RZBENCH: Performance evaluation of current HPC architectures using low-level and application benchmarks
RZBENCH is a benchmark suite that was specifically developed to reflect the requirements of scientific supercomputer users at the University of Erlangen-Nuremberg (FAU). It comprises a number of application and low-level codes under a common build in…
Authors: Georg Hager, Holger Stengel, Thomas Zeiser
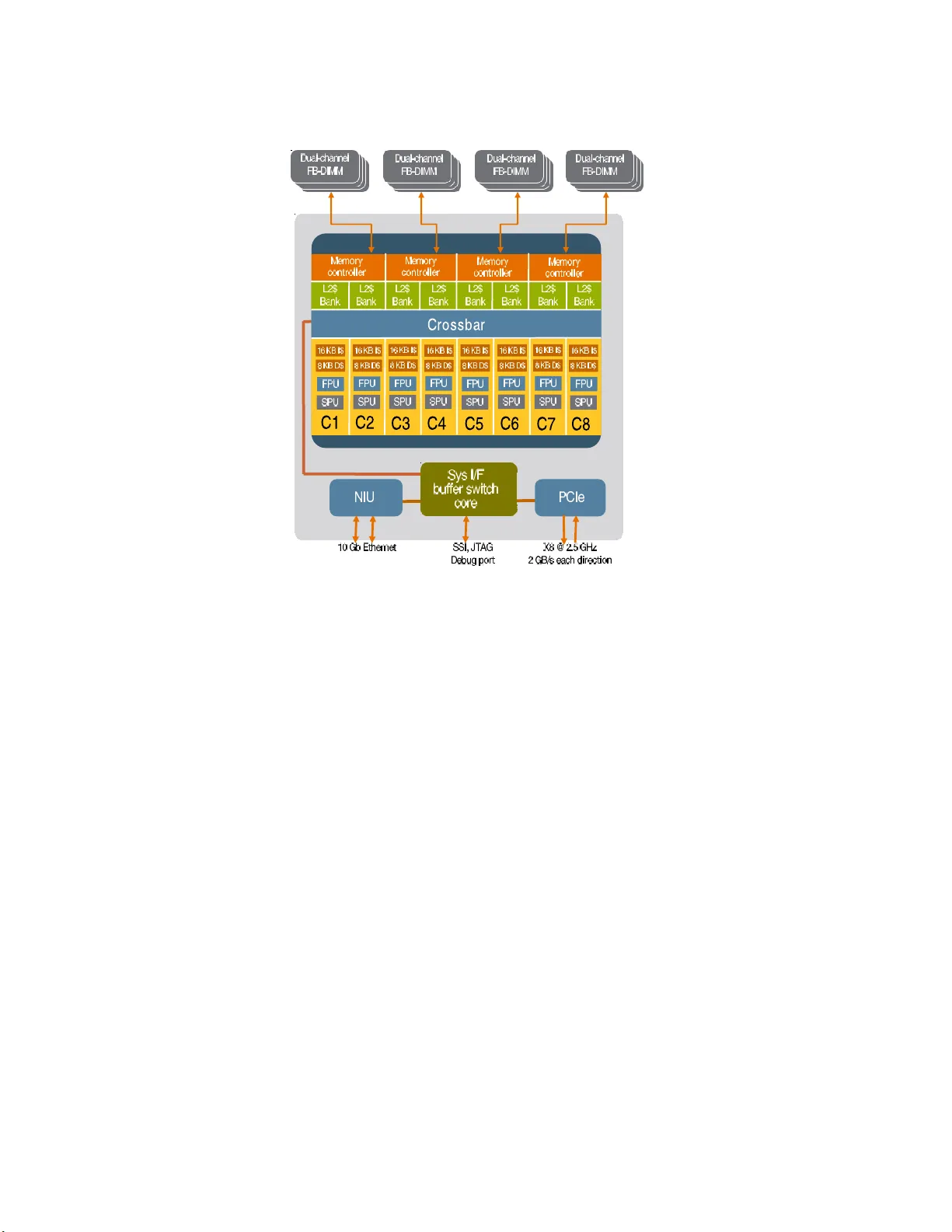
RZBENCH: P erformance ev aluation of curren t HPC arc hitectures using lo w-lev el and application b enc hmarks Georg Hager, Holger Stengel, Thoma s Zeiser, a nd Gerhar d W ellein Regionales Rechenzen trum Erlangen (R RZE), M artensstr. 1, D-91058 Erlangen, German y Summary . RZBENCH is a benchmark suite that was sp ecificall y developed t o re- flect the requirements o f scientific supercompu t e r users at the Universit y of Erlangen- Nuremberg (F A U). It comprises a num b er of application and lo w-level co des un- der a common b uild infrastructure that fos ters main tainability and expandabilit y . This pap er reviews the structure of the su ite and briefly introd uces th e most rele- v ant b enc hmarks. In addition, some widely know n standard b enc hmark co des are review ed in order to emp hasi ze the need for a critical review of often-cited per- formance results. B enchmark data is p res ented for the H LRB-II at LRZ Munic h and a local Infin iBand W o odcrest cluster as well as tw o uncommon system arc hi- tectures: A bandwidth-optimized Infi n iB and cluster based on singl e so c ket nod es (“P ort T ownsend”) and an early versi on of Sun’s highly t hrea d ed T2 arc hitecture (“Niagara 2”). 1 Introduct i on Benchmark r ankings ar e of premier impo rtance in High Performance Comput- ing. Decisions abo ut future pro curements are mostly based on results obtained by b enc hmarking ear ly access systems. Often, standardized suites like SP EC [5] or the NAS parallel b enc hmar ks (NPB) [6] are used because the r esults are publicly a v ailable. The downside is that the mixture of requir emen ts to run the standard b enc hmar ks fast is not guaranteed to b e in line with the needs of the lo cal users. Ev en worse, c ompiler vendors go to g r eat lengths to make their compilers pro duce tailor -made machine co de for well-known co de constellations. This do es not r eflect a real user situatio n. F or those reasons , the application benchmarks co n tained in the RZ BENCH suite ar e for the most part widely used b y scientists at F A U. They have bee n adapted to fit into the build framework and pro duce comprehensible per formance num b ers for a fixed s e t of inputs. A central customized make- file pro vides all the necessar y information like names of compilers, paths to libraries etc. After building the suite, customizable r un scrips provide a 2 G. Hager, H. Stengel, T. Zeiser, G. W ellein streamlined user interface by whic h all r equired parameter s (e. g., num b ers of thre ads/pro c esses and others) can b e sp ecified. Where numerical accur acy is a n issue, mechanisms for co rrectness checking have b een employ ed. O ut - put da ta is produced in “raw” and “coo k ed” formats, the latter as a mere higher-is-b etter p erformance num b er a nd the former as the full o ut put of the application. The co ok ed p eformance da ta can then e a sily b e p ost-pro c essed by s cripts and fed into plotting to ols or spreads heets. The suite contains co des from a wide v ariety of applica tio n are as and uses all of the language s and pa r allelization metho ds that are imp ortant in HPC: C, C++, F ortra n 77, F or t r an 90 , MPI, and OpenMP. 2 Benchm ark systems All state-of the art HPC systems are nowada ys based on dual- core and quad- core pr ocessor chips. In this analysis the fo cus is on standard dual-cor e chips such as the Intel Montecito and Int el W o odcr est/Conro e pro cessor se ries. The Int el Clov er to wn quad-cor e ser ies is o f no in teres t here, since it implements t wo complelety separa t e dual- core chips put o n the same c a rrier. W e compa re those sta nda rd tec hnologies with a new architecture, the Sun Ultr a SP AR C T2 (co denamed “Niagara 2” ), which might be a fir st glance at po t ential future chip designs: A highly threaded server-on-a-chip using many “simple” co res which run at low clo c k sp eed but supp ort a large num ber o f threads. T able 1. Sp ecificatio ns for the different compu t e no des, sorted according to single core, single sock et and single no d e p rop erties. The L2 cache sizes marked in bold face refer to shared on- c hip cac hes, otherwise all caches are lo cal to each core. Core Cach e Sock e t Node Platform Clock GHz P eak GFlop/s L1 kB L2 MB L3 MB # of cores Bandw. GB/s # of sock ets HLRB I I 1.6 6.4 16 0.25 9 2 8.5 1-256 W o odcrest 3.0 12.0 64 4 – 2 10.6 2 Conroe 2.66 10.6 64 4 – 2 8.5 1 Niagara2 1.4 1.4 8 4 – 8 42R+21W 1 2.1 HLRB I I – SGI Altix 4700 The SGI Altix 4700 sys tem at LRZ Munich compris e s 9728 Int el Itanium2 pro cessor cores integrated in to the SGI NUMALink4 netw or k. It is configur ed RZBENCH 3 C C P C C P C C P C C P C C P C C P C C P C C P R R Memory Memory Memory Memory S S S S Fig. 1. Possible lay out of a small SGI Altix system. The lines connecting routers (“R”) and SHUB chips (“S”) are NUMALink4 connections with a theoretical band- width of 3.2 GB/sec p er direction. as 19 c c N UMA no des each holding 512 cor es and a total of 2 Tbyte o f sha red memory per partitio n. The 13 standard nodes ar e equipped with a s ingle so c ket per memo ry channel, while in the six “high density” no des tw o s ock ets, i.e. four cores, have to share a single memory channel. T able 1 presents the single core sp ecifications of the Intel Itanium2 pro cessor us e d for HLRB I I. A striking featur e o f this pro cessor is its large o n-c hip L3 cache of 9 Mb yte per core. A mor e detailed discussion of the Int el Itanium2 architecture is presented in Ref. [8]. The NUMALink4 net work provides a high bandwidth (3.2 Gb yte/s p er direction and link), low la t ency (MPI latency c an be less than 2 µ s ) comm u- nication net work (see Fig. 1 for a p ossible netw o r k top ology in a small Altix system). Howev er, the ne tw o rk top ology implemented do es not allo w to keep the bi-se ct io nal bandwidth constant within the sy stem. Even the no m inal bi- section bandwidth p er s ock et (0.8 Gbyte/s p er direction) in a sing le standar d no de (256 s ock ets) falls sho rt of a sing le p oin t to po in t connection by a factor of four. Co nnec t ing the no des with a 2 D tor us NUMALink top ology , things get ev en worse. F or a more detailed picture of the curr en t netw or k to pology status we refer to Ref. [9]. All measurements presented were done within a s ingle standard no de. 2.2 W o o dcrest – InfiniBand cluster The W o o dcrest system at RRZE repr e sen ts the pr otot ypical desig n of mo dern commo dit y HP C clusters: 217 compute no des (s e e Fig . 2 ) are connected to a single InfiniBand (IB) switch (V oltaire ISR9288 with a maximum of 288 por t s, cf. [1 0 ]). The dual-so c ket compute no des (HP DL1 4 0G3) are equipp ed with 8 Gb ytes of main memory , tw o Intel Xeon 516 0 dual core chips (co denamed “W o odcrest” ) running at 3.0 GHz and the bandwidth o ptim ized “Greencr eek” 4 G. Hager, H. Stengel, T. Zeiser, G. W ellein Socket C C C Chipset Memory P P P P C C C Fig. 2. La yout of a single W o odcrest-based compute no de. Eac h line connected to the chipset represents a data path with a band w idth eq uiv alent to FSB1333. chipset (In tel 5 000X). With Intel’s new C o re2 architecture several improv e- men ts were intro duced as co mpa red to the Netburst design, aiming a t higher instruction throughut, shorter pipe lines and faster caches to na me a few which are imp ortant for High Performa nce C o mput ing. Each no de features a DDR IB HCA in its PCIe- 8x slot, thus the maxim um IB co mm unication band- width (20 GBit/s p er direction at 10 bits per byte) is exac tly matched to the capabilities of the PCIe -8x slo t (16 GBit/s per direction at 8 bits pe r byte) . The tw o- lev el IB switch is a compr o mise b et ween DDR and SDR (10 GBit/s per dir ection) technology: The 2 4 switches a t the fir st level which provide 1 2 downlinks to the compute no des and 12 uplinks r un at DDR sp eed, while the 12 second level s witc hes run at SDR sp eed. T hus, communication intensiv e applications can get a p erformance hit when spr ead ov er several first level switches. 2.3 Conro e – InfiniBand clus ter While m ulti-so ck et compute nodes a re the standar d building blo c ks of HPC clusters they a re ob viously not the optimal choice for a wide r ange of MPI- parallel HPC applications : • A single netw ork link m ust b e shared by s e v eral s o ck ets. • ccNUMA technology as used in, e.g., the SGI Altix or AMD Op eron ba sed systems bea rs the potential for per f or mance p enalties when lo calit y con- traints ar e not obser v ed. • Bus overhead is in tro duced by ca c he cohere n cy pro tocols. Going back to the “ro ots” of clus ter computing, as implemented by the s ing le so c ket Intel S3000 PT bo a rd design, one ca n alleviate these problems : A single RZBENCH 5 so c ket is connected to one netw ork link and to the lo cal memory throug h a single frontside bus (FSB1 066). While the nominal bandwidth pe r s ock et is reduced as co mpared to the HP DL14 0 G3 compute no des (tw o FSB1 3 33 con- nections for t wo so c kets), p o wer cons umption can b e singnifica n tly improved through the use of unbuffered DIMMs ins tea d o f fully buffered DIMMs. Note that the pow er consumption of a single fully buffered DIMM ca n b e as high as 5–10 W atts. Moreover, the lack o f cache co he r ence traffic can ov erco m e the nominal los s in ma in memory bandwidth, re s ult ing in an equal o r even higher main memory thr o ughput p er so c ket for the Conro e system a s measured with the TRIAD be nchmark b elo w. The Xeon 307 0 dual-cor e CPUs (co denamed “Conro e”) used in this system implemen t the Intel Cor e2 architecture and run a t 2.66 GHz. 66 S3000P T no des with 4 Gb ytes of memory each ar e connected to a 72 -port IB switc h (Flextronics) running at full DDR s peed. 2.4 Sun UltraSP AR C T2 – s i ngle s oc ket Sun serv er The single so ck et “Niagar a 2” system studied in this r eport is a n early access, pre-pro duction mo del of Sun’s T2 ser v er series. T rading high single cor e p er- formance for a highly parallel system o n a chip architecture is the basic idea of Niag ara 2 as ca n b e seen in Fig . 3: Eight simple in- order co res (running at 1.4 GHz) ar e connected to a shared, banked L2 cache and four indep enden tly op erating dual channel FB-DIMM memory controllers thr ough a non-blo c king switch. At first glance the UMA memor y subsystem provides the scala bilit y of ccNUMA approa c hes, taking the be s t of tw o worlds at no co st. The aggr e- gated nominal main memor y bandwidth of 4 2 Gbyte/s (read) and 21 Gbyte/s (write) fo r a sing le so c ket is far a head of most o ther general purp ose CPUs and topped only b y the NEC SX-8 vector series. Since there is only a single floating p oin t unit (per f o r ming MUL T o r ADD o perations) p er c o re, the sys- tem balanc e of a ppro ximately 4 bytes/Flop (assuming read) is the same as for the NEC SX-8 vector pro cessor. T o overcome the restrictions of in-or der a r c hitectures and long memor y latencies, each co re is able to supp ort up to eight threads. T he s e thr eads ca n be interleav ed betw een the v a rious pip eline s t a g es with only few restrictions [2]. Thus, r un ning more than a s ingle thread p er cor e is a m ust for most applications. Going b ey o nd the r equiremen ts of the tests presented in this r eport o ne should be a ware that the Niag ara 2 chip also comprises on-chip PCIe- x8 and 10 Gb Ethernet connections as well as a cr yptographic copro cessor. 6 G. Hager, H. Stengel, T. Zeiser, G. W ellein Fig. 3. B lo c k diagram of the Sun UltraSP A RC T2 (“Niagara 2”) chip architecture [2]. Eight physical cores ( C 1 , . . . , C 8) with local L1 data (8 KB) and L1 instruction (16 KB) caches are connected to eigh t L2 banks (tw o of them sharing a memory contro ller) through a non-blo c king crossbar switch. S e veral interco nn ect p orts (e.g. PCIe-8x or 10 Gb Ethernet) and a cry ptogr aph i c copro ces sor are put on the die, complemen ting the “serv er on a c hip” arc hitecture. (Picture by courtesy of Sun Microsystems) 3 Low- level bench marks and p erforma nce r e sults 3.1 TRIAD TRIAD is bas ed on the w ell-k nown vector tria d code, which has b een ex- tensively used by Sch¨ onauer [7] to quantify the capabilities of memory int er f ac e s. The tria d p erforms a multiply-add op eration on four vectors, A(:)=B (:)+C(:)*D(: ) in F ortra n. The lo op kernel is r e peated to pro duce accurate execution time and cache p erformance mea suremen ts. With its code ba lance of 2 words/Flop, the vector triad is obviously limited by memo r y bandwidth on a ll cur ren t sup ercomputer systems, including vec- tors. If the arrays are short enough to fit into the cache of a RISC pro cessor, the b enc hmar k tes t s the ability of the cache to feed the a rithmetic units. Even in this situation ther e is no proc essor on whic h the triad is purely c ompute- RZBENCH 7 bo und. Co nsequen tly , given the array leng t hs and basic ma c hine p erformance nu mber s like maximum cache and memory bandwidths a n d latencies, it s ho uld be easy to calcula te to highest p ossible p e rformance of the v ecto r triad. Unfor- tunately , many o f the c ur ren tly p o pular P C-based systems fall short of those exp ectations bec a use their memor y interface suffers from s e v ere inefficiencies . The usual write-back polic y for outer-level caches le a ds to an a ddit io n a l complication. As the cache can o nly c omm unicate w ith memory in ch unks of the cache line size, a wr ite miss kicks off a cach e line read first, g iving the cache exclusive ownership of the line. These so -called RF O (rea d for ownership) transactions increase the co de balance even further to 2.5 words/Flop. So me architectures supp ort sp ecial mac hine instructions to circumven t RFOs, either by bypassing the cache altog eth er (“non-tempo ral” or “ s treaming” stor es on x86, “blo c k stores” on Sun’s UltraSP ARC) or by claiming cac he line owner- ship without a prior read (“cac he line zero” on IBM’s Pow er architecture). Often the compiler is able to apply those instr uc tio ns automa t ica lly if certain alignment constraints ar e satisfied. It must b e noted, thoug h, that cache by- pass on write can hav e s ome impact on p erformance if the problem is actually cache-bound. While the vector triad code in RZ BENCH is designed with MPI to al- low simple saturation measur emen ts, this b enc hmark is most o ften used with standard Ope nMP paralle liz ation. Unfortunately , Op enMP can hav e some adverse effects on p erformance. If, for instance, the applica bilit y o f sp ecial in- structions like non- t emp oral stores dep ends on the c o rrect alignment of da t a in memory , the compiler must “play s afe” and genera t e co de that can do with- out a ssumptions a bout alignment. At b est there will b e tw o different versions of a lo op which are selec t ed a t runtime acco rding to alignment constraints. If other r estrictions like, e.g ., ccNUMA placement or load im bala nce further confine av ailable options, one ca n eas ily b e left with large compromise s in per formance. As a n example we will consider the Op enMP vector tr ia d o n Sun’s Ultra- SP ARC T2 proce s sor, describ ed in Sect. 2.4. Without any sp ecial pro visio ns the v ector triad p e rformance with 32 threads shows a very erratic pattern (circles in Fig. 4). Threads were distributed evenly acr oss cores for these runs. Apparently , so me v alues for N entail a ccess patterns that utilize, in the worst case, only one of the four av ailable memory controllers a t a time. This can b e easily explained by the fact that the controller to use is selected by address bits 8 and 7, while bit 6 determines which of the tw o L2 banks to access [2, 3]. If N is such that all threads alwa ys hit the same memor y controller or even cache bank for all four data streams concurrently , p erformance br eaks down by a fa c to r of four. The t ypica l “lo ckstep” acces s pattern emp osed by lo op kernels that work on multiple data str eams ensures this in a mos t reliable way if OpenMP chun k base addre s ses ar e aligne d inappropriately . This condition can actually b e enforced by ma n ual a lignmen t of A(:) , B (:) , C(:) , and D( :) to byte addr e sses which are multiples o f 5 1 2 = 2 9 . In Fig. 4, the dev astating effect of alignment to 409 6 byte b oundaries is shown (squar es). 8 G. Hager, H. Stengel, T. Zeiser, G. W ellein 10 5 10 6 10 7 N [DP words] 0 250 500 750 1000 Performance [MFlops/s] std triad align 4k align 4k, shift=32 align 4k, shift=128 Fig. 4. Op enMP-parallel vector triad p erformance versus arra y length for d i fferent alignmen t options on Sun U l traSP ARC T2 with 32 threads and static scheduling. Knowing the details ab out memory controller assigment, ho wev er, it is easy to devise a mutual arra ngemen t of ar ra ys that av oids the b ottlenec ks. After alignment to the 4 kB b oundary , the four a rra ys can b e s hifted by four different integer multiples of so me offset k . The triang les and diamonds in Fig. 4 show the results for k = 32 and k = 1 2 8, re s pectively . The la tter cas e seems to be optimal, which is not s u r prising since it constitutes the “s weet sp ot” where all four controllers are addressed concurr en tly , indep enden t of N . All erratic b e ha viour has v anished. It m ust b e stressed that the Niagara 2 architecture shows a v ery rich s et of p erformance fea tur es, of which the influence of ar ra y alignment is only one. F urthermore, the starting addresses for the 3 2 O penMP c hunks that emerge fro m static sc heduling hav e not b een adjusted in a n y sp ecial way . This may be insig nifican t on the Niagara 2, but it is of vital imp ortance on x86-bas ed a rc hitectures where certain vectorization instructions can only be applied for arrays that are a ligned to 16 byte b oundaries. Details about if and how optimal alignment and data placement can b e achieved b y sp ecial progra mmin g techniques will b e published elsewhere. 3.2 IMB T o test the basic capa bilit ies o f the interconnects we use the Intel MPI b enc h- mark (IMB 3.0) suite whic h is the successo r o f the famous Pallas MP I suite. RZBENCH 9 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 N [byte] 0 1000 2000 3000 B eff [Mbyte/s] Voltaire DDRx: SDR Voltaire DDRx: DDR NUMALink4 (cf. inset) NUMALink4 (mod) 10 0 10 1 10 2 10 3 Message Size [byte] 0 2 4 6 Latency [ µ s] 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 N [byte] 0 2000 4000 6000 8000 B eff [Mbyte/s] MPI_BUFFER_MAX= 8192 MPI_BUFFER_MAX=32768 MPI_BUFFER_MAX=10 9 NUMALink4 Fig. 5. MPI “PingP ong” interconnect bandwith ( B eff ) ( m ain panel and left inset) and interconnect latencies (right inset) as measured wi th the IMB. F or SGI A l tix, bandwidth numbers of the standard I M B implemen tation and differen t v alues of MPI BUFFER MAX are giv en in the left inset while in the main panel results are included for a mo dified versio n (mod) of IMB, whic h acco unts for the sh ared- memo ry node arc hitecture. Within this suite the standa r d benchmark to tes t the unidirectional band- width and latency b et ween t wo MP I pro cesses is the so called “PingPong”: Using MPI _SEND / MPI_ RECV pair s a messa ge is sent from one to the o t her pro- cessor and upo n arriv al a differe nt mess age is sent back. This is rep eated a large num be r of times to get sufficient acc uracy , but it is imp ortan t to no te that the messa ges themselves ar e never touched, i.e. mo dified, in this scheme. The main panel of Fig. 5 depicts the typical unidirectional bandwidth vs. message size . The left ins et sho ws latency for the interconnects used in this per formance study . While the IB technologies behave the con ven tional way and a c hieve appr o ximately 70–7 5% of their unidirectiona l bandwidth limit, running the b enc hmark with no changes on the SGI Altix shows a str ange b e- haviour (left inset o f Fig. 5). A bandwidth maximum of more than 7 GB/s can be achiev ed at in termediate message lengths, exceeding more than t wice the nominal capa bilities of NUMALink4. F or larg e mes sages p erformance brea ks down to the IB DDR level. Although results like this a re rea dily interpreted by vendors to show the sup e rior quality of their pro ducts, a more thoro ugh analys is is in or der. Keeping in mind that b oth pro cesses inv olved in the communication run in shared memory , the m ystery is easily unrav eled (see Fig. 6 ): The transfer of 10 G. Hager, H. Stengel, T. Zeiser, G. W ellein P0 C0 M0 P1 C1 M1 sendb 0 sendb 1 4 3 1 2 sendb 0 00 00 11 11 sendb 1 00 11 1 recvb 0 recvb 1. First ping: P1 copies sendb 0 to recvb 1 , whic h resides in its cache 2. First p ong: P0 copies sendb 1 to recvb 0 , whic h resides in its cache 3. Second ping: P1 p erforms in-cac he copy operation on its u nmodified recvb 1 4. Second p ong: P0 p erforms in-cache copy operation on its u nmodified recvb 0 5. . . . Rep eat steps 3 and 4, working in cac he Fig. 6. Chain of even ts for th e standard MPI PingPo ng on shared-memory systems when the messages fit in to cache. C0 and C1 denote the cac hes of pro cessors P0 and P1, resp ectiv ely . M0 and M1 are P0’s and P1’s lo cal memories. sendb 0 from pro cess 0 to recvb 1 of pro cess 1 can b e implemented as a sing le c opy op eration on the receiver side, i.e . pr ocess 1 executes r ecvb 1 (1:N) = sendb 0 (1:N) , where N is the num b er o f bytes in the mess age. If N is suffi- ciently sma ll, the data fr o m send b 0 is lo cated in the cache of pro cess 1 and there is no need to repla ce o r mo dify these cache entries unless send b 0 gets mo dified. How ever the se n dbuffers are not changed o n either pro cess in the lo op k ernel. Thus, a f ter the first iteration the sendbuffers are lo cated in the caches of the receiving pro cesses and in-ca c he copy op erations oc cur in the succeeding iterations instead of da ta transfer through the netw ork. There a re t wo reasons for the p erformance drop at la rger message sizes : First, the L3 cache (9 Mbyte) is to small to hold both or at lea st one of the lo cal r eceiv e buffer and the remo te send buffer. Second, the IMB is p erformed so that the num b er of rep etitions is decrease d with increasing message size un til only one iteratio n — which is the initial copy operatio n through the net work — is do n e for lar g e messa ges. The use of single-copy transfers as des cribed a bov e can b e controlled on SGI Altix through the MPI_ BUFFER_MAX e nvironment v ariable which sp ecifies the minim um size in bytes for which messag e s a re co ns idered for single-co p y . As can b e seen in the left inset o f Fig. 5, changing the environmen t v aria ble from its default v alue 32768 one can adjust the width of the artificial ultra-high bandwidth “hump”. If MP I_BUFFER_M AX is larg er than the biggest message, the effect v anishes completely . In this ca se, how ever, asymptotic p erformance (stars in ma in pa n el of Fig. 5) dr ops significantly below the IB DDR num b ers. This leads to the conclusion that there is substa n tial ov er h ea d in this limit with single-copy transfer s disabled. It is obvious that rea l-w orld applicatio ns can not make use of the “ perfor- mance hump”. In or der to ev aluate the full p oten tial o f NUMA Link4 for co des that should benefit from single-co p y for lar ge messages, we sugges t a simple RZBENCH 11 mo dification of the IMB Ping P ong benchmark: Adding a second “ P ingP ong” op eration in the inner iteration with a rra ys se ndb i and recvb i int er c hanged (i.e. s endb i is sp ecified as the r eceiv e buffer with the second MPI_R ECV on pro - cess i ), the s ending pro cess i g ains ex clusiv e ownership of sen db i again. After adjusting the timings in the co de a ccordingly the mo dified version shows the well k no wn a nd sensible netw ork characteristics (diamonds in Fig . 5 ). In view of this discussion so me ma xim um “PingPong” ba ndwidth num ber s for SGI Altix systems o n the HPC Challeng e website [1 1 ] should be recons id - ered. 4 Application b enc hmarks and p erformance results 4.1 Benchmark descriptions This section describ es briefly the applications that constitute par t of the benchmark s uit e. W e have selected the five most interesting co des which were also us ed in the previous pro curemen t by RRZE under similar b oundary con- ditions (pro cessor num b ers etc.). EXX EXX is a quant um chemistry pa c k age develop ed at the chair for theoret- ical chemistry a t F A U. It is us ed for the c a lculation of str uc tur al and elec- tronic prop erties of p eriodic systems like solids, slabs or wires , a pply ing (time- depe ndent) Densit y F unctional Theory (DFT). Performance is dominated b y FFT op erations using the widely known FFTW pac k age. The prog ram is writ- ten in F ortra n90 and par allelized using MP I. The b enc hmark ca se con tained in the s uite is larg ely ca c he-b ound and scales rea sonably well up to 32 cores. Note that EXX b ears so me o pt imiza- tion p oten tial (trigonometric function tabula t io n, FFT accelera tion by vendor libraries) which has be en exploited by benchmarking teams in the course of pro curemen ts. Howev er, for long-term repro ducability and co mparabilit y o f per formance results the codeba se will no t be c hang ed to reflect ar c hitecture- sp ecific optimizations . AMBER/PMEM D AMBER is a widely used commercial molecular dyna m ics (MD) suite. Distri- buted-memory FFT and for c e field calculations domina t e pe r formance. The benchmark case “ HCD ” used for these tests s im ulates HPr:CCpa tetra mer dynamics using the PMEM D mo dule o f AMBE R. This c ode is la rgely cache-bo und but also suffers fro m slow netw orks. The progra m is written in F or tran90 a nd paralleliz ed with MPI. 12 G. Hager, H. Stengel, T. Zeiser, G. W ellein IMD IMD is a molecular dyna mics pack age develop ed at the Universit y of Stuttgart. A t F A U, it is mainly used by Ma ter ials Science groups to simulate defect dynamics in so lids. It is weakly dependent o n memory bandwidth and has mo derate communication r equiremen ts. The pack a ge was developed in C a nd is pa r allelized using MPI. As the test case works with a 1 00 3 lattice a nd the domain is decomp osed evenly in all three dimensions, 64 is the la rgest p o wer- of-tw o pro cess num ber that can b e used with it. Oak3D Oak3D is a ph ys ics co de develop ed at the Institute fo r Theoretical Physics at F AU. It mo dels the dynamics o f exotic (sup erheavy) nuclei via time-dep endet Hartree-F o c k (TDHF) metho ds and is us ed to simulate photoabso rption, elec- tron capture , n uclear fusion and fission. F or calculating deriv atives, the code relies heavily on small-size FFTs that are usually handled inefficien tly by vendor-provided pack a ges. This is wh y Oak3D uses its own FFT pac k age. Performance is domina ted b y FFT and dense matrix-vector op erations; for large pro cessor num b ers a n MPI _ALLREDUCE op e ration gains impo rtance. So me memory ba ndwidth is required, but be ne fits from lar ge ca c hes can b e exp ected. The co de was develope d with F or tran90 a n d MP I. TRA TS TRA TS, also k nown a s BE S T, is a pro duction-grade lattice-B oltzmann CFD co de develop ed a t the Institute for Fluid Dyna mics (F AU). It is heavily memory-b ound on standar d micro computers, but compute-b ound on top of the line vector proces sors like the NEC SX b ecause of its co de balance of ≈ 0 . 4 words/Flop. It uses F or tran90 and MPI for paralleliza tion. Paralleliza- tion is do ne by domain decomp osition, and in the strong scaling benchmark case we chose a 128 3 domain, cut into quadr atic slabs along the x - y pla ne . While w e ar e aw ar e that this is not an optimal domain decompositio n, it al- lows us to control the communcation v s. computatio n r atio q u ite eas ily . With strong s caling it th us represents a p ow erful b enc hmar k fo r netw ork capabili- ties. TRA TS is cur ren tly the only code in the suite fo r which the ex ecution infrastructure pr o vides a w eak scaling mo de, but this feature has not b een used here. W e present p erformance results for applica t ion benchmarks in a concise format as it would b e imp ossible to iterate over all p ossible options to run the five co des on four architectures. Dual core pro cessors ar e used throughout, so we p erformed sca la bilit y measure m ents by filling chips firs t and then so c k- ets. That way , neighbouring MPI ra nk s share a dual-co re chip when po ssible. Strict pr ocess-c ore pinning (pro cessor affinity) was implement ed in order to RZBENCH 13 get r eproducible a nd consistent results. On HLRB2, all runs were pe rformed inside a sing le standard (no high-density) dedicated SSI no de. The latest com- piler relea ses av aila ble at the time of writing w ere used (In tel 10.0.0 25 and Sun Studio 12). F or Nia g ara 2 only a subse t of the application b ench mar ks was considered. A more complete investigation is under w ay . 4.2 Perf orm ance results Single core As a first s t ep we compar e the s ing le cor e pe r formance of HLRB2, the RRZE W o o dcrest clus t er a nd the RRZE Conro e cluster in order to set a baseline for scalability measurements. Extra polating from raw clo c k frequency and mem- ory ba ndwidt h num b ers one might exp ect that Ita niu m cor es co uld hardly b e comp etit ive, as mea s ured by their price ta g. How ever, one should a dd that the Itanium bus interface is muc h more efficient than on C o re2 in terms of achiev able fractio n of theoretical bandwidth, even if the la ck of non-temp oral store instructions on IA64 is taken into acco un t. Mor eo ver, if the compiler is able to g enerate efficient E PIC co de, the IA64 a rc hitecture can deliver b ett er per formance p er clock cy cle than the less clean, very complex Core2 design. Fig. 7 reflec ts thos e p eculiarities. I nterestingly , the largely ca c he-b ound co des EXX and AMBER/P MEMD (se e Fig. 8 for PMEMD as the parallel binary requires at lea st tw o MP I proc esses) that may b e exp ected to scale r oughly with clock frequency sho w s uperior p erformance on Itanium 2. On the other hand, although Oak3D should b enefit fro m la rge memor y ba ndwidt h and big caches, it falls shor t of these ex pectations by r o ughly 4 0 %. This effect can b e explained by the abunda nc e of s hort lo ops in the code which p ose a severe problem for the in-o rder IA64 architecture. Even if softw are pip elining can b e applied by the compiler, short lo ops lead to domina ting wind-up and wind- down phases which ca nnot b e overlapped betw een adjacent loops without manual int er v ention by ha nd -c oded a ssem bly [4]. Moreov er , latency cannot be hidden efficiently by prefetching. F or the lattice-Bo lt zma nn co de TRA TS, how ever, IA64 is way a hea d p er core b ecause its memory architecture is able to sustain a larg e num b er of co current write streams. The re sults a re thus in line with published STREAM ba ndwidth num b ers [1 ]. Int er estingly the Conro e system, despite of its lo wer nomina l p er-so c ket memory ba ndwidt h (FSB1 066) compared to W o o dcrest (FSB13 3 3), outper - forms the latter significantly on TRA TS and O ak3D. Its simple one- sock et no de design is o bviously a ble to y ield a muc h hig her fraction of theoretical pea k bandwidth. F or the cache-bound c o des IMD, EXX and AMBER Con- ro e suffers fro m its low er clo ck frequency . W e will see later that this can in some cases b e ov erco mp ensated by the s uperior p er-so c ket netw ork bise c tio n bandwith of the Conr oe cluster . 14 G. Hager, H. Stengel, T. Zeiser, G. W ellein PMEMD EXX IMD Oak3D TRA TS 1 0.5 b c b c b c b c b c HLRB2 r s r s r s r s r s W o odcrest u t u t u t u t u t Conroe Fig. 7. Single core p erformance comparison using th e most imp o rtant b enchmarks from the RZBENCH suite. Num b ers hav e been normalized to the best system for eac h b enchmark. The parallel binary for PMEMD requires at least t wo MPI p ro - cesses. One and t w o so c k ets The cur r en t evolution of m ulti-core proce s sors shows the attractive prop ert y that the pric e p er raw CPU so ck et (or “chip”) stays roug hly constant ov er time. If soft ware can exploit the increased lev el of parallelism provided by m ulti-co re, this le ads to a price/ performance ra tio that follows Mo ore’s Law. Of c ourse, bottlenecks like shared caches, memory connections and netw o r k int er f ac e s reta r d this effect so that it is vital to kno w what le v el of perfor- mance ca n be expected from a single so ck et. This da ta is shown in Fig. 8. Comparing with the single-core data in Fig. 7, the most notable obser v ation is that in contrast to the x86-ba s ed pro cessors the IA64 system is able to im- prov e sig nifican tly o n Oak3 D p erformance if the second c ore is used. This is mostly due to the doubling o f the agg regated ca c he size fro m 9 MB to 18 MB and b ecause tw o cor es can sustain mo re outsta nd ing references a nd thus b et- ter hide latencies. F or the o th er benchmarks, scalability from one to tw o cor es is roug hly equiv alent. The tw o-so ck et W o odcres t no des that ar e in wide us e to day deserve some sp ecial a t tention here. Although the no de lay out sugg ests that memor y ba nd- width should scale when using tw o sockets instead of one, memory-b ound benchmarks indicate that the gain is sig nifica n tly b elo w 100 %. Fig. 9 shows a compar ison betw een o ne-core, tw o-cor e and four-cor e (t wo-so c ket) per f o r- mance on a single W o odcres t no de. The ca c he-b ound co des EXX and IMD are obviously able to pro fit muc h b etter from the second c o re o n a chip than RZBENCH 15 PMEMD EXX IMD Oak3D TRA TS 1 0.5 b c b c b c b c b c b c HLRB2 r s r s r s r s r s r s W o odcrest u t u t u t u t u t u t Conroe Fig. 8. Single socket p erf ormance comparison. In case of the Conroe system th is is a complete no de. the bandwidth-limited Oak 3D and TRA TS. F or Oak3 D this cor robor ates our statement that aggr egate cache size b oo sts tw o-c o re p erformance on HLRB2. PMEMD EXX IMD Oak3D TRA TS 1 0.5 b b b b b b 2 sockets r r r r r r 1 socket q q q q q 1 core Fig. 9. Scal ability inside a tw o-socke t W oo dcrest nod e: Single core, single sock et and tw o-sock et p erf ormance. There is no one-core data for PMEMD as th e p a rallel binary for this b enchmark n eed s at least tw o MPI pro cess es. 16 G. Hager, H. Stengel, T. Zeiser, G. W ellein As s uggested ab o ve, s calabilit y o f TRA TS and Oa k3D when going from one to t wo so ck ets is less tha n p erfect (impro vemen ts of 70 % and 80 %, resp ec- tively). This result is matc hed b y published STREAM performa nce data [1]. As fo r the rea s on one may specula te that c ac he cohe r ence traffic cuts on av ail- able ba ndwit h although the Intel 5 000X chipset (“Gr eencreek”) has a sno op filter that should eliminate r edundan t address sno o ps. In a n y case, we must emphasize that in the era o f m ulti-core pro cessing it ha s be c ome vital to un- derstand the top ological pro perties and b ottlenec ks of HP C a rc hitectures and to act accor dingly by pro per thread/pro cess placement. Scalabilit y In terms of scalability one ma y exp ect the SGI Altix system to outp erform the Int el-ba sed clusters b y far becaus e of its NUMALink4 in terco n nect featuring 3.2 GB/s p er direc tio n p er so ck et. How ever, as mentioned ab o ve, even inside a s ingle Altix no de the net work is not completely non-blo cking but provides a nominal bisectio nal bandwidth of about 0.8 GB/ s p er so ck et and direction only , which is roughly equiv alent to the achiev able DDR InfiniBand PingPong per formance using a standard non- blocking switch. W e thus ex pect s calabilit y to s ho w roug hly similar b ehaviour on all three a rc hitectures, certa inly taking int o acc oun t the differe nces in single-so ck et p erformance. PMEMD (32) EXX (32) IMD (64) Oak3D (128) TRA TS (128) 1 0.5 b c b c b c b c b c b c HLRB2 r s r s r s r s r s r s W o odcrest u t u t u t u t u t u t Conroe Fig. 10. Par allel p erformance comparison. The num b er of MPI p rocesses used is indicated for each b enc hmark . Fig. 10 shows a p erformance comparis on for parallel runs b et ween 32 and 128 cor es. The Conr oe system c an extend its lead on W o odcr est esp ecially for RZBENCH 17 the net work-b ound parallel TRA TS when compared to the one- sock et case (Fig. 8) and ev en draws lev el with HLRB2. This is due to its competitive net work bisection bandwidth. On PMEMD, despite its 1 0 % low er clock fr e- quency , Conro e can even slightly outp erform W o odcr est for the same r eason. In this con text, E XX shows a s omewhat atypical b ehaviour: Performance on W o o dcrest is far sup erior, des pit e the pro mising sing le core and single so c ket data (Figs. 7 and 8). The r eason for this is as yet unknown and will b e inv es- tigated further. 1 2 4 8 # cores 0 0.5 1 1.5 2 relative performance HLRB2 Woodcrest Conroe Niagara 2 (64 threads) IMD 1 2 4 8 # cores 0 0.5 1 1.5 2 relative performance HLRB2 Woodcrest Conroe Niagara 2 (64 threads) Oak3D Fig. 11. Comparing the Sun UltraSP ARC T2 with the I n tel-based arc hitectures using IMD (left) and Oak3D (right). F or reference, all d a ta w as normalized to the one-socket p erformance on Su n UltraSP ARC T2 (d a shed line). Using the IMD and Oak3D benchmarks as prototypical cache a n d mem- ory bo u nd c odes, resp ectiv ely , we finally co mpa re the Intel-based archit ec- tures with Sun’s Niagara 2 in Fig . 1 1 . Ro ug hly , a single Nia gara 2 so c ket is equiv alent to b et w een four and six Intel cores. Note, how ever, that it takes 64 MPI pro cesses to reach this level of per f or mance: Mas siv e multithreading m ust make up for the rather simple desig n of the single core so that av ailable resource s like memo ry bandwidth ca n be fully utilized and latencies can be hidden. 5 Conclusions and ackn owledgem ents W e have analyzed low-level and application b enc hmarks on cur ren t high- per formance ar c hitectures. On an early- a ccess Sun Niagar a 2 system we hav e shown that naive vector tr ia d per formance fluctuates erratica lly with v ary ing array size due to the hard-wir ed mapping of addresses to memor y co n trollers. Careful choice of a lig nmen t constraints and appropriate pa d ding a llo wed us to eliminate the fluctuations completely , lea ding the wa y to ar c hitecture-sp ecific optimization a pproac hes in the future. On HLRB2 we ha ve explained a widely unrecognized, pathologica l “fea tu r e” of the IMB Ping-Pong b enc hmark and 18 G. Hager, H. Stengel, T. Zeiser, G. W ellein hav e shown a possible s olution for making it mor e meaningful for rea l appli- cations. RZBENCH, the integrated b enc hmark suite which has b een develop e d by RRZE, was then used to compar e se rial and pa rallel applicatio n p erformance on HLRB2, a W o odcr est IB c lus t er a nd a Co nroe IB cluster with only one so c ket p er no de. The IA64 architecture shows s up erior p erformance for most co des on a one-cor e a nd one-so c ket basis but is on par with the commo dit y clusters for para llel runs. It could b e shown that the extra inv estment in net- work ha rdw are for a sing le - sock et commo dit y cluster can pay o ff for c e rtain applications due to improv ed bisection and agg regated memory bandwidth. Sun’s new UltraSP ARC T2 pro c essor could be demonstrated to display very comp etit ive p erformance levels if applications can s u sta in a muc h mo r e mas- sive parallelis m than on standar d s ystems. W e ar e indebted to Sun Microsystems a nd R WTH Aachen Computing Cent r e fo r g ran ting a ccess to a pre-pro duction Ultra SP ARC T2 system. References 1. http://www.c s.virginia.edu/stream/ 2. Sun Microsystems: Op enSP ARC T 2 Cor e Mi c r o ar chite ctur e Sp e cific ation. http: //openspar c- t2.sunsource.net/s p ec s/OpenSPARCT2_C ore_Micro_Arch.pdf 3. Sun Microsystems, priv ate comm un ication. 4. J. T reibig and G. Hager: Why i s p erformanc e pr o ductivity p o or on mo dern ar chite ctur es? T alk with Jan T reibig at the Dagstuhl Seminar on Petacom- puting, F eb 13 –17, 2006, Dagstuhl, German y . http:/ /kathrin.dagstuhl .de/ files/Mate rials/06/06071/0 6 071.TreibigJan.Slides.pdf 5. Standard Performa nce Ev aluation Corp oration, http://www.spec.or g 6. The NAS parallel b enchmarks, published b y the NAS A Adv anced Sup ercomput- ing Division, http://www.nas.n asa.gov/Resources/Software/npb.html 7. W. Sch¨ onauer: Sci entific Sup er c omputing: A r chite ctur e and Use of Shar e d and Distribute d Memory Par al lel Computers. Self-edition, Karlsruhe (2000), http: //www.rz.u ni- karlsruhe.de/ ~ rx03/book 8. F. Deserno, G. H ager, F. Brech tefeld, and G. W ellein, in S . W agner et al. (Eds.): High Perf ormance Computing in Science and Engineering Munic h 2004, pp . 3– 25, Springer 2005. 9. http://www.l rz- muenchen.de/services/compute/hlrb/batch/batch.html 10. http://www.volt aire.com/Products/Grid_Backbone_Switches/Voltaire_ Grid_Direc tor_ISR_9288 11. MPI Ping-Pong results fo r HPC Challenge can b e found at http://icl. cs. utk.edu/hp cc/hpcc_results_ l at_band.cgi
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment