Proactive Service Migration for Long-Running Byzantine Fault Tolerant Systems
In this paper, we describe a novel proactive recovery scheme based on service migration for long-running Byzantine fault tolerant systems. Proactive recovery is an essential method for ensuring long term reliability of fault tolerant systems that are…
Authors: Wenbing Zhao
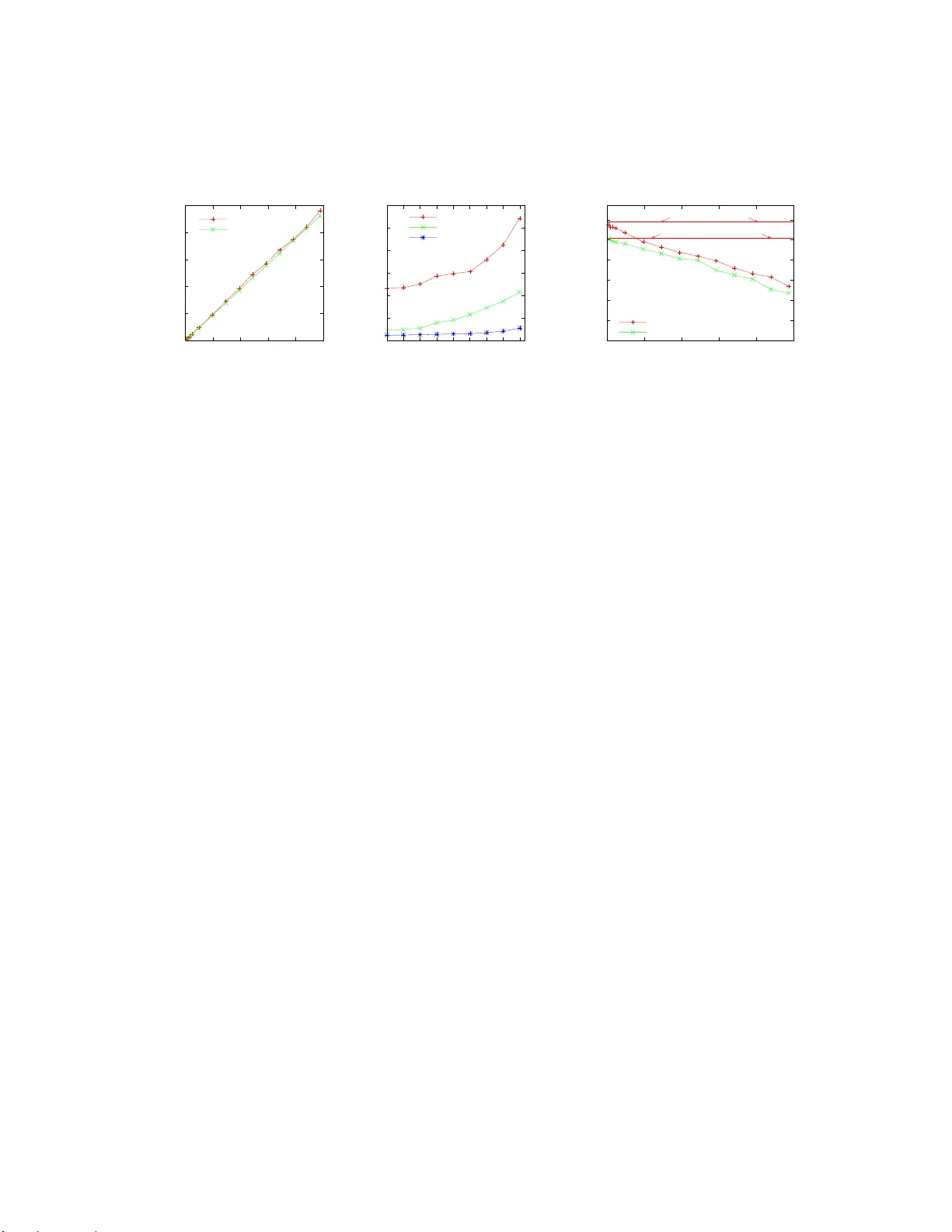
Proacti ve Service Migration for Long-Run ning Byzantin e F ault T olerant Systems ∗ W enbing Zhao Department of Electrical and Computer Engineering Cle veland State Uni versity , 2121 Euclid A ve., Cle veland, OH 44115 wenbing@ieee.org Abstract In this paper, we describe a novel proactive recov- ery scheme based on service migra tion for long-runn ing Byzantine fault tolerant systems. Proactive recovery is an essential metho d for ensuring long term reliability of fault tolerant sy stems that are und er continu ous threats from malicious adversaries. T he primary benefit of our proactive recovery schem e is a reduced v ulnerab ility win- dow . This is ach iev ed by removing the time-co nsuming reboot step from the critical path of proactive recovery . Our migration -based proacti ve r ecovery is coo rdinated among the replicas, therefore, it can a utomatically adjust to different system loads and av oid the prob lem o f ex- cessi ve concurr ent proactiv e recoveries that m ay occur in previous work with fixed watchdo g timeouts. M oreover , the fast proactive re covery also significantly improves th e system a vailability in the presence of faults. Keywords: Proactive Recovery , Byzantine Fault T oler- ance, Service Migr ation, Replication, Byzantine Agr ee- ment 1 Introd uction W e h ave seen increasing reliance on ser vices p rovided over the In ternet. Th ese services are expected to b e con- tinuously av ailab le over extended period of time (typi- cally 24x 7 and all ye ar long ). Unfortu nately , the vul- ∗ This research has been supported in part by Department of En- ergy Contrac t DE-FC26-06NT42853, and by Cl e vela nd State Uni versity through a Fac ulty Research Dev elopment award. nerabilities du e to insufficient design an d poor imple- mentation are of ten exploited b y adversaries to c ause a variety of damages, e.g., crashing of the applications, leaking of co nfidential informatio n, modify ing or delet- ing of critical data, or injecting of erron eous inf orma- tion into the application data. These malicious faults are ofte n modeled as Byzantine faults [9], an d they are detrimental to any online service providers. Suc h threats can be coped with using Byzantine fault tolera nce (BFT) technique s, as demonstrated by many research results [2, 3, 4 , 5, 7, 11, 13, 16]. The Byzantin e fault to lerance algorithm s assume that on ly a small portion of th e rep li- cas can be faulty . When the numb er of faulty replica s exceeds a threshold, BFT may fail. Consequen tly , Cas- tro and Lisko v [3] propo sed a p roactive recovery scheme that periodically reboots replicas and refreshes their state, ev en before it is known that they hav e failed. A s long as the number of compro mised replicas d oes not exceed the threshold within a time wind ow that all replicas can b e proactively recovered ( such window is ref erred to as win- dow o f vulner ability [4], or v ulnerab ility window), the in- tegrity of the BFT algo rithm holds and the services being protected remain highly reliable over the long term. Howe ver, the reboot-b ased proactive r ecovery scheme has a numb er of issues. First, it assum es that a simple reboot ( i.e., power cycle the computin g node) can suc- cessfully repair a compro mised node, which might not be the case, a s pointed out in [ 15]. Second, even if a com- promised nod e can be r epaired by a re boot, it is often a prolon ged process (typically over 30 s for modern operat- ing s ystems). During the rebootin g step, the B FT services might not be av ailab le to its clien ts ( e.g., if the reb oot- ing node happen s to be a no nfaulty replica needed for the replicas to reach a Byzantine agreemen t). Third, the re lacks coor dination among replicas to ensure that no more than a small portion of the rep licas (ide ally no more than f r eplicas in a system of 3 f + 1 replicas to toler ate up to f faults) are undergoing pro activ e recovery at any given time, o therwise, th e services may be un av ailab le fo r ex- tended period of time. The static watchdog timeout used in [4] also co ntributes to the pr oblem because it cann ot automatically adapt to various system loads. The stag- gered proactive r ecovery scheme in [4] is not sufficient to prevent th is problem from happen ing. In this paper, we presen t a novel proa cti ve recovery scheme based on service migr ation, which ad dresses all these issues. Our proac ti ve recovery scheme requires the av ailab ility of a pool of standby computing nodes in addi- tion to the acti ve nod es where the re plicas are deployed. The b asic id ea is outlin ed below . Period ically , th e repli- cas in itiate a pro activ e recovery by selecting a set o f ac- ti ve r eplicas, and a set of target stand by nod es for a ser- vice migratio n. At the en d of the service m igration, th e source active nodes will be put und er a series of preven- ti ve sanitizing and rep airing steps (su ch as reb ooting and swapping in a cle an ha rd drive with the origin al system binaries) be fore they are assigned to the poo l of stan dby nodes, and the target nodes ar e promo ted to the grou p of activ e nodes. The unique feature of th is design is that the sanitizing and rep airing step is carried out off the critical path of pr oactive recovery and consequently , it h as m in- imum negativ e impact on the av ailability of the services being protected. This paper makes the following r esearch contributions: • W e p ropo se a novel migratio n-based pro activ e re- covery scheme for lo ng-ru nning Byzantine fault tol- erant systems. The sch eme sign ificantly red uces the recovery time, and hen ce, the vulnerab ility win- dow , by movin g the time- consumin g replica sanitiz- ing and repairin g step off the critical path. • Our pro activ e recovery scheme ensures a coo rdi- nated period ical rec overy , which prevents harm ful excessi ve concur rent proacti ve recoveries. • W e presen t a comparison stud y on the perform ance of th e reboot-based and ou r migratio n-based proa c- ti ve recovery s chemes in th e presence of faults, bo th by analysis and by experimen ts. 2 System Model W e assume a partially asyn chrono us distributed system in that a ll message exchan ges an d processing related to proactive re covery can be co mpleted within a bo unded time. This bou nd can be initially set by a system ad - ministrator and can b e dynamically adjusted by the re - covery mech anisms. Howe ver , the safety pr operty of the Byzantine agreement o n all proacti ve recovery related de- cisions (such as the selection o f source nodes and desti- nation nodes for service migration) is maintained without any system synchrony requirement. W e assum e the av ailability of a pool of node s to serve as the stand by no des for service m igration, in addition to the 3 f + 1 active nod es requ ired to tolerate u p to f Byzan - tine faulty replicas. Th e poo l size is large enou gh to repair damaged nodes while enabling fre quent service m igration for proa cti ve recovery . Furtherm ore, both active nod es and stand by nodes can b e subject to m alicious attacks (in addition to oth er non-m alicious faults such as h ardware failures). Howe ver, we assume that the rate of success- ful attacks on the standby nodes is much smaller than that on active nodes, i.e., the tolerated successfu l a ttack rate on active no des is deter mined by the vulnerability win- dow the system can ac hieve, and the tolerated successful attack rate on standby n odes is determined by the r epair time. The allowed rep air time can b e much larger than the achiev able vulne rability window giv en a sufficiently large pool of standby nodes. If the above assumptions are violated, there is no hope to ach iev e long-term Byzantine fault tolerance. W e assum e the existence o f a trusted configu ration manager, as d escribed in [14, 15], to mana ge the p ool of standby nodes, and to assist service migra tion. Exam- ple tasks include frequen tly probing and mon itoring the health o f each standby n ode, and repairing any faulty n ode detected. W e will not discuss the mechanisms used by the manager to carry out such tasks, they are out of the scop e of this paper . Other assumptions regarding the system is similar to those in [4] and they ar e summarized h ere. All com - municating entities (clients, r eplicas and stand by nodes) use a secure hash function such as SHA1 to compu te the 2 digest of a message and use the message authen tication codes (MAC s) to au thenticate messages exchang ed, ex- cept fo r key exchan ge messages, which are pr otected by digital sig natures. For point to point message excha nges, a single MAC is included in each message, while multi- cast messages are protec ted by an authenticator [1]. E ach entity has a pair of p riv a te and p ublic keys. The active and standby nod es each is equipped with a secure copro - cessor an d sufficiently large read-on ly me mory . In th ese nodes, th e priv ate key is stored in the coprocessor and all digital signing a nd verification is carried out b y the co pro- cessor without revealing the priv ate key . The read -only memory is used to store th e execution code for the server application and the BFT framework. W e do not requ ire the presence of a hardware watchdog timer because of th e coordin ation of m igration an d th e existence o f a tru sted configur ation manager . Finally , we assume that an adversary is computatio nal bound so that it cann ot break the ab ove authentication scheme. 3 Pr oactive Service Migration Mechanisms The proactive service migration mec hanisms c ollectiv ely ensure the following objectives: 1. T o ensure that correct active replicas h av e a con- sistent membership view of the av ailable standby nodes. 2. T o determin e when to migra te and how to initiate a migration . 3. T o determine the set of source and target nodes for migration . 4. T o transfer a correct co py of the system state to the new replicas. 5. T o no tify the clients the n ew member ship after e ach proactive r ecovery . The first objectiv e is clearly need ed b ecause oth erwise the replicas cannot possibly agree on the set of target no des for migration. The second and third objectives are cr it- ical to en sure a coor dinated periodic proac ti ve recovery . R e p l i c a0 J O I N- R E Q U E S T Sa n t i z a t io n Pr o c e d u r e Up d a t e St a n d b yN o d es Me m b e r s h ip R e p l i c a1 R e p l i c a2 R e p l i c a3 R u nB F T a l g o r i t h mf o r Tot a lO r d e r i n go f J O I N - R E Q U E S T J O I N- A P P R O V E D S t a n d b y N o d e Figure 1: The protocol used for a standby node to register with active replicas. The four th objective is obviously necessary f or th e new replicas to start from a con sistent state. The fifth objec- ti ve is essential to ensure that the clients know the correct membersh ip of the server rep licas so that they do not ac- cept me ssages from po ssibly faulty replicas that ha ve b een migrated o ut of active ex ecuting duty , and they can send requests to the new replicas. 3.1 Standby Nodes Registration Each standby n ode is con trolled by the trusted configu - ration m anager and is u ndergoin g constant probing and sanitization proced ures such as reb oot. If the configur a- tion man ager suspects the n ode to b e faulty and cann ot repair it automatically , a system ad ministrator might be called in to manually fix the pr oblem. Each time a standb y node completes a sanitizatio n procedure , it notifies the ac- ti ve replicas with a J O I N - R E Q U E S T messag e in the form of < J O I N - R E Q U E S T , l , i s > σ i s , where l is the co unter value maintained b y the secure copr ocessor o f the standby no de, i s is the identifier o f the stan dby node, and σ i s is the au- thenticator . The r egistration protoco l is illustrated in Fig- ure 1. An active replica accep ts the J O I N - R E Q U E S T if it has not accepted one fro m th e same standby nod e with the same o r greater l . Th e J O I N - R E Q U E S T message, on ce ac- cepted by the p rimary , is orde red the same way as a reg- ular message with a sequ ence numb er n r , except that the primary also assigns a timestamp as the join tim e of th e 3 standby no de and piggyb acks it with the ord ering mes- sages. The total ordering of the J O I N - R E Q U E S T is imp or- tant so th at all acti ve no des have the same membersh ip view of the stan dby no des. The significance of the join time will be elaborated later in this section. When a replica executes th e J O I N - R E Q U E S T mes- sage, it sen ds a J O I N - A P P RO V E D message in the f orm of < J O I N - A P P RO V E D , l , n r > σ i to the requesting stand by node. T he requesting standby node m ust collect 2 f + 1 consistent J O I N - A P P RO V E D messages with the same l and n r from different a cti ve replicas. The standby nod e then initiates a key exchang e with all active replicas for futu re commun ication. A stan dby node might go throu gh multiple rou nds of proactive san itization before it is selected to run an activ e replica. Th e node sends a ne w J O I N - R E Q U E S T reconfirm - ing its mem bership af ter each ro und of sanitization. T he activ e replicas su bsequently updates the join time of the standby node. It is also possible that the configuration man ager deems a registered standb y node as faulty a nd it r equires a lengthy r epair, in which ca se, the configuratio n ma nager deregisters the faulty node from acti ve re plicas by send- ing a L E A V E - R E Q U E S T . Th e L E A V E - R E Q U E S T is handled by th e active r eplicas in a similar way as that f or J O I N - R E Q U E S T . In the un likely case that the faulty stand by node has bee n selected as the new activ e node , the mech- anisms react in the following ways: (1) if the mig ration is still ongo ing when the L E A V E - R E Q U E S T arriv es, it is aborted and restarted with a dif ferent set of target standby nodes, and (2) if the migration has been com pleted, an on-dem and service migration wi ll be initiated to sw ap out the faulty no de. T he on- demand service migration m ech- anism is rath er similar to the proactive migration me cha- nism, as will be discussed in Section 3.4. 3.2 Pr o active S ervice Migration When a nd How t o Initia te a P roactive Service Migra- tion? The pro activ e service m igration is tr iggered by the software-ba sed m igration timer main tained by each replica. T he tim er is reset and restar ted at t he end of each rou nd o f migratio n. ( An on-d emand ser vice migra- tion may also be carried out upon the n otification from the configuratio n manag er , as mentio ned in the previous subsection.) How to pr operly initiate a proactive service m igration, howe ver , is tricky . W e can not depend on the primary to initiate a proactive recovery because it might be faulty . Therefo re, th e mig ration initiation mu st involv e all repli- cas. On expir ation of the migr ation timer , a re plica choo ses a set of f acti ve rep licas, and a set of f standby nod es, and multicasts an I N I T - M I G R A T I O N request to all othe r replicas in the fo rm < I N I T - M I G R A T I O N , v , l , S, D , i> σ i , where v is the current vie w , l is the migratio n nu mber (de- termined by th e num ber o f successful mig ration rou nds recorde d by re plica i ), S is the set o f id entifiers fo r th e f activ e replicas to be migrated, D is th e set o f identifiers for the f standby nod es as th e targets o f the migr ation, i is the iden tifier for the sen ding replica, and σ i is the au- thenticator for the message. On recei ving an I N I T - M I G R A T I O N message, a replica j accep ts th e message and stores the m essage in its data structure provided that the message carries a v alid authen- ticator , it has n ot accep ted an I N I T - M I G R A T I O N message from the same replica i in view v w ith the same or higher migration numbe r , an d the replicas in S and D ar e c on- sistent w ith the sets de termined by itself a ccording to the selection algorithm (to be introdu ced ne xt). Each replica waits un til it has collected 2 f +1 I N I T - M I G R A T I O N messages from different replicas (includin g its o wn I N I T - M I G R AT I O N message ) be- fore it constructs a M I G R AT I O N - R E Q U E S T message. The M I G R AT I O N - R E Q U E S T message has the form < M I G R A T I O N - R E Q U E S T , v , l , S, D > σ p . The primary , if it is c orrect, sho uld place the M I G R AT I O N - R E Q U E S T message at the head o f the r equest queue and order it im mediately . The primar y orde rs the M I G R A T I O N - R E Q U E S T in the same way as th at f or a normal r equest coming from a client, except that (1) it does not batc h the M I G R A T I O N - R E Q U E S T message with normal requ ests, and (2) it piggyb acks the M I G R AT I O N - R E Q U E S T and the 2 f +1 I N I T - M I G R AT I O N m essages (as proof of v a lidity of the migr ation reque st) with th e P R E - P R E PA R E message . The reason fo r ordering the M I G R A T I O N - R E Q U E S T is to ensure a con sistent synchro nization po int for migration at all r eplicas. An illustration of the migration initiation protoco l is s hown as part of Figure 2. Each replica starts a view change timer when the M I G R A T I O N - R E Q U E S T message is constru cted (just like when it receives a no rmal requ est) so th at a vie w change 4 R e p l i c a0 Mi g r a t io n Ti m e rE xp i r e s Co n s t r uc t MI G R ATI ON - R E Q UE S T up o nc o l le c t i n g2f + 1 IN I T-M I G R A TI O N I NI T - M I G R A T I O N I n i t - M i g r a t i o n P h a s e S t a t e Tr a n s f e r P h a s e Tose l e ct e d st a n d b y no d e s R e p l i c a1 R e p l i c a2 Re p l i c a3 R u nB F T a l g o r i t h mf o r Tot a lO r d e r i n go f M I G R ATI O N - R E Q U E S T S y n c - P o i n t D e t e r m i n a t i o n P h a s e M IG R A T I O N - N O W ( wi t hc h e c k p o i n t ) Figure 2: T he proactive serv ice migration protoco l. will be initiated if the primary is faulty and does not order the M I G R AT I O N - R E Q U E S T message. The new primary , if it is not faulty , should contin ue this roun d of pr oactive migration . In this work , we cho ose not to initiate a v iew chan ge when the primary is migrated if the state is smaller than a tunable pa rameter (1 00KB is used in our experiment). For larger state ( i.e., when the cost of state transfer is m ore than tha t of the view change), th e pr imary multicasts a V I E W - C H A N G E me ssage bef ore it is migr ated, similar to [4]. Migration Set Selection. The selection of the set o f ac- ti ve r eplicas to be migrated is relatively straigh tforward. It takes f our ro unds o f mig ration (ea ch r ound for f repli- cas) to proactively re cover all activ e replicas at least once. The replicas are recovered acc ording to the reverse or- der of their identifiers, similar to that used in [4]. For example, fo r the very first rou nd o f migration, replicas with identifiers of 3 f , 3 f − 1 , ..., 2 f + 1 will be migrated, and this will be f ollowed by r eplicas with id entifiers of 2 f , 2 f − 1 , ..., f + 1 in the secon d rou nd, r eplicas with identifiers of f , f − 1 , ..., 1 in th e third r ound, and fin ally replicas with iden tifiers o f 0 , 3 f , ... 2 f + 2 in the f ourth round . (The example assume d f > 2 . It is straigh tfor- ward to deri ve the selections for the cases when f = 1 , 2 .) The selection is deterministic and can be easil y computed based on th e migration number . Note that the migration number con stitutes part of middleware state and will b e transfered to all recovering rep licas. Th e selection is in- depend ent of the view t he replicas are in. The selectio n of the set of s tandby n odes as the target of migration is based on the elapsed time since the stand by nodes wer e last sanitized. That is wh y each replica keeps track o f the jo in time o f each standby nod es. For each round of migration , the f standb y n odes with the least elapsed time will be chosen . This is out of co nsideration that the probab ility o f these no des to b e com promised at the time of mig ration is the least (assuming b rute-for ce attacks by adversaries). Migration Synchronizatio n Point Determinatio n. It is important to ensure all (correct) rep licas to use th e same synchro nization p oint when perf orming th e service mi- gration. This is achieved b y ordering the M I G R AT I O N - R E Q U E S T message. The pr imary starts to order the message by sen ding a P R E - P R E PA R E message for th e M I G R A T I O N - R E Q U E S T to all backup s, as descr ibed pre- viously . A back up verifies the p iggybac ked M I G R AT I O N - R E Q U E S T in a similar fashion as that f or the I N I T - M I G R A T I O N m essage, except now the replica mu st check that it h as received all the 2 f +1 init-migration mes- sages that the p rimary used to co nstruct the M I G R AT I O N - R E Q U E S T , and the sets in S a nd D match those in the I N I T - M I G R AT I O N messages. The back up requests the prim ary to r etransmit any m issing I N I T - M I G R A T I O N messages. The backup a ccepts th e P R E - P R E PA R E mes- sage f or the M I G R AT I O N - R E Q U E S T p rovided that the M I G R A T I O N - R E Q U E S T is correct and it has n ot accepted another P R E - P R E PAR E m essage for th e same sequence number in v iew v . From n ow on, the replicas executes accordin g to the three-p hase BFT algorithm [4] as usua l until they commit the M I G R AT I O N - R E Q U E S T . State T ransfer . When it is ready to execute the M I G R A T I O N - R E Q U E S T , a replica i takes a ch eckpoin t o f its state (both the app lication and the BFT middleware state), and multicasts a MI G R A T E - N O W m essage to the f stand by nodes selected. Th e M I G R AT E - N OW message has the f orm < M I G R A T E - N O W , v , n, C, P , i> σ i , where n is the seq uence num ber assigned to the M I G R A T I O N - R E Q U E S T , C is the digest o f the check point, and P con- tains f tuples. Each tuple con tains the identifiers of a source-n ode and target-node pair . The standby node d , once completes the proactiv e r ecovery procedure , 5 assumes the identifier s of the acti ve node it rep laces. A replica send s the actual checkp oint ( together with all queued request messages, if it is th e primary) to the target nodes in separate messages. If a replica be longs to the f n odes to be migrated , it per - forms the fo llowing add itional a ctions: (1 ) it stops accept- ing ne w request messages, and (2) it repor ts to the trusted configur ation manager as a can didate standby no de. This replica is th en hande d over to the c ontrol o f the co nfigu- ration manager for sanitization. Before a standby node can be promoted to run an acti ve replica, it mu st collect 2 f +1 con sistent M I G R A T E - N O W messages with the same sequ ence nu mber and the d igest of the che ckpoint from different active replicas. On ce a standby no de obtains a stable checkp oint, it applies the checkpo int to its state and starts to accept clients’ req uests and participate the BFT algorithm as an activ e replica. 3.3 New Membership Notification One can envisage that a fault node might want to continue sending messages to the active re plicas and the clients, ev en if it has b een migrated, bef ore it is sanitized b y the configu ration man ager . It is importan t to info rm the clients the new mem bership so th at they can igno re suc h messages sent b y the faulty replica. The memb ership in- formation is also imp ortant fo r the clients to ac cept me s- sages send by new activ e replicas, and to send messages to these replicas. Th is is guarante ed by the ne w membership notification mechanism. The new mem bership notification is p erform ed in a la zy manner to imp rove the perf ormanc e u nless a new acti ve replica assumes th e primary ro le, in which case, th e no ti- fication is sent immed iately to all known clients (so that the clients can send their requests to the new p rimary). Furthermo re, the notification is sent on ly by the existing activ e replicas ( i.e., n ot the new active re plicas because the clients do not kn ow them yet). No rmally , the n otification is sent to a client only after the client has sent a request that is ord ered after the M I G R AT I O N - R E Q U E S T message , i.e., th e sequence number assigned to the client’ s req uest is bigger than that of the M I G R AT I O N - R E Q U E S T . The notification message has the form < N E W - M E M B E R S H I P , v , n, P , i> σ i (basically the same a s the M I G R A T I O N - N O W message without the checkpoin t), where v is the v iew in which the migr ation occurr ed, and n is the seq uence num ber assigned to the M I G R A T I O N - R E Q U E S T , and P c ontains the tuples of th e iden tifiers for the r eplicas in the previous and th e new mem bership. Note all activ e replicas should hav e the information. When a client collects f + 1 consistent N E W - M E M B E R S H I P messag es from different r eplicas, it up - dates its state accor dingly and starts to accept rep lies from, and to send requests to, the new replicas. 3.4 On-Demand Migration One demand migration can ha ppen whe n the co nfigura- tion m anager d etects a node to be faulty after it has been promo ted to ru n an active replica. I t can also h appen when r eplicas have collected solid evidence that on e or more replicas are faulty , su ch as a ly ing primary . The on-dem and migratio n mechan ism is rather similar to that for proactive recovery , with only tw o differences: (1 ) The migration is in itiated o n-deman d, rather th an b y a m igra- tion timeout. Howe ver , replicas still must exchange the I N I T - M I G R A T I O N m essages before the migration can take place; (2) T he selection pr ocedur e for the sourc e no de is omitted bec ause the no des to be swapped out a re alre ady decided, and the s ame number of target nodes are selected accordin gly . 4 Benefits of Pr oactive Service Mi- gration 4.1 Reduced V ulnerability Window The primary b enefit of u sing the m igration- based p roac- ti ve recovery is a reduced vulnerability window . The term vu lnerability win dow (or window of vulner ability) T v = 2 T k + T r is in troduced in [ 4]. Here T r is the time elapsed between when a replica becomes faulty and when it fully recovers from the fault, an d T k is th e key refre sh- ment perio d. As lon g as n o mo re than f replicas b ecome faulty during the window of T v , the inv ariants for Byzan- tine fault tolerance will be preserved. In the r eboot-b ased proa cti ve r ecovery scheme, the vul- nerability windo w T pr v is character ized to be 2 T k + T pr w + R n , as shown in the upper half of Fig ure 3, wh ere T pr w is the watchdo g timeout, R n is th e recovery time for a no n- faulty rep lica un der nor mal load con ditions. The do mi- 6 R n T re b o ot T r 2 T k T s pr T w pr T v pr R n T r 2 T k T s pm T w pm T v pm R n T s pm T w pm R n T s pm T w pm R n T s pm T w pm Figure 3: V arious time inte rvals used in mod elling the vulnerab ility wind ows for th e two proactive recovery schemes. nating factors for rec overy time in clude T r eboot , the re- boot time, and T pr s , the time it takes to save, restor e and verify th e rep lica state. The watchdog time out T pr w is set rough ly to 4 R n to ena ble a stagg ered proactive recovery of f replicas at a time. The composition of the vulne rability wind ow f or the migration -based proacti ve recov ery is shown in the lower half of Figur e 3. The time in tervals s pecific to m igration- based pro activ e recovery is labeled by the pm su per- script. Because the migration is co ordinated in this recov- ery scheme, no watchdog timer is used and th e term T pm w is now interpr eted as the migratio n timer, i.e., th e time elapsed between two consecu ti ve rounds of migra tions of f rep licas each. This is very different from the watch- dog timeout T pr w , wh ich is statically co nfigured pr ior to the start of each replica. Because the recovery time in the migration -based proactive recovery is much shorter than that in the reboot-b ased rec overy , and the migration is co- ordinated , it takes mu ch shorter time to fully r ecovery all activ e rep licas once. Hence , T r can b e muc h shor ter fo r the m igration- based rec overy , wh ich leads to a smaller vulnerab ility window . 4.2 Increased A vailability in the Pr esence of Faults Under fault-fre e con dition, n either the r eboot-b ased nor the mig ration-b ased rec overy scheme has much negative impact to the runtime p erform ance u nless the state is very large, as s hown in the experimental data in [4 ] and in Sec - tion 5 o f this paper . Howe ver , in the p resence of faulty nodes, the system availability can b e reduced significan tly in the reboot- based proactive recovery scheme, wh ile the reduction in av ailab ility remains small in our migration- based recovery s cheme. The s ee the benefit of the migration-b ased pr oactive re- covery regarding the system availability in the presence of faults, we con sider a specific case when th e numb er of faulty no des is f and f = 1 . While developing a thor- ough analytical model is c ertainly desirable, it is ou t of the scope of this paper . W e assume tha t th ere are f = 1 faulty rep lica at the beginning o f the set o f fo ur r ound s o f mig ration to erad- icate it. (Recall that we assume tha t at most f re plicas can b e compr omised in one v ulnerability wind ow , which constitutes fo ur roun ds proactive recovery of f rep licas at a time and 2 T k , ther efore, it is not possible to end up with m ore tha n f faulty rep licas with this assumption .) W e f urther assum e that the proactive recovery roun ds af- ter the removal o f the faulty r eplica has n o negative imp act on th e system av ailability , and so does the case when the faulty rep lica is recovered in th e same r ound of r ecovery . W e a lso ignore the differences between the recovery time of a norm al replica and t hat of a faulty one. Since f = 1 , the faulty node mu st be rec overed in one of th e fou r ro unds of recovery . Assumin g that th e faulty node is ch osen r andom ly , it is recovered in ev en prob a- bility in either o f the fou r ro unds, i.e., P i = 0 . 25 , where i = 0 , 1 , 2 , 3 . If the faulty replica is recovered in th e first round of recovery , there is no reduction of system a vail- ability q 0 ( i.e., q 0 = 1 ). If the faulty replica is recov- ered in ro und i , where i = 1 , 2 , 3 , the sy stem will not b e av ailab le while a r eplica is recovering during each r ound because there will be insufficient number of correct repli- cas until th e recovery is completed, and hence, the system av ailab ility q i in this case will be determin ed as q i = P i T v − iR n T v (1) Therefo re, t he total system av ailability is q = 3 X i =0 q i = 0 . 25 3 X i =0 T v − iR n T v (2) For th e r eboot-b ased recovery , R n ≈ T r eboot + T pr s , and for the migratio n-based recovery , R n ≈ T pm s . It 7 0 0.2 0.4 0.6 0.8 1 50 100 150 200 250 300 System Availability Vulnerability Window (in seconds) (b) Minimum T v pr Minimum T v pm Parameter Used: T reboot =30s, T s =10s, T k =15s Reboot-Based Proactive Recovery Migration-Based Proactive Recovery 0 0.2 0.4 0.6 0.8 1 10 20 30 40 50 60 70 80 90 100 System Availability Reboot Time (in seconds) (a) Parameter Used: T v =210s, T s =10s Reboot-Based Proactive Recovery Migration-Based Proactive Recovery Figure 4: An analy tical comparison o f the system a vail- ability b etween the rebo ot-based proactive r ecovery and the migration -based recovery . (a) Wi th a fixed v ulnera- bility window of 210 s and various re boot time. (b) Wit h fixed recovery time and various vulnerability window set- tings. is n ot un reasonable to assume T pr s ≈ T pm s because the network ba ndwidth is similar to the disk IO band width in modern gener al-purp ose systems. As shown in Fig- ure 4(a) , the migr ation-based recovery can achieve much better system av ailability if the reboot time T r eboot is large, which is generally th e case. Fur thermor e, as indi- cated in Figure 4(b), for the range of vu lnerability window considered , the system av a ilability is consistently higher for the migra tion-based p roactive r ecovery than that f or the reboot-b ased proacti ve recovery . 5 Pe rf ormance Evaluation The proactive serv ice mig ration mech anisms h av e b een implemented a nd inco rporate d into the BFT fram ew ork developed b y Castro, Rodriguos and Liskov [2, 3, 4, 5]. Due to the p otential large state, an optimization ha s b een made, similar to the optimization o n the reply m essages in the o riginal BFT fra mew ork, i.e., instead o f every replica sends its checkpoint to the target nodes o f migration , only one actually sends the full check point. The target no de can verif y if th e copy o f the full check point is corr ect by comparin g the digest of the checkp oint with the dige sts received from the replicas. If the check point is not co r- rect, the target no de ask s fo r a retran smission fro m o ther replicas. Similar to [4], the p erform ance measureme nts are car- ried out in gen eral-pur pose servers withou t har dware co- processors. The related oper ations ar e simulated in sof t- ware. Fu rthermo re, the trusted configu ration manager is not dev eloped as this is on e of th e n o go als of this pa- per . Th e motiv ation of th e measu rements is to assess the runtime perfor mance of the proactive service migration scheme for practical use. Our testbed consists of a s et of Dell SC440 servers c on- nected by a 100 Mbp s local-a rea network. Each server is equippe d with a single Pentium dual-co re 2.8GHz CPU and 1GB of RAM, and runs the SuSE Lin ux 10.2 oper a- tion system. The mic ro-ben chmarkin g example included in the o riginal BFT fram ew ork is adapted as the test ap- plication. The request and reply message length is fixed a t 1KB, and each client g enerates requests consecutively in a loop without any think time. Each server replica simply echoes the payload in the request back to the client. Four active no des, f our stand by nod es, and up to eig ht client no des are used in the experiment. This setup can tolerate a single Byzantine faulty replica. Th e service mi- gration interval is set to 70 s , cor respond ing to the mini- mum possible vulnera bility window fo r a key exch anged interval of 15s a nd a ma ximum recovery tim e (for a single replica) of 10 s . T o ch aracterize the runtime co st of the service migra- tion scheme, we measure the recovery time for a single replica with and witho ut the pre sence of clients, and the impact of pr oactive migr ation on the system perform ance perceived by clients. Th e re covery time is d etermined by measuring the time elapsed between th e following two ev ents: (1 ) the p rimary sending the P R E - P R E PA R E mes- sage for the M I G R AT I O N - R E Q U E S T , and (2) the primary receiving a notification from the target stand by node in- dicating that it has collected and ap plied th e latest stable checkpo int. ( The notification m essage is not p art of the 8 0 2 4 6 8 10 0 2 4 6 8 10 Service Migration Latency (in seconds) State Size (in MB) (a) With One Client Without Client 0 2 4 6 8 10 12 0 1 2 3 4 5 6 7 8 Service Migration Latency (in seconds) Number of Clients (b) 5MB State 1MB State 512KB State 0 10000 20000 30000 40000 50000 60000 0 2 4 6 8 10 Number of Calls Made (in 70 seconds) State Size (in MB) (c) With No Migration and No Fault With No Migration and One Faulty Replica Fault-Free Condition With One Faulty Replica Figure 5: (a) Service migration latency for dif ferent state sizes measured when (1) the replicas are idle (other than the service migration acti vity), labeled as “W itho ut Client” and (2) in the presence of one client. (b ) The impact o f system load on th e migr ation latency . (c) The imp act of proactive migration on system perf ormance (witho ut and with one crashed replica) , as observed by a single client in term s of the number of calls made within one vu lnerability window (70 s ). recovery protoco l. It is inser ted solely for the purpo se of perfor mance mea surements.) W e refer to this time inter- val as the serv ice migration laten cy . Th e impact o n the system perform ance is measured at the client by counting the nu mber of calls it has mad e du ring one vulnerability window , with and without proa ctiv e migr ation-based re- covery . The m easurement r esults ar e summ arized in Figure 5. Figure 5(a) shows the service mig ration latency for var- ious state sizes (from 100KB to ab out 10MB). It is n ot surprising to see that the cost of migratio n is limited by the band width av ailable (1 00Mbp s) because in our ex- periment, the time it takes to take a local checkpoint ( to memory ) and to restore one (from memor y) is negligible. This is intentiona l for two reason s: (1) the ch eckpoin ting and restoration cost is very application depend ent, an d (2) such cost is the sam e regardless of the proactive recovery schemes used. Furthermo re, we measure the migration laten cy as a function o f the system load in term s of the num ber of concur rent c lients. The results are sho wn in Figur e 5(b ). As can be seen, the mig ration latency increases more sig- nificantly fo r larger state when th e system lo ad is hig her . When there are eigh t concurren t clients, the migr ation la- tency for a state size of 5 MB exceeds 10 s , which is th e maximum recovery time we assume d in our availability analysis. This o bservation suggests the need fo r dynamic adjusting of some par ameters r elated to th e vulner ability window , in particular, the watchdog timeou t used in the reboot- based r ecovery schem e. If the watchdog timeou t is too short for the system to go throug h f our round s of proactive recovery (of f rep licas at a time), th ere will b e more than f replicas going through proactive recoveries concur rently , which will d ecrease the system av ailability , ev en wi thout any fault. Ou r migration-based proactive re- covery does no t suffer from this prob lem. Due to the use of coor dinated recovery , when the system load incr eases, the vuln erability windo w automatically increases. Figure 5(c) shows the perfor mance impact of proactive service migra tion as perceived by a single client. In the experiment, we cho ose to use the par ameters consistent with those used in the availability analysis (for migration- based r ecovery), i.e., key excha nge p eriod of 15 s , maxi- mum recovery time of 10 s , and a vulnerab ility window of 70 s . As can be seen , the impact o f p roactive mig ration on the system perfo rmance is quite acceptable. For a state smaller than 1MB, the throughp ut is reduced only by 10 % or less compar ing with the no-pro activ e-recovery case. In addition, we have mea sured the migration performa nce in the presence of one (crash ) faulty replica (the recovering recovery is different fr om the crashed replica). The sys- tem th rough put degradation is similar to that in fault-free condition . Note that when there are only three correct replicas, the system throu ghpu t is redu ced even without 9 proactive m igration, as shown in the figure . 6 Related W ork Ensuring Byzantin e fault tolera nce for long -runn ing sys- tems is an extremely challenging task. Th e pioneerin g work is carried out by Castro and L iskov . In [4], they propo sed a reboot-based pr oactive recovery scheme as a way to r epair com promised nodes perio dically . The work is further extended by Rodrigues an d Liskov in [15]. They pro posed additio nal infr astructure support and re- lated mechanisms to han dle the cases when a da maged replica c annot be repair ed by a simple reboo t. Our work is inspired by bo th work. Th e novelty and the benefits o f our service-migr ation scheme o ver the reboo t-based pro activ e recovery scheme hav e been elaborated in Section 4. Other related work includ es [ 12]. I n [12], Pallemulle et a l. extended the BFT algo rithm to hand le replicated clients and introduced another B yzantine agreement (B A) step to ensure th at all replicated clients receive the same set of replies. I t was claim ed that the mechanisms can also be used to per form o nline upgr ading, which is im- portant fo r long -runn ing applications and not add ressed in our work. However , it is not clear if the B A step on the replies is useful, while incurring significantly higher cost. If there are more than f compro mised server replicas, the integrity of the service is alre ady bro ken, in wh ich case, there is no use f or th e client replicas to r eceiv e the same faulty reply . Finally , the reliance on extra no des beyo nd the 3 f + 1 activ e no des in our scheme may so mewhat relates to th e use of 2 f add itional witness replicas in the f ast Byzantine consensus algorithm [10]. However , the extra no des are needed for co mpletely different purposes. In our schem e, they are requ ired fo r pr oactive recovery for lon g-run ning Byzantine fault tolerant systems. In [10], h owe ver, they are needed to reach Byzan tine co nsensus in fewer mes- sage delays. 7 Conclusion In this paper, we pr esented a novel proactive recov- ery scheme based on service migra tion f or long-ru nning Byzantine fault tolerant systems. W e described in detail the challenge s an d mechanisms needed for o ur migration- based proac ti ve recovery to work . Th e migr ation-based recovery scheme has a n umber of un ique benefits over previous work, in cluding a smaller vulne rability wind ow by shifting the time-co nsuming r epairing step out of the critical re covery path, h igher system a vailability un der faulty con ditions, and self-adaptation to different system loads. W e validated these benefits bo th analytically and experimentally . For future work, we plan to investigate the design and imp lementation of the trusted config ura- tion manag er , in p articular, the inc orpora tion of the cod e attestation metho ds [6, 8] into the fault detection mecha- nisms, and the application of the mig ration-b ased r ecov- ery scheme to practical systems such as networked file systems. Refer ences [1] M. Castro and B . Liskov . Authenticated Byzantine fault tolerance without pu blic-ke y cryptography . T echnical Re- port MIT -LCS -TM-589, MIT , June 1999. [2] M. C astro and B. Lisko v . P ractical Byzantine fault toler- ance. In Pr oceedings of the T hir d Symposium on Oper- ating Systems Design and Implementation , New Orleans, USA, February 1999. [3] M. Castro and B. L isko v . Proactiv e recov ery in a Byzantine-fau lt-tolerant system. In Proc eedings of the Thir d Symposium on Operating Systems Design and Im- plementation , San Diego, USA, October 2000. [4] M. C astro and B. Lisko v . P ractical Byzantine fault toler- ance and proacti ve recov ery . A CM T ransac tions on Com- puter Systems , 20(4):398–46 1, Nov ember 2002 . [5] M. Castr o, R. Rodrigues, and B. Liskov . BASE: Using abstraction to improv e fault tolerance. ACM T ransa ctions on Computer Systems , 21(3):236–2 69, August 2003 . [6] B . Chen and R. Morris. Certifying program e xec ution with secure processors. In Pr oceedings of the 9th W orksho p on Hot T opics in Operating Systems , May 2003. [7] J. Cowling, D. Myers, B. Liskov , R. R odrigues, and L. Shrira. HQ R eplication: A Hybrid quorum protocol for Byzantine fault tolerance. In Procee dings of the Seventh Symposium on Operating Systems Design and Implemen- tations , Seattle, W ashington, No vember 2006. [8] T . Garfinkel, B . Pfaf f, J. Chow , M. Rosenblum, and D. Boneh. T erra: A virtual machine-based platform for trusted comp uting. I n Procee dings of the 19th Sympo sium on Operating System Principles , October 200 3. 10 [9] L. Lamport, R. Shostak, and M. Pease. The Byzantine generals problem. A CM T ransactions on Pro gramming Langua ges and Systems , 4(3):382–401, July 1982. [10] J. Martin and L. Alvisi. F ast Byzantine C onsensus. IEEE T ransa ctions on Dependable and Secur e Comput- ing , 3(3):202–21 5, July-September 20 06. [11] M. Merideth, A. Iyengar , T . Mikalsen, S. T ai, I. Rouvel- lou, and P . Narasimhan. Thema: Byzantine-fault-tolerant middle ware fo r web service s applications. In Pr oceeding s of the IEEE Symposium on Reliable Distributed Systems , pages 131–142 , 2005. [12] S. Pallemulle, L . W ehrman and K. Goldman. Byzantine fault tolerant execution of long-running distributed appli- cations. In Pro ceedings of the IASTED International Con- fer ence on P arallel and Di stributed Computing and Sys- tems , Dallas, TX, Nov ember 2006 . [13] S. Rhea, P . Eaton, D. Geels, H. W eatherspoon, B. Zhao, and J. Kub iatowicz. P ond: the OceanStore prototyp e. In Pr oceedings of the 2nd USENIX Confer ence on File and Stora ge T echnolo gies , March 2003. [14] R. Rodrigues and B. Liskov . Rosebud: A scalable Byzan- tine fault-tolerant storage architecture. T echnical Report MIT CSAIL TR/932, MIT , December 2003 . [15] R. Rodrigues and B. Li sko v . Byzantine fault tolerance in long-lived systems. In Pr oceedings of the 2nd W ork- shop on Futur e Dir ections in Distrib uted Computing , June 2004. [16] J. Y in, J.-P . Martin, A. V enkataramani, L. Alvisi, and M. Dahlin. S eparating agreement from ex ecution fo r byzantine fault tolerant services. In Pr oceeding s of the ACM Symp osium on Operating Systems Principles , pages 253–26 7, Bolton Landing, NY , USA, 2003. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment