Network Coding for Distributed Storage Systems
Distributed storage systems provide reliable access to data through redundancy spread over individually unreliable nodes. Application scenarios include data centers, peer-to-peer storage systems, and storage in wireless networks. Storing data using a…
Authors: Alex, ros G. Dimakis, P. Brighten Godfrey
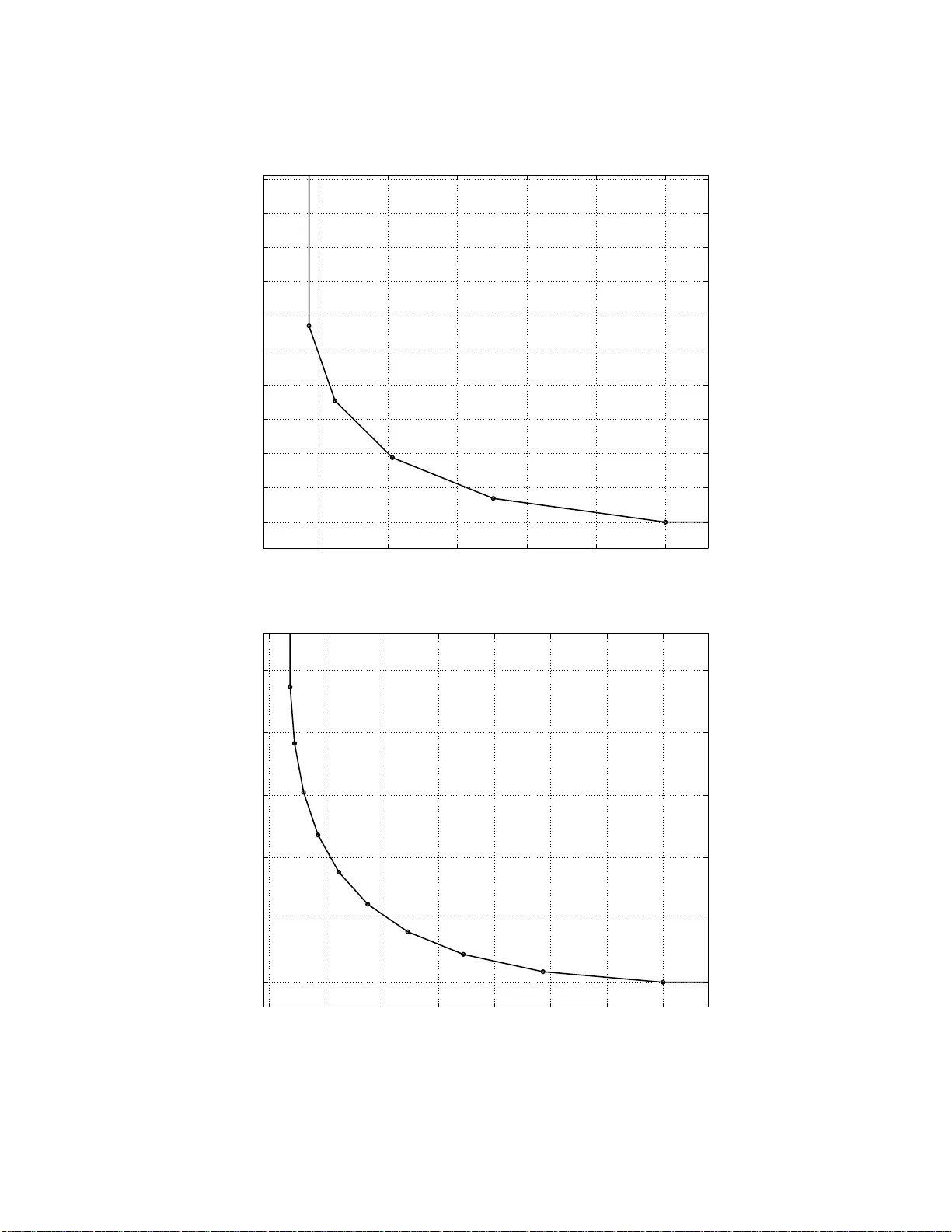
1 Netw ork Coding for Distrib ute d Storage Systems Alexandros G. Dimakis, P . Brighten Godfrey , Y unnan W u, Martin O. W ainwright and Ka nnan Ramc handran Department o f Electrical Engine ering an d Compute r Science , Univ ersity of California, Berkeley , CA 9 4704. Email: { adim, pbg , wainwrig, kannan r } @eecs.berkeley .edu and yunnanw u@microsoft.com Abstract —Distributed storage systems provide reliable access to d ata th rough redundancy spread over individually unreliable nodes. Application scenarios includ e data centers, peer-to-peer storage systems, and storage in wireless n etworks. Storin g data using an erasure code, in fra gments spread acro ss nodes, requires less redundancy than simple replication for the same level of reliability . Ho wever , sin ce fragments must be periodically replaced as nodes fail, a key question is h ow t o generate encoded fragments in a d i stributed way wh ile transferring as little data as p ossible across the network. For an erasure coded system, a common practice to repair from a node failure is f or a new node to download subsets of data stored at a number of surv iving nodes, reconstruct a l ost coded bl ock using the downloaded data, and store it at the new node. W e show that th is procedure is sub-opt i mal. W e i n troduce the notion of r egenerating codes, which allo w a new node to download functions of the stored data from the su rvi ving nodes. W e show th at regenerating codes can significantly r educe the repair bandwidt h. Further , we show that th ere is a fundamental tradeoff b etween storage and repair bandwidth which we theo- retically ch aracterize u sing flow arguments on an appropriately constructed graph. By in voking constructive results in network coding, we introduce regenerating codes th at can achiev e any point in t h is optimal tradeoff. I . I N T RO D U C T I O N The pu rpose of distributed storage systems is to store da ta reliably over long periods of time using a distrib u ted collection of storag e nodes which may be ind ividually unr eliable. A ppli- cations inv o lve storage in large d ata centers and peer-to-peer storage systems such as Oce anStore [3], T otal Recall [4], an d DHash++ [ 5], that use nodes acr oss the Internet for d istributed file stor age. In wireless sen sor ne tworks, obtaining reliab le storage over un reliable mo tes migh t be desirable for robust data recovery [6 ], especially in catastro phic scenarios [7]. In all these scenarios, ensur ing reliability r equires the in- troductio n o f redu ndancy . The simplest form of redundan cy is replication, which is adopte d in m any practical stora ge systems. As a generalization of replication, erasure cod ing offers better storage efficiency . For instance, we can di vide a file of size M into k p ieces, each of size M / k , en code them into n c oded pieces u sing an ( n, k ) maxim um distance separable (MDS) code, and store them at n n odes. Then , the original file can be r ecovered from any set of k c oded pieces. Results in thi s paper have appe ared in part in [1] and [2]. Fig. 1. The repai r problem: Assume that a (4,2) MDS erasure code is used to generate 4 fragments (stored in nodes x 1 , . . . x 4 ) with the property that any 2 can be used to reconst ruct the origin al data y 1 , y 2 . W hen node x 4 fail s, and a ne wcomer x 5 needs to generate an erasure fragment from x 1 , . . . x 3 , what is the mini mum amount of informat ion tha t needs to be communicate d? This perform ance is optimal in terms of the redun dancy– reliability tradeoff b ecause k pieces, each of size M /k , provide th e min imum data for rec overing the file, which is o f size M . Several designs [8], [4], [5] use erasure cod es in stead of replication. F or certain cases, er asure cod ing can ach iev e orders of m agnitude high er reliability for the same red undancy factor comp ared to replication ; see, e.g., [9 ]. Howe ver, a com plication arises: In distributed sto rage sy s- tems, red undan cy must b e contin ually refreshed as nodes fail or leave the system, wh ich inv o lves large d ata transfer s acr oss the n etwork. This p roblem is best illustrated in the simple example o f Fig. 1: a data object is divided in two fragm ents y 1 , y 2 (say , each of size 1 Mb) and the se enco ded into fo ur fragmen ts x 1 , . . . x 4 of same size, with the pro perty that any two o ut o f the fo ur can be used to recover the original y 1 , y 2 . Now assume that storage no de x 4 fails and a new n ode x 5 , the newcomer, needs to com municate with existing nodes and create a new encoded packet, such that any two out of x 1 , x 2 , x 3 , x 5 suffice to recover . Clearly , if the newcomer can download any two enco ded frag ments ( say from x 1 , x 2 ), reconstruc tion of the whole data o bject is possible and then a new en coded frag ment can be g enerated (fo r example b y making a new lin ear com bination th at is indep endent f rom the existing ones). This, howe ver , req uires the commu nication of 2 Mb in th e network to gene rate an erasure encod ed frag ment of size 1 Mb at x 5 . In ge neral, if an object of size M is di vided in k initial fr agments, the rep air ban dwidth with this strategy 2 Fig. 2. Example: A repair for a (4,2)-Minimum-Storage Re generating Code. All the pack ets (boxes) in th is figure ha ve size 0 . 5 Mb and each node stores two pack ets. Note that any two node s ha ve four equations that can be used to recov er the data, a 1 , a 2 , b 1 , b 2 . T he parity pack ets p 1 , p 2 , p 3 are use d to create the two pac kets of the newcome r , requiring repair bandwidth of 1 . 5 MB. The multiplying coeffici ents are select ed at random and the exa mple is shown ov er the inte gers for simpli city (alt hough any suf ficiently larg e field w ould be enough). The key point is that nodes do not send their information but generate smalle r parity pack ets of their data and forw ard them to the ne wcomer who furthe r m ixe s them to gener ate two ne w packet s. Note that the sel ected coef ficients also need to be includ ed in the packets, which introduc es some ov erhead . is M bits to gen erate a fra gment of size M / k . I n co ntrast, if replication is used instead, a ne w replica may simply be copied from any other existing node, incurring no ban dwidth over- head. It was comm only believ ed that this k -factor overhead in repair bandwidth is an un a voidable overhead th at comes with the benefits of coding (see, for example, [10]) . I ndeed, all known cod ing co nstructions r equire access to th e o riginal data object to ge nerate encoded fr agments. In this pap er we show that, surprisingly , there exist erasure codes that can be repa ired withou t comm unicating th e who le data ob ject. In particu lar , for the (4 , 2) e xample, we show th at the newcomer can d ownload 1 . 5 Mb to repair a failure and that this is the inf ormation theo retic min imum (see Fig . 2 f or an examp le). Mo re genera lly , we identify a tradeo ff between storage and repair band width an d show th at codes exist that achieve e very point on this optimal tr adeoff curve. W e call codes that lie on this optimal tradeoff curve r eg enerating codes . Note that th e tradeoff region computed corrects an erro r in th e threshold a c computed in [1] and generalizes the result to every fea sible ( α, γ ) pair . The two extremal points on the tradeoff cu rve are of special interest and we re fer to them as m inimum-stor age regenerating (MSR) codes and min imum-ba ndwidth regenera ting (MBR) codes. The former co rrespond to Maxim um Distance Sepa- rable (MDS) cod es that can also be ef ficiently repaired. At the other end of the tradeoff are the M BR codes, wh ich have minimum rep air bandwidth. W e show that if each storage node is allowed to store slightly more than M /k bits, the repair bandwidth can be significan tly reduce d. The remain der o f this paper is organized as follows. In Section II we discu ss r elev ant backgrou nd an d related work from n etwork cod ing theory and distributed storag e sy stems. In Section III we introdu ce the notion of the inf ormation flow graph, which represents how information i s com municated and stored in the n etwork as no des join an d leave the system. In Section II I-B we characterize the min imum storage and re pair bandwidth and show that there is a tradeoff between these two q uantities that can be expressed in ter ms of a maximum flow o n this gr aph. W e further show that fo r any fin ite in for- mation flow gr aph, there exists a regeneratin g cod e that can achieve any point on the minimum stora ge/ bandw idth feasible region we compu ted. Finally , in Sectio n IV we ev a luate the perfor mance of the propo sed regen erating cod es using tr aces of failures in real systems a nd compar e to altern ati ve schemes previously pro posed in the distributed storag e literature. I I . B AC K G RO U N D A N D R E L AT E D W O R K A. Erasur e cod es Classical cod ing th eory focuses o n the tr adeoff between redund ancy and err or toler ance. In terms of the re dundan cy- reliability trade off, the Maximu m Distance Separab le (MDS) codes are optim al. The most well-known class of MDS erasure codes is the Reed -Solomon co de. More recent stud ies on era- sure cod ing fo cus on o ther pe rforman ce metr ics. For instan ce, sparse graph cod es [1 1], [12], [1 3] c an achieve n ear-optimal perfor mance in terms of the redun dancy-reliab ility tradeoff and also require low encod ing and deco ding co mplexity . Another line of research for er asure co ding in storage applications is parity arra y codes; see, e.g ., [14], [15], [ 16], [17]. Th e array codes are based solely on XOR operatio ns and they are gener ally designed with th e objective of low enc oding, decodin g, a nd u pdate com plexities. Plank [18] gave a tutorial on erasure codes f or storage ap plications a t USENIX F AST 2005, which covers Reed-Solo mon codes, p arity-arra y cod es, and LDPC codes. Compared to th ese stud ies, th is paper focuses on differ- ent per forman ce metrics. Spec ifically , motiv ated by practical concern s in large distributed storage systems, we exp lore 3 erasure co des that o ffer good tradeo ffs in terms of redun dancy , reliability , and r epair band width trad eoff. B. Network Coding Network codin g is a gener alization of the con ventional rout- ing ( store-and- forwarding) metho d. In conventional r outing, each interm ediate nod e in the network simply stores an d for- wards i nfor mation received. In contrast, netw ork coding allo ws the in termediate nod es to g enerate outpu t data by encod ing (i.e., com puting certain func tions of) p reviously recei ved input data. Thu s, network co ding allows info rmation to be “mixed” at intermediate no des. The potential advantages of network coding over rou ting inc lude r esource (e.g., bandwidth a nd power) ef ficiency , computatio nal ef ficien cy , and robustness to network dynamics. As shown by the pioneering work of Ahlswede et al. [19], n etwork coding can incre ase the p ossible network thr oughp ut, and in the multicast case can achieve the maximum data rate th eoretically possible. Subsequen t work [20], [21] showed that the maximu m multicast cap acity can be achiev ed by usin g linear encoding function s at each nod e. The studie s by Ho e t al. [22] and Sanders et a l. [ 23] fu rther showed that rando m linear network coding over a suf ficiently large finite field can (asym ptotically) achieve the multicast cap acity . A polyno mial comp lexity pro - cedure to construct d eterministic network cod es th at achieve the m ulticast capacity is given by Jaggi et al. [24]. For distributed storage, the id ea of u sing network cod ing was intro duced in [6] for wir eless sensor networks. Many aspects of cod ing for storag e were f urther explo red [7], [2 5], [26] f or senso r network applications. Network coding was propo sed for peer-to-peer content d istribution systems [27] where ran dom linear operations over packets are pe rformed to improve file downloading in large unstructured overlay networks. The key difference o f th is pap er to this existing litera ture is that we brin g the dim ension of r epair bandwidth into the picture, and presen t fun damental b ounds and constru ctions for network codes that need to be main tained over t ime. Similar to this related work, intermed iate nodes form linear comb inations in a fin ite field an d the combin ation coefficients are also stored in eac h packet, creating some overhead that can be made arb itrarily small for larger packet sizes. In regeneratin g codes, repair ban dwidth is reduced because many nodes cr eate small parity packets of their data that essentially contain enoug h novel informatio n to generate a ne w encoded fragment, without req uiring to reco nstruct the whole data o bject. C. Distrib uted storage systems A n umber of recent stud ies [2 8], [8], [29], [30], [4], [31] have de signed and ev alu ated large-scale, peer-to-peer dis- tributed storage systems. Redund ancy man agement strategies for su ch systems h av e been e valuated in [9], [3 2], [4], [ 10], [31], [33], [34], [35]. Among these, [9], [4], [ 10] com pared r eplication with erasure codes in the b andwidth- reliability tradeoff space. Th e analysis of W eatherspoon and Kubiatowicz [ 9] showed that erasure cod es cou ld reduce ban dwidth use b y an order of magnitud e comp ared with replicatio n. Bhagwan et al. [4] came to a similar c onclusion in a simu lation of the T otal Recall storage system. Rodrigues a nd L iskov [10] pro pose a solutio n to the r epair problem that we call the Hybrid strate g y : one special sto rage node m aintains one full rep lica in ad dition to multiple er asure- coded fragmen ts. The node storing the replica can produce new f ragments and send them to n ewcomers, thus transfer ring just M / k bytes for a n ew fragmen t. Howe ver, maintainin g an extra rep lica on o ne n ode dilutes th e b andwidth- efficiency of erasure codes an d c omplicates system d esign. For example, if the r eplica is lost, n ew f ragments can not be cr eated until it is restored. The au thors show that in high -churn environmen ts (i.e., hig h rate of n ode joins/leaves), erasure codes p rovide a large storage benefits but the bandwidth cost is too high to be pra ctical for a P2P distributed storage sy stem, using the Hybr id strategy . In low-churn environmen ts, th e reductio n in bandwidth is negligible. In moderate-ch urn environments, there is so me ben efit, but this may be outweighed by the added architectu ral complexity that erasure codes in troduce as discussed furth er in Section IV -E. These con clusions were based on an analytical model aug mented with parame ters estimated from traces of real systems. Compared with [9], [10] used a muc h smaller value of k ( 7 instead of 32 ) and the Hybrid stra tegy to add ress th e code regeneration p roblem. I n Section IV, we f ollow th e evaluation m ethodolo gy of [10] to measure the per forman ce of the two r edunda ncy maintenan ce schemes that we in troduce. I I I . A N A LY S I S Our analysis is based on a particular graph ical rep resen- tation of a d istributed storag e system, which we ref er to as an information flow graph G . T his graph describes how th e informa tion of the data object is commun icated thr ough the network, stored in nodes with lim ited memor y , and reaches reconstruc tion poin ts at the da ta collector s. A. Information Flow Graph The inform ation flo w graph is a dir ected acyclic graph consisting of thre e kinds of nod es: a single d ata source S , storage nodes x i in , x i out and data collectors DC i . The single node S corresponds to the sourc e of the or iginal data. Storag e node i in the system is rep resented by a storag e inpu t node x i in , and a storage ou tput nod e x i out ; th ese tw o nodes are connected by a directed edge x i in → x i out with cap acity eq ual to the amoun t of data stored at node i . See Figure 3 for an illustration. Giv en the dynamic n ature of the storage systems that we consider, the in formation flow gra ph also ev o lves in time . At any gi ven time, each vertex in the grap h is either active or inactive , depen ding on wh ether it is av ailable in the network. At th e initial time, o nly the source no de S is ac ti ve; it th en contacts an initial set of storage nodes, and connects to their inputs ( x in ) with directed edges o f infinite capacity . Fr om this p oint onwards, the original sou rce no de S becomes and remains inactive. At the next time step, the initially cho sen storage n odes become now active; they rep resent a distributed 4 Fig. 3. Illustra tion of the informatio n flow graph G corresponding to the (4,2) code of figure 1. A distribute d s torage s cheme uses an (4 , 2) erasure code in which any 2 fragments suffice to recov er the origina l da ta. If node x 4 becomes unav ailable and a new node join s the system, we need to construct ne w encoded fragment in x 5 . T o do so, node x 5 in is conne cted to the d = 3 acti ve s torage nodes. As suming β bits communicated from each acti ve storage node, of int erest is the minimum β required. The min-cut separat ing the source and the data collecto r must be larg er than M = 2 Mb for reconstructi on to be possible. For this graph, the min-cut v alue is giv en by 1 + 2 β , implying that β ≥ 0 . 5 Mb is suffici ent and necessary . erasure code, correspo nding to the desired steady state of the system. If a n ew no de j joins the system , it can o nly be connected with acti ve nodes. If th e newcomer j chooses to connect with acti ve storage node i , then we add a directed edge from x i out to x j in , with capacity equal to the amount of data that the n ewcomer downloads fr om no de i . Note that in gen eral it is possible f or nod es to download more data than they store, as in the example o f th e (4 , 2) -erasure co de. If a node leaves the system, it becom es inactive. Finally , a da ta co llector DC is a node that co rrespond s to a requ est to reconstruct the data. Data collectors co nnect to subsets of active nodes th rough ed ges with infin ite capacity . An important n otion assoc iated with th e information flow graph is that of m inimum cuts: A cut in the graph G b etween the so urce S and a fixed data collector no de DC is a su bset C of edges such th at, there is no path starting f rom S to DC that does not h a ve one or more edg es in C . The minimum cut is the cut between S and DC in which the to tal sum o f the ed ge capactities is smallest. B. Storage-Bandwidth T radeoff W e are now read y fo r the main result of this paper, the chara cterization of the f easible storage- repair bandwidth points. The setup is as follows: The normal redundancy we want to maintain r equires n active stor age no des, each storing α bits. Whenever a n ode fails, a n ewcomer downloads β bits each from any d survi ving nodes. Therefore the total repair bandwidth is γ = dβ (see figure 3). W e restrict our attentio n to the sym metric setu p wh ere it is r equired that any k storag e nodes can rec over the origin al file, and a newcomer do wnloads the same amoun t o f inf ormation fro m each of the existing nodes. For each set of par ameters ( n, k , d, α, γ ) , th ere is a family of in formation flo w graphs, each of which corr esponds to a par ticular ev o lution of node failur es/repairs. W e d enote this family of d irected acyclic grap hs by G ( n, k , d, α, γ ) . An ( n, k, d, α, γ ) tuple will b e f easible, if a code with storage α and repair bandwidth γ exists. For the exam ple in figure 3, the p oint (4 , 2 , 3 , 1 Mb , 1 . 5 Mb ) is feasible (and a code th at achieves it is sh own in figure 2) an d also o n the op timal tradeoff whereas a standard er asure co de wh ich co mmunicates the wh ole data ob ject would co rrespond to γ = 2 Mb instead . Note that n, k , d mu st be integers while α, β , γ are real valued. Theor em 1: For any α ≥ α ∗ ( d, γ ) , th e points ( n, k, d, α, γ ) are feasible, an d linear network codes suffice to achieve th em. It is informatio n theoretically i mpossible to achieve po ints with α < α ∗ ( d, γ ) . The threshold fu nction α ∗ ( d, γ ) (which also depend s on n , k ) is the following: α ∗ ( d, γ ) = ( M k , γ ∈ [ f (0) , + ∞ ) M− g ( i ) γ k − i , γ ∈ [ f ( i ) , f ( i − 1)) , (1) where f ( i ) ∆ = 2 M d (2 k − i − 1 ) i + 2 k ( d − k + 1) , (2) g ( i ) ∆ = (2 d − 2 k + i + 1) i 2 d . (3) The minim um γ is γ min = f ( k − 1) = 2 M d 2 k d − k 2 + k . (4) The comp lete proof of this theo rem is g i ven in the Ap- pendix. The main idea is th at the code repair problem can be mapp ed to a multicastin g p roblem on th e inform ation flow graph. Known results on network coding fo r mu lticasting can then b e used to establish that code repair can be ach iev ed if and o nly if the un derlying in formation flow grap h has eno ugh connectivity . The b ulk o f the technical analy sis of the proo f then in volves com puting the minimum cuts on arbitrar y graphs in G ( n, k, d, α, γ ) and solving an optimization problem for minimizing α subject to a sufficient flow constrain t. The o ptimal tradeo ff curves for k = 5 , n = 1 0 , d = 9 an d k = 10 , n = 15 , d = 14 are shown in Figure 4 (top) and (bottom) , respectively . C. S pecial Cases: Minimum-Storage Regener ating (MSR) Codes and Minimum-Ban dwidth Regener ating ( MB R) Codes W e now study two extremal points on the op timal tradeoff curve, which cor respond to the best storage efficiency and the minimum repair bandwidth, respectively . W e call codes that attain these p oints minimu m-storage regenera ting (MSR) codes a nd minimu m-band width regenera ting (MBR) code s, respectively . It can be verified that the minimu m storage point is achieved by the p air ( α M S R , γ M S R ) = M k , M d k ( d − k + 1) . (5) If we sub stitute d = k into the above, we n ote that the total network band width for repair is M , the size of the original file. Therefore, if we o nly allow a newcomer to co ntact k nodes, it is optima l to download the whole file and the n compute the n e w frag ment. Howe ver, if we allow a newcomer 5 0.26 0.28 0.3 0.32 0.34 0.36 0.2 0.21 0.22 0.23 0.24 0.25 0.26 0.27 0.28 0.29 0.3 Bandwidth to repair one node γ Storage per node α Optimal tradeoff for k=5, n=10 0.14 0.16 0.18 0.2 0.22 0.24 0.26 0.28 0.1 0.11 0.12 0.13 0.14 0.15 Bandwidth to repair one node γ Storage per node α Optimal tradeoff for k=10, n=15 Fig. 4. Optimal tradeof f curve between storage α and re pair ban dwidth γ , for k = 5 , n = 10 (left) and k = 10 , n = 15 (ri ght). For both plo ts M = 1 and d = n − 1 . Note that traditio nal erasure coding correspond s to the points ( γ = 1 , α = 0 . 2) and ( γ = 1 , α = 0 . 1) for the top and bott om plots. 6 to con tact more than k nodes, the n etwork bandwid th γ M S R can be reduced significantly . The minimum network bandwidth is clearly achieved b y h a ving the newcomer co ntact all other nodes. For in stance, for ( n, k ) = (14 , 7) , th e newcomer needs to d ownload only M 49 from ea ch of th e d = n − 1 = 13 acti ve storage nodes, makin g th e repair bandwid th equal to 13 M 49 , required to generate a fragmen t of size M 7 . Since the MSR cod es stor e M k bits at each node while ensuring any k coded bloc ks can be used to recover th e original file, the MSR codes have equiv alent reliability-red undancy per- forman ce with standard Maximu m Distance Separab le (MDS) codes. However , MSR codes o utperfor m classical MDS codes in term s o f the network repair b andwidth. At the other end of the tradeoff are MBR codes, which have minim um repair band width. I t can be verified th at the minimum rep air bandwid th point is achieved by ( α M B R , γ M B R ) = 2 M d 2 k d − k 2 + k , 2 M d 2 k d − k 2 + k . ( 6) Note that the minimum bandwidth regenerating codes, the stor - age size α is equal to γ , the total n umber of bits downloaded. Therefo re MBR co des incur no band width expan sion at all, just like a replication system does. Ho wev er , the b enefit o f MBR co des is significan tly better storag e efficiency . I V . E V A L UA T I O N In this section, we com pare r egenerating codes with oth er redund ancy managemen t schemes in the co ntext of dis- tributed storag e systems. W e fo llow the e valuation method - ology of [10], which consists of a simple analytica l m odel whose par ameters are obtaine d from traces of nod e a vailability measured in sev eral real d istributed systems. W e begin in Sectio n IV -A with a d iscussion o f node dynam- ics an d th e o bjectives relev ant to distributed sto rage systems, namely reliability , band width, an d disk space. W e introduc e the m odel in Section IV -B an d estimate realistic v alues f or its parameters in Section IV -C. Section IV - D contains the quantitative r esults of our evaluation. I n Section IV -E, we discuss qualitativ e tradeoffs b etween regenerating c odes and other strategies, and how our r esults ch ange th e con clusion of [10] that erasu re codes pr ovide limited practical b enefit. A. Node dyna m ic s a nd obje c tives In this section we introduce some backgrou nd and termi- nology which is common to most of the work discussed in Section II- C. W e draw a distinction between pe rmanent and tr ansient node failures. A per manent failure, such as the p ermanent departur e of a no de f rom the sy stem or a disk failure, results in loss o f the data stored on the no de. In contrast, data is p reserved across a tran sient failure, such as a r eboot or temporar y ne twork disconne ction. W e say that a node is available when its data can b e retrieved across th e network. Distributed storage systems attempt to provide two types of reliability: availability an d durab ility . A file is av ailable when it can be rec onstructed f rom the data stored on curr ently av ailab le n odes. A file’ s durability is mainta ined if it has not b een lo st du e to perman ent node failure s: that is, it may be av a ilable at som e point in the fu ture. Both pro perties are desirable, but in this paper we rep ort results f or a vailability only . Specifically , we will show file unavailability , the fraction of time that the file is not av ailab le. B. Model W e u se a mod el w hich is inten ded to capture the average- case bandwidth used to maintain a file in the system, and the resulting a verage availability o f the file. W ith minor exceptions, 1 this model and the subsequent estimation of its parameters are equiv alent to that o f [ 10]. Alth ough this evalu- ation methodolog y is a significant simplification of real storage systems, it allows u s to comp are directly with the con clusions of [10] as well as to calculate precise values for ra re events. The mod el has two key paramete rs, f and a . First, we assume that in expectatio n a fraction f o f the nodes storing file data fail perma nently per u nit time, cau sing data tra nsfers to repair th e lost redund ancy . Second , we assume that at any giv en time wh ile a node is storing data, the nod e is av ailable with some prob ability a (a nd with probability 1 − a is curren tly experiencing a transient failure). Moreover, the mod el assumes that the e vent that a nod e is av ailable is ind ependen t of the av ailab ility of all other n odes. Under the se assumption s, we can compu te the expec ted av ailab ility and ma intenance band width of v arious r edundan cy schemes to maintain a file of M b ytes. W e m ake u se o f the fact that for all sche mes except MSR codes, the amoun t of bandwidth used is eq ual to the amoun t of redund ancy that had to be re placed, which is in expectatio n f times th e amoun t of storage used . Replication: I f we store R replicas of the file, then we store a to tal of R · M bytes, and in expectation we must replace f · R · M bytes per unit tim e. The file is un av ailab le if no replica is av ailable, which hap pens with p robability (1 − a ) R . Ideal Erasure Co des: For compariso n, we show the band- width and availability of a hypo thetical ( n, k ) era sure code strategy which can “magically” crea te a n ew packet while transferrin g just M /k bytes ( i.e. , the size of the packet). Setting n = k · R , th is strategy sends f · R · M bytes per unit time and has un av ailability pr obability U ideal ( n, k ) := P k − 1 i =0 n i a i (1 − a ) n − i . Hybrid: If we store o ne fu ll replica plus a n ( n, k ) er asure code where n = k · ( R − 1 ) , then we again store R · M bytes in total, so we tr ansfer f · R · M bytes per unit time in expectation. The file is unav ailable if the replica is unav ailable and fewer than k erasure-co ded pac kets are available, which happen s with proba bility (1 − a ) · U ideal ( n, k ) . Minimum-Storage Regenera ting Codes: An ( n, k ) MSR Code with red undancy R = n/k stores RM by tes in total, so f · R · M bytes mu st be replaced pe r unit time. W e will refe r to the overhead of an MSR cod e δ M S R as th e extra amou nt 1 In additi on to ev aluating a larger set of strategi es and using a some what dif ferent set of traces, we count bandwidth cost due to permanent node fail ure only , rather than both failures and joins. Most designs [4 ], [31], [33] can av oid reacti ng to node join s. Additionall y , we compute probabilit ies directl y rather than using approxi mations to the binomial. 7 of informatio n that needs to be transfered compared to the fragmen t size M /k : δ M S R ∆ = ( n − 1) β M S R M /k = n − 1 n − k . (7) Therefo re, r eplacing a fragmen t require s transfer ring over the network δ MSR times the size of the fragment in the most fa vorable case wh en n e wcomers conn ect to d = n − 1 nodes to co nstruct a new fragme nt. Th erefore, this results in f · R · M · δ MSR bytes sent pe r unit time, a nd u nav ailab ility U ideal ( n, k ) . Minimum-Bandwid th Regenerat ing Codes: It is convenient to define the MBR c ode overhead as th e amount of infor mation tran sfered over the ideal fragment size: δ M B R ∆ = ( n − 1) β M B R M /k = 2( n − 1 ) 2 n − k − 1 . (8) Therefo re, an ( n, k ) MBR Code stores M · n · δ MBR bytes in total. So in expectation f · M · n · δ MBR bytes ar e transfer ed per un it time , and the unavailability is again U ideal ( n, k ) . C. Estimating f and a In this section we d escribe how we estimate f , the fractio n of nodes that per manently fail per un it time, a nd a , the mean node av ailability , based on traces of node a vailability in se veral distributed systems. W e use f our trace s of no de availability with widely varying characteristics, summarized in T ab le I. The PlanetLab All Pairs P ing [36] trac e is based on p ings sent every 15 minutes between all pa irs of 200 - 400 nodes in PlanetLa b, a stable, managed network research testb ed. W e co nsider a node to be up in one 15 -m inute interval when at least h alf of the pings sent to it in that interval succeeded. In a nu mber of perio ds, all or near ly all PlanetLab nodes were down, most likely due to plan ned system up grades or measuremen t errors. T o exclu de these cases, we “cleaned” the trace as follows: for each period of downtime at a particular no de, we r emove tha t per iod (i.e. we conside r the node up during that in terval) wh en the a verage nu mber of n odes up during that pe riod is less th an half the average numb er of no des up over all time. The Microsoft P Cs [2 8] trace is derived fro m hourly pings to d esktop PCs within Micro soft Corporation . The Skype superpeers [3 7] trace is based on app lication-level pings at 30 -minute intervals to nodes in the Skype su perpeer network, which may appr oximate the b ehavior o f a set of well-provisioned end hosts, since superpeers may be selected in part based on ban dwidth av ailability [37]. Finally , th e trace of Gnutella peers [ 38] is based on app lication-level pings to ordinar y Gnutella p eers at 7-minu te intervals. W e next describe how w e derive f and a from these traces. I t is of key importance f or the storage system to distinguish b etween p ermanen t and transient failures (d efined in Section IV -A), since only th e fo rmer requ ires bandwidth - intensive replacem ent o f lost r edunda ncy . Most systems use a timeout heu ristic: when a node has not respon ded to network- lev el p robes after some period o f time t , it is considered to have failed per manently . T o approxim ate a storage system’ s behavior , we use the same heu ristic. No de a vailability a is then calculate d as the mean (ov er time) fraction of n odes which wer e av a ilable amon g those w hich were not co nsidered permane ntly failed at that time. The re sulting values of f an d a appear in T able I, where we have fixed the timeout t at 1 day . L onger time outs reduce overall b andwidth costs [1 0], [33], but begin to im pact durability [33] and are more likely to pro duce artificial effects in the short ( 2 . 5 -day) Gnutella trace. W e emphasize that the pr ocedure described above only provides an estimate of f an d a which m ay be biased in se veral ways. Som e design s [ 33] rein corpora te data o n node s which return after transient failures which were longer than the timeout t , which would re duce f . Addition ally , even placing files on unifo rm-ran dom n odes r esults in selecting nodes that are more av ailab le [34] a nd less pron e to failure [35] than the av erage node. Finally , we h av e not accounted for the time needed to transfer data onto a no de, d uring which it is effecti vely unavailable. Howev er , we con sider it unlikely that these biases would impact our main r esults sinc e we are p rimarily concern ed with the relative p erform ance of the strategies we comp are. D. Quantitative r esults Figure 5 shows the tradeoff between mean unavailability and mean mainten ance band width in each of th e strategies of Section IV -B using the values of f and a f rom Section IV -C and k = 7 . Feasible p oints in the tr adeoff space are prod uced by varying the red undancy factor R . The mar ked points along each curve highligh t a sub set of the feasible points (i.e., points for which n is integral). Figure 6 sh ows that re lati ve perform ance of th e various strategies is similar f or k = 14 . For conciseness, we omit p lots of storage u sed by the schemes. Ho wev er , disk u sage is p roportio nal to band width for all schemes we evaluate in this section, with the exception of minimum stor age regenerating codes. This is because MSR codes are the only scheme in whic h the da ta transfer red on to a newcomer is not equ al to the amo unt of data that the ne wcomer finally sto res. In stead, the storage used by M SR co des is equal to that of the storage used by hyp othetical ideal erasu re co des, and hence MSR co des’ space usage is pro portion al to the bandwidth used by ide al c odes. For example, f rom Figur e 5( b) we ca n com pare the strate- gies at their feasible points closest to unavailability 0 . 0001 , i.e., fo ur nines of availability . At these p oints, MSR codes u se about 4 4 % more b andwidth an d 2 8 % less stor age spac e than Hybrid, while MBR codes use abou t 3 . 7 % less b andwidth a nd storage space than Hyb rid. Add itionally , these feasible p oints giv e MSR and MBR cod es some what better unav ailab ility than Hybrid ( . 00 0059 vs. 0 . 00 018 ). One in teresting effect apparen t in the plots is that M SR codes’ mainten ance bandwidth actually decr eases as the re- dunda ncy factor R increases, before coming to a minimum and then increasing again . Intuiti vely , while increasing R incr eases the total amou nt o f data that needs to be maintained , for small R th is is more th an co mpensated for by the reduction in overhead. Th e expected main tenance b andwidth per unit time 8 T race Length Start Mean # f a (days) date nodes up (fractio n failed per day) PlanetLa b 527 Jan. 2004 303 0.017 0.97 Microsoft PCs 35 Jul. 6, 1999 41970 0.038 0.91 Skype 25 Sept. 12, 2005 710 0.12 0.65 Gnutell a 2.5 May , 2001 1846 0.30 0.38 T ABLE I T H E A V A I L A B I L I T Y T R AC E S U S E D I N T H I S PA P E R . 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 0.5 1 1.5 2 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file (a) PlanetLab trace 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 0.5 1 1.5 2 2.5 3 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file (b) Microsoft PCs trace 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 2 4 6 8 10 12 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file (c) Skype superpeers trace 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 5 10 15 20 25 30 35 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file Replication MSR Codes Hybrid MBR Codes Ideal Erasure (d) Gnutella peers trace Fig. 5. A vaila bility-b andwidth tradeof f for k = 7 with parameters deri ved from each of the trac es. T he k ey in (d) applie s to all four plots. is f M R δ MSR = f M n k n − 1 n − k . (9) It is easy to see that th is f unction is minim ized b y selectin g n one of the two integers clo sest to n opt = k + p k 2 − k . (10) which app roaches a redu ndancy factor of 2 as k → ∞ . E. Qualitative comp arison In this section we discuss two question s: First, based o n the results of the previous sectio n, what are the qualitative advantages and disadvantages of the tw o extremal regenerating codes com pared with the Hy brid coding schem e? Second, do our results affect the con clusion of Rodrig ues and Liskov [ 10] that erasur e codes offer too little improvement in bandwidth use to clear ly offset the add ed complexity that they add to the system? 1) Comp arison with Hyb rid : Compared with Hybrid , f or a giv en target availability , min imum storage regeneratin g codes offer slightly lower main tenance b andwidth and storage, and a simpler system a rchitecture since only one type of r edunda ncy needs to be main tained. An imp ortant practical disadvantage of using th e Hyb rid schem e is asymmetr ic design which can cause the disk I/O to beco me th e bottleneck of the system during r epairs. This is becau se the disc stor ing the full replica and gen erates the encod ed f ragments need to r ead the whole data object and com pute the en coded f ragment. Howe ver, MBR cod es ha ve at least two disadvantages. First, constructing a new packet, or reconstructing the entire file, requires commun cation with n − 1 nod es 2 rather than o ne 2 The scheme could be adapted to connect to fewe r than n − 1 nodes, but this woul d increase maintenan ce bandwidth. 9 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 0.5 1 1.5 2 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file (a) PlanetLab trace 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 0.5 1 1.5 2 2.5 3 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file (b) Microsoft PCs trace 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 2 4 6 8 10 12 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file (c) Skype superpeers trace 1e-06 1e-05 0.0001 0.001 0.01 0.1 1 0 5 10 15 20 25 30 35 Pr[data is not available] Aggregate bandwidth in KB/s per 1 GB file Replication MSR Codes Hybrid MBR Codes Ideal Erasure (d) Gnutella peers trace Fig. 6. A vaila bility-b andwidth tradeof f for k = 14 with parameters deri ved from each of the trac es. (in Hybr id, th e node holding the single replica). This add s overhead that could be sign ificant for sufficiently small files o r sufficiently large n . Perhaps m ore importan tly , there is a factor δ MBR increase in total data transferr ed to read the file, rough ly 30 % fo r a r edunda ncy factor R = 2 and k = 7 or 13 % fo r R = 4 , Thu s, if the f requency that a file is read is sufficiently high an d k is sufficiently small, this inefficiency could become unacceptab le. Again co mpared with Hy brid, M SR co des o ffer a simpler, sym metric system d esign and so mewhat lower storage space f or the same reliab ility . Howe ver , MSR codes have somewhat high er m aintenance ban dwidth and like MSB codes requ ire that ne wcomers and data co llectors con nect to multiple no des. Rodrigues et al. [ 10] discussed two principal disadvan- tages of using erasure co des in a wid ely distrib uted system: coding—in pa rticular , the Hybrid strategy—com plicates the system arc hitecture; and th e improvement in main tenance bandwidth was m inimal in more stable environments, wh ich are the more likely deploymen t scenar io. Regenerating codes address the first o f these issues, wh ich may make coding more broadly ap plicable. V . C O N C L U S I O N S W e presen ted a general th eoretic fra mew ork that can de- termine the inform ation th at must b e com municated to re pair failures in en coded sy stems and id entified a tradeoff between storage and repair ban dwidth. Certainly ther e are m any issues tha t rema in to be add ressed before these idea s can be implemented in pr actical systems. In future work we plan to in vestigate deter ministic designs of regenerating codes over small finite fields, th e existence of systematic regenerating co des, d esigns th at minim ize the overhead sto rage of th e coefficients, as well as the im pact o f node dynam ics in reliability . Oth er issues of interest in volve how CPU processing an d disk I/O will influen ce the system perfor mance, as well as integrity and security for the linear combinatio n packets (see [39] for a related analy sis for content distribution). One potential applicatio n fo r the propo sed regeneratin g codes is distributed archival storag e or b ackup, wh ich might be useful for data center applicatio ns. I n this case, files are likely to be large and infrequen tly rea d, making the draw- backs mentio ned ab ove less significan t, so that MBR codes’ symmetric design may make them a win over Hy brid; and the requ ired r eliability may a lso be high, mak ing them a win over simple replicatio n. In o ther app lications (such as storage system within fast local networks) th e re quired storage may become importan t, and the results of the previous s ection show that minimu m stora ge regenerating codes ca n be useful. 10 R E F E R E N C E S [1] A. G. Dimakis, P . G. Godfrey , M. J. W ainwrigh t, and K. Ramchan- dran, “Network coding for distrib uted s torage systems, ” in IEEE Proc. INFOCOM , (Anchorage , Alaska), May 2007. [2] Y . Wu, A. G. Dimakis, and K. Ramchandran, “Determini stic regen er- ating codes for distribu ted storage, ” in Allert on Confere nce on Contr ol, Computing , and Communicati on , (Urbana-Champai gn, IL), September 2007. [3] S. Rhea, C. W ells, P . Eaton, D. Geels, B. Zhao, H. W eatherspoon, and J. Kubiato wicz, “Maintena nce-free global data storage, ” IEEE Internet Computing , pp. 40–49, Septe mber 2001. [4] R. Bhagwan, K. T ati, Y .-C. Cheng, S. Sav age, and G. M. V oel ker , “T otal recall : System support for automat ed ava ilabil ity management, ” in NSDI , 2004. [5] F . Dabek, J. L i, E . Sit, J. Robertson, M. Kaashoek, and R. Morris, “Designi ng a dht for lo w latenc y and high throughput, ” 2004. [6] A. G. Dimakis, V . Prabhakara n, and K. Ramchandr an, “Decent ralize d erasure codes for distributed netw orke d storage, ” in Joi nt special issue , IEEE T rans. on Info. Theory and IEEE/ACM T rans. on Networking , June 2006. [7] A. Kamra, J. Feldman, V . Misra, and D. Rubenstein, “Growt h codes: Maximizi ng sensor netw ork data persistence, ” ACM SIGCOMM , 2006. [8] S. Rhea, P . Eaton, D. Geels, H. W eatherspoon, B. Zhao, and J. Kubi- ato wicz, “Pond: the OceanSto re prototype, ” in Pro c. USENIX File and Stora ge T ec hnolog ies (F AST) , 2003. [9] H. W eathe rspoon and J. D. Kubiato wicz, “Erasure coding vs. replicat ion: a quantit iati ve comparison, ” in Pr oc. IPTPS , 2002. [10] R. Rodrigues and B. Liskov , “High ava ilabil ity in DHTs: E rasure coding vs. replic ation, ” in Proc. IP TPS , 2005. [11] M. Luby , M. Mitzenmacher , M. A. Shokrollahi, and D. Spielman, “Improv ed low-den sity parity check codes using irregula r graphs, ” IEEE T rans. Info. Theory , vol . 47, pp. 585–598, February 2001. [12] M. Luby , “L T codes, ” P r oc. IEE E F oundations of Computer Science (FOCS) , 2002. [13] A. Shokrollahi, “Raptor codes, ” IEE E T rans. on Information Theory , June 2006. [14] M. Blaum, J. Brady , J. Bruck, and J. Menon, “EVENODD: An efficie nt scheme for tole rating doub le disk failures, ” IEEE T rans. on Computing , vol. 44, pp. 192–202, February 1995. [15] L. Xu and J. Bruck, “X-code: MDS array codes with optimal encoding, ” IEEE T rans. on Information Theory , vol. 45, pp. 272–276, January 1999. [16] C. Huang and L . Xu, “ST AR: An e ffic ient c oding scheme for correcti ng triple storage node failur es, ” in F AST -2005: 4th Usenix Confer ence on F ile and Stor ag e T echnolo gies , (San Francisco, CA), December 2005. [17] J. L. Hafner , “WEA VER codes: Highly fault tolerant erasure codes for storage systems, ” in F AST -2005: 4th Usenix Confere nce on Fil e and Stora ge T ec hnolog ies , (San Francisco , CA), Decembe r 2005. [18] J. S. Pl ank, “Erasure codes for storage applicat ions, ” in T u- torial, F AST -2005: 4th Usenix Confer ence on File and Stora ge T ec hnologies , (San Francisco, CA), December 2005. [online ] http:/ /www .cs.utk.edu/ plank/pla nk/paper s/F AST -2005.html. [19] R. Ahlswede, N. Cai, S. -Y . R. L i, and R. W . Y eung, “Netw ork infor- mation flow , ” IE E E T rans. Info. Theory , vol. 46, pp. 1204–1216, July 2000. [20] S.-Y . R. Li, R. W . Y eung, and N. Cai, “Linear network coding, ” IEEE T rans. on Informatio n Theory , vol. 49, pp. 371–381, February 2003. [21] R. Koet ter and M. M ´ edard, “ An algebraic appr oach to network cod ing, ” in IEEE/ACM T ransacti ons on Networking , October 2003. [22] T . Ho, M. M ´ eda rd, R. Koe tter , D. R. Karge r , M. Effros, J. Shi, and B. Leong, “ A random linear network coding approach to m ultic ast, ” IEEE T rans. Inform. Theory , vol . 52, pp. 4413–4430, Oct. 2006. [23] P . Sand er , S. Egne r , and L. T olhuizen, “Poly nomial time al gorithms for netw ork information flow , ” in Symposium on P aralle l A lgorithms and Arc hitectur es (SP AA) , (San Diego, CA), pp. 286–294, AC M, June 2003. [24] S. J aggi, P . Sanders, P . A. Chou, M. Effros, S. E gner , K. Jain, and L. T olhuizen, “Polynomial time algorithms for network code construc- tion, ” IEEE T rans. Inform. Theo ry , vol. 51, pp. 1973–1982, June 2005. [25] X. Zhang, G . Neglia, J. Kurose, and D. T owsle y , “On the benefits of random linear coding for unic ast appl icatio ns in disrupti on tolerant net- works, ” Second W orkshop on Network Coding, Theory , and Applicati ons (NETCOD) , 2006. [26] D. W ang, Q. Z hang, and J. Liu, “Parti al network coding: Theory and applic ation for cont inuous sensor data coll ection, ” F ourtee nth IEEE Internati onal W orkshop on Qual ity of Service (IWQoS) , 2006. [27] C. Gkantsidis and P . Rodriguez, “Netw ork coding for large scale conten t distrib ution, ” Pro ceeding s of IEEE Infoc om , 2005. [28] W . J. Bolosky , J. R. Douceur , D. Ely , and M. Theimer , “Feasibility of a serve rless distri bute d file system depl oyed on an exi sting set of desktop PCs, ” in Pr oc. SIGMETRICS , 2000. [29] F . Dabek, F . Kaa shoek, D. Karger , R. Morris, and I. Stoic a, “W ide-area coopera ti ve storage with CFS, ” in Pr oc. A CM SOSP , 2001. [30] A. Rowstron and P . Druschel, “St orage management and cach ing in past, a large-sca le, persistent peer-to- peer storage utility , ” in Proc. ACM SOSP , 2001. [31] H. W eatherspoo n, B.-G. Chun, C. W . So, and J. Kubiato wicz, “Long- term data mainten ace in wide-area storage systems: A quantit ati ve approac h, ” tech. rep., UC Berk ele y , UCB/CSD-05-1404, July 2005. [32] C. Blak e and R. Rodrigues, “High ava ilabil ity , scal able s torage , dynamic peer neet works: Pick two, ” in Pr oc. HO TOS , 2003. [33] B.-G. Chun, F . Dabek, A. Haeberl en, E. Sit, H. W eatherspoon, M. F . Kaashoek, J. Kubiato wicz, and R. Morris, “Ef ficient replica maintenance for distrib uted storage systems, ” in NSDI , 2006. [34] K. T ati and G. M. V o elke r , “On object mainte nance in peer-to-pee r systems, ” in Pr oc. IPTPS , 2006. [35] P . B. Godfre y , S. Shenk er , and I. Stoica , “Minimizing churn i n distrib uted systems, ” in Pr oc. A CM SIGCOMM , 2006. [36] J. Stribling, “Planetl ab all pairs ping. ” http:// infospect .planet- lab .org/pings. [37] S. Guha, N. Daswani, and R. Jain, “ An exper imental study of the Skype peer -to-peer V oIP system, ” in IPTPS , 2006. [38] S. Saroiu, P . K. Gummadi, and S. D. Gribble, “A Measurement Study of Peer-to-Pe er File Sharing Systems, ” in Proc . MMCN , (Sa n Jose, CA, USA), January 2002. [39] P . R. C. Gkantsidis, J. Miller , “ Anatomy of a P2P content distrib ution system with netw ork coding, ” Proce edings of IPTPS , 2006. [40] J. Bang-Jensen and G. Gutin, Dig raphs: The ory , Algorithms and Appli- cations . New Y ork: Springe r , 2001. V I . A P P E N D I X Here we prove Theorem 1. W e first start with th e following simple lemma. Lemma 1: No data collecto r DC can reco nstruct the initial data obje ct if th e minimum cu t in G between S an d DC is smaller than th e initial object size M . Pr oof: The inform ation of the initial data ob ject mu st be commun icated fro m the source to the particular d ata collector . Since every link in the informatio n flo w graph can only be used at most on ce, and since the p oint-to-p oint capacity is less th an the data object size, a stan dard cut-set boun d shows that the entro py of the da ta o bject co nditioned on ev erythin g observable to the data collector is non- zero and therefore reconstruc tion is imp ossible. The inform ation flow graph casts th e origina l storag e pr ob- lem as a network co mmunicatio n pro blem where the sou rce s multicasts the file to th e set o f all p ossible data collectors. By analy zing th e connectivity in the inf ormation flow g raph, we ob tain necessary con ditions for all p ossible storage c odes, as shown in Lemma 1. In add ition to p roviding necessary condition s for a ll codes, th e in formation flow g raph can also imply the existence of cod es u nder prop er assum ptions. Pr opo sition 1 : Consider any giv en finite inform ation flow graph G , with a finite set of data c ollectors. I f the minimu m of the m in-cuts separa ting th e sou rce with each data collec tor is larger or equ al to the data ob ject size M , the n ther e exists a linear network code d efined over a suf ficiently large finite field F (who se size depends on the graph size) such that all d ata collectors can recover the d ata ob ject. Further , rand omized network coding guar antees that all collector s can re cover the data object with probab ility that can be driven arb itrarily h igh by incre asing th e field size. 11 Pr oof: The key po int is observin g that the reconstru ction problem reduces exactly to multicasting on all the possible data collector s on the info rmation flow graph G . Theref ore, the result follows dire ctly fr om th e constructive results in network coding theory for single s ource multicasting; see the discussion of related works on ne twork coding in Sectio n II-B. T o apply Pr oposition 1, consider an info rmation flow grap h G tha t enu merates all p ossible failure/repair patter ns an d all possible data collectors when the number of failures/rep airs is b ounded . This imp lies that there exists a valid regeneratin g code achieving the ne cessary cut bou nd (cf. Lemm a 1), which can tolerate a b ounded numb er o f failures/repairs. In another paper [2], w e present cod ing m ethods that co nstruct d etermin- istic r egenerating code s that can tolerate infin ite nu mber of failures/repairs, with a bou nded field size, assuming only the populatio n of active nodes at any time is b ounded . For the detailed cod ing theoretic constru ction, please refer to [ 2]. W e an alyze th e connectivity in the in formation flow grap h to find the minim um re pair b andwidth. T he next key lemma characterizes the flow in any info rmation flow g raph, under arbitrary failure p attern and con nectivity . Lemma 2: Consider any (poten tially infinite) info rmation flow graph G , fo rmed by having n initial n odes th at c onnect directly to the source and obtain α bits, while add itional nodes join th e gr aph by conn ecting to d existing nodes and obtain ing β bits fr om each. 3 Any data collector t that co nnects to a k - subset o f “out-no des” (c.f. Figure 3) of G must satisfy : mincut ( s, t ) ≥ min { d,k }− 1 X i =0 min { ( d − i ) β , α } . (11) Furthermo re, there exists an inf ormation flo w graph G ∗ ∈ G ( n, k , d, α, β ) where this boun d is matched with equality . Fig. 7. G ∗ used in the proof of le mma 2 Proof: First, we show that there exists an infor mation flo w graph G ∗ where the bou nd (11) is matched with equality . This graph is illustrated by Figure 7. In this graph , there are initially n nodes labeled from 1 to n . Con sider k newcomers labeled as n + 1 , . . . , n + k . The newcomer node n + i co nnects to nodes n + i − d, . . . , n + i − 1 . C onsider a da ta collector t that co nnects to the last k nodes, i.e., nod es n + 1 , . . . , n + k . Co nsider a cut ( U, U ) de fined as fo llows. For each i ∈ { 1 , . . . , k } , if α ≤ ( d − i ) β , then we includ e x n + i out in U ; otherwise, we 3 Note th at thi s setup allo ws more graphs than those in G ( n, k , d, α, β ) . In a graph in G ( n, k , d, α, β ) , at an y time there are n acti ve storage nodes a nd a newc omer can only connect to the acti ve nodes. In contrast, in a graph G describe d in this lemma, there is no notion of “acti ve node s” and a ne wcomer can conne ct to any d existi ng nodes. include x n + i out and x n + i in in U . Th en this cut ( U, U ) achieves (11) with equality . W e now show th at (11) must b e satisfied for any G fo rmed by a dding d in-d egree nodes as described above. Conside r a data collector t that connec ts to a k -subset of “out-no des”, say { x i out : i ∈ I } . W e w ant to sho w that any s – t cut in G has capacity at least min { d,k }− 1 X i =0 min { ( d − i ) β , α } . (12) Since the incoming edges o f t all h av e infinite capacity , we only need to examine the c uts ( U, U ) with s ∈ U , x i out ∈ U , ∀ i ∈ I . (13) Let C de note th e edges in the cu t, i.e., the set o f ed ges going from U to U . Every directed acyclic grap h has a to pological sorting (see, e.g., [ 40]), where a top ological sorting (or acyclic order ing) is an orde ring of its vertices such th at the existence of an edge from v i to v j implies i < j . Let x 1 out be the to pologically first output nod e in U . Consider two cases: • If x 1 in ∈ U , then the edg e x 1 in x 1 out must be in C . • If x 1 in ∈ U , since x 1 in has an in-d egree of d and it is the topolog ically first no de in U , all the inco ming edg es of x 1 in must be in C . Therefo re, th ese edges related to x 1 out will contr ibute a value of min { dβ , α } to the cut capacity . Now co nsider x 2 out , th e topolo gically seco nd ou tput node in U . Similar to the above, we have two cases: • If x 2 in ∈ U , then the edg e x 2 in x 2 out must be in C . • If x 2 in ∈ U , sin ce at m ost one of the incoming edges of x 2 in can b e fr om x 1 out , d − 1 in coming edg es of x 1 in must be in C . Follo wing the same reasonin g we find tha t fo r the i -th no de ( i = 0 , . . . , min { d, k } − 1 ) in the sorted set U , either one edge of capacity α or ( d − i ) edges of capacity β must be in C . Equation (1 1) is exactly summin g th ese contr ibutions. From Lemma 2, we know that there exists a graph G ∗ ∈ G ( n, k, d, α, β ) whose minc ut is e xactly P min { d,k }− 1 i =0 min { ( d − i ) β , α } . T his implies that if we want to ensure recoverability while allowing a newcomer to connect to any set o f d existing nod es, th en the following is a nece ssary con dition 4 min { d,k }− 1 X i =0 min { ( d − i ) β , α } ≥ M . (14) Furthermo re, when this condition is satisfied, we kn ow any graph in G ( n, k , d, α, β ) will have en ough flo w from the source to each data collec tor . For this r eason, we say C ∆ = min { d,k }− 1 X i =0 min { ( d − i ) β , α } (15) 4 This, howe ver , does not rule out the possibility that the mincut is lar ger if a newcomer can choose the d exist ing nodes to connect to. W e lea ve this as a future wor k. 12 is the ca pacity for ( n, k , d, α, β ) regenerating codes (where each newcomer can access any arbitrar y set of k nod es). Note that if d < k , requir ing any d storag e nod es to have a flo w of M will lea d to the same con dition (c .f. (14)) as requirin g any k storage no des to have a flow of M . Hence in such a case, we might as well set k as d . For th is rea son, in the fo llowing we assume d ≥ k withou t lo ss of generality . W e a re inter ested in characterizin g th e achievable tra deoffs between th e storage α and the repair ba ndwidth dβ . T o der i ve the optimal tr adeoffs, we can fix the repair bandwidth and solve for the minimum α su ch that (1 4) is satisfied. Recall that γ = dβ the total r epair bandwid th, and th e parameter s ( n, k, d, α, γ ) can b e used to character ize the sy stem. W e are interested in finding the whole region of f easible poin ts ( α, γ ) and then select the one that min imizes storage α or rep air bandwidth γ . Con sider fixin g bo th γ and d ( to some integer value) and minimize α ; α ∗ ( d, γ ) ∆ = min α (16) subject to: k − 1 X i =0 min 1 − i d γ , α ≥ M . Now observe that the dep endence o n d must be mon otone: α ∗ ( d + 1 , γ ) ≤ α ∗ ( d, γ ) . (17) This is beca use α ∗ ( d, γ ) is always a feasible solution f or th e optimization for α ∗ ( d + 1 , γ ) . Hence a larger d always im plies a better storage–r epair ban dwidth tradeoff. The optimization (1 6) can be explicitly solved: W e c all th e solution, th e thr eshold function α ∗ ( d, γ ) , which f or a fixed d , is piecewise linear: α ∗ ( d, γ ) = ( M k , γ ∈ [ f (0) , + ∞ ) M− g ( i ) γ k − i , γ ∈ [ f ( i ) , f ( i − 1)) , (18) where f ( i ) ∆ = 2 M d (2 k − i − 1 ) i + 2 k ( d − k + 1) , (19) g ( i ) ∆ = (2 d − 2 k + i + 1) i 2 d . (20) The last part of the proo f in volves showing that the threshold function is the solution of this o ptimization. T o simplify notation, intro duce b i ∆ = 1 − k − 1 − i d γ , for i = 0 , . . . , k − 1 . ( 21) Then the problem is to m inimize α sub ject to th e con straint: k − 1 X i =0 min { b i , α } ≥ B . (22) The left h and side of (22), as a fun ction of α , is a p iecewis e- linear fun ction of α : C ( α ) = k α, α ∈ [0 , b 0 ] b 0 + ( k − 1) α, α ∈ ( b 0 , b 1 ] . . . . . . b 0 + . . . + b k − 2 + α, α ∈ ( b k − 2 , b k − 1 ] b 0 + . . . + b k − 1 , α ∈ ( b k − 1 , ∞ ) . (2 3) Note f rom this expression that C ( α ) is strictly inc reasing fro m 0 to its ma ximum value b 0 + . . . + b k − 1 as α in creases from 0 to b k − 1 . T o find the minimu m α su ch that C ( α ) ≥ B , we simply let α ∗ = C − 1 ( B ) if B ≤ b 0 + . . . + b k − 1 : α ∗ = B k , B ∈ [0 , k b 0 ] B − b 0 k − 1 , B ∈ ( k b 0 , b 0 + ( k − 1) b 1 ] . . . . . . B − P k − 2 j =0 b j , B ∈ P k − 2 j =0 b j + b k − 2 , P k − 1 j =0 b j i (24) For i = 1 , . . . , k − 1 , the i -th co ndition in the above expression is: α ∗ = B − P i − 1 j =0 b j k − i , for B ∈ i − 1 X j =0 b j + ( k − i ) b i − 1 , i X j =0 b j + ( k − i − 1 ) b i , Note from the definitio n of { b i } (21) that i − 1 X j =0 b j = i − 1 X j =0 1 − k − 1 − j d γ = γ i 1 − k − 1 d + i ( i − 1 ) 2 d = γ i 2 d − 2 k + i + 1 2 d , = γ g ( i ) , and i X j =0 b j + ( k − i − 1 ) b i = γ ( i + 1) 2 d − 2 k + i + 2 2 d + ( k − i − 1) γ 1 − k − 1 − i d = γ 2 ik − i 2 − i + 2 k + 2 k d − 2 k 2 2 d , = γ B f ( i ) , where f ( i ) and g ( i ) are defined in (2)(3). Hence we have: α ∗ = B − g ( i ) k − i , f or B ∈ γ B f ( i − 1) , γ B f ( i ) . The expression of α ∗ ( d, γ ) then follows.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment