 ) ∪ ω ( S 2 ) ∅ = ω ( S 1 − S 2 ) ∩ ω ( S 2 ) ω ( S 1 ) ∩ ω ( S 2 ) = ∅ ⇒ ω ( S 1 − S 3 ) ∩ ω ( S 2 − S 3 ) = ∅ The correctness of probability computation by ws-descriptor elimination follo ws immediately from Lemma 6.2. Theorem 6.3. Gi ven a ws-set S , the function P w c om- putes the pr ob ability of S . As a corollary , we hav e t hat Cor ollar y 6.4 ( Theorem 6.3 ). An y ws-set n S i =1 { d i } has the e quivalent mutex ws-set n − 1 S i =1 ( { d i } − n S j = i +1 { d j } ) ∪ { d n } . Like the t ranslation of ws-sets into ws-trees, th is meth od can tak e exp onential time in the size of th e input ws-set. Moreo ver, the equiv alent m utex ws-set giv en ab ov e can be exp onentia l. On the p ositive side, computing th e exact probabilit y of su ch m utex ws-sets can b e done in linear time. Additionally , the probability of { d } − S d can b e computed on the fly without requiring to first generate all ws-descriptors in the difference ws-set. This foll ow s from the fact that the difference op eration on ws-descriptors only generates mutex and distinct ws-descriptors. After generating a ws- descriptor from the difference ws-set w e can thus add its probabilit y to a running sum and discard it b efore gener- ating the next ws-descriptor. The next section rep orts on exp erimen ts with an implementation of this metho d. 7. EXPERIMENTS The exp eriments were conducted on an A thlon-X2 (4600+) x86-64bit/1.8GB/ Linux 2.6.20/gcc 4.1.2 mac hine. W e considered tw o synthetic data sets. TPC-H data and queries . The fi rst data set consists of tuple-indep endent probabilistic databases obtained from re- lational d atabases pro duced by TPC-H 2.7.0, where each tuple is asso ciated with a Bo olean random v ariable and the probabilit y d istribu tion is chosen at random. W e ev aluated the tw o Bo olean q ueries of Figure 10 on each probabilis- tic database and th en computed the probabilit y of the ws- set consisting of the ws-descriptors of all the answ er t uples. Among the tw o queries, only th e second is safe and thus admits PTIME ev aluation on tuple-ind ep endent probabilis- tic databases [9]. As we rewrite constraints in to Boolean queries, w e consider this q uerying scenario equally relev ant to conditioning. Query Size of TPC-H #Input Size of User ws-desc. Scale V ars ws-set Time(s) Q 1 : select true from customer c, orders o, lineitem l 0.01 77215 9836 5.10 where c.mktsegment = ’BUILDING’ and c.custk ey = o.custkey 3 0.05 382314 43498 99.76 and o.orderkey = l.orderkey and o.orderdate > ’1995-03-15’ 0.10 76 5572 63886 356.56 Q 2 : select true from lineitem 0.01 60175 3029 0.20 where ship date b et ween ’1994-01-01’ and ’1996-01-01’ 1 0.05 299814 15545 8.24 and discount b etw een ’0.05’ and ’0.08’ and quantit y < 24 0.10 60 0572 30948 33.68 Figure 10: TPC-H s ce nario: Queries, data char acteristics, and pe rformance of IND V E(minlog). 0.01 0.1 1 10 100 1000 50k 25k 10k 5k 2k 1k time in sec (ln scale) Size of ws-set (ln scale) Few variables (100), many ws-descriptors, r=4(2), s=4 kl(e.01) indve kl(e.1) ve 0.01 0.1 1 10 100 1000 6.0k 2.5k 1.0k 0.5k 0.2k 0.1k time in sec (ln scale) Size of ws-set (ln scale) Many variables (100k), few ws-descriptors, r=4, s=2 kl(e.01) kl(e.1) indve (a) (b) Figure 11: The tw o cases when the n umbers of v ariables and of w s -descriptors diffe r by orders of magnitude. #P-hard cases . The second data set consists of ws-sets similar to those associated with the answers of n onhierarc hi- cal conjun ctiv e q ueries without self-joins on tuple-ind epend en t probabilistic d atabases, i.e. join queries suc h as Q s = R 1 ✶ · · · ✶ R s for sc hemas R i ( A i , A i +1 ) in which all relations are joined together, but there is n o single column common to all of them. Such queries are kn o wn t o be #P-hard [9 ]. The d ata generation is simple: w e partition the set of v ariables in to s equally-sized sets V 1 , . . . , V s and t hen sample ws-sets { x 1 7→ a 1 , . . . , x s 7→ a s } where x i is from V i and a i is a random alternative for x i , for 1 ≤ i ≤ s . It is easy to verif y that each such ws-set is actually the result of qu ery Q s on some tuple-ind ep endent probabilistic database. (F or s = 3 this fact is u sed in the #P-h ardness proof of [9].) W e use th e follo wing parameters in our ex periments: num- b er n of var iables ranging from 50 to 100K, num b er r of p ossible alternatives per va riable (2 or 4), length s of ws- descriptors, which equals t h e number of joined relations (2 or 4), and number w of ws-d escriptors ranging from 5 to 60K. F or each vari able, the alternativ es ha ve uniform probabili- ties 1 /r : our exact algorithms are not sensitive t o changing probabilit y v alues as long as the num b ers of alternativ es of the v ariables remain constan t. Note that the focus on Bo olean qu eries means no loss of generalit y for confid ence computation; rather, the pro jection of a query result to a nullary relation causes all the ws-sets to b e unioned and large. Algorithms . W e exp erimentally compared three versions of our exact alg orithm: one t h at emp lo y s indep endent parti- tioning and vari able elimination (INDVE), one that employs v ariable elimination only (VE), and one with ws-descriptor elimination (WE). W e considered INDVE with the tw o h eu- ristics minlog and minmax. These implementatio ns compute confidence val ues and th e mo dified world table (∆ W in Ex - ample 5.2), but do not materialize the m o dified, conditioned U-relations ( U ′ in Examp le 5.2). W e hav e verified that the computation of these additional data structures adds only a small ov erhead ov er confi dence computation in p ractice. W e therefore do not distinguish in the sequel b etw een confi- dence compu tation and conditioning. Note that our imple- mentatio n is b ased on t he straigh tforw ard comp osition of the ComputeT ree and cond itioning algorithms and do es n ot need to materialize the ws-trees. Although w e also implemented a brute-force algorithm for probabilit y compu t ation, its timing is extremely bad and n ot rep orted. At a glance, this algorithm iterates ove r all worl ds and sums up t he probabilities of those that are represented by some ws-descriptors in the inp ut ws-set. W e also tried a slight improv emen t of the b rute-force algorithm by first partitioning the input ws-set into indep endent subsets [22]. This version, to o, p erformed bad and is n ot rep orted, as the partitioning can only b e applied once at t he b eginning on the whole ws-set, yet m ost of our input ws-sets only exhibit indep endence in the context of v ariable eliminations. W e exp erimental ly compared IN D VE against a Monte Carlo simulation algorithm for confidence computation [21, 9] which is based on the K arp- Luby (KL) fully p olyno- mial rand omized appro ximation scheme (FPRAS ) for DNF counting [17]. Given a DNF form u la with m clauses, the base algorithm compu tes an ( ǫ, δ )-approxima tion ˆ c of the num ber of solutions c of th e DNF form ula such t h at Pr[ | c − ˆ c | ≤ ǫ · c ] ≥ 1 − δ for any giv en 0 < ǫ < 1, 0 < δ < 1. It do es so within ⌈ 4 · m · log (2 /δ ) /ǫ 2 ⌉ iterations of an efficiently computable estimator. This algorithm can b e easily t urned into an ( ǫ, δ )- FPRAS for tuple confidence comp u tation (see [19]). I n our exp erimen ts, w e use th e optimal Monte-Carlo estimation al- gorithm of [8]. This is a technique to determine a small suf- ficient number of Monte-Carlo iterations (within a constant factor from optimal) based on first collecting statistics on the input by run ning the Monte Carlo sim u lation a small n um- b er of times. W e use the version of the Karp-Luby unbiased estimator describ ed in the b o ok [24], which conv erges faster than the basic algori thm of [17], adapted to the problem of 0.01 0.1 1 10 100 1000 10000 5000 825 500 200 90 5 time in sec (ln scale) Size of ws-set (ln scale) Number of variables close to ws-set size, 70 variables, r=4, s=4 indve(ymax) indve(median) kl(e.001) indve(ymin) Figure 12: P erformance of INDVE and KL when n umbers of v ariables and ws-descriptors are close. computing confid ence v alues. This algorithm is similar to the self-adjusting cov erage algorithm of [18]. 1. Querie s on TPC-H data. Figure 10 shows that IN - DVE(minlog) p erforms within hundreds of seconds in case of queries with equi-joins ( Q 1 ) and selection-pro jection ( Q 2 ) on tuple-indep endent probabilistic TPC-H databases with ov er 700K v ariables and 60K ws-descriptors. In the answ ers of query Q 2 , ws-descriptors are p airwis e indep endent, and IN- DVE can effectively employ indep endence partitition, mak- ing confidence compu tation more efficien t than for Q 1 . The remaining exp eriments use t he second data generator. 2. T he numbers of v ariables and of ws-descriptors differ by orders of magnitude. If there are muc h more ws-descriptors than v ariables, man y ws-descriptors share v ari- ables ( or v ariable assignments) and a goo d c hoice for v ari- able elimination can effectively partition the ws-set. On the oth er hand, indep endence partitioning is un lik ely to be very effectiv e, and the time for chec king it is w asted. Fig- ure 11(a) sho ws that in such cases VE and INDVE (with minlog heuristic) are very stable and not infl u enced by fluc- tuations in data correlations. In particular, V E performs b etter than INDVE and within a second for 100 v ariables with domain size 4 (an d nearly th e same for 2), ws-descriptors of length 4, and ws-set size ab o ve 1.2k. W e witnessed a sharp hard-easy transition at 1.2k, which suggests that the com- putation b ecomes harder when t he num b er of ws-descriptors falls under one order of magnitude greater than th e number of v ariables. Exp eriment 3 studies easy-h ard-easy transi- tions in more detail. The plot data were prod uced from 25 runs and record th e med ian va lue and y min/ymax for the error bars. In case of many v ariables and few ws-descriptors, t he in- dep endence partitioning clearly pays off. This case n atu- rally o ccurs for qu ery ev aluation on probabilistic databases, where a small set of tuples ( and th us of ws-descriptors) is se- lected from a large database. As shown in Figure 11(b), IN- DVE(minlog) p erforms within seconds for the case of 100K v ariables and 100 to 6K ws-descriptors of size s = 2, and with v ariable domain size r = 4. Two further findings are not shown in the fi gure: (1) V E p erforms much worse than INDVE, as it cannot exploit the indep endence of tup les and thus creates partitions th at o verlap at large; (2) th e case of s = 4 has a few (2 in 25) outliers exceeding 600 seconds. 3. T he numbers of v ariables and of ws-descriptors are close . It is known from literature on knowledge compi- 0.01 0.1 1 10 100 1000 500 200 100 50 time in sec (ln scale) Size of ws-set (ln scale) INDVE heuristics; 100K variables, r=4(2), s=4 minmax minlog Figure 13: Heuristics: minmax versus minl og. lation and mo del coun ting [6 ] th at the computation becomes harder in th is case. Figure 12 sho ws the easy-hard-easy pattern of INDVE(minlog) b y plotting the minimal, maxi- mal, and median computation time of 20 runs (max allo wed time of 9000s ). W e exp erimentally observed the exp ected sharp transitions: W hen the num bers of ws-descriptors and of v ariables b ecome close, the computation b ecomes hard and remains so u n til the num ber of ws-descriptors b ecomes one ord er of magnitude larger than the num b er of v ariables. The beh avior of WE (not shown in the figure) follow s very closely the easy-hard transition of INDVE, but in our exper- iment WE d oes not return anymore to the easy case within the range of ws-set sizes rep orted on in the figure. 4. Exact versus appro ximate computation . W e ex- p erimen tally verified our conjecture t h at the Karp-Lu b y ap- proximati on algo rithm (KL) converge s rath er slo wly . In case the num b ers of v ariables and of ws-descriptors differ by or- ders of magnitude, INDVE(minlog ) and VE(minlog) are def- initely competitive when compared to KL with parameters ǫ = 0 . 1 resp. ǫ = 0 . 01, and δ = 0 . 01, see Figure 11 . In Figure 11(b), KL uses ab out t h e same number of itera- tions for all the ws-set sizes, a sufficient num b er to wa rrant the runn ing time. The reason for th e near-constant line for KL is that for s = 2 and 100k v ariables, ws-descriptors are predominantly pairwise indep en dent, and th e confidence is close to 1 − (3 / 4) w , where w is the num ber of ws-descriptors. But th is qu ic kly gets close to 1, and the optimal algorithm can decide on a small num b er of iterations that does n ot increase with w . In case the num bers of v ariables and ws- descriptors are close (Figure 12), KL with ǫ = 0 . 001 only p erforms b etter than INDVE(minlog) in the hard cases. 5. Heuristics for v ariable eli mination . Figure 13 show s that, although the minmax heu ristic is cheaper to compute than the min log heuristic, using minlog we find in general b etter c hoices of v ariables and INDVE remains less sensitive to data correlations. The p lot data are produced from 10 runs and sho w th e median va lue and ymin/ymax for t h e error b ars. A lthough VE exceeds the allo cated time of 600 seconds for different data p oin ts, it d o es this less than five times (the median v alue is closer to ymin) . 8. RELA TED WORK T o the b est of our knowledge, this p ap er is th e first t o study th e conditioning problem for p robabilistic databases. In th is section, we survey related wo rk in th e areas of prob- abilistic databases and kn o wledge compilation pro cedures. U-relations captu re most other representation formalisms for uncertain data that w ere recently prop osed in th e litera- ture, includ ing those of MystiQ [9], T rio [5], and MayBMS [3]. F or eac h of these formalisms, natural ap p lications in data cleaning and other areas ha ve b een d escribed [5 , 4, 9 ]. Graphical mo d els are a class of ric h formalisms for rep- resen ting probabilistic in formation which p erform wel l in scenarios in whic h cond itional probabilities and a known graph of dep endencies and indep endences b etw een even ts are av ailable. There are, for instance, Ba yes ian netw ork learning algorithms that p roduce just such data. U nfortu- nately , if probabilistic data is obtained by q ueries on tu ple- indep endent or similar databases, the correspond ing graph- ical models tend to b e relative ly flat [23] but hav e high tree-width, which causes techniques widely used for confi- dence compu tation on graphical mo d els to b e highly ineffi- cien t. Graphical mo dels are more succinct t han U-relations, yet th eir succinctness d o es n ot b enefit the currently known query ev aluation techniques. This justifies the developmen t of conditioning techniques sp ecifically for the c- t able-lik e representa tions (such as U-relations) developed by the data- base communit y . It has been long known t h at compu ting t uple confiden ce v alues on DN F-lik e represen tations of sets of p ossible worl ds is a generalization of the DNF mo del counting problem and is #P- complete [10]. Monte Carlo approximation t ec hniques for confidence computation ha ve b een k no wn since t he orig- inal work by Karp, Luby , and Madras [18]. Within the database field, th is approach has fi rst b een follo w ed in work on query reliabilit y [14] and in the MystiQ p ro ject [9]. S ec- tion 7 rep orts on an exp erimenta l comparison of approxima- tion and our exact algorithms. Our v ariable elimination technique is based on Da vis-Put- nam pro cedure for satisfiability chec king [12]. This pro- cedure w as already used for mo del counting [6]. Our ap- proac h combines it with indep endent partitioning for ef- ficiently solving tw o more difficult p roblems: ex act confi - dence comp u tation and conditioning. [6] uses the minmax heuristic (whic h w e b enchmark against) and discusses ex- p erimen ts for CNF formulas with up to 50 v ariables and 200 clauses only . Our ex periments also discuss new settings that are more natural in a database context: for instance, when the size of a query answ er (and th us the number of ws-descriptors) is small in comparison to th e size of the in- put database (and thus of v ariables). F ollo w-up work [15 ] rep orts on techniques for compiling ws-sets generated by conjunctive queries with inequalities into decision diagrams with p olynomial-time guarantees. Finally , there is a strong connection b etw een ws-trees and ordered binary d ecision diagrams (OBDDs). Both make the structure of the propositional formulas ex plicit and allo w for efficien t manipulation. They differ, ho we ver, in imp ortan t aspects: binary versus multistate v ariables, same vari able ordering on all paths in case of OBDDs, and the n ew ws- tree ⊗ - node t yp e, which makes indep endence exp licit. It is p ossible to reduce the gap b etw een th e tw o formalisms, but this affects the representation size. F or instance, different v ariable orderings on different paths allo ws for exponentially more succinct BDDs [20 ]. Multistate v ariables can b e easily translated in to binary v ariables at a price of a logarithmic increase in the number of v ariables [25 ]. 9. REFERENCES [1] S. Abiteb oul, P . Kanellakis, and G. Grahne. “On the Represen tation and Querying of Sets of P ossible W orlds”. The or. Comput. Sci. , 7 8 (1):158– 187, 1991. [2] P . Andritsos, A. F uxman, and R. J. Mill er. “Clean Answers o ver Di rt y D ataba ses: A Pr obabili stic Approach”. In Pr o c. ICDE , 2006. [3] L. Ant ov a, T. Jansen, C. Ko c h, and D. Ol tean u. “F ast and Simple Relational Pr ocessing of Uncertain Data”. In Pr o c. ICDE , 2008. [4] L. Ant ov a, C. K och, and D. Olteanu . “10 10 6 W orl ds and Bey ond: Efficient Representation and Pro cessing of Incomplete Information”. In Pr o c . ICDE , 2007. [5] O. Benjelloun, A. D . Sarma, A. Halevy , and J. Widom. “ULDBs: Databases with Uncertaint y and Lineage”. In Pr o c . VLDB , 2006. [6] E. Birnbaum and E. Lozinskii. “The Go od Old Da vis-Putnam Pr ocedure Helps Coun ting Mo dels”. Journal of AI R ese ar ch , 10 (6):457–477, 1999. [7] R. E. Bryan t. Graph-based algori thms for b o olean function manipulation. IEEE T r ans. Computers , 35(8):677–691, 1986. [8] P . Dagum, R. M. K arp, M . Luby , and S. M. Ross. “An Optimal Algori thm for M on te Car lo Estimation”. SIAM J. Comput. , 29 (5):1484–1496, 2000. [9] N. Dalvi and D. Suciu. “Efficien t query ev aluation on probabilistic databases”. VL DB Journal , 16 (4):523–544, 2007. [10] N. Dalvi and D . Suciu. “Managemen t of Probabilistic Data: F oundations and Challenges”. In Pr o c . PODS , 2007. [11] A. Darwiche and P . Marquis . “A kno wlege compilation map”. Journal of AI R ese ar ch , 17:229–264, 2002. [12] M. Davis and H . Putnam. “A Computing Pro cedure for Quan tification Theory”. Journal of ACM , 7 (3):201–215, 1960. [13] N. F uhr and T. R¨ olleke . “A Pr obabilistic Relational Algebra for the Integrat ion of Information Retri ev al and Database Systems”. ACM T r ans. Inf. Syst. , 15 (1):32– 66, 1997. [14] E. Gr¨ ade l, Y. Gurevich, and C. Hir sc h. “The Complexity of Query Reliabili t y”. In Pr o c . PODS , pages 227–234, 1998. [15] J. Huang and D. Ol tean u. Conjunctiv e queries with inequalities on probabilis tic databases. T echnical rep ort, Unive rsity of Oxford, 2008. [16] T. Imielinski and W. Li pski. “Incomplete i nformation in relational databases”. Journal of ACM , 31 (4):761–791, 1984. [17] R. M. Karp and M. Luby . “Mont e-Carlo Al gorithms f or En umeration and Reliability Problems”. In Pr o c. F OCS , pages 56–64, 1983. [18] R. M. Karp, M. Lub y , and N. M adras. “Monte-Carlo Approx imation Al gori thms for E numeration Problems”. J. Algo rithms , 10 (3):429– 448, 1989. [19] C. Koch. “Approximating Predicates and Expressive Queries on Pr obabilistic Databases”. In Pr o c. PODS , 2008. [20] C. Meinel and T. Theobald. Algo rithms and Data Structur es in VLSI Design . Springer-V erlag, 1998. [21] C. Re, N. Dalvi , and D. Suciu. Efficient top-k query ev aluation on probabilistic data. In Pr o c. ICDE , pages 886–895, 2007. [22] A. D. Sarma, M. Theobald, and J. Widom. “Exploiting Lineage for Confidence Computation in Uncertain and Probabilistic Databases”. In Pr o c. ICDE , 2008. [23] P . Sen and A. Deshpande. “Represen ting and Queryi ng Correlated T uples in Probabilistic Databases”. In Pr o c. ICDE , pages 596–605, 2007. [24] V. V. V azirani. Appr oximation Algorithms . Spri nger, 2001. [25] M. W ach ter and R. Haenni. “Multi-state Dir ected A cyclic Graphs”. In Pr o c. Canadian AI , pages 464–475, 2007. APPENDIX Pr oof of Theore m 4.4 W e p ro ve that the translation from ws-sets to ws-trees is correct. That is, given a ws-set S , ComputeT ree( S ) and S represent the same w orld- set. W e use induction on the structure of ws-trees. In the base case, w e map ws-sets representing the empty world-set to ⊥ , and ws-sets containing the universal ws-descriptor ∅ (that represents the whole world-set) to ∅ . W e consider now a ws-set S . W e ha ve tw o cases corresp onding to the different types of ws-tree inner nodes. Case 1. A ssume S = S i ∈ I S i with S i pairwise indepen dent and R i = ComputeT ree( S i ). By hyp othesis, ω ( R i ) = ω ( S i ). Then, ComputeT ree( S ) = N i ∈ I ( R i ) and ω (ComputeT ree( S )) = S i ∈ I ω ( R i ) = S i ∈ I ω ( S i ) = ω ( S ) . Case 2. Let x be a v ariable in S and consider the ws- sets S x 7→ i ( i ∈ dom x ) and T as given by ComputeT ree. Because the whole world-set can be rep resen ted by A = S i ∈ dom x {{ x 7→ i }} , it holds that ω ( A ) ∩ ω ( S ) = ω ( S ). W e push the assignmen ts of x in eac h ws-descriptor of S and obtain ω ( S ) = ω ` [ i ∈ dom x { d ∪ { x 7→ i } | d ∈ S } ´ . W e can remo ve all inconsistent ws-descriptors in the ws-set of the right-hand side while preserving equiv alence: ω ( { d ∪ { x 7→ i } | d ∈ S } ) = ω ( { d ∪ { x 7→ i } | d ∈ S, 6 ∃ j ∈ d om x : j 6 = i, { x 7→ j } ⊆ d } ) = ω ( { d ∪ { x 7→ i } | { x 7→ i } ⊆ d ∈ S } ) ∪ ω ( { d ∪ { x 7→ i } | d ∈ S, 6 ∃ j ∈ d om x : { x 7→ j } ⊆ d } ) = ω ( S x 7→ i ) ∪ ω ( T ) = ω ( S x 7→ i ∪ T ) W e no w consider all v alues i ∈ dom x and obtain ω ( S ) = ω ` [ i ∈ dom x ( S x 7→ i ∪ T ) ´ = ω ` M i ∈ dom x x 7→ i : ( S x 7→ i ∪ T ) ´ . Pr oof of Theore m 5.3 W e prove th at given a rep resentation of probabilistic d ata- base W = { ( I 1 , p 1 ) , . . . , ( I n , p n ) } and a ws-tree R identify- ing a nonemp ty sub set of the wo rlds of W , t he algorithm of Figure 8 computes a representation of probabilistic database { ( I j , p j c ) | ( I j , p j ) ∈ W , I j ∈ ω ( R ) } such that the probabilities p j add up to 1. The cond itioning algorithm computes the probability c of eac h no de of the input ws-tree R as giv en b y our probabil- it y computation algorithm of Figure 7. W e next consider the correctness of renormalization using indu ction on th e structure of the input ws-tree. Base case: The ws-tree ∅ represents the whole w orld-set and w e thus return U u nc hanged (no conditioning is done). Induction cases ⊗ (indep endent partitioning) and ⊕ (v ari- able elimination). F or b oth n ode types, we return the union of ws-sets U ′ i that are the ws-sets U i ⊆ U where the va riables encountered at the no des on t he recursion path are replaced by new ones. The ws-sets U i are the subsets of U consis- tent with each child of the ⊕ or ⊗ no de. By hyp othesis, the ws-sets U i are conditioned correctly . In case of ⊗ - nodes, no further conditioning is done, because no re-wei ghting tak es place. In case of a ⊗ - n ode, we re-weigh t the assignmen ts of the v ariable eliminated at that n ode. Let I ⊆ dom x b e t h e set of alternativ es of x presen t at that no d e. Since P ( R ) = P ` M i ∈ I ( x 7→ i : R i ) ´ = X i ∈ I P ( { x 7→ i } ) · P ( R i ) , if w e create a n ew va riable x ′ , P ( { x ′ 7→ i } ) := P ( { x 7→ i } ) · P ( R i ) P ( R ) . This guaran tees th at P ` M i ∈ I ( x ′ 7→ i : R i ) ´ = 1 . If w e ask whic h tuples of U should b e in an instance satisfying R , t h e answe r is of course all th ose whose ws- descriptors are consisten t with one of the ws-descriptors in x 7→ i : R i for some i ∈ I . The U -relation tuples in the results of the inv ocations cond( R i , U i ) grant exactly th is.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment