RZBENCH: 최신 HPC 아키텍처 성능 평가와 벤치마크 교훈
RZBENCH는 FAU 연구자들의 실제 요구를 반영한 응용·저수준 벤치마크 모음이다. 공통 빌드·실행 인프라를 제공해 유지·확장이 용이하며, Itanium2 기반 HLRB‑II, InfiniBand Woodcrest·Conroe 클러스터, 그리고 Sun Niagara 2 서버 등 네 종류의 시스템에서 상세 성능을 측정한다. 메모리 대역폭·캐시 일관성, OpenMP 정렬 문제 등 저수준 코드가 시스템 특성에 크게 좌우됨을 보여준다.
저자: Georg Hager, Holger Stengel, Thomas Zeiser
본 논문은 독일 에라헨 대학교(FAU) 연구자들의 실제 요구를 반영한 벤치마크 모음인 RZBENCH를 소개하고, 이를 이용해 최신 HPC 아키텍처 네 종류의 성능을 정밀히 평가한다. RZBENCH는 응용 프로그램 중심의 벤치마크와 저수준 메모리·연산 테스트를 하나의 빌드·실행 프레임워크에 통합하였다. 공통 Makefile은 컴파일러, 라이브러리 경로, 스레드·프로세스 수 등을 일관되게 지정하도록 하며, 실행 후에는 “raw”와 “cooked” 두 형태의 결과 파일을 생성한다. “cooked” 데이터는 자동 스크립트로 후처리·시각화가 가능하도록 설계돼, 다양한 시스템 간 비교를 용이하게 만든다.
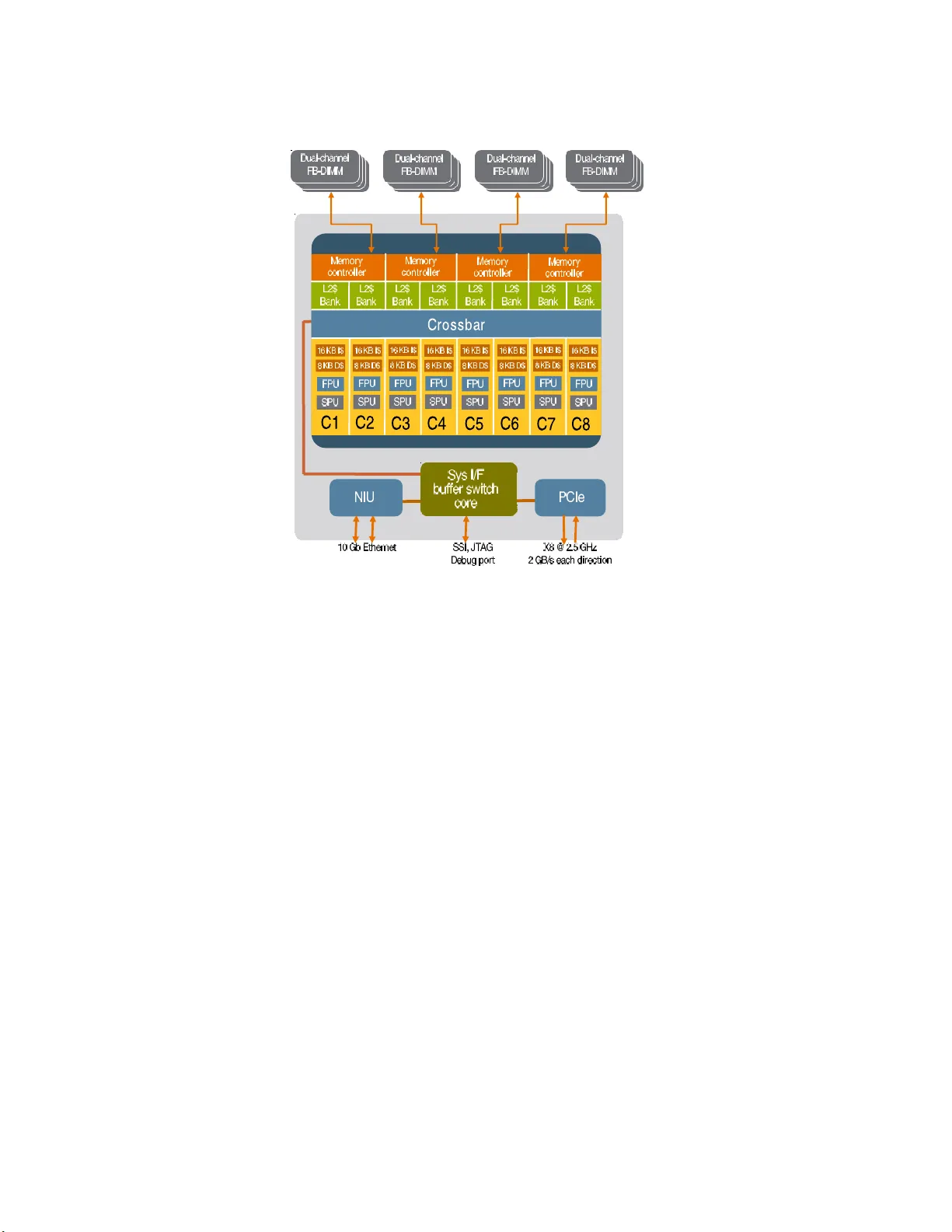
벤치마크 대상 시스템은 다음과 같다. (1) SGI Altix 4700에 탑재된 Itanium2 기반 HLRB‑II(1.6 GHz, 9 MB L3) – NUMALink4 네트워크가 고대역폭·저레턴시를 제공하지만, 노드당 메모리 채널이 제한돼 실제 비대칭 대역폭이 발생한다. (2) Woodcrest 클러스터 – Intel Xeon 5160 듀얼코어(3.0 GHz)와 DDR InfiniBand 스위치를 사용해 이론적 20 GB/s IB 대역폭을 충분히 활용하지만, 1단계 DDR·2단계 SDR 스위치 구조로 인해 다중 스위치 경유 시 성능 저하가 관찰된다. (3) Conroe 클러스터 – Intel Core2 듀얼코어(2.66 GHz)와 단일 FSB 1333을 사용해 메모리 대역폭이 절반으로 감소하지만, 캐시 일관성 트래픽 감소와 언버퍼드 DIMM 사용으로 실제 메모리 대역폭은 TRIAD 테스트에서 오히려 향상된다. (4) Sun UltraSPARC T2(Niagara 2) 서버 – 8개의 저클럭(1.4 GHz) 인‑오더 코어가 4개의 메모리 컨트롤러와 8개의 L2 뱅크를 공유한다. 전체 메모리 대역폭은 42 GB/s(read)·21 GB/s(write)로 매우 높지만, 코어당 연산 성능이 낮아 멀티스레드 활용이 필수적이다.
저수준 벤치마크로는 Fortran 기반 TRIAD와 Intel MPI Bench(IMB) “PingPong”을 사용했다. TRIAD는 4벡터 곱셈-덧셈 연산으로 메모리 대역폭 한계를 측정한다. 테스트 결과, 대부분의 시스템에서 메모리 대역폭이 실제 성능을 제한했으며, 특히 Sun T2에서는 OpenMP 정적 스케줄링 시 배열 정렬이 성능에 큰 영향을 미쳤다. 4 KB 경계 정렬 후 128워드(≈512 byte) 오프셋을 적용하면 메모리 컨트롤러와 L2 뱅크에 부하가 고르게 분산돼, 정렬이 맞지 않을 때보다 4배 이상 높은 MFlops를 기록했다. 이는 T2 아키텍처가 주소 비트(8,7)로 메모리 컨트롤러를, 비트 6으로 L2 뱅크를 선택하기 때문에 발생한다.
IMB 테스트에서는 인터커넥트 대역폭과 레이턴시를 측정했다. Woodcrest·Conroe 클러스터는 DDR IB 스위치 특성상 메시지 크기에 따라 70~75%의 이론적 대역폭을 달성했으며, 레이턴시도 수 마이크로초 수준으로 양호했다. 반면 SGI Altix에서는 기본 IMB 구현이 공유 메모리 노드 구조를 고려하지 않아 비정상적으로 낮은 대역폭을 보였지만, 메모리 공유를 고려한 수정 버전(mod)에서는 기대치에 부합하는 결과를 얻었다. 이는 벤치마크 도구 자체가 하드웨어 특성을 정확히 반영하도록 튜닝될 필요성을 강조한다.
논문은 또한 표준 벤치마크(SPEC, NPB)와 비교해 RZBENCH가 실제 사용자 워크로드에 더 적합함을 주장한다. 표준 벤치마크는 컴파일러 최적화와 특정 코드 패턴에 맞춰 성능을 끌어올리는 경우가 많아, 실제 과학 응용 프로그램에서 기대되는 성능과 차이가 발생한다. RZBENCH는 FAU 연구자들이 실제 사용 중인 코드와 입력을 기반으로 설계돼, 보다 현실적인 성능 지표를 제공한다.
결론적으로, RZBENCH는 다양한 HPC 시스템의 메모리·캐시·인터커넥트 특성을 정밀히 드러내며, 특히 메모리 대역폭과 배열 정렬, 캐시 일관성 트래픽이 성능에 미치는 영향을 상세히 분석한다. 이러한 결과는 시스템 설계자와 사용자 모두에게 하드웨어 선택·튜닝, 소프트웨어 최적화 전략을 수립하는 데 실질적인 가이드를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기