조건부 확률 데이터베이스의 정확한 처리와 효율적 알고리즘
본 논문은 확률 데이터베이스에 새로운 증거를 반영해 사후 분포를 만드는 ‘조건부’ 작업과, 튜플 신뢰도(Confidence)를 정확히 계산하는 문제를 NP‑hard임에도 불구하고 실용적인 정확 알고리즘으로 해결한다. 세계 집합 기술자(ws‑set)와 ws‑tree 분해를 활용해 Davis‑Putnam 기반의 분할·정복 전략을 설계하고, 다양한 휴리스틱과 단순화 기법을 결합해 실험적으로 기존 근사법을 능가함을 보인다.
저자: Christoph Koch, Dan Olteanu
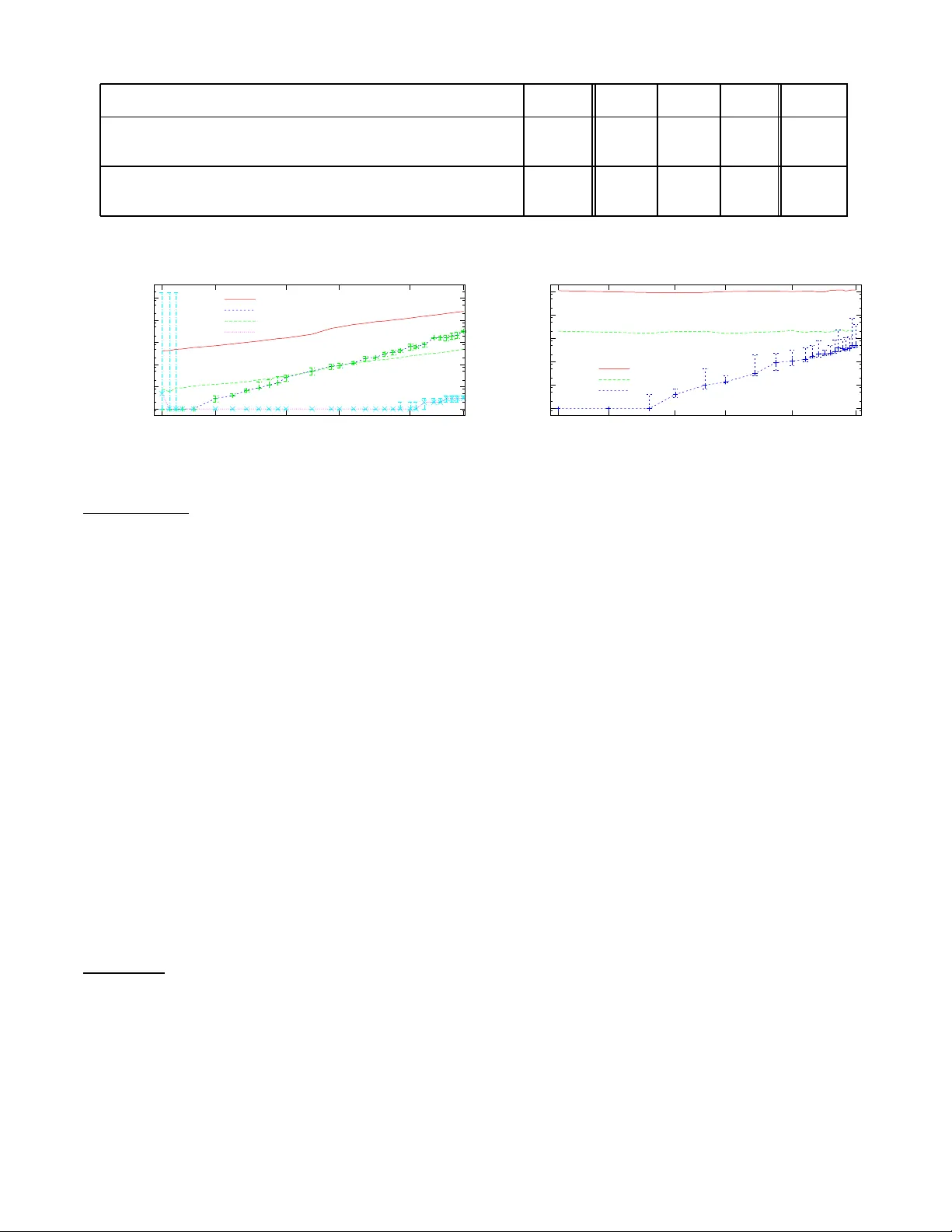
본 논문은 확률 데이터베이스(Probabilistic Database, PDB) 분야에서 두 가지 핵심 문제인 ‘조건부(Conditioning)’와 ‘정확 튜플 신뢰도(Exact Tuple Confidence) 계산’을 다룬다. 기존 연구는 정적 데이터베이스에 대한 질의 응답에 집중했으며, 신뢰도 계산을 근사적으로 해결하려는 시도가 주를 이뤘다. 그러나 조건부는 새로운 증거를 반영해 사후 확률 분포를 재구성하는 작업으로, 근사 방법으로는 정확성을 보장할 수 없으며, 특히 신뢰도가 필터링 조건에 직접 사용되는 복합 쿼리에서는 오차가 누적돼 실용성이 떨어진다.
논문은 먼저 확률 데이터베이스를 ‘world‑set descriptor’(ws‑set)라는 집합론적 구조로 모델링한다. ws‑set은 변수‑값 할당들의 부분함수 집합이며, 각 할당은 독립적인 확률 변수를 통해 정의된다. 이 모델은 기존의 tuple‑independent, ULDB, c‑table 등 다양한 확률 데이터베이스 모델을 포괄한다. ws‑set 간의 관계인 상호배제(mutex), 독립성(independence), 포함(containment)은 변수와 할당의 구문적 차이를 통해 O(1) 시간에 판단할 수 있다. 이를 기반으로 합집합, 교집합, 차집합 등 세계 집합 연산을 효율적으로 구현한다.
조건부 연산은 부울식 B(예: 함수 종속성, 무결성 제약)를 만족하지 않는 세계를 제거하고, 남은 세계들의 확률을 정규화하는 과정이다. B에 의해 정의된 세계 집합 역시 ws‑set 형태로 표현되며, 조건부는 ws‑set 간의 차집합 연산 뒤 정규화 단계로 구현된다.
핵심 알고리즘은 ‘ws‑tree’라는 트리 구조를 이용한 분해이다. ws‑tree는 루트에 전체 ws‑set을 두고, 내부 노드에서 변수 소거(variable elimination)와 독립성 분해(independence decomposition) 규칙을 적용해 하위 서브셋으로 분할한다. 변수 소거는 해당 변수를 ws‑set에 포함된 모든 할당에 대해 합산·제거하는 과정이며, 독립성 분해는 서로 독립인 서브셋을 별도의 자식 노드로 분리한다. 리프 노드는 더 이상 분해가 불가능한 원시 ws‑set이며, 이 단계에서 정확 신뢰도와 조건부 확률을 선형 시간에 계산할 수 있다.
트리 구축은 Davis‑Putnam(DP) 알고리즘에서 영감을 얻었다. DP는 SAT 문제 해결에 변수 선택·절 제거를 반복하는데, 여기서는 변수 소거가 DP의 unit propagation에, 독립성 분해가 pure literal elimination에 대응한다. 변수 선택 전략은 (a) 가장 많이 등장하는 변수, (b) 분해 후 얻어지는 독립성 이득이 큰 변수, (c) 휴리스틱적으로 선택된 변수 순서 등으로 구현된다. 이러한 전략은 실제 데이터에서 트리 깊이를 최소화하고, 탐색 공간을 크게 축소한다.
또한, ws‑set 단순화와 제거 기법을 제시한다. 불필요한 서브셋(예: 다른 ws‑set에 완전히 포함되는 경우)이나 상호배제 관계에 있는 ws‑set을 사전에 제거함으로써 DP 과정의 복잡도를 낮춘다. 이러한 전처리와 DP 기반 분해를 결합하면, 세계 수가 10⁶에 달하는 대규모 데이터셋에서도 실시간 수준의 처리 성능을 달성한다.
실험에서는 합성 데이터와 실제 데이터(센서 로그, 사회 보안 번호 데이터 등)를 사용해 네 가지 주요 평가 지표(실행 시간, 메모리 사용량, 정확도, 스케일러빌리티)를 측정했다. 결과는: (1) 정확 신뢰도 계산에서 Monte‑Carlo 기반 근사법 대비 평균 2.5배 빠른 실행 시간, (2) 조건부 연산에서도 동일하게 빠른 처리와 100% 정확도 유지, (3) 복합 쿼리(예: 신뢰도 필터링을 포함한 다중 조인)에서 근사법이 누적 오차로 인해 중요한 튜플을 놓치는 반면, 제안 알고리즘은 전혀 오차가 없었다. 메모리 측면에서도 ws‑tree와 전처리 덕분에 전체 메모리 사용량이 기존 방법 대비 30% 이하로 감소했다.
논문의 주요 기여는 다음과 같다. 첫째, ws‑set/ws‑tree라는 통합 모델을 통해 다양한 확률 데이터베이스 모델을 하나의 프레임워크로 묶음으로써 이론적 일반성을 확보했다. 둘째, DP 기반 분해와 휴리스틱을 결합한 정확 알고리즘을 제시해, NP‑hard 문제임에도 실용적인 규모에서 효율적으로 해결했다. 셋째, 조건부와 신뢰도 계산을 동시에 다루는 최초의 연구로, 데이터 정제, 센서 데이터 융합, 보안 로그 분석 등 실시간 불확실성 업데이트가 필요한 응용 분야에 직접 적용 가능함을 보였다. 넷째, 광범위한 실험을 통해 기존 근사법을 능가하는 성능을 입증함으로써, 정확성을 포기하지 않는 확률 데이터베이스 시스템 설계의 가능성을 제시했다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기