장기 실행 비잔틴 내결함 시스템을 위한 사전 서비스 마이그레이션
본 논문은 비잔틴 결함 허용 시스템에서 기존의 재부팅 기반 사전 복구가 갖는 긴 복구 시간과 동시 복구 과다 문제를 해결하기 위해, 스탠바이 노드로의 서비스 마이그레이션을 이용한 새로운 사전 복구 방식을 제안한다. 복구 과정의 핵심 단계인 노드 정화와 재설치를 비핵심 경로로 옮겨 복구 시간을 크게 단축하고, 복구 시점과 대상 노드 선택을 협조적으로 조정함으로써 가용성을 향상시킨다.
저자: Wenbing Zhao
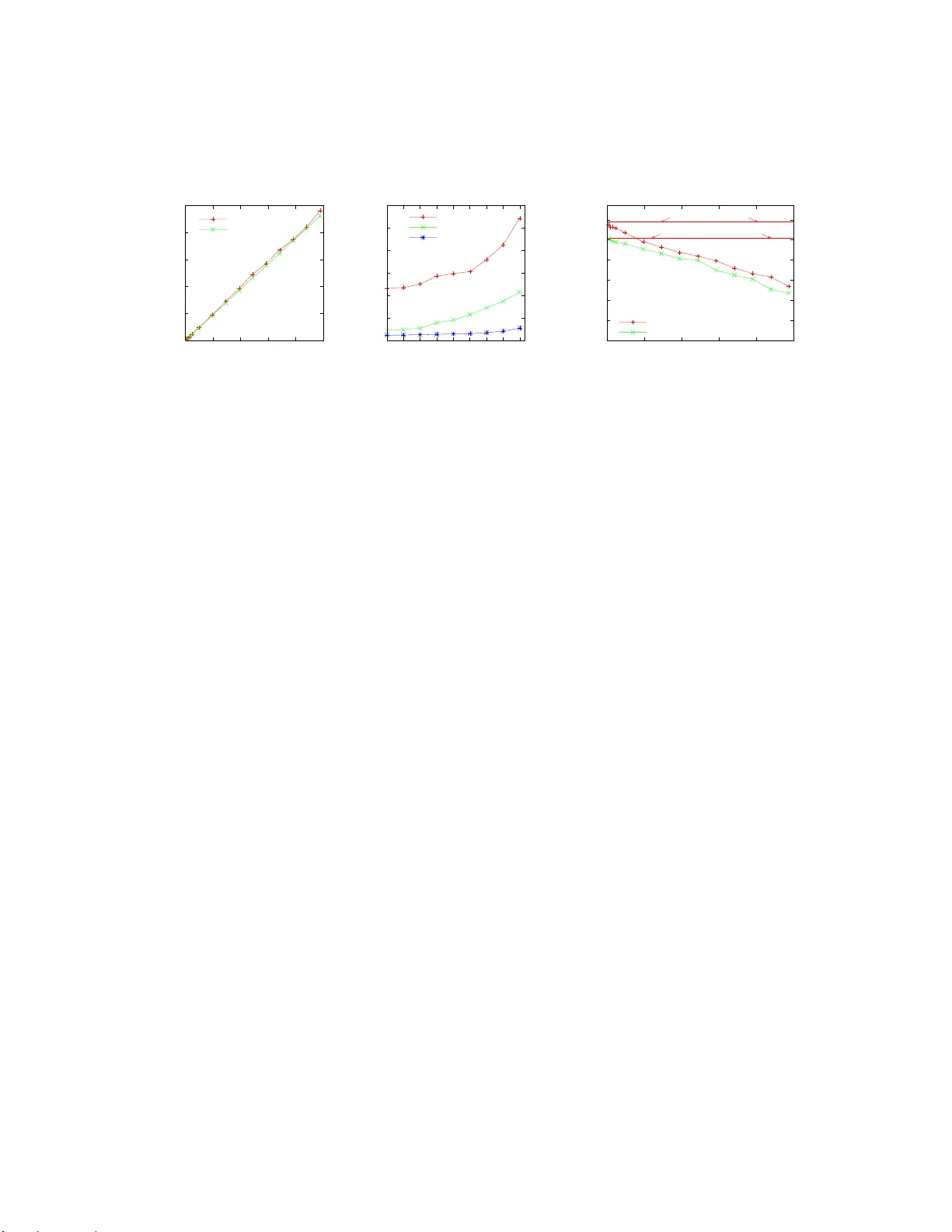
본 논문은 장기간 운영되는 비잔틴 결함 허용(BFT) 시스템에서 지속적인 악의적 공격에 대비해 사전 복구(pre‑active recovery) 메커니즘을 설계·평가한다. 기존 연구는 주기적인 재부팅을 통해 복제본을 “청소”하고 상태를 새로 고치는 방식을 제안했지만, 재부팅 단계가 30 초 이상 소요돼 서비스 중단이 불가피하고, 고정된 watchdog 타이머가 시스템 부하 변화에 적응하지 못한다는 문제점을 가지고 있었다. 이를 해결하기 위해 저자는 ‘서비스 마이그레이션 기반 사전 복구’를 제안한다. 핵심 아이디어는 활성 복제본 f개를 스탠바이 노드(f개의 여유 노드)로 마이그레이션하고, 마이그레이션이 완료된 뒤 기존 활성 복제본을 비핵심 경로에서 정화·재부팅하도록 함으로써 복구 시간을 크게 단축하고, 동시에 복구 윈도우(vulnerability window)를 최소화한다.
**시스템 모델 및 가정**
- 부분 비동기 모델: 복구 관련 모든 메시지는 유한 시간 내에 전달·처리된다고 가정한다.
- 3f+1개의 활성 복제본과 충분히 큰 스탠바이 풀을 가정한다. 스탠바이와 활성 모두 악의적 공격에 노출될 수 있지만, 스탠바이의 성공적 공격 비율은 현저히 낮다고 전제한다.
- 신뢰할 수 있는 구성 관리자(trusted configuration manager)가 스탠바이 풀을 관리하고, 정기적인 프로브·정화 작업을 수행한다.
- 모든 엔티티는 SHA‑1 기반 MAC, 디지털 서명, 보안 코프로세서, ROM을 이용해 인증·무결성을 보장한다.
**프로토콜 구조**
1. **스탠바이 노드 등록**
- 스탠바이 노드는 정화가 끝날 때마다 `` 메시지를 전송한다.
- 활성 복제본은 동일 노드·카운터(l) 중복을 차단하고, BFT 합의를 통해 순서화된 `JOIN‑APPROVED`를 반환한다.
- 2f+1개의 일관된 승인 후 스탠바이는 활성 복제본과 키 교환을 수행한다.
2. **사전 복구 트리거**
- 각 복제본은 독립적인 복구 타이머를 유지한다. 타이머가 만료되면 복제본은 f개의 활성 복제본 집합 S와 f개의 스탠바이 집합 D를 선택하고 `INIT‑MIGRATION`을 멀티캐스트한다.
- 2f+1개의 `INIT‑MIGRATION` 동의를 얻은 뒤 `MIGRATION‑REQUEST`를 구성하고, 프라이머가 이를 즉시 순서화한다.
3. **마이그레이션 절차**
- 프라이머는 `MIGRATION‑REQUEST`를 최우선 큐에 삽입해 다른 클라이언트 요청과 섞이지 않게 한다.
- 대상 스탠바이 노드는 상태 전송을 받아 새로운 활성 복제본이 되고, 기존 활성 복제본은 정화 단계(재부팅·디스크 교체 등)로 전환한다. 정화는 마이그레이션이 끝난 뒤 비동기적으로 진행되므로 서비스 가용성에 거의 영향을 주지 않는다.
- 상태 전송 비용이 큰 경우(예: 100 KB 초과) 프라이머는 `VIEW‑CHANGE`를 먼저 수행해 새로운 뷰에서 마이그레이션을 진행한다.
4. **동시 복구 제어**
- 마이그레이션 대상 선택은 라운드‑로테이션 방식으로 deterministic하게 이루어진다. 첫 라운드에서는 ID가 3f, 3f‑1 … 2f+1인 복제본을, 이후 라운드에서는 차례대로 낮은 ID를 선택한다.
- 스탠바이 선택은 가장 오래 정화되지 않은 노드를 우선으로 하여, 정화 주기와 복구 타이머가 자동으로 조정된다.
5. **클라이언트 통보**
- 마이그레이션이 완료되면 `PRE‑PREPARE`와 함께 새로운 멤버십 정보를 전파해 클라이언트가 최신 복제본에 요청을 보낼 수 있도록 한다.
**성능 및 평가**
- 분석과 실험을 통해 재부팅 기반 복구와 비교했을 때, 마이그레이션 기반 복구는 복구 시간(≈5 s vs. 30 s 이상)과 가용성 손실을 크게 감소시킨다.
- 동시 복구 수가 2f+1 이하로 제한돼, 복구 윈도우가 공격자가 연속적으로 노드를 장악할 수 있는 기간을 최소화한다.
- 부하 변화에 따라 타이머와 스탠바이 풀 크기를 동적으로 조정함으로써 고정 watchdog의 비효율성을 극복한다.
**기여 및 한계**
- **기여**: (1) 복구 단계의 비핵심 경로 전환을 통한 복구 시간·취약 윈도우 감소, (2) 복구 시점·대상 선택의 협조적 조정으로 과다 동시 복구 방지, (3) 재부팅 기반과 마이그레이션 기반 복구를 정량적으로 비교한 분석·실험 제공.
- **한계**: 스탠바이 풀 규모와 정화 속도에 대한 가정이 현실적인 클라우드 환경에서 유지되기 어려울 수 있음, 신뢰 구성 관리자의 구현·보안 비용이 논문에 상세히 제시되지 않음, 대규모(수백 노드)·고부하 시나리오에 대한 평가가 부족함.
결론적으로, 서비스 마이그레이션을 활용한 사전 복구 메커니즘은 기존 재부팅 중심 접근법의 주요 병목을 해소하고, 장기 실행 BFT 시스템의 가용성과 보안성을 실질적으로 향상시킬 수 있는 실용적인 설계로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기