Local additive estimation
Additive models are popular in high--dimensional regression problems because of flexibility in model building and optimality in additive function estimation. Moreover, they do not suffer from the so-called {\it curse of dimensionality} generally aris…
Authors: Juhyun Park, Burkhardt Seifert
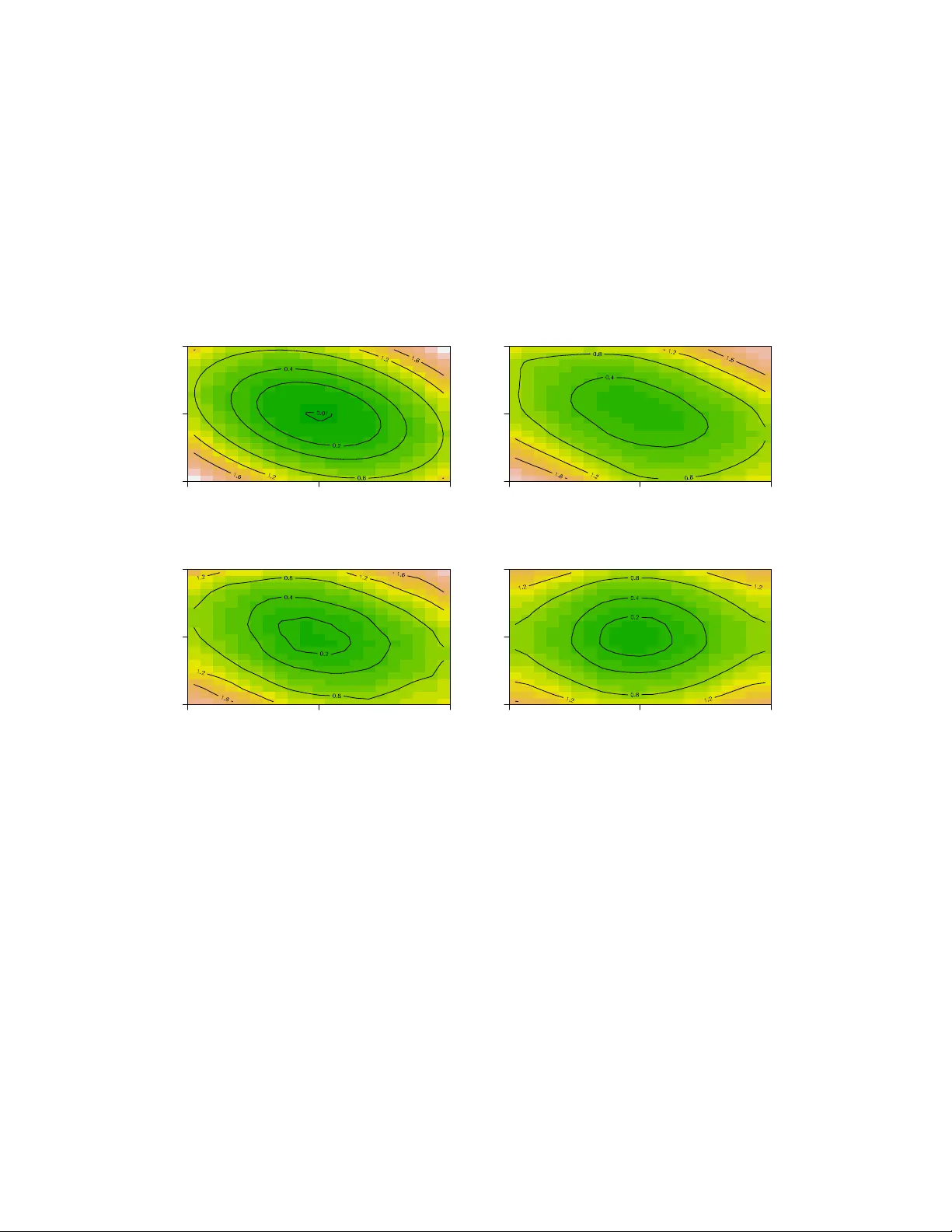
Lo cal additiv e estimation Juh yun P ark and Burkhardt Seifert ∗ Lancaster Univ ersit y and Univ ersit y of Z ¨ uric h June 30, 2021 Abstract Additiv e mo dels are p opular in high–dimensional regression problems b e- cause of flexibilit y in mo del building and optimality in additive function esti- mation. Moreov er, they do not suffer from the so-called curse of dimensionality generally arising in nonparametric regression setting. Less known is the mo del bias incurring from the restriction to the additiv e class of models. W e intro- duce a new class of estimators that reduces additive mo del bias and at the same time preserv es some stability of the additive estimator. This estima- tor is shown to partially relieve the dimensionality problem as well. The new estimator is constructed by lo calizing the assumption of additivit y and thus named lo c al additive estimator . Implementation can b e easily made with an y standard soft w are for additiv e regression. F or detailed analysis we explicitly use the smo oth backfitting estimator b y Mammen, Lin ton and Nielsen (1999). ∗ Juh yun P ark w as P ostdo ctoral Researc h F ellow (Email: juhyun.p ark@lanc aster.ac.uk ), Burkhardt Seifert is Professor (Email: seifert@ifspm.uzh.ch ) in Biostatistics unit, Institute for So cial and Pre- v en tive Medicine, Univ ersity of Z ¨ uric h, Z¨ urich, Switzerland. F unding for this work was provided by Swiss National Science F oundation grant 20020-103743. 1 KEY WORDS: Nonparametric regression, additiv e mo dels, backfitting, lo cal p olynomial smo othing. 1 In tro duction Application of additiv e models is n umerous from econometrics, so cial sciences to en vironmental sciences (Deaton and Muellbauer 1980; Hastie and Tibshirani 1990). Separabilit y of eac h comp onen t is w ell suited for flexible and interpretable mo del building in modern high dimensional problems with man y co v ariates. The main adv an tage of additive regression is that it allo ws us to deal with high-dimensional regression in one-dimensional precision. Since the recognition of p otential of additiv e mo dels in 80s, several additive esti- mators ha ve b een dev elop ed in v arious con texts of smo othing. Earlier metho ds tend to b e more algorithmic in nature b ecause of nontrivial analyses required to under- stand the b eha viour of estimators (see Opsomer and Rupp ert 1997; Opsomer 2000). More recent metho ds include marginal integration b y Lin ton and Nielsen (1995) and smo oth backfitting b y Mammen, Lin ton and Nielsen (1999). The smo oth backfitting estimator (SBE) is shown to b e oracle optimal for the additiv e function estimation, that is, it ac hiev es the same precision as in one–dimensional regression. The SBE is also applicable when additivit y is only appro ximately v alid b y means of a pro jection idea (Mammen et al. 2001). Less kno wn is the mo del bias incurring from the restriction to the additiv e class of mo dels. Additive mo dels miss imp ortan t (nonadditive) features by considering the nonadditiv e part nuisance or noise. This is also related to the fact that fitting additiv e mo dels and diagnostics are less trivial in that it in v olves v arious issues concerning mo del selection and stabilit y (Breiman 1993). Mo dels without additive restriction fall in the broad category of nonparametric 2 regression mo dels. Their prop erties ha ve b een well established in sev eral earlier works, one of whic h p oin ts out that lo cal linear estimator is minimax optimal in more than one–dimensional regression problem (F an et al. 1997). Ho wev er, as the dimension of the v ariables grows, the stability of the estimation b ecomes increasingly an issue, whic h brings ab out curse of dimensionality (see, e.g. Stone 1980, 1982). This situation leads to the question whether or how to combine adv an tages of those estimators, the stabilit y of additive estimator and the optimalit y of lo cal linear one. The approac h prop osed in Studer et al. (2005) uses p enalt y to the nonadditive part, whic h pro duces a family of r e gularise d estimators. In this pap er, w e introduce another class of estimators by lo c alizing the additivit y assumption and this will b e named lo c al additive estimator . Let ( X , Y ) b e random v ariables of dimensions d and 1, resp ectively and let ( X i , Y i ) , i = 1 , · · · , n, b e indep enden t and iden tically distributed random v ariables from ( X , Y ). Denote the design density of X by f ( x ). W e assume that X has com- pact supp ort [ − 1 , 1] d . The regression function r ( x ) = E [ Y | X = x ] is assumed to b e smo oth. The additive mo del has the relation r ( x ) = r 0 + r 1 ( x 1 ) + · · · + r d ( x d ) . (1) This is a global assumption on the shap e of the regression function and thus quite restrictiv e. Giv en x , consider a w -neigh b orho o d of x . If || w || is small enough, b y T a ylor theorem, w e would hav e r ( x ) ≈ r 0 + r 1 ( x 1 ) + · · · + r d ( x d ) . Note that this is not an assumption on the mo del. The accuracy of the approxima- tion clearly dep ends on the w -neigh b orho o d. W e will call this appro ximate additiv e relation lo c al additivity . 3 The ab ov e argumen t naturally leads to an estimator that can b e constructed from additiv e estimator using data in the neighborho o d of in terest. F or a given p oin t x 0 , construct an additiv e estimator using data in the w -neighborho o d of x 0 . The new estimator is defined as the predictor of the additiv e estimator at x = x 0 . This will b e termed lo c al additive estimator , denoted by ˆ r ladd ( x 0 ). A formal definition is given in Section 2. By not directly imp osing the additiv e restriction, w e reduce mo del bias. On the other hand, the merit of additivit y that allows us to deal with high–dimensional regression in one–dimensional precision is partially lost. The main adv an tages of the new estimator can b e summarized as follo ws. 1) Additivit y is approximately v alid lo c al ly ev en when the true regression function is not additive. This helps keep bias small for general regression function. 2) The lo cal additiv e appro ximation is more flexible than the lo cal linear one. Th us, the lo cal region for the additiv e estimator can b e chosen larger than that for the lo cal linear one, which improv es v ariance of the estimator. 3) Standard soft ware for additive estimators is directly applicable. The pap er is organized as follo ws. W e formulate main results in Section 2, follo wed b y asymptotic comparison to the lo cal linear estimator, ˆ r ll , and the additiv e estimator, ˆ r add as an illustration. Smoothing parameter selection is also discussed. Numerical studies are found in Section 3 with an application to a real data example. An extended v ersion of sim ulation studies and some pro ofs of Section 2.5 are found in P ark and Seifert (2008). 4 2 Lo cal additiv e estimation 2.1 Preliminaries Let x 0 b e a fixed in terior output p oint. F or w = ( w 1 , · · · , w d ), we apply an additive estimator ˆ r add using data in a w -neighborho o d of x 0 . Our analysis is based on d – dimensional rectangular region [ x 0 ± w ] = { X i , X i ∈ [ x 0 − w , x 0 + w ] } . Denote the n umber of observ ations X i in [ x 0 ± w ] by ˜ n . Prop erties of the lo cal additiv e estimator can b e developed by rescaling the region [ x 0 ± w ] to [ − 1 , 1] d and then using results kno wn for ˆ r add . W e will consider additiv e estimators that reach the optimal order O ( n − 4 / 5 ). F or technical reasons, w e will focus on linear estimators, which enable us to compute exp ectations under T a ylor expansions. The SBE b y Mammen et al. (1999) is known to b e oracle optimal under general conditions, and other estimators inherit this optimality under more sp ecial situations (Linton and Nielsen 1995; Opsomer and Rupp ert 1997; Opsomer 2000). Throughout the article, w e will assume that ( A. 1) The regression function r and the design density f are t wice contin uously dif- feren tiable. The sp ecial case of uniform design will b e separately dealt with later in this section. When additiv e estimator is viewed as a comp onen t wise one–dimensional smo other, it has inheren tly a smo othing parameter asso ciated with it. It ma y refer to smoothing windo w h as in kernel smo others, smo othing parameter λ as in smo othing splines, or generally degrees of freedom d f as in equiv alent linear smo others. W e will stic k to h for a smo othing parameter, as the lo cal linear smo other is used later in our analysis. Supp ose that all w j ’s are of same order. F or simplicit y of notation let w j = w . Let w → 0 and h j /w → 0. W rite U = X − x 0 w , (2) 5 for the rescaled random v ariable on [ − 1 , 1] d with densit y ˜ f ( u ) = f ( x 0 + w u ) / Z [ − 1 , 1] d f ( x 0 + w u ) d u = f ( x 0 + w u ) 2 d f ( x 0 ) + O ( w 2 ) . (3) The corresp onding regression function is ˜ r ( u ) = r ( x 0 + w u ) (4) and the transformed bandwidth is ˜ h j = h j /w . (5) The lo cal additiv e estimator at x 0 is defined as ˆ r ladd ( x 0 ) = b ˜ r add ( 0 ). Denote 1st and 2nd partial deriv ativ es of r by r 0 j ( x ), r 00 j,k ( x ) and the d × d matrix of 2nd deriv atives by r 00 . ˆ r ll ( x 0 ) and the lo cal additiv e estimator by ˆ r ladd ( x 0 ). W e write E, B, V, MSE, ISE, ASE, MISE and MASE for the conditional exp ectation, bias, v ariance, mean squared error, in tegrated squared error, a verage squared error, in tegrated mean squared error and av erage mean squared error, resp ectiv ely . Define a matrix norm || · || for a symmetric matrix A = { a ij } as || A || = max i,j | a ij | and write || · || 2 for the usual L 2 norm. Let us first consider a bilinear function of comp onents u j and u k as b j k ( u ) = ( u j − ¯ U j )( u k − ¯ U k ) , where ¯ U j and ¯ U k are j th and k th marginal av erages of U in (2). Note that ¯ U j and ¯ U k are considered constants giv en U . W e will see that studying this function is rev ealing when applying T aylor expansions in the pro of of our main results. Let f w b e a sequence of design densities that conv erges to uniform. This can b e constructed, for example, as in (3) b y defining f w ( u ) = f ( x 0 + w u ) 2 d f ( x 0 ) for a density f satisfying (A.1). Let 6 ˆ b j k add,w b e the corresp onding additiv e estimator. If u j and u k are uniformly distributed, as n → ∞ , b j k ( 0 ) → 0 and ˆ b j k add, 0 → 0. Th us, ˆ b j k add,w ( 0 ) should conv erge to zero to o. Surprisingly enough, the case of v anishing second partial deriv atives needs sp ecial atten tion. Denote A j,k = x ∈ [ − 1 , 1] d | r 00 j,k ( x ) = 0 . (6) Without higher order smo othness ass umption, the results b elow are only v alid for x 0 outside the b orders ∂ A j,k of A j,k . W e claim ho wev er that these b orders are small and can b e ignored for most practical situations, as explained in the remarks following Prop osition 1 in Section 2.5. In addition to ( A. 1), the following assumptions are made. ( A. 2) The kernel K is b ounded, has compact supp ort, is symmetric around 0 and is Lipsc hitz contin uous. ( A. 3) The density f of x is b ounded aw a y from zero and infinity on [ − 1 , 1] d . ( A. 4) F or some θ > 5 / 2 , E [ | Y | θ ] < ∞ . ( A. 5) ˜ h j → 0 suc h that ˜ n ˜ h d j / ln ˜ n → ∞ as ˜ n → ∞ . 2.2 Main result Theorem 1. Assume that ˆ r add is line ar in Y and or acle optimal. L et f w b e a se- quenc e of design densities that c onver ges to uniform f 0 and ˆ r add,w b e the c orr esp onding additive estimator. Assume that ˆ r add,w c onver ges as f w c onver ges and satisfies | ˆ b j k add,w ( 0 ) − ˆ b j k add, 0 ( 0 ) | ≤ L || f w − f 0 || 2 2 for al l j 6 = k , wher e L is a c onstant. Then, for al l x 0 6∈ S j,k ∂ A j,k define d in (6), B 2 [ ˆ r ladd ( x 0 )] = max { O ( h 4 ) , O ( w 8 + w 4 max j,k | ˆ b j k add, 0 ( 0 ) | 2 ) } V [ ˆ r ladd ( x 0 )] = O (( nw d − 1 h ) − 1 ) . 7 Pr o of. Here, we will presen t the main ideas for bias. Because the estimator is linear, w e hav e E [ ˆ r add ( x 0 )] = 1 n n X i =1 W i ( x 0 , X i ) r ( X i ) . Similarly , for the lo cal additive estimator, we ha v e E [ ˆ r add,w ( x 0 )] = 1 ˜ n ˜ n X i =1 ˜ W i ( 0 , U i ) ˜ r ( U i ) , where U is given in (2). ˜ r ( U i ) = r ( x 0 + w U i ) = r ( x 0 ) + w X j r 0 j ( x 0 ) U ij + w 2 2 X j,k r 00 j,k ( x 0 ) U ij U ik + R ( x 0 , U i ) = additiv e + w 2 2 X j 6 = k r 00 j,k ( x 0 ) U ij U ik + R ( x 0 , U i ) . Th us, B [ ˆ r ladd ( x 0 )] = 1 ˜ n ˜ n X i =1 ˜ W i ( 0 , U i ) ˜ r ( U i ) − r ( x 0 ) = B [ additiv e ] + w 2 2 X j 6 = k r 00 j,k ( x 0 ) 1 ˜ n ˜ n X i =1 ˜ W i ( 0 , U i ) U ij U ik + 1 ˜ n ˜ n X i =1 ˜ W i ( 0 , U i ) R ( x 0 , U i ) . Because of oracle optimality of the estimator, the bias of the additiv e part b ecomes B [ additiv e ] = ˜ h 2 2 w 2 2 X j 2 r 00 j,j ( x 0 ) + o ( ˜ h 2 w 2 ) = h 2 2 X j r 00 j,j ( x 0 ) + o ( h 2 ) , (7) the latter equalit y following from (5). F or the leading nonadditive term, first consider 1 ˜ n ˜ n X i =1 ˜ W i ( 0 , U i ) U ij U ik . 8 Observ e that U ij U ik = ( U ij − ¯ U j )( U ik − ¯ U k ) + ¯ U j U ik + ¯ U k U ij + ¯ U j ¯ U k . (8) Giv en U i , the last three terms are linear and thus do not add additional bias. There- fore, w e fo cus on 1 ˜ n ˜ n X i =1 ˜ W i ( 0 , U i )( U ij − ¯ U j )( U ik − ¯ U k ) = ˆ b j k add,w ( 0 ) . This is nothing but the additive estimator at 0 when the design density is f w and the true regression function is the bilinear function b j k . It ma y b e written as ˆ b j k add,w ( 0 ) = ˆ b j k add,w ( 0 ) − ˆ b j k add, 0 ( 0 ) + ˆ b j k add, 0 ( 0 ) . Th us, | ˆ b j k add,w ( 0 ) | ≤ L || f w − f 0 || 2 2 + | ˆ b j k add, 0 ( 0 ) | = O ( w 2 + | ˆ b j k add, 0 ( 0 ) | ) . (9) Therefore, the second term is of order O ( w 2 ) O ( w 2 + | ˆ b j k add, 0 ( 0 ) | ). The last remainder term ma y b e written as w 2 X j,k 1 ˜ n ˜ n X i =1 ˜ W i ( 0 , U i ) U ij U ik Z 1 0 (1 − θ ) { r 00 j,k ( x 0 + θ w U i ) − r 00 j,k ( x 0 ) } dθ . As r 00 is contin uous, the integrands are o (1) and the corresp onding terms b ecome negligible compared to the main term ab ov e, if r 00 j,k ( x 0 ) 6 = 0. If r 00 j,k ( x ) = 0 in a neigh b orho o d of x 0 , the corresp onding integrand v anishes. Hence, the result follows from (7) and (9). T o demonstrate the idea of our result, w e mak e a rough comparison to the exist- ing results in the following t wo sections b y differentiating a situation with additive regression function from that with general regression function. 9 2.3 Beha vior for additiv e regression function When the true regression function is additiv e, the additive estimator ˆ r add has MSE of O ( n − 4 / 5 ) and the lo cal linear estimator ˆ r ll has MSE of O ( n − 4 / (4+ d ) ). W e can see this from V ˆ r ll ( x 0 ) = O ( nh d ) − 1 , B 2 ˆ r ll ( x 0 ) = O h 4 || r 00 || 2 = O h 4 , V ˆ r add ( x 0 ) = O ( nh ) − 1 , B 2 ˆ r add ( x 0 ) = O h 4 ( || r 00 || ) 2 = O ( h 4 ) . The lo cal additive estimator ˆ r ladd should b eat the lo cal linear estimator and come as close to the additiv e one as p ossible. With the same principle, the lo cal additiv e estimator w ould hav e V ˆ r ladd ( x 0 ) = O ( ˜ n ˜ h ) − 1 = O ( nw d − 1 h ) − 1 , B 2 ˆ r ladd ( x 0 ) = O ˜ h 4 ( || ˜ r 00 || ) 2 = O ( h 4 ) . Ob viously , the additive estimator is optimal, the lo cal linear estimator is w orst, and the lo cal additiv e estimator is in b etw een. 2.4 Beha vior for general regression function No w consider the general case. Note that prop erties of additiv e estimators for general regression functions are not well studied. Nev ertheless, when the true regression function is not additive, bias of the additiv e estimator is O (1). V ariance do es not dep end on the regression function and thus remains the same. Thus we hav e V ˆ r ll ( x 0 ) = O ( nh d ) − 1 , B 2 ˆ r ll ( x 0 ) = O h 4 || r 00 || ) 2 = O h 4 , V ˆ r add ( x 0 ) = O ( nh ) − 1 , B 2 ˆ r add ( x 0 ) = O || r 00 || 2 = O (1) . Applying the same principle to the lo cal additive estimator would lead to V ˆ r ladd ( x 0 ) = O ( ˜ n ˜ h ) − 1 = O ( nw d − 1 h ) − 1 , B 2 ˆ r ladd ( x 0 ) = O || ˜ r 00 || 2 = O ( w 4 ) . 10 W e will sho w (Theorem 2) that the limit for the bias of ˆ r ladd ( x 0 ) can b e further impro ved to B 2 [ ˆ r ladd ( x 0 )] = O ( w 8 ) using the SBE. 2.5 Lo cal additiv e estimator based on the SBE When the regression function is additive, it can b e shown that there is no loss in bias with lo cal additiv e estimator compared to additive estimator. F or general case, the lo cal additiv e estimator based on the SBE satisfies the requiremen ts of Theorem 1. Note that for the SBE, existence and conv ergence o ccur with probabilit y tending to one (see Mammen et al. 1999), thus our statemen ts imply the same without explicitly men tioning it. The results are v alid under quite general distributions, see assumption (A.4). F or simplicit y of notation we will assume that the residuals ε hav e constan t v ariance σ 2 whenev er appropriate. Theorem 2. The lo c al additive estimator ˆ r ladd b ase d on the smo oth b ackfitting esti- mator fulfil ls The or em 1 with ˆ b j k add,w = O ( w 2 ) and V [ ˆ r ladd ( x 0 )] = 2 µ 0 ( K 2 ) σ 2 d X j =1 nw d − 1 h j − 1 (1 + o (1)) . Corollary 1. F or al l x 0 6∈ S j,k ∂ A j,k define d in (6), the lo c al additive estimator ˆ r ladd b ase d on the smo oth b ackfitting estimator has B 2 [ ˆ r ladd ( x 0 )] = max { O ( h 4 ) , O ( w 8 ) } . In brief, the pro jection property of the SBE together with (A.1) helps reducing the bias for the general regression function. In summary we hav e for general regression function M S E [ ˆ r ladd ( x 0 )] = O ( h 4 + w 8 + ( nw d − 1 h ) − 1 ) . (10) 11 Corollary 2. Assume that d ≤ 8 . Optimal or ders of w and h of the lo c al additive estimator ˆ r ladd b ase d on the smo oth b ackfitting estimator ar e given by w ∼ n − 1 / (9+ d ) , h ∼ n − 2 / (9+ d ) , le ading to M S E [ ˆ r ladd ( x 0 )] ∼ n − 8 / (9+ d ) = n − 4 / 4+ d +1 2 . In comparison, the optimal lo cal linear estimator ac hieves O ( n − 4 / (4+ d ) ). The re- duction of dimensionality is explained b y the factor ˜ d = d +1 2 , the e quivalent dimension . F or example when d = 3 the lo cal additive estimator b ehav es similar to a lo cal linear estimator with ˜ d = 2, and when d = 5 it will b e reduced to ˜ d = 3. Thus, lo- cal additive estimation provides some relaxation of dimensionalit y in nonparametric regression compared to the minimax lo cal linear estimator. It turns out that the existence of second deriv ativ es is not sufficient to derive explicit co efficients for leading terms. Below w e deal with the sp ecial situation of a uniform design with higher order smo othness assumption. ( A. 1 0 ) The regression function r is four times con tin uously differen tiable and f is uni- form. Prop osition 1. Supp ose that ( A. 1 0 ) holds. Bias of the lo c al additive estimator ˆ r ladd b ase d on the smo oth b ackfitting estimator is given by B [ ˆ r ladd ( x 0 )] = µ 2 ( K ) 2 d X j =1 h 2 j r 00 j,j ( x 0 ) − w 4 4! · 9 X j 6 = k r 0000 j,j,k,k ( x 0 ) + o h 2 + w 4 . Con trary to Theorems 1 and 2, the Prop osition is v alid without any exclusion of b oundaries ∂ A j,k , whic h implies that the restriction there is related to irregular p oin ts of the regression function only . It should b e mentioned how ever that irresp ec- tiv e of condition ( A. 1 0 ) the MSE is alwa ys of order O h 4 + w 6 + ( nw d − 1 h ) − 1 if r 00 is 12 Lipsc hitz contin uous. Thus, the lo cal additiv e estimator works also at the remaining b oundaries. Prop osition 1 additionally shows that higher order smo othness assump- tion would not help further reduce bias. Moreo ver, it can b e deduced from the pro of (not sho wn) that the existence of r 00 is not sufficien t to derive leading terms. The optimal smo othing parameters are determined in the following. Define a = µ 2 ( K ) 2 X j r 00 j,j ( x 0 ) , b = 1 4! · 9 X j 6 = k r 0000 j,j,k,k ( x 0 ) , c = 2 dµ 0 ( K 2 ) σ 2 . Prop osition 2. Supp ose that ( A. 1 0 ) holds. Assume that h j = h and let h = C h w 2 . The smo othing p ar ameter w that minimizes asymptotic MSE is given by w = c ( d + 1) 8 C h ( aC 2 h − b ) 2 1 / (9+ d ) n − 1 / (9+ d ) . Prop osition 3. Under the same assumptions as in Pr op osition 2, the optimal choic e of C h is given by C h = r 2 d − 1 − b a . pr ovide d that ab < 0 . Prop erties of the lo cal additive estimator based on the SBE are studied in detail in Park and Seifert (2008). Pro ofs of Prop ositions 1 – 3 are found there and results of Theorem 2 and Corollary 1 can b e deduced directly from results form ulated there. 2.6 Data-adaptiv e parameter selection W e consider smo othing parameter selection based on mo del selection criteria for gen- eral regression function estimation. Although asymptotic equiv alence of classical mo del selection criteria has long been recognized (H¨ ardle et al. 1988), b ecause of small sample b ehavior, several versions of mo del selection criteria exist (Hurvich and Simonoff 1998). Still most discussions w ere limited to one dimensional problem. 13 F or additiv e mo dels with ordinary backfitting estimator, Opsomer and Rupp ert (1998) prop osed a plug-in bandwidth selector and W o o d (2000) prop osed general- ized cross-v alidation approach for additive mo dels with p enalized regression splines. F or additiv e mo dels with smo oth bac kfitting estimator, Nielsen and Sperlich (2005) discussed cross v alidation, while Mammen and Park (2005) prop osed a bandwidth selection metho d whic h minimizes a p enalized sum of squared residuals P LS = ˆ σ 2 1 + 2 X j 1 nh j K (0) ! and noted that it is computationally more feasible than cross v alidation. They also conjectured ab out mo del missp ecification (p. 1263) that ...the p enalize d le ast squar es b andwidth wil l work r eliably also under missp e cific ation of the additive mo del. This c onje ctur e is supp orte d by the definition of this b andwidth... but p ointed out the difficult y inv olv ed in the theory (p. 1267). F or nonadditiv e mo dels Studer et al. (2005), in the con text of p enalized additiv e regression approach, inv estigated parameter selection based on AIC-type mo del se- lection criteria suc h as AIC, GCV, and AIC C (Hurvic h et al. 1998) and established asymptotic equiv alence of these estimators in m ultiv ariate lo cal linear regression for d ≤ 4 where the estimator satisfies stability condition. Note that the additiv e SBE uses only tw o-dimensional marginal densities and thus such restriction is not neces- sary . W e inv estigate smo othing parameter selection based on AIC-type mo del selection criteria and show that PLS is equiv alent to AIC-t yp e model selection criteria. Because the lo cal additive estimator based on the SBE uses tw o-dimensional densities in the rescaled window, the formulas (6.18)-(6.21) in Mammen and P ark (2005) can b e used to show that (A.5) is sufficien t for the lo cal additive estimator to b e stable. In view of Corollary 2, (A.5) is necessary to o. 14 Consider AI C ( h, w ) = log ( ˆ σ 2 ) + 2 tr ( H ) /n , where ˆ σ 2 = 1 n || Y − H Y || 2 , Y is the column vector of resp onses on design p oin ts with a hat matrix H and tr ( H ) is the trace of the hat matrix H . Using log( ˆ σ 2 ) = log ( σ 2 ) + ˆ σ 2 σ 2 − 1 + O p ( ˆ σ 2 − σ 2 ) 2 . Studer et al. (2005) defined the T aylor appro ximation of AIC − log ( σ 2 ) b y AIC T = ˆ σ 2 σ 2 − 1 + 2 n tr ( H ) . (11) It can b e shown that AIC and AIC T are equiv alen t for the optimal parameters in Corollary 2. Using the fact that for additive regression functions tr ( H ) → K (0) X j 1 /h j , (see (6.11) in Mammen and Park 2005), w e establish b elow that PLS and AIC T are equiv alent as long as ˆ σ 2 is consisten t and ˆ r is stable. Prop osition 4. The PLS define d by Mammen and Park (2005) is e quivalent to AIC T define d by Studer et al. (2005). A decomp osition of AI C T leads to Prop osition 5. AI C T − 1 nσ 2 ε 0 ε − 1 = 1 nσ 2 || ( I − H ) r || 2 + 1 nσ 2 E [ || H ε || 2 ] + O p ( h 2 + w 4 √ n ) + O p 1 n √ w d − 1 h The first term on the righ t hand side of the decomp osition of AIC T is the mean squared bias, whereas the second term is the v ariance of ˆ r ladd , b oth divided b y σ 2 . Th us, smo othing parameter selection based on AIC-type model selection criteria leads to asymptotically optimal bias v ariance compromise. Pro ofs of Prop ositions 4 and 5 are given in App endix. 15 3 Numerical p erformance 3.1 Sim ulation studies W e are interested in inv estigating how the smoothing parameters are related to p erfor- mance of the estimators of general regression function in terms of conditional MISE. F or general multiv ariate nonparametric regression problem, there are limited sim u- lation studies rep orted in the literature. F or example, Banks et al. (2003) rep orted comparison results of a broad class of multiv ariate nonparametric regression tech- niques. Some additive mo del sim ulation studies can b e found in Dette et al. (2005) and Martins-Filho and Y ang (2006). Here we fo cus on comparison to lo cal linear and additive estimators as a b enc hmark on either extremes. Lo cal linear estimator is optimal for general regression function estimation so the comparison to it allo ws us to assess the b ehavior for nonadditive regression function estimation. Likewise additiv e estimator is used to study the b eha vior for additiv e regression function estimation. Results are based on Monte-Carlo approximation of MISE. d=2: A random uniform design on [ − 1 , 1] 2 and normally distributed residuals N (0 , σ 2 ) w ere assumed with sample sizes 200, 400, and 1600. Estimators are ev aluated at an equidistan t output grid of 21 × 21 p oin ts. F or fitting the SBE, w e used SBF2 pack age of R developed in conjunction with Studer et al. (2005), which is freely a v ailable from www.biostat.uzh.c h/research/soft ware/. The main factor of consideration in our sim ulation studies is the regression func- tion, cov ering a range of additive and nonadditive functions. T o illustrate the b ehavior of the lo cal additiv e estimator, we first consider the regression function r ( x ) = x 2 1 + x 2 2 + α 1 − α x 1 x 2 , (12) 16 where α con trols the amount of nonadditive structure in the function. Figure 1 ab out here. P erformance of the lo cal additiv e estimator is illustrated in Figure 1. Estimation is based on 400 observ ations with α = 0 . 4 and σ = 0 . 5. All estimators used their MISE-optimal smo othing parameters. As exp ected, the additive estimator (low er righ t panel) do es not capture the nonadditive structure. The lo cal linear estimator (upp er right) reveals the diagonal structure but has a quite large bias due to its large MISE-optimal bandwidth ( h = 0 . 64). Because of lo cal additive, instead of lo cal linear, approximation of the regression function, the lo cal additive estimator uses more observ ations ( w = 0 . 94), resulting in an improv ed v ariance, whereas the bandwidth is smaller ( h = 0 . 47), resulting in an improv ed bias. As a consequence, the lo cal additiv e estimator inherits the optimal prop erties in a lo c al sense. F or smo othing parameter selection in practice, Figure 2 presents comparison of ASE-optimal parameters to AIC C optimal ones for the lo cal additive estimator based on one realization dra wn from the same design used in Figure 1 with σ = 0 . 5. The range of smo othing parameters suggested b y b oth criteria largely agrees and we find AIC C comparable for practical use. Figure 3 ab out here. The effect of nonadditivity α in the regression function on MISE can b e seen in Figure 3, on a log scale. MISE (first ro w) is decomp osed in to the integrated squared bias (second row) and v ariance (third row). Differen t columns corresp ond to different σ s. In each panel, the optimal MISE is plotted as a function of α , with an individual optimal choice of smo othing parameters found in the ab ov e simulations. Solid line is for lo cal additiv e estimator, dashed line for lo cal linear estimator and dotted line for additive estimator. As is exp ected, the regression function has little effect on the 17 lo cal linear estimator but had a dramatic impact on the additiv e estimator because of gro wing nonadditivity . Lo cal additive estimator sho ws relativ ely robust p erformance, adapting the b est of the former estimators. MISE b ehavior for other regression functions is summarized in T able 1. Regression functions used are additive p eaks r ( x ) = 1 2 2 X k =1 0 . 3 exp( − 2( x k + 0 . 5) 2 ) + 0 . 7 exp( − 4( x k − 0 . 5) 2 ) + 0 . 5 exp( − x 2 k 2 ) , sup erp osed p eaks r ( x ) = 0 . 3 exp( − 2 k x + 0 . 5 k 2 ) + 0 . 7 exp( − 4 k x − 0 . 5 k 2 ) + 0 . 5 exp( − k x k 2 2 ) , and p erio dic nonadditiv e function r ( x ) = cos( π || x || ) . MISE-v alues are m ultipled b y 1000. MISE-optimal smo othing parameters are also supplied, with MISE ratios. T able 1 ab out here. W e considered v arian ts of these scenarios for other regression functions and design densities such as fixed uniform, fixed uniform jittered, linearly skew ed one and lin- early sk ewed jittered designs and observed similar phenomena stable across designs considered. More simulation results are found in P ark and Seifert (2008). There, one can also find sim ulations for d = 3. Because of dimensionalit y , the candidate regions of smo othing parameters are narrow er than those for d = 2, but the b ehavior of the estimators is similar and thus the same conclusions apply . d=10: F or higher–dimensional case, we considered the regression function r ( x ) = x 2 1 + αx 1 10 X j =2 x j ) α = 0 , 0 . 5 , or 1 , (13) 18 with 2000 observ ations on a random uniform design and σ = 0 . 2. Local estimation in 10 dimensions calls for boundary correction. Otherwise, the exp ected num b er of observ ations in a corner w ould b e w 10 n compared to 1024 w 10 n in the center. T o illustrate the b ehavior of lo cal additiv e estimator using an additive estimator other than the SBE, we used the function gam in the mgcv pac k age of R . Although op- timalit y of the p enalized splines used there is not known, the idea of lo cal additiv e estimator can b e easily applied. Moreo v er, gam has computational adv antages; im- plemen tation with gam particularly facilitates selection of smo othing parameter using generalized cross v alidation (GCV). Unconditional MASE w as approximated with 20 runs of simulation. T o reduce computational burden, estimators are ev aluated at 50 design p oin ts randomly c hosen at each sim ulation. The resulting relative standard error of MASE estimators is ab out 3-5%. Figure 4 ab out here. Figure 4 sho ws p erformance of estimators for three different v alues of α . Dashed line is for lo cal linear estimator, solid line for lo cal additiv e estimator. The letter “a” at the end of solid line represents additive estimator. The x -axis represents smo othing parameter; for lo cal linear estimator, it is the bandwidth h and for lo cal additive estimator, it is w , and the GCV-optimal v alue of h given w was chosen in ternally b y gam . P erformance of lo cal linear estimator do es not dep end on the regression function, while lo cal additive estimator adapts to additivit y , exhibiting lo wer curves as the panel mov es to the right. W e can conclude that ov erall p erformance of lo cal additiv e estimator exceeds that of others, adapting to nonadditivit y . In summary , we ha ve observed that when the regression function is additive or close to additive the lo cal additive estimator is compatible to the additiv e estimator, and when the regression function is nonadditiv e it mimics the lo cal linear estimator whenev er possible. W e also ha v e noticed that the low est p ossible bandwidth that lo cal 19 additiv e estimator could exploit is limited by the n um b er of observ ations required to obtain a stable estimator for ev ery output p oin t. A b oundary correction sometimes helps to stabilize an estimator but it w orks differen tly for different estimators and th us we decided not to include it except for d = 10. 3.2 Real data example W e use the ozone dataset from the R pack age (Section 10.3, Hastie and Tibshi- rani (1990)) to make comparison to the previous analysis. With nine predictors, an additiv e regression mo del would b e a natural c hoice. When a new approach which can deal with nonadditive structure is applied, the mo del can b e further refined or simplified. Studer et al. (2005) p ointed out that the additive mo del with nine predic- tors is almost equiv alent, in terms of adjusted R 2 , to an additive mo del with a subset of predictors, allo wing biv ariate in teraction terms. They applied p enalized regression approac h to uncov er b ehavior of the biv ariate in teraction, noting serious departure from additiv e mo del assumption. T o make it comparable, we adopt the same framework as Studer et al. (2005), where the dep endent v ariable is defined as the logarithm of the upland ozone concen- tration (up03) and three predictors, humidit y (hmdt), inv ersion base height (ibtp), and calendar da y (day) are c hosen whic h maximize adjusted R 2 among fitted additiv e mo dels with biv ariate interaction terms with 16 degrees of freedom each, using gam in R pack age mgcv . Then the three v ariables w ere scaled to [0,1]. As noted in the previous analysis, one observ ation (92) that con tains excessive v alue of wind sp eed w as remov ed prior to the analysis. W e consider local additiv e model and additiv e with biv ariate in teraction mo del for comparison. The additiv e with in teraction mo del w as fitted using gam with in ternally c hosen optimal smo othing parameters. T o fit the lo cal additive mo del based on the 20 SBE, univ ariate bandwidths h 1 , h 2 and h 3 are initially chosen to ha ve four degrees of freedom each as in Studer et al. (2005). These are shown to lie close together with mean h = 3 √ h 1 h 2 h 3 = 0 . 237. Bandwidths for the lo cal additiv e estimator are set to b e ( ch 1 , ch 2 , ch 3 ). Parameters c and w are then selected based on AIC C . Figure 5 ab out here. These estimators are compared in Figure 5. F or reference, w e also repro duced the lo cal linear estimator from Studer et al. (2005). The univ ariate comp onen ts on the top show similar trend, although the lo cal linear estimates sho w o ccasional kinks and the additiv e with in teraction mo dels tends to smo oth out quic kly , esp ecially for hmdt. The b ottom row sho ws the largest biv ariate interaction, that b etw een ibtp and hmdt, for each estimator. W e see that in b oth terms the lo cal additive estimator pro vides a go o d compromise. In terested readers are referred to Section 5.3 and Figure 5 in Studer et al. (2005) for further comparison and issues with regularisation. References [1] Banks, D. L., Olszewski, R. T., and Maxion, R. A. (2003). Comparing metho ds for multiv ariate nonparametric regression. Computations in Statistics , 32 , 541- 571. [2] Breiman, L. (1993). Fitting additive mo dels to regression data: Diagnostics and alternativ e views. Computational Statistics and Data Analysis , 15 , 13-46. [3] Deaton, A. and Muellbauer, J. (1980). Econometrics and consumer b ehaviour. Cambridge University Pr ess: Cambridge . 21 [4] Dette, H., V on Lieres, Carsten, and Sp erlich, S. (2005). A comparison of differen t nonparametric metho ds for inference on additives. Nonp ar ametric Statistics , 17 , 57-81. [5] F an, J. (1993). Lo cal linear regression smo others and their minimax efficiency . A nnals of Statistics , 21 , 196-216. [6] F an, J., Gasser, T., Gijb els, I., Bro c kmann, M. and Engel, J. (1997). Lo cal p oly- nomial regression: optimal kernels and asymptotic minimax efficiency . A nnals of the Institute of Statistic al Mathematics , 49 , 79-99. [7] Hastie, T. and Tibshirani, R. (1990). Generalized additiv e mo dels. Chapman and Hal l, L ondon . [8] Hurvich, C., Simonoff, J. and Tsai, C. (1998). Smo othing parameter selection in nonparametric regression using an impro v ed Ak aike information criterion. Jour- nal of R oyal Statistic al So ciety, B , 60 , 271-293. [9] Linton, O. and Nielsen, J. (1995). A kernel metho d of estimating structured nonparametric regression based on marginal in tegration. Biometrika , 82 , 93-100. [10] Mammen, E., Lin ton, O. and Nielsen, J. (1999). The existence and asymptotic prop erties of a bac kfitting pro jection algorithm under weak conditions. A nnals of Statistics , 27 , 1443-1490. [11] Mammen, E., Marron, J. S., T urlach, B. A. and W and, M. P . (2001). A general pro jection framework for constrained smo othing. Statistic al Scienc e , 16 (3), 232- 248. [12] Mammen, E. and P ark, B. U. (2005). Bandwidth selection for smooth bac kfitting in additiv e mo dels. Annals of Statistics , 33 (3), 1260-1294. 22 [13] Martins-Filho, C. and Y ang, K. (2006). Finite sample p erformance of kernel- based regression metho ds for nonparametric additive mo dels under common bandwidth selection criterion. , [14] Nielsen, J. P . and Sp erlic h, S. (2005). Smo oth bac kfitting in practice. Journal of the R oyal Statistic al So ciety, B , 60 , 43-61. [15] Opsomer, J. (2000). Asymptotic prop erties of bac kfitting estimators. Journal of Multivariate A nalysis , 73 , 166–179. [16] Opsomer, J., and Rupp ert, D. (1997). Fitting a biv ariate additiv e mo del by local p olynomial regression. A nnals of Statistics , 25 , 186–212. [17] Opsomer, J., and Rupp ert, D. (1998). A fully automated bandwidth selection metho d for fitting additive mo dels. Journal of Americ an Statistic al Asso ciation , 93 , 605–619. [18] Park, J. and Seifert, B. (2008). On prop erties of lo cal additiv e estimation based on the smo oth bac kfitting estimator. te chnic al r ep ort , av ailable on http://www.maths.lancs.ac.uk/~parkj1/paper/locaddSBE.pdf [19] Stone, C. J. (1980). Optimal rates of conv ergence for nonparametric estimators. A nnals of Statistics , 8 , 1348-1360. [20] Stone, C. J. (1982). Optimal global rates of conv ergence for nonparametric re- gression. A nnals of Statistics , 10 , 1040-1053. [21] Stone, C. J. (1985). Additiv e regression and other nonparametric mo dels. A nnals of Statistics , 13 , 689-705. [22] Studer, M., Seifert, B. and Gasser, T. (2005). Nonparametric regression p enal- izing deviations from additivity . Annals of Statistics , 33 , 1295-1329. 23 [23] W o o d, S. N. (2000). Mo delling and smo othing parameter estimation with mul- tiple quadratic p enalties. Journal of R oyal Statistic al So ciety, B , 62 , 413–428. true −1 0 1 −1 0 1 local linear −1 0 1 −1 0 1 local additive −1 0 1 −1 0 1 additive −1 0 1 −1 0 1 Figure 1: Contour plot of regression function (12) and estimators. P arameters are c hosen to b e MISE-optimal from sim ulation with α = 0 . 4 and σ = 0 . 5. Additive estimator fails to capture nonadditive structure. While lo cal linear estimator and lo cal additiv e estimator sho w compatible performance, lo cal additiv e estimator incurs smaller bias at the center due to smaller bandwidth. 24 Additiv e p eaks σ lo cal linear ( h opt ) lo cal additiv e ( h opt , w opt ) additiv e ( h opt ) 0.1 3.9=315% (h=0.260) 1.2=100% (h=0.123, w=0.870) 1.3=107% (h=0.143) 0.5 22.1=136% (h=0.473) 16.2=100% (h=0.350, w=0.988) 15.4=95% (h=0.350) 1.0 39.6=111% (h=1.000) 35.6=100% (h=0.741, w=0.933) 32.5=91% (h=0.861) Sup erp osed p eaks σ lo cal linear ( h opt ) lo cal additiv e ( h opt , w opt ) additiv e ( h opt ) 0.1 2.6=117% (h=0.260) 2.2=100% (h=0.193, w=0.242) 7.0=311% (h=0.350) 0.5 14.9=124% (h=0.741) 12.0=100% (h=0.638, w=0.716) 13.3=110% (h=0.638) 1.0 30.9=123% (h=1.000) 25.1=100% (h=0.741, w=0.741) 24.4=97% (h=0.861) P erio dic nonadditiv e σ lo cal linear ( h opt ) lo cal additiv e ( h opt , w opt ) additiv e ( h opt ) 0.1 4.8=130% (h=0.260) 3.7=100% (h=0.193, w=0.242) 96.8=2611% (h=0.166) 0.5 32.7=97% (h=0.350) 33.6=100% (h=0.260, w=0.260) 111.7=333% (h=0.302) 1.0 85.7=91% (h=0.473) 93.9=100% (h=0.407, w=0.407) 139.2=148% (h=0.473) T able 1: Comparison of MISE p erformance based on 400 observ ations at different standard deviations–optimal parameters are giv en in the parentheses. Outp erfor- mance of lo cal additive estimator is consequence of smaller h than that for lo cal linear estimator and smaller additiv e region ( w < 1) than that for additiv e estimator. 25 w/h h ASE 1 2 5 10 0.1 0.2 0.5 1 ● h = 0.35 , w = 0.7 w/h h AICc 1 2 5 10 0.1 0.2 0.5 1 ● h = 0.3 , w = 0.95 Figure 2: ASE and parameter selection b y AIC C for regression function (12) and design used in Figure 1 with σ = 0 . 5. 26 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 σ = 0.1 MISE 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 IB 2 α 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 IV 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 σ = 0.5 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 α 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 σ = 1 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 α 0.00001 0.01 0 0.1 0.2 0.3 0.4 0.5 Figure 3: Effect of nonadditive regression function on the MISE p erformance for MISE-optimal parameters. MISE (first row), in tegrated squared bias (second ro w) and v ariance (third row) as functions of α in (12) is plotted on a log scale for increasing σ . Lo cal linear estimator (dashed line) is not affected but additive estimator (dotted line) dramatically deteriorates. Lo cal additiv e estimator (solid line) sho ws relativ ely robust p erformance. 27 w MASE ∑ j = 1 10 x j 2 + x 1 ∑ j = 2 10 x j 0.7 0.8 0.9 1 0.001 0.01 0.05 ● ● a w MASE ∑ j = 1 10 x j 2 + 0.5x 1 ∑ j = 2 10 x j 0.7 0.8 0.9 1 0.001 0.01 0.05 ● ● a w MASE ∑ j = 1 10 x j 2 0.7 0.8 0.9 1 0.001 0.01 0.05 ● ● a Figure 4: Comparison of unconditional MASE p erformance of a 10–dimensional re- gression function (13) for lo cal linear estimator (- -), lo cal additive estimator (–) and additiv e estimator (“a”). x -axis represents bandwidths for lo cal linear estimator and w for lo cal additive estimator with an in ternal choice by gam of h at given w . Dots and “a” sho w mean MASE at GCV-optimal smo othing parameters vs. mean GCV- optimal w . 28 −1.0 0.0 0.5 1.0 outgrid log(upo3) ibtp 0.0 0.2 0.4 0.6 0.8 1.0 outgrid day outgrid hmdt log(upo3) 0.0 0.2 0.4 0.6 0.8 1.0 −1.0 0.0 0.5 1.0 loc.add. loc.lin. add.interaction 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.4 0.8 Local linear ibtp hmdt Local additive ibtp Add. interaction ibtp hmdt 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.4 0.8 Figure 5: Comparison of lo cal linear, lo cal additive, and additive spline with in ter- action estimators. T op row sho ws univ ariate additiv e comp onents and b ottom row sho ws biv ariate comp onents of ibtp and hmdt for each estimator. 29 App endix Pro of of Prop osition 4 W e use the follo wing fact for additiv e regression functions tr ( H ) → K (0) X j 1 /h j := tr ( H ) ∞ , whic h can b e deduced from (6.11a) or (6.11) in Mammen and P ark (2005). Th us, PLS (p. 1269, Mammen and P ark 2005) is defined for additive regression functions as P LS = ˆ σ 2 1 + 2 tr ( H ) ∞ n . In this form, it can be generalized to nonadditiv e functions. Firstly from the definition of AIC T , it can b e written as AI C T + 1 = 1 σ 2 P LS + 2( σ 2 − ˆ σ 2 ) tr ( H ) n + 2 ˆ σ 2 tr ( H ) − tr ( H ) ∞ n . Then observ e that 2( σ 2 − ˆ σ 2 ) tr ( H ) n + 2 ˆ σ 2 tr ( H ) − tr ( H ) ∞ n = o tr ( H ) n . Therefore, it follo ws that AI C T + 1 = 1 σ 2 P LS + o tr ( H ) n , as long as ˆ σ 2 is consisten t and ˆ r is stable. Pro of of Prop osition 5 AIC T can b e written as AIC T = 1 nσ 2 r 0 ( I − H ) 0 ( I − H ) r + 1 nσ 2 ε 0 ( I − H ) 0 ( I − H ) ε + 1 nσ 2 2 ε 0 ( I − H ) 0 ( I − H ) r − 1 + 2 tr ( H ) n . Observ e that ε 0 ( I − H ) 0 ( I − H ) ε = ε 0 ε − 2 E [ ε 0 H ε ] + O p ( p V [ ε 0 H ε ]) + E [ ε 0 H 0 H ε ] + O p ( p V [ ε 0 H 0 H ε ]) . 30 Since E [ ε 0 H ε ] = tr ( H ) σ 2 , w e hav e AIC T − 1 nσ 2 ε 0 ε − 1 = 1 nσ 2 || ( I − H ) r || 2 + 1 nσ 2 E [ ε 0 H 0 H ε ] + 1 nσ 2 2 ε 0 ( I − H ) 0 ( I − H ) r + 1 nσ 2 O p ( p V [ ε 0 H ε ]) + 1 nσ 2 O p ( p V [ ε 0 H 0 H ε ]) . The rest follo ws from a series of lemmas b elo w. Lemma 1. tr (( H 0 H ) 0 ( H 0 H )) = O tr ( H 0 H ) = O 1 / ( w d − 1 h ) Pro of: Denote b y H i the hat matrix of the additive estimator used for lo cal additiv e estimation at x 0 = X i . Then, inflating the matrix to an n × n matrix, the i th line of H is the i th line of H i := H i,i . No w, considering the form of the estimator ˆ r i = ˆ r 0 + ˆ r 1 + . . . + ˆ r d , where all comp onen ts are oracle, we hav e H i,j = O ( 1 ˜ n ˜ h ) if for all k : | X i k − X j k | ≤ w and for some k : | X i k − X j k | ≤ h O ( 1 ˜ n ) if for all k : | X i k − X j k | ≤ w and for all k : | X i k − X j k | > h 0 otherwise Note, that these O ()s are uniform o ver X b ecause of (A.5), using Gao (2003) as in Studer et al. (2005). Let’s first lo ok at tr ( H 0 H ). W e hav e H 0 i,i H i,i = O O ( 1 ˜ n ˜ h ) 2 O ( ˜ n ˜ h ) + O ( 1 ˜ n ) 2 O ( ˜ n ) = O 1 ˜ n ˜ h = O 1 nw d − 1 h . Consequen tly , tr ( H 0 H ) = O 1 w d − 1 h . 31 No w, lo ok at the general elements of H 0 H . With a slight abuse of notation, H 0 i,i H j,j = O O ( 1 ˜ n ˜ h ) 2 O ( ˜ n ˜ h ) + O ( 1 ˜ n ˜ h ) O ( 1 ˜ n ) O ( ˜ n ˜ h ) + O ( 1 ˜ n ) 2 O ( ˜ n ) if for all k : ( X i k ± w ) ∩ ( X j k ± w ) 6 = ∅ and for some k : ( X i k ± h ) ∩ ( X j k ± h ) 6 = ∅ O O ( 1 ˜ n ˜ h ) O ( 1 ˜ n ) O ( ˜ n ˜ h ) + O ( 1 ˜ n ) 2 O ( ˜ n ) if for all k : ( X i k ± w ) ∩ ( X j k ± w ) 6 = ∅ and for some k : ( X i k ± w ) ∩ ( X j k ± h ) 6 = ∅ or ( X i k ± h ) ∩ ( X j k ± w ) 6 = ∅ O O ( 1 ˜ n ) if for all k : ( X i k ± w ) ∩ ( X j k ± w ) 6 = ∅ and ( X i k ± w ) ∩ ( X j k ± h ) = ∅ and ( X i k ± h ) ∩ ( X j k ± w ) = ∅ 0 otherwise . Finally , H 0 i,i H j,j = O ( 1 ˜ n ˜ h ) if for all k : ( X i k ± w ) ∩ ( X j k ± w ) 6 = ∅ and for some k : ( X i k ± h ) ∩ ( X j k ± h ) 6 = ∅ O ( 1 ˜ n ) if for all k : ( X i k ± w ) ∩ ( X j k ± w ) 6 = ∅ and for all k : ( X i k ± h ) ∩ ( X j k ± h ) = ∅ 0 otherwise . Th us, H 0 H has the same structure as H , of course with differen t constants and larger non-zero regions, but all of the same order. Therefore, tr ( H 0 H H 0 H ) = O ( tr ( H 0 H )) = O 1 w d − 1 h . Lemma 2. 1 nσ 2 ε 0 ( I − H ) 0 ( I − H ) r = 1 nσ 2 < ( I − H ) ε, ( I − H ) r > = O p h 2 + w 4 √ n 32 Pro of: First note that ( I − H ) r = O (( h 2 + w 4 ) 1 ). 1 nσ 2 < ( I − H ) ε, ( I − H ) r > ≤ 1 nσ 2 || ( I − H ) ε |||| ( I − H ) r || ≤ 1 nσ 2 O p ( √ n ) O (( h 2 + w 4 ) 1 ) = O p h 2 + w 4 √ n where the last inequality follows from || ( I − H ) ε || 2 = O p ( tr ( V [ || ( I − H ) ε || 2 )) = O p ( tr (( I − H )( I − H ) 0 σ 2 ) = O p ( n ) . Lemma 3. V [ ε 0 H ε ] = V [ < ε, H ε > ] = O ( E [ || H ε || 2 ]) If tr (( H 0 H )( H 0 H )) = O ( tr ( H 0 H ) , then V [ ε 0 H 0 H ε ] = V [ || H ε || 2 ] = O ( E [ || H ε || 2 ]) Pro of: Similar to the pro of of lemma 5 in the app endix of Studer et al. (2005), w e use the following fact: F or symmetric matrices B and C and E [ ε 4 ] = (3 + κ ) σ 4 , C ov ( ε 0 B ε, ε 0 C ε ) = 2 σ 4 tr ( B C ) + κσ 4 tr ( B · diag ( C )) Putting B = C = 1 2 ( H + H 0 ) giv es V [ 1 2 ε 0 ( H + H 0 ) ε ] = 2 σ 4 ( 1 4 tr ( H H + 2 H 0 H + H 0 H 0 ) + κσ 4 tr ( 1 4 ( H 0 + H ) diag ( H + H 0 )) V [ ε 0 H ε ] = σ 4 ( tr ( H H + H 0 H ) + κ tr ( diag ( H ) 2 ) ≤ σ 4 ( tr ( H H ) + tr ( H 0 H ) + | κ | tr ( H 0 H ) Using the equiv alence of the trace to Hilb ert-Schmidt norm, || H || 2 H S = tr ( H 0 H ) 33 it follo ws that tr ( H H ) = < H 0 , H > H S ≤ || H 0 || H S || H || H S = || H || 2 H S = tr ( H 0 H ) . Hence, V [ ε 0 H ε ] ≤ σ 4 (2 tr ( H 0 H ) + | κ | tr ( H 0 H )) = σ 4 (2 + | κ | ) tr ( H 0 H ) = σ 2 (2 + | κ | ) E [ || H ε || 2 ] Th us, V [ < ε, H ε > ] = O ( E [ || H ε || 2 ]). Moreov er, replacing H by H 0 H in the ab ov e leads to V [ ε 0 H 0 H ε ] ≤ σ 2 (2 + | κ | ) tr (( H 0 H ) 0 ( H 0 H )) . Hence, if tr (( H 0 H ) 0 ( H 0 H )) = O ( tr ( H 0 H )), then V [ || H ε || 2 ] = O ( tr ( H 0 H )) = O ( E [ || H ε || 2 ]). 34
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment