분산 저장 시스템을 위한 재생 코딩: 저장량과 복구 대역폭의 근본적 트레이드오프
이 논문은 기존 erasure code 기반 복구 방식이 전체 데이터를 전송해야 하는 비효율성을 지적하고, 각 저장 노드가 데이터의 함수만을 전송하도록 설계된 “재생 코딩(regenerating codes)”을 제안한다. 저장 용량(α)과 복구 대역폭(γ) 사이에 존재하는 최적의 트레이드오프 곡선을 정보 흐름 그래프와 네트워크 코딩 이론을 이용해 정량화하고, 그 곡선상의 모든 점을 달성할 수 있는 구체적인 코드 구조를 제시한다.
저자: Alex, ros G. Dimakis, P. Brighten Godfrey
본 논문은 분산 저장 시스템에서 데이터 신뢰성을 확보하기 위해 사용되는 erasure code가 복구 과정에서 발생시키는 과도한 네트워크 트래픽 문제를 해결하고자 한다. 전통적인 복구 방식은 실패한 노드의 데이터를 재생성하기 위해 살아있는 여러 노드로부터 전체 데이터 조각을 다운로드하고, 이를 다시 인코딩해 새로운 조각을 만든다. 이 과정에서 최소 k 개의 조각을 받아야 원본 파일을 복원할 수 있기 때문에, 복구 대역폭은 최소 M 바이트(파일 크기)와 동일하거나 그보다 크게 된다. 이는 복제 방식에 비해 저장 효율은 좋지만, 복구 시 네트워크 부하가 크게 증가한다는 단점을 가지고 있다.
저자들은 이러한 비효율성을 극복하기 위해 “재생 코딩(regenerating codes)”이라는 새로운 코딩 프레임워크를 제안한다. 재생 코딩에서는 새로 들어오는 노드가 기존 노드들로부터 직접 원본 데이터를 받는 것이 아니라, 각 노드가 보유한 데이터의 선형 함수(예: 선형 결합)를 전송한다. 이렇게 하면 전체 데이터를 전송하지 않아도 새로운 조각을 생성할 수 있다. 핵심은 각 노드가 전송하는 정보량 β와 저장 용량 α 사이의 관계를 최적화하는 것이다.
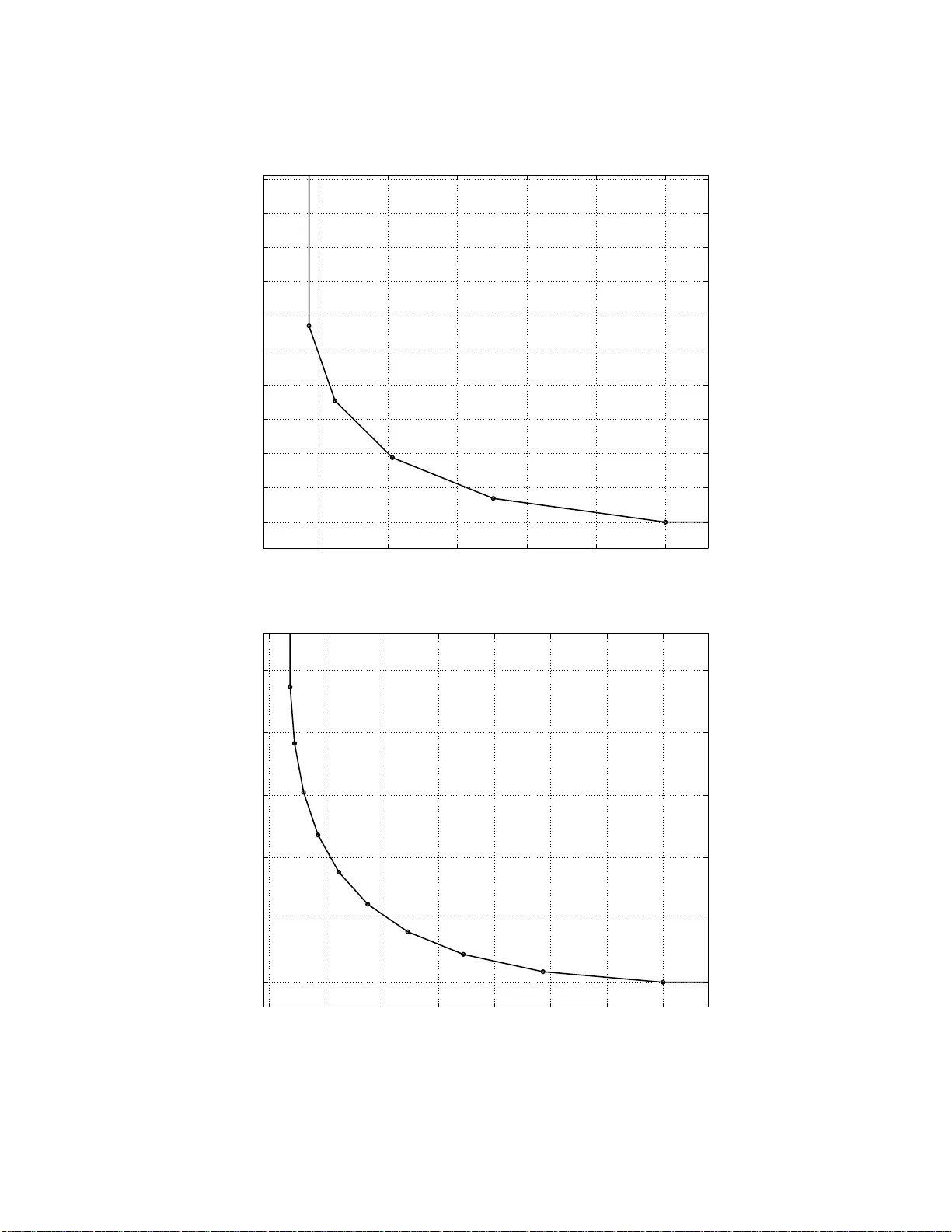
이를 정량적으로 분석하기 위해 논문은 “정보 흐름 그래프(information flow graph)”를 도입한다. 그래프는 다음과 같은 요소로 구성된다.
- 소스 노드 S: 원본 데이터의 출처.
- 저장 노드 i: 입력 노드 x_i^in과 출력 노드 x_i^out으로 분리되며, 두 노드 사이의 간선 용량은 α(노드에 저장되는 데이터 양)이다.
- 데이터 수집기 DC: 파일 복원을 요청하는 엔티티로, 무한 용량 간선으로 활성 저장 노드와 연결된다.
시스템이 동적으로 변하면서 노드가 실패하고 새로운 노드가 들어올 때마다, 새로운 입력 노드 x_j^in은 d개의 살아있는 노드의 출력 노드와 β 용량의 간선을 통해 연결된다. 이렇게 구성된 그래프에서 소스와 데이터 수집기 사이의 최소 컷(min‑cut)을 계산하면, 복구가 가능하기 위한 기본적인 정보량 제한을 얻을 수 있다.
수식적으로는 다음 부등식이 도출된다.
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기