Distributions associated with general runs and patterns in hidden Markov models
This paper gives a method for computing distributions associated with patterns in the state sequence of a hidden Markov model, conditional on observing all or part of the observation sequence. Probabilities are computed for very general classes of pa…
Authors: ** (원문에 저자 정보가 제공되지 않았으므로, 논문에 명시된 저자명을 그대로 기재해 주세요.) **
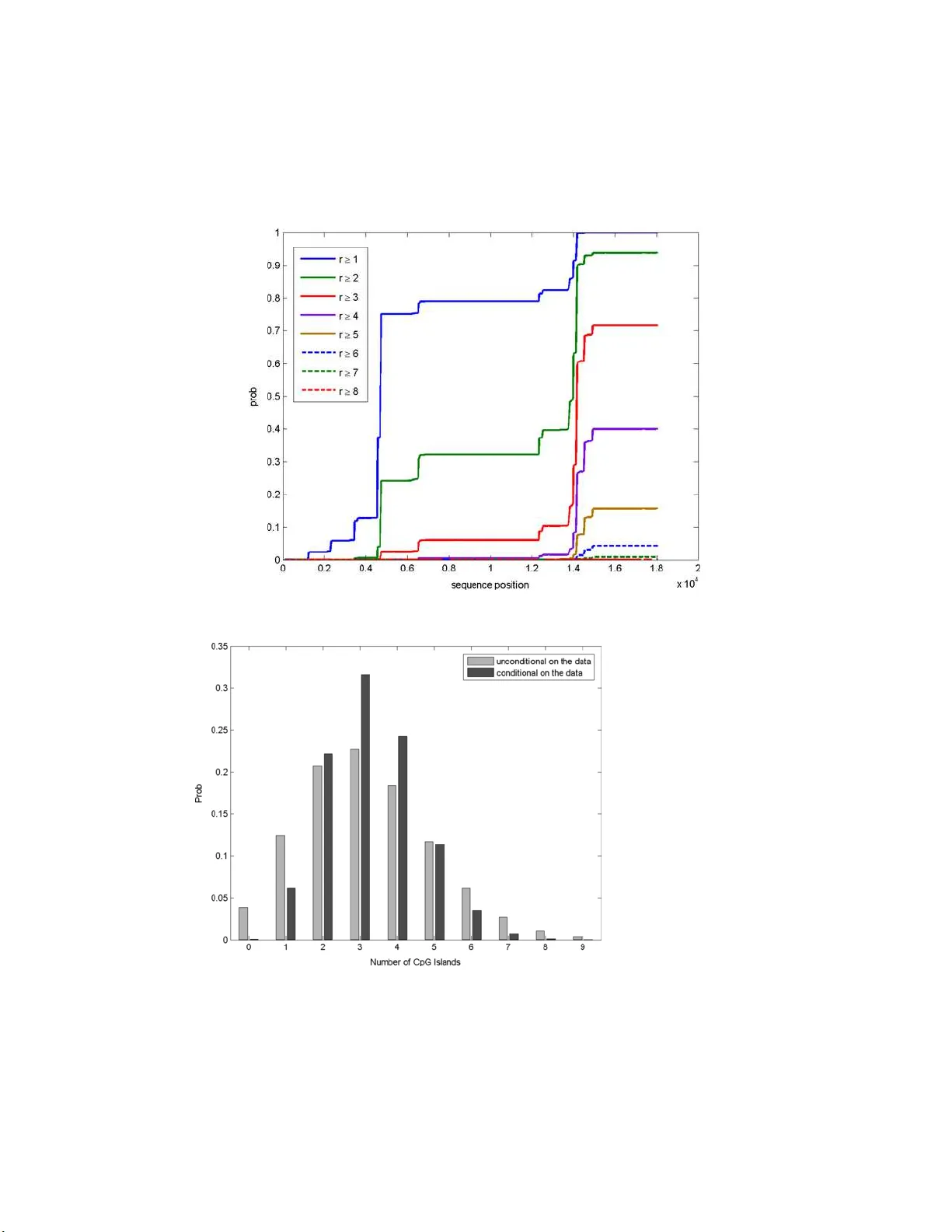
The Annals of Applie d Statistics 2007, V ol. 1, No. 2, 585–611 DOI: 10.1214 /07-A OAS125 c Institute of Mathematical Statistics , 2 007 DISTRIBUTIONS ASS OCIA TED WITH GENERAL R UNS AND P A TTERNS IN HIDDEN MARK O V MODELS By John A. D. Aston and Donald E. K. Mar tin A c ademia Sinic a , and Unite d States Census Bu r e au , Howar d University and North Car olina State U niversity This pap er giv es a method for comput in g distributions associated with patterns in the state sequence of a hidden Mark ov mod el, con- ditional on observing all or part of th e observ ation sequ en ce. Proba- bilities are computed for very general classes of patterns (comp eting patterns and generalized later patterns), and thus, th e theory in- cludes as sp ecial cases results for a large class of problems that hav e wide application. The unobserved state sequ ence is assumed to b e Mark o v ian with a general order of d ep endence. A n auxiliary Marko v chai n is associated with the state sequ ence and is used to simplify the computations. Two examp les are given to illustrate t he use of the metho dology . Wh ereas the first application is more to illustrate the b asic steps in app lying the theory , the second is a more detailed application to DNA sequences, and sho ws th at the metho ds can b e adapted to include restrictions related to biological k nowl edge. 1. In tro d uction. Hidden Mark ov mo d els (HMMs) provide a ric h structur e for u s e in a wid e range of statistical applications. As examples, they serve as mo dels in sp eec h recognition [ Rabiner ( 1989 )], image p ro cessing [ Li and Gray ( 2000 )], DNA sequence analysis [ Durbin , Edd y , Krogh and Mitc hison ( 1998 ) and Koski ( 2001 )], DNA microarra y time course analysis [ Y uan and Kendziorski ( 2006 )] and econometrics [ Hamilton ( 1989 ) and Sims and Zha ( 2006 )], to name ju st a few. HMMs essentia lly sp ecify tw o structures, an underlying mo del for the unobserved state of the system, and one for the observ ations, conditional on the unobserved states. Thus, HMMs are a sub -class of state space mo dels [ Harv ey ( 1989 )], b ut ha ve the restriction th at the m o dels for the h idden states are defined on finite dimen sional spaces. Received January 2007; revised June 2007. Supplementary material av ailable at http://imstat.org/a oas/supplements Key wor ds and phr ases. Competin g patterns, CpG islands, finite Marko v chain imbed- ding, generalized later p atterns, higher-order hidden Marko v mo dels, so oner/later w aiting time distributions. This is a n electronic r eprint of the original article publishe d by the Institute of Mathematical Statistics in The Annals of Applie d Statistics , 2007, V ol. 1 , No. 2 , 585– 611 . This reprint differs fr o m the or iginal in pag ination and typogra phic detail. 1 2 J. A. D . AS TON AND D. E. K. MAR TIN HMMs h a ve b een studied extensiv ely , esp ecially for the case where the hidden sequence is fi rst-order Mark ovia n (a Marko v c h ain); see, for example, Rabiner ( 1989 ). Higher-order HMMs are less frequen tly used, but are gain- ing in p opularit y , esp ecially in areas such as bioinformatics [ Krogh ( 1997 ) and Ching, Ng and F ung ( 2003 )]. F or practical purp oses, th ree fu n dament al problems asso ciated with fir s t-order HMMs hav e b een examined thoroughly and solv ed [ Rabiner ( 1989 )]: (1) the efficien t computation of the lik eliho o d of the sequ en ce of observ ations giv en the HMM [ Baum and Eagon ( 1967 )]; (2) the determination of a b est sequence of under lyin g states to maximize the lik eliho o d of the observ ation sequence [ Viterbi ( 1967 )]; an d (3) the ad- justment of mo del parameters to maximize the likeli ho o d of th e observ ations [the Baum–W elc h algorithm; see Baum and Eagon ( 1967 )]. Ho we v er, little is kno wn ab out probabilities for patterns or collections of patterns (also kn o wn as wo rds or motifs, resp.) in heterogeneous sequences suc h as those of HMMs [ Reinert, Sch bath and W aterman ( 2005 )]. In th is pap er a fourth p roblem that is b ecoming in creasingly more imp ortant for applications su c h as b ioinformatics an d data minin g is considered: th e pr ob - abilit y that a pattern has o ccurred or w ill o ccur in the hid den state sequence of an HMM. Currently , inference on p atterns in the hidd en state sequ en ce of an HMM usually pro ceeds as follo ws. The HMM is determined and the Viterbi algo- rithm is used to find th e most probab le state sequence among all p ossible ones, conditional on the observ ations. Th is state sequence is then treated as if it is “deterministically correct” and p atterns are found by examining it. Ho we v er, the conditional distrib u tion (giv en the observ ations) of p atterns o ve r all state sequen ces is more relev an t. If, for example, the num b er of genes present in a DNA sequence is of in terest and the Viterbi s equence of an HMM is used [as in m etho ds based on Krogh, Mian and Haussler ( 1994 )], then coun ting genes from the Viterbi sequence cannot b e guarantee d to ev en giv e a go o d estimate of the num b er of genes. Th is is b ecause there could b e gene coun ts that corresp ond to many state s equ ences, and w h en accumulat- ing probabilities o ve r those sequences, one could find th at those coun ts are m u c h more lik ely than the count corresp onding to the Viterbi sequen ce. This could esp ecially b e true if there are man y differen t sequ en ces all with likeli - ho o d close to that of the Viterbi sequen ce. If a sin gle c hoice of gene coun t is needed, then the mean of the conditional distribu tion o ver state sequences, giv en the observ ations, w ould seem to b e a more reasonable c h oice. Thus, a metho d to compu te pattern distrib u tions in s tate sequences mo d eled as HMMs would b e helpf ul. In this p ap er a compu tational metho d for fi nding suc h pattern distribu- tions is dev elop ed, and wa iting time probab ilities for patterns under the gen- eral framew ork giv en in Aston and Martin ( 2005 ) are extended to the state sequence of HMMs. Th e probab ilities are computed under the parad igm DISTRIBUTION S FOR HMM P A TTERNS 3 that T observ ations of the outpu t sequence of the HMM ha ve b een realized, and the generation p ro cess is either complete or set to con tin ue. W aiting time probabilities are then computed for patterns in the unobser ved state sequence up to a time T ∗ ≥ T . Note that w aiting time p robabilities for p at- terns in the observ ations of an HMM when n o data has yet b een observe d (i.e., T = 0), a case that relates directly to computations in th e standard case of Marko vian sequences with no “hidd en ” states, wa s d ealt with in Cheung ( 2004 ). The metho dology of this pap er will b e applied to t wo examples, but one application will b e stu died in detail, that of CpG Island analysis in DNA sequences. A CpG island is a short segmen t of DNA in whic h th e frequ ency of CG pairs is higher than in other r egions. The “ p ” in dicates that C and G are connected b y a phospho d iester b ond. The C in a CG pair is often mo dified b y methyla tion, and if that h app en s , there is a relativ ely high c h ance that it will m u tate to a T , and thus, CG pairs are und er-represent ed in DNA sequences. Upstream fr om a gene, the meth ylation pr o cess is sup p ressed in a short region of length 100–5,00 0 n ucleotides, kn o wn as CpG islands [ Bird ( 1987 )]. The un derlying nucleotide generating sequence can b e mo deled as t wo different sy s tems, one for when the sequence is in a CpG island, and one for when it is not. As CpG islands can b e esp ecially u seful for identifying genes in human DNA [ T ak ai and Jones ( 2002 )], different metho d s ha v e b een d evelo p ed for their detection. Tw o distinct metho ds for CpG island analysis are com- mon. First, a win do wed segmen t of the DNA sequence is taken and the n u m b er of CG p airs within it is coun ted. If the frequency of CG p airs is higher than some p redetermined threshold, then the segmen t is defined to b e within a CpG island [ T ak ai and Jones ( 2002 )]. P opu lar softw are suc h as CpG Island S earc her [ T ak ai and Jones ( 2003 )] pr o ceeds along these lines. Ho we v er, these t yp es of metho ds hav e b een criticized du e to the need f or the predetermination of thresholds and the v ariabilit y in the results that arise dep end ing on th e c hoice [ Durbin, Eddy , Krogh and Mitc hison ( 1998 ) and Saxono v, Berg and Brutlag ( 2006 )]. A second metho d of determinin g islands, wh ic h ov ercomes the n eed f or thresholds, is to use HMMs for the analysis [ Durbin, Edd y , Krogh and Mitc hison ( 1998 )]. Softw are is readily av ailable to imp lemen t these HMM-based meth- o ds for CpG island analysis, f or example, Gu ´ eguen ( 2005 ). The Viterbi al- gorithm is used to segment the sequ ence and analysis then pro ceeds as in- dicated ab o ve using the “deterministic” Viterbi sequence. Ho wev er, it will b e sho w n that by computing other d istributions s uc h as the d istribution of the num b er of CpG islands and the distribution of CpG island lengths, ad - ditional biologicall y useful information may b e obtained. Sp ecific examples will also b e giv en to illustrate that the num b er of CpG islands found by the Viterbi algorithm do es not n ecessarily repr esent th e most pr ob ab le num b er 4 J. A. D . AS TON AND D. E. K. MAR TIN in sets of h u man DNA data, and that the length of the islands found by the Viterbi algorithm can b e significant ly longer than exp ected. The pap er is organized as f ollo ws. I n the n ext section some bac kgrou n d material on hidden Mark o v mo d els is giv en, includin g theorems establishing the forwa rd and b ac kwa rd algorithms in the general m th ord er case anal- ogous to those when m = 1. Also included in the section is information on the types of p atterns that the theory co ve rs, the counting tec h niques that ma y b e used, and the metho dology that is used to compute probabilities. In Section 3 the results of the pap er are giv en, n amely , the lemmas and theo- rems required to calculate d istributions asso ciated with patterns in the s tate sequence of an HMM. Section 4 con tains tw o examples. A simple application to geological data is u sed to demonstr ate the ideas, and then the analysis of the system just discussed , that of CpG islands in DNA sequences, is un- dertak en. It will b e shown th at a v ariet y of distrib utions of in terest ma y b e calculated, including d istributions un der biological constraints such as minim um island lengths and minimal separation b etw een islands. S ection 5 is a d iscussion. 2. Notatio n and p reliminaries. 2.1. H idden Markov mo dels. Let { Y t } T t =1 b e th e observ ations of a higher- order HMM, generated from an underlying unobserv ed state sequence { X t } T ∗ t = − m +1 that is assum ed to b e a Mark ovia n sequence of a general order m . (F requen tly sequences will b e denoted u sing {·} notation without giving the sp ecific index set, e.g., { Y t } and { X t } for the observ ation and state se- quences ab o ve, n ot to b e confu s ed with generic sequence v alues Y t and X t .) While there are observ ations Y 1 , . . . , Y T to index T (that is u sually r eferred to as “time” in this pap er, bu t could simp ly b e the sequence index), it is as- sumed that the system is set to contin ue un til a time T ∗ ≥ T , allo w ing f or the consideration of systems where only partial observ ation sequ en ces ha ve b een realized. The states X − m +1 , . . . , X 0 are defined to allo w the initializatio n of the sys tem. Denote the state space of { X t } as S X , and similarly , let S Y b e th e state space of the observ ation sequence. S Y is assumed to b e fin ite for simp licit y , although this assumption m a y b e relaxed w ithout causing m uc h difficult y . The initial distribution of the state sequence { X t } is denoted b y π ( X − m +1 , . . . , X 0 ) , (1) and the time-homogeneous trans ition probabilities are denoted by p ( X t | X t − m , . . . , X t − 1 ) . (2) An alternativ e s etup is to place the initial distribu tion on X 1 , . . . , X m , wh ic h will lead to analogous results if n ot identica l ones. DISTRIBUTION S FOR HMM P A TTERNS 5 Also denote the observ ation p robabilities, conditioned on the state X t , b y γ t ( Y t | X t ), t = 1 , . . . , T . The assumption is made that, conditional on X − m +1 , . . . , X T ∗ , the Y t ’s are ind ep endent, and that the co n ditional dis- tribution of eac h Y t giv en X − m +1 , . . . , X T ∗ dep end s only on X t . These as- sumptions were tak en as fundamenta l to HMMs in MacDonald and Zucc h in i ( 1997 ) with T ∗ = T , that is, th e latter authors were only concerned with times up to time T and n ot T ∗ . The assumptions imply that the Y t ’s are indep en den t give n X − m +1 , . . . , X T as w ell. In an HMM of ord er m , conditional pr obabilities for the h idden state X t giv en X t − m , . . . , X t − 1 are indep enden t of the m ore distan t past. Usually the assumption that m = 1 is made, ho w ever, in this pap er, m m ay take on general p ositiv e in teger v alues. Rabiner ( 1989 ) considered HMMs as b oth a generator of the ob s erv ations, and as a mo d el for ho w a giv en observ ation sequence Y ( T ) w as generated by an appropr iate HMM. It sh ou ld b e n oted that taking either the MacDonald and Zucc h in i ( 1997 ) or Rabiner ( 1989 ) viewp oints to wa r d HMMs leads to computationally iden tical answ ers. The f orw ard and backw ard algorithms [ Baum and E agon ( 1967 )] are h elp- ful for computing pr ob ab ilities asso ciated with the HMM. Th ese algorithms are well kno wn for the first-order HMM case; here versions are stated for general ord ers of d ep enden ce. While it is true that a higher-order HMM ma y b e p osed as a first-order HMM, the forw ard and b ac kward algorithms that follo w can b e more efficien t if the higher-order mo del is used. The pr o ofs of these algorithms follo w in a straigh tforward manner from the pro ofs of the original f orward and bac kw ard algorithms and are therefore omitted. F or notational p urp oses, let Y ( j ) ≡ Y 1 , . . . , Y j , j ≥ 1, X ( l ) ≡ X − m +1 , . . . , X l , l ≥ ( − m + 1) and ˜ X t ≡ ( X t − m +1 , . . . , X t ), t = 0 , 1 , . . . , T ∗ . No w defin e the “forw ard ” v ariables b y α 0 ( ˜ X 0 ) ≡ π ( ˜ X 0 ), and α t ( ˜ X t ) ≡ P ( Y ( t ) , ˜ X t ) , t = 1 , . . . , T . (3) Theorem 2.1. F or an m th or der HM M, the forwar d variables may b e c ompute d r e cursively, and the pr ob ability of the observation se quenc e Y ( T ) may b e c ompute d fr om them, using the fol lowing: (i) Initializa tion: α 0 ( ˜ X 0 ) = π ( ˜ X 0 ) . (4) (ii) R e cursion: F or t = 1 , . . . , T , α t ( ˜ X t ) = X X t − m α t − 1 ( ˜ X t − 1 ) p ( X t | ˜ X t − 1 ) γ t ( Y t | X t ) . (5) (iii) T erminat ion: P ( Y ( T ) ) = X ˜ X T α T ( ˜ X T ) . (6) 6 J. A. D . AS TON AND D. E. K. MAR TIN Also defin e the “bac k ward” v ariables by β T ( ˜ X T ) = 1 for all ˜ X T , and β t ( ˜ X t ) ≡ P ( Y t +1 , . . . , Y T | ˜ X t ) , 0 ≤ t ≤ T − 1 . (7) Theorem 2.2. F or an m th or der HMM , the b ackwar d variables may b e c ompute d r e cursively usi ng the fol lowing: (i) Initializa tion: β T ( ˜ X T ) = 1 for al l ˜ X T . (8) (ii) R e cursion: F or t = T − 1 , T − 2 , . . . , 1 , 0 , β t ( ˜ X t ) = X X t +1 p ( X t +1 | ˜ X t ) γ t +1 ( Y t +1 | X t +1 ) β t +1 ( ˜ X t +1 ) . (9) 2.2. N otation for p atterns. A simple p attern Λ i refers to a sp ecified se- quence of symb ols of S X , wh ere the symb ols are allo we d to b e rep eated. A c omp ound p attern Λ is the u nion of simple patterns, that is, Λ = S η i =1 Λ i , where the lengths of the simp le patterns, Λ i ma y v ary , Λ a ∪ Λ b denotes the o ccurrence of pattern Λ a or pattern Λ b , and th e in teger η ≥ 1. Consider now a system Λ (1) , . . . , Λ ( c ) of c comp ound patterns, c ≥ 1 , with corresp onding n um b ers r 1 , . . . , r c , wh ere r j denotes the requ ir ed n um - b er of occurr ences of comp ound pattern Λ ( j ) . If th e wai ting time of in - terest is the time until the first o ccurrence of one of the comp ound pat- terns its sp ecified num b er of times, Λ (1) , . . . , Λ ( c ) are called c omp eting p at- terns [ Aston and Martin ( 2005 )]. If all of the patterns m ust o ccur their sp ecified num b er of times, th e system is called gener alize d later p atterns [ Martin and Aston ( 2007 )]. When c = 1, resu lts for comp eting and generalized later p atterns redu ce to those for comp ound patterns. On the other hand, if r j = 1 for all j and , in addition, eac h of th e comp eting or generalized later patterns consists of ju s t one sim p le pattern, then the resp ectiv e waiti ng time distributions reduce to so oner and later waiting time distributions as defined in th e literature; f or example, see Balakrishnan and Koutras ( 2002 ). A sp ecial s imple pattern is a run o f length k , where r un is us ed in a lo ose sense that includes consecutive o ccurrences of any pattern such as a single sym b ol or alternating symb ols, as in examples of S ection 4 , wh en the length distribu tion of the longest run is consid er ed . A run of length k w ill b e denoted by Λ( k ) and its waiting time by W (Λ( k )) , where the t yp e of run will b e un dersto o d by the con text. 2.3. M etho ds of c ounting. Two distinct metho ds of coun ting p atterns are p ossible, though muc h of the implemen tation will n ot change d r amat- ically b etw een the t wo cases. T he fi rst metho d is that of nonoverlap ping DISTRIBUTION S FOR HMM P A TTERNS 7 coun ting. With that metho d , when a pattern o ccurs, the counting p ro cess re-starts from that p oint, and an y p artially completed pattern cannot b e finished. Nono ve rlapping counting can b e system w ide (S WNO), or it can b e r estricted to within comp ound patterns (WPNO), wh ere counting only starts o ver for sim p le p atterns within the same comp ound p attern as the one th at has just o ccurred [ Aston and Martin ( 2005 )]. The second coun ting metho d is that of overlapping count ing, where p artially completed patterns ma y b e finished at an y time, r egardless of w hether another pattern has b een completed after the p artially completed pattern starts b u t b efore it is com- pleted. T o illustrate, let Λ (1) = Λ(5) = 11111 and Λ (2) = 1011 ∪ 00. F or th e real- ization ( X 1 , . . . , X 15 ) = 011 01111 1101 100 , (10) using SWNO count ing, there are t w o o ccur r ences of 1011 and one of 00 (and th u s, three o ccurr ences of Λ (2) ), bu t no o ccurrences of Λ (1) are coun ted. Although there are six consecutive ones in the realization, only four of them o ccur after th e fir s t completion of 1011 (whic h re-starts coun ting), and thus, 11111 is n ot counted. With WPNO counting, in add ition to the o ccur r ences men tioned ab ov e, Λ (1) is coun ted once, since no w the firs t o ccurrence of 1011 do esn’t cause a re-starting of counting for 11111, wh ic h is in a different comp ound pattern. Finally , with o v erlappin g coun ting, Λ (1) o ccurs twice (the t wo o verlapping o ccurr ences of 11111), in addition to th e three o ccurrences of Λ (2) . 2.4. M etho d of c omputation . Th e use of an auxiliary Mark o v pro cess to aid with the computation of probabilities has b een used for more than fi ft y y ears. As an example, Co x ( 195 5 ) used supp lemen tary v ariables to obtain a Mark o v p ro cess that s im p lified th e computation of wai ting time probabili- ties, and noted that the u se of su pplementa ry v ariables in that manner was a w ell-known tec hn ique at the time. In a recen t pap er concerning Mark o v Mo dulated P oisson Pro cesses [ Hw ang, Choi an d Kim ( 2002 )], wa iting time distributions w ere computed in a s imilar manner. F u and K outras ( 1994 ) used auxiliary Mark o v chains, and develo p ed an elegan t f ramew ork [call- ing it Finite Markov Chain Imb e dding (FMCI)] for h andling distrib utions asso ciated w ith run s and p atterns in d iscrete time Mark o v p ro cesses. In the FMCI metho d , a Marko v c hain { Z t } is dev elop ed such that th er e is a one-to-one corresp ondence b et ween classes of its states and th ose of { X t } . The Marko v chain { Z t } facilitates the computation of waiting time distri- butions for patterns, since an absorbing state for { Z t } can b e defined to corresp ond to the o ccurrence of the p attern of interest. T he desired p roba- bilit y ma y then b e compu ted by determin in g the pr obabilit y that { Z t } lies in the corresp ond ing abs orbing state, which is compu ted using basic p rop erties 8 J. A. D . AS TON AND D. E. K. MAR TIN of Mark ov c hains. Aston and Martin ( 2005 ) and Martin and Aston ( 2007 ) used the FMCI approac h to compute wait ing time distribu tions for comp et- ing and generalized later patterns, resp ectiv ely , in higher-order Marko v ian sequences, and that metho d is also used in this pap er. As is the case when conv erting an m th order Mark o vian sequence into a first- order one through the use of m -tuples, the m -tuple X t − m +1 , . . . , X t m u st b e a part of the state of Z t . T o deal with comp eting and generalized later patterns in general, inform ation on the n u m b er of comp ound p attern o ccurrences to date and current p rogress in to the simple patterns of the system must also b e p art of the state of Z t , so that probabilities for Z t +1 ma y b e determined based only on Z t , and n ot on earlier time p oints. Once the state sp ace S Z of { Z t } is determin ed , ent ries of the asso ciated transition pr obabilit y matrix are determined by fir s t noting the p ossible transitions for { X t } (and the implied transitions for { Z t } ), and then as- signing the appropr iate transition probabilities. T h e in itial distribu tion as- so ciated with Z 0 is d etermined by mapping m -tuples ( x − m +1 , . . . , x 0 ) in to corresp ondin g Z 0 v alues, and then assigning the corresp onding pr obabili- ties π ( X − m +1 , . . . , X 0 ). All other initial s tates will h av e pr obabilit y zero. The formation of the state space S Z and the determination of its transition probabilit y matrix and initial distribution will b e illustrated in the examples. In the next s ection it is shown th at the results of the latter t wo refer- ences ma y b e extend ed to d eriv e d istributions asso ciated with patterns in the state sequence of an HMM. Th e f u ndamenta l difference b etw een d istr i- butional problems dealt w ith in this pap er an d those for regular Mark ovia n sequences is that in the pr esen t setup the observ ed data up to time T must b e accoun ted for, whereas regular Mark o vian sequences are equiv alen t to the HMM case where no observ ed data is a v ailable ( T = 0). 3. Distributions asso ciated with patterns in HMM states. In this section results on distributions asso ciated with pattern occurren ces in the state sequence of an HMM of a general order are presen ted. T o apply the metho ds describ ed ab ov e to the un derlying state sequence { X t } of an HMM, it is necessary to kno w the transition probabilities of { X t } conditional on the observ ed v alues Y ( T ) . These probabilities are giv en by the follo wing lemma. A theorem giving a form u la for computing the waiti ng time probabilities th en follo w s, along with resu lts that may b e obtained fr om that theorem. Lemma 3.1. F or an m th or der HMM , if 1 ≤ t ≤ T , then P ( X t | X ( t − 1) , Y ( T ) ) = β t ( ˜ X t ) β t − 1 ( ˜ X t − 1 ) p ( X t | ˜ X t − 1 ) γ t ( Y t | X t ) . (11) DISTRIBUTION S FOR HMM P A TTERNS 9 If T < t ≤ T ∗ , then P ( X t | X ( t − 1) , Y ( T ) ) = p ( X t | ˜ X t − 1 ) . (12) The sp ecial case of ( 11 ) with m = 1 was give n in Lindgren ( 1978 ), and the p ro of follo w s in a similar manner and is therefore omitted. Theorem 3.2 (W aiting time distribution for patterns in HMMs). Con- sider an m th or der H MM with state se quenc e { X t } T ∗ t = − m +1 and observation se quenc e { Y t } T t =1 . If { Z t } T ∗ t =0 is a Markov chain such that, c onditione d on Y ( T ) , the desir e d p attern has o c curr e d b y time t if and only i f Z t lies in a c orr esp onding absorbing state Γ ∈ S Z , then, c onditiona l on Y ( T ) , the wait- ing time distributions for c omp eting and gener alize d later p atterns may b e c ompute d thr ough { Z t } by the e quation P ( Z t = Γ) = ψ 0 t Y j =1 M j ! U (Γ) , (13) wher e M j is the tr ansition pr ob ability matrix for tr ansitions fr om Z j − 1 and Z j , ψ 0 is a r ow ve ctor holding the initial distribution of Z 0 , and U (Γ) is a c olumn ve ctor with a one i n the lo c ation c orr esp onding to absorbing state Γ , and zer os elsewher e. Pr oof. By assumption, the pattern of inte rest has occurr ed by time t if and only if Z t = Γ. Equation ( 13 ) then follo ws u sing the w ell-kno w n Chapman–Kolmogoro v equations. An equation similar to ( 13 ) is also u sed in the aforementio ned researc h that uses sup plemen tary v ariables to calculate wa iting time d istributions. The entries of the m atrices M t are b ased on trans itions for the underlyin g state sequence { X t } cond itioned on Y ( T ) , and th us are determined u s ing Lemma 3.1 . The d istribution of th e length of the longest run of symb ols may b e com- puted thr ough wa iting time probabilities. Th e relationship b et ween the p rob- abilit y mass f unction of R ( t ) , the length of the longest run that has o ccurred b y time t , and w aiting time p robabilities for runs is giv en b y P ( R ( t ) = k ) = P ( R ( t ) ≥ k ) − P ( R ( t ) ≥ k + 1) (14) = P ( W { Λ( k ) } ≤ t ) − P ( W { Λ( k + 1) } ≤ t ) . The distr ibution of the num b er of runs of length at least k ma y also b e computed remark ably easily through asso ciating Mark o v chains { Z ( i ) t } , i = 1 , . . . , r with eac h o ccurrence ( r b eing the maxim um num b er of o ccur rences 10 J. A. D . AS TON AND D. E. K. MAR TIN of in terest), and then usin g a renew al argum en t. An abs orbing state Γ is included in S Z to denote the o ccurrence of a run of length at least k . Also placed in S Z are “con tinuation” states ( s, → ) that ind icate that the ( i − 1)st o ccurrence of the run is still in progress in { Z ( i ) t } , where s den otes an m - tuple of the last m state v alues that either led to the o ccurrence o r to the conti n u ation of th e ru n (as with the absorbing state Γ, a common set of con tinuatio n states are used by the v arious c h ains { Z ( i ) t } , although the exact interpretatio n of all th e states in S Z dep end s on wh ic h c hain is b eing considered). Entries are added into the transition matrix M t corresp ondin g to transition probabilities from the con tinuation s tates into the other states. The conti n u ation states either transition to one of th e con tinuatio n states, whic h w ould indicate the run is still in progress, or to one of the other states in S Z when the run has en d ed. The probabilities for the con tin uation state transitions are determined in an ident ical w ay to the other tr an s ition probabilities in M t . No states in S Z transition into the con tin uation states other than the conti n u ation states th emselv es. O therwise, in this algorithm, there are no c hanges to M t . The first Mark o v chain { Z (1) t } follo ws the mo vemen ts of { Z t } up to the first o ccur r ence of a r u n of length k , and with that o ccurrence the c hain en ters state Γ. The chain is initialized through ψ 0 , with zero es ad d ed for the con tinuatio n states. Subsequ ent c hains { Z ( i ) t } , i = 2 , . . . , r , are initialized in the “con tinuatio n” states s in ce a pattern of length k has just o ccurred, and trac k the mo vemen ts of { Z t } b etw een the ( i − 1)st and i th r un o ccur r ences. Eac h c h ain en ters the absorb ing state once th e run of the d esired length o ccurs. In this algorithm, the 1 × | S Z | r ow v ector ψ t = ψ 0 ( Q t j =1 M j ) of ( 13 ), whic h giv es the pr obabilit y of the c hain lying in its v arious states at time t ≥ 1, is no w replaced by an r × | S Z | m atrix Ψ t ( | B | denotes the num b er of elemen ts of the set B ). The matrix elements Ψ t ( i, j ) giv e the join t probabilities of there having b een ( i − 1) ru n o ccurrences of length at least k , and the chain { Z ( i ) t } lying in state j . These p robabilities m ust b e increment ed at time t b y adding the probabilit y that the ( i − 1)st run o ccurs at that time. A t time t = 0, the first ro w of Ψ 0 consists of ψ 0 , with zero es add ed to account for the contin uation states, as mentioned ab o ve . Rows 2 , . . . , r , resp ectiv ely , corresp ondin g to the chains { Z ( i ) t } , i = 2 , . . . , r , consist of all zero es, since there is zero pr obabilit y that there has b een an o ccurren ce of a run of length k or longer at that time. The algorithm is giv en in the f ollo wing theorem. Theorem 3.3 (Num b er of run o ccurr en ces of at least a certain length in HMMs). F or an m th or der HM M and auxiliary Markov chain { Z t } T ∗ t =0 as in The or em 3.2 , let { Z ( i ) t } T ∗ t =0 b e the c orr e sp onding c hains that tr ack move- ments of { Z t } T ∗ t =0 b etwe e n the ( i − 1) st and i th run of length at le ast k . Then DISTRIBUTION S FOR HMM P A TTERNS 11 c onditiona l on Y ( T ) , the distribution of the nu mb er of runs of length at le ast k may b e c ompute d thr ough P ( Z ( i ) t ∈ Γ) = Ψ t ( i, · ) U (Γ) , (15) wher e Ψ t ( i, · ) is the i th r ow of Ψ t . In ( 15 ) , Ψ t (0 , · ) c onsists of ψ 0 app ende d with zer os for the c ontinuation states, and the entries for the other r ows of Ψ 0 ar e al l zer o. Also, Ψ t is c alculate d fr om the fol lowing iter ative scheme, for t = 1 , . . . , T ∗ : Ψ t = Ψ t − 1 M t (16) Ψ t ( i, ( s, → )) ← Ψ t ( i, ( s, → )) + Ψ t ( i − 1 , Γ) − Ψ t − 1 ( i − 1 , Γ) , (17) i = 2 , . . . , r , wher e ← denotes that the quantity on the right r eplac es that on the left. The theorem is similar to ( 13 ), but is mo d ified slightly . T h e justification for the algorithm ( 16 )–( 17 ) is as follo ws. E q u ation ( 16 ) is the standard m a- trix multiplicati on for eac h time step as in ( 13 ). Th e extra op eration ( 17 ) is inserted to incr ement the ro w pr obabilities, as mentio ned ab o ve , as the elemen ts of ro w i of Ψ t giv e the joint probabilit y of there ha ving b een ( i − 1) o ccurrences with th e chain lying in the v arious states. With this setup, the probabilit y of b eing in the absorbin g state of Z ( i ) t equals the probabilit y of at least i o ccur rences having tak en place. Once the system is ev aluated for all t up to T ∗ , th e v alues in the column of Ψ T ∗ corresp ondin g to the absorbing state Γ giv e the probabilities of the pattern ha vin g o ccurred at least 1 , . . . , r times b y time T ∗ . More d etails on the d eriv ation of the algorithm are giv en in the App end ix . Theorem 3.3 ma y b e mo dified to allo w for general num b ers of o ccurrences of runs to b e counted wh en usin g o v erlappin g or n ono verlapping counting (for length exactly k rather than length at least k ) in a similar manner. The con tinuatio n states would not b e n eeded in these cases, as th e initial states for the c h ains { Z ( i ) t } , i = 2 , . . . , r will already b e in S Z . As can b e seen, when r = 1, the iterativ e sc h eme of Theorem 3.3 is not needed. 4. Examples. In th is s ection t wo applications of the metho d ology out- lined in the last section are giv en. Th e first, to erup tions of the old faithful geyser, is a simple examp le giv en mainly to illustr ate v arious asp ects of the metho d, such as the c hoice of the auxiliary Marko v chain, the determination of its s tate s pace and the form ation of its transition pr obabilit y matrix. The second examp le is more substantiv e, dealing with the CpG island pr oblem that was discussed briefly in the In tro duction . 12 J. A. D . AS TON AND D. E. K. MAR TIN 4.1. O ld F aithful geyser. The durations of successiv e eru ptions from Au- gust 1 to August 15, 1985 of the Old F aithful geyser in Y ello wstone National P ark were presente d b y Azzalini and Bo wman ( 1990 ) an d analyzed using a second-order Mark o v chain. T he d urations w ere classified as either b eing short (0) or long (1 ) to give a binary time series of length T = 299. Ho wev er, what is observe d is not necessarily what is happ ening with the u nderlying system. Sp ecifically , there could b e a long eruption even th ough the state of the geyser is more in line with a sh ort eru ption. MacDonald and Zucc h in i ( 1997 ) extended th e mo del to a second-order HMM to mitigate the noise in the s ystem. Their mo del is used here to find d istributions of patterns in the underlying system. The state spaces are S X = S Y = { 0 , 1 } . The transition p robabilities for the hidden states { X t } are p (0 | 0 , 0) = p (0 | 1 , 0) = 0, p (0 | 0 , 1) = 0 . 717, p (0 | 1 , 1) = 0 . 414 and p (1 | x t − 1 , x t ) = 1 − p (0 | x t − 1 , x t ). The initial distr ibution is π (0 , 0) = 0, π (1 , 0) = π (0 , 1) = π (1 , 1) = 1 3 . The outpu t probabilities cond itioned on states are γ (0 | 0) = 0 . 928, γ (0 | 1) = 0, with γ (1 | x t ) = 1 − γ (0 | x t ). This is actually an example of a r ed uced second-order Mark o vian state sequence, as X t +1 = 1 wh enev er X t = 0, regardless of any v alues of previous states. This indicates that a short eruption state is alw ays follo w ed by a long one. It is only when the current state is 1 that X t − 1 is needed to determine probabilities for transitions to X t +1 . Th e initial distribution accoun ts for the fact that the state w here X − 1 = X 0 = 0 is not p ossible u nder the mo del. Tw o t y p es of p atterns in the erup tion pr o cess are typical; either there are runs in the und erlying state p ro cess of long eru ptions, or the sy s tem alternates b et w een the long and sh ort erup tion states. Little is kn o wn ab out wh y these p atterns o ccur other than that the short eruption state is alw ays follo w ed by the long one [ P erkin s ( 1997 )]. It is of interest to see ho w these pattern distribu tions mo deled through HMMs corresp ond to pattern distri- butions unconditional on data. Here, the alternating pattern is analyzed. The corresp onding comp ound pattern is Λ( k ) = k z }| { 0101 .. 01 ∪ k z }| { 1010 .. . 10 , where Λ( k ) denotes an alternating ru n of length exactly k , and k z}|{ · in dicates there are k s ym b ols under the brack et. The ab o ve formula r epresen ts the case w here k is ev en. If k we re o dd, th e next alternating s ym b ol would b e added to eac h of the t w o simple p atterns of Λ( k ), that is, the last symb ol w ould b e the same as the firs t. P r ogress in to the simple patterns can b e any of the follo wing (assuming that k is even): { 0 , 1 , 01 , 10 , 010 , 101 , . . . k − 1 z }| { 0101 .. 0 , k − 1 z }| { 1010 .. . 1 } . DISTRIBUTION S FOR HMM P A TTERNS 13 The s tates of S Z are defined as ordered vect or pairs, the fi rst element b eing the 2-tuple that gives the last tw o v alues of the { X t } sequence, and the second elemen t b eing the progress in to a pattern: (00 , 0) , (11 , 1) , (01 , 01) , (01 , 101) , (01 , 0101) , . . . , (01 , k − 1 z }| { 1010 .. 1 ) , (10 , 10) , (10 , 010) , (10 , 1010) , . . . , (10 , k − 1 z }| { 0101 .. 0 ) , Γ . The states (00 , ∅ ) , (01 , ∅ ) , (10 , ∅ ) , (11 , ∅ ) , (01 , 1) , (10 , 0) are also needed; the fi r st four as p ossible states for Z 0 , and th e latter t wo as p ossible v alues of Z 1 . Here ∅ denotes that there is no progress into a simple pattern of the system. These initializa tion states are needed f or times t < 2 since, for these v alues of t , some or all of the 2-tuple do es not count, rend ering pattern pr ogress differen t than for times t ≥ 2 . After time t = 1, the Marko v c hain can nev er r eturn to these states, and th u s, they are deleted from the state sp ace after th at time. The transition p robabilit y matrix for Z t is constructed us in g transition probabilities determin ed through Lemma 3.1 . The trans ition probabilities required are based on the transition pr ob ab ilities determined for the { X t } se- quence th rough the 2-tuple, while the en tire vec tor state from S Z determines the p ossible destination of the state. A few example transition prob ab ilities are listed b elo w , w ith the others determined in a similar manner: P ( Z t = (10 , i +1 z }| { 01 . . . 010) | Z t − 1 = (01 , i z }| { 01 . . . 01)) = P ( X t = 0 | X t − 2 = 0 , X t − 1 = 1 , Y ( T ) ) , i = 1 , . . . , k − 2 , P ( Z t = (11 , 1) | Z t − 1 = (01 , i z }| { 10 . . . 101)) = P ( X t = 1 | X t − 2 = 0 , X t − 1 = 1 , Y ( T ) ) , i = 1 , . . . , k − 1 , (18) P ( Z t = (10 , 10) | Z t − 1 = (11 , 1)) = P ( X t = 0 | X t − 2 = 1 , X t − 1 = 1 , Y ( T ) ) , P ( Z t = Γ | Z t − 1 = (10 , k − 1 z }| { 0101 . . . 0)) = P ( X t = 1 | X t − 2 = 1 , X t − 1 = 0 , Y ( T ) ) , P ( Z t = Γ | Z t − 1 = Γ) = 1 . 14 J. A. D . AS TON AND D. E. K. MAR TIN Using { Z t } , the waiti ng time probabilit y for an alternating sequence of length k can b e found through Theorem 3.2 and then using ( 14 ). The proba- bilit y mass function P ( R ( T ) = k ) f or alternating r uns of lengths k = 1 , . . . , 70 giv en all the data ( T = T ∗ = 299) is s h o wn in Figure 1 . Th is p lot indi- cates that, conditional on the observ ations, only ve ry sp ecific alternating run lengths are likely . Ind eed, as the probabilit y of t wo short eruption states follo wing one another is zero, the pattern is highly lik ely to start in state 1 and end in s tate 1, h en ce, the sp ecific lengths. Ho wev er, the cond itional distribution giv en the obser v ations is v ery differen t from the u nconditional distribution, sho wing that information from the observ ation sequ ence is ve ry useful for determining pr obabilities for p atterns in the und erlying states. 4.2. D NA se quenc e analysis—CpG islands. The use of HMMs to m o del DNA sequences with heterogenous segmen ts w as pioneered by Ch urc hill ( 1989 ), and sin ce that time their u se f or th at cause has increased. As men- tioned in the introd uction, HMMs ha ve b een sho w n to b e esp ecially suitable for the analysis of CpG islands. Define S X = { A + , C + , G + , T + , A − , C − , G − , T − } , where a sup erscript “+ ” indicates that the state is within a CpG island and “ − ” that it is not, and Fig. 1. Gr aph of the pr ob ability mass function of the length of the longest al ternating underlying short/long eruption states, b oth c onditional and unc onditional on the observa- tion se quenc e, for the Old F aithful geyser, Y el lowstone National Park, fr om August 1 to Aug ust 15, 1985. DISTRIBUTION S FOR HMM P A TTERNS 15 let S Y = { A, C, G, T } . The tr an s ition p robabilit y m atrix asso ciated with the state sequen ce { X t } is tak en to b e { p ( x i +1 | x i ) } (19) = A + C + G + T + A − C − G − T − 0 . 17635 0 . 26838 0 . 41719 0 . 11761 0 . 003721 4 0 . 00559 95 0 . 008635 4 0 . 002 5226 0 . 16737 0 . 36005 0 . 26811 0 . 18400 0 . 003538 1 0 . 00747 03 0 . 005594 0 0 . 003 8774 0 . 15775 0 . 33201 0 . 36726 0 . 12250 0 . 003341 7 0 . 00689 82 0 . 007616 5 0 . 002 6225 0 . 07746 8 0 . 34768 0 . 37607 0 . 17831 0 . 001703 4 0 . 00721 79 0 . 007797 3 0 . 003 7613 0 . 00042 47 0 . 000329 7 0 . 00040 87 0 . 0 00334 7 0 . 29953 0 . 20472 0 . 28456 0 . 20971 0 . 00044 66 0 . 000422 7 0 . 00020 19 0 . 0 00426 6 0 . 32148 0 . 29753 0 . 07796 9 0 . 30152 0 . 00030 18 0 . 000363 7 0 . 00041 67 0 . 0 00416 7 0 . 17677 0 . 23865 0 . 29154 0 . 29154 0 . 00037 27 0 . 000370 7 0 . 00042 27 0 . 0 00332 7 0 . 24763 0 . 24563 0 . 29753 0 . 20771 . This matrix is based on the transitio n probabilit y matrices giv en in Durbin, Eddy , Krogh and Mitc hison ( 1998 ), wh ic h w ere calculated usin g max- im u m lik eliho o d metho ds from human DNA with 48 putativ e CpG islands present (wh ic h w ere predetermined using other metho ds). If Q represents a generic nucleo tide, that is, Q ∈ { A, C , G, T } , then γ ( Q | Q − ) = γ ( Q | Q + ) = 1. Ev en though the observe d n ucleotide is totally deter- mined if the underlying state is kno w n , it is not p ossible to kno w w hether an observ ation came from a CpG island or not. Finally , d efine π ( A − ) = π ( C − ) = π ( G − ) = π ( T − ) = 1 4 , that is, th e u n derlying state sequence is equally lik ely to start in an y of the non- CpG island states. The patterns of in terest are sequ ences of + ’s, wh ic h indicate that th e system is currentl y in a CpG island (since + denotes A + ∪ C + ∪ G + ∪ T + ). This is slightl y differen t from the traditional definition of run s (consecutiv e o ccurrences of one symbol). Of interest will b e the d istr ibution of the length of CpG islands in a give n sequence of nucleo tides, and the distrib u tion of the num b er of CpG island s of length at least k , for sp ecified v alues of k . The state space for the auxiliary { Z t } c hain is giv en by [ Q ∈{ A,C,G, T } { ( Q + , +) , ( Q + , ++) , . . . , ( Q + , k − 1 z }| { + · · · +) , Q − } ∪ Γ , (20) where k is a sp ecified run length, ( Q + , i z }| { + · · · +) giv es the v alue of X t and th e current run of + ’s, and Γ is an absorbing state to indicate that k consecutiv e +’s hav e o ccurred. The desir ed run o ccurs by time t if and only if Z t = Γ, and th u s theorems from Section 3 may b e used to compute p robabilities. As it is assumed that the state sequence d o es not b egin in a CpG island state, no additional states are needed to initialize the c h ain. [T o r elax this assumption, the states S Q ∈{ A,C,G, T } { ( Q + , ∅ ) } w ould n eed to b e added as initializat ion states for Z 0 .] The HMM describ ed in this subsection was used to analyze several human genomic sequences. First, chromosome 20, lo cus AL133339 [ Barlo w ( 2005 )] 16 J. A. D . AS TON AND D. E. K. MAR TIN with 18,058 base pairs w as inv estigat ed (th u s, T = T ∗ = 18 , 058), that is, AL13333 9 is the observed sequence { Y t } . This sequen ce is kno wn to cont ain at least one example of a putativ e CpG island. Given that the defi n ition of a CpG island is sligh tly op en to in terpretation, the distribution of the CpG island lengths in the sequ ence is of interest. This is calculated through ( 14 ), if Λ( k ) is tak en to mean a run of + ’s of length k . W aiting time probabilities are computed through Th eorem 3.2 . Appro ximate lo cations of CpG islands are indicated b y the jumps in the probabilit y p lot of Figure 2 (a). In that p lot, w hen k = 100, there is a jum p around sequ ence p osition 4,500, and th en another jump app ro ximately at p osition 14,000. How ev er, when the length k is increased, the jump aroun d sequence p osition 4,500 disapp ears, in dicating that the firs t CpG isla nd is smaller than the second one. Th ese lo cations and size differences were v er- ified by u sing the soft ware CpG islands searc her [ T ak ai and Jones ( 2003 )], whic h is based on the (non-HMM) algorithm of T ak ai and Jones ( 2002 ) and requires the use of p redetermined thresholds. Ho wev er, though the analysis using the latter softw are concurred with th e relativ e lengths f ou n d in this w ork, the actual lengths of the CpG islands giv en by the soft ware (wh ic h giv es a fixed length and not a distribu tion) were longer than those exp ected using the fu ll distribution. Note that b oth th e CpG island lengths deter- mined by the soft w are, and the length distrib ution computed here, dep end on initial settings, the initial parameters for the softw are or th e transition probabilities for the { X t } sequence when u sing HMMs. The stand ard metho d of detecting CpG islands using HMMs is to use th e Viterbi algorithm to find the most probab le state sequ ence and then searc h for CpG islands as though th e d er ived state sequence giv es the true un der- lying states. Ho we v er, as was mentioned in the in tro duction, although the Viterbi algorithm giv es the most probable state sequ en ce, using it do es not necessarily lead to the most pr ob ab le CpG island length. Using the Viterbi algorithm, a CpG island of length 362 is found in the data. This corresp ond s to the small j ump in the d istribution at th e corresp onding lo cation [tow ard the r ight tail of the probabilit y distribu tion plotted in Figur e 2 (b)]. Thus, while 362 is the CpG island length from the most p robable state s equence, it is not the most pr ob ab le CpG island length for this data set. By definition, CpG island s are often required to be at least 100 base pairs long, and thus, th e num b er of islands of at least size 100 is of signifi- can t interest. Defining contin uation states S Q ∈ A,C, G,T { ( Q + , → ) } , and using Theorem 3.3 , the d istr ibution of the num b er of CpG islands of length at least k is computed (Figure 3 ). T his distribution yields an estimated mean for the num b er of islands of length at least 100 in the sequence of 3.26, and a m o de of 3 islands. Using the metho d based on the Viterbi algorithm [ Durbin, Eddy , Krogh and Mitc hison ( 19 98 )], four islands were iden tified, ho wev er, only t wo of them are at least 100 base p airs in length, sho win g DISTRIBUTION S FOR HMM P A TTERNS 17 (a) Probability distribution of a CpG island of length at least k having o ccurred at or b efore different sequence p ositions. (b) Probability mass funct ion of maximal CpG island length. Fig. 2. CpG island distributions for the 18,058 nucle otide gene se quenc e lo cus AL133339 fr om Human Chr omosome 20. The first plot shows the pr ob ability of islands of lengths k = 100 , k = 200 , and k = 300 o c curring at or b efor e the various lo c ations of the se quenc e, while the se c ond gives the pr ob ability m ass f unction of the maximal CpG i sland l ength using the entir e data se quenc e. 18 J. A. D . AS TON AND D. E. K. MAR TIN that the most probable state sequence d o es n ot necessarily giv e the most probable n um b er of islands when imp ortan t biological constr aints are ap- plied. It w ould b e very difficult to fi nd a w ay to constrain the Viterbi algorithm to fi nd the most probable state sequence sub ject to b iologica l constrain ts. Ho we v er, if, once the most likely state sequ ence is foun d using the Viterbi algorithm, b iologica l constrain ts are imp osed, the state sequence is mo difi ed, c hanging some island states in to n on-island states. The state sequence is then not guarantee d to b e the most p robable on e, nor ev en th e most pr obable state sequen ce among those which conform to the desired constraints. F or the pu rp oses of counting, it is often desirable to ha v e gaps of at least a certain length, b efore allo win g a new island to start. This is biologi- cally r ealistic as islands are presu med not only to b e longer than a certain length but also to b e infrequent and n ot particularly close to one another [ T ak ai and Jones ( 2002 )]. In this case, a p roblem again arises when us in g the Viterbi algorithm f or CpG island detection. If t wo islands are close to- gether, they are deemed one island an d again the state sequence found b y the Viterbi algorithm is mo dified (the intermediate non-island states in the sequence b et w een the tw o islands are c h anged to b e island states). This also cannot then b e guarante ed to b e the most probable state sequ en ce among all sequences that conform to the biological constraints. On the other hand, gaps are very easily handled in the computation of pattern distribu tions present ed h ere. The distr ib ution of the n u m b er of CpG islands of at least a certain length, and ha ving gaps s eparating them, ma y b e calculate d b y extending the ideas of ordered patterns [ F u and Ch ang ( 2003 )]. How ev er, the state space needed w ould b ecome v ery large. It is muc h m ore efficien t to calculate the distribu- tion us ing an argum en t ve ry similar to that used to compute the distribu tion of the total n u m b er of island s of length at least 100 (Theorem 3.3 ). In th is case, tw o Mark o vian systems are used, one to fin d CpG islands of at least a certain length, and an other to fi nd non- CpG island in terv als after the CpG island has fin ished. This essenti ally requires fin ding patterns of +’s in one conditional Mark ov c hain and then p atterns of − ’s in another conditional c hain. T he pr obabilit y of ente ring the absorb in g state of a “ +” pattern is then used as the probability for an in itial state of the conditional chain for the “ − ” pattern and visa v ersa, in a similar mann er as the absorp tion prob- abilit y from the ( i − 1)st chain is u sed as the initial probabilit y in ( 23 ) of the App end ix . F or example, the second “ +” c hain is n o w conditioned on b oth a “ +” pattern ha ving o ccurr ed previously and also a separation of “ − ” of a certain length ha ving o ccurred after that. A separation of at least 100 base pairs is often c h osen to b e the m in im u m that is required for t w o CpG islands to b e distinct [ T ak ai and Jones ( 2003 )]. The CpG island searc her soft ware requires a minimum of 200 base pairs to DISTRIBUTION S FOR HMM P A TTERNS 19 (a) Probability distribution of num b er r of CpG islands of length at least 100 having occurred at or b efore different seq u ence p ositions. (b) Probability mass funct ion of number of CpG islands of length at least 100. Fig. 3. CpG island distributions for the 18,058 nucle otide gene se quenc e lo cus AL133339 fr om Human Chr omosome 20. The first plot shows the pr ob ability of having r islands of lengths at le ast 100 o c cur at or b efor e the various lo c ations of the se quenc e. The se c ond plot depicts the pr ob ability mass function of the numb er of CpG i slands of length at le ast 100 using the entir e observe d data se quenc e, as wel l as unc onditional on the data. 20 J. A. D . AS TON AND D. E. K. MAR TIN b e present for a s egmen t to b e coun ted as a CpG island, as well as a mini- m u m separation of at least 100 base pairs b et we en islands, and these lengths will b e used here to p ro vid e a comparison. Ho wev er, the analysis could eas- ily b e mo d ified to deal with other biological constraints, if necessary . Th e CpG islands p resen t in the DNA sequence AL133339 are r elativ ely s h ort (as evidenced by the length distrib ution), whic h means that there is less chance of the patterns b eing split in to t wo islands with b oth b eing coun ted as b e- ing ab ov e a certain length. How ev er, the DNA sequence AL117335 [ Smith ( 2007 )] of length 44,527 base p airs, also f r om c hromosome 20, contai ns an example of a long CpG island . If th is island were split without a minim um separation d istance b et ween the p ieces, a higher num b er of islands could b e predicted by th e mo del. In deed, when usin g the Viterbi algorithm, it is n ot unusual to see islands with small breaks b et w een them in the most p robable state sequence (without any constrain ts placed on it). Th ese would then b e mo dified and coun ted as b eing f rom one island. Thus, th e condition of a minim um separation b et ween islands is a u seful b iological constraint th at should b e imp osed on the analysis. As exp ected, add in g the biological restriction of a minimum gap length of 100 b ase pairs reduces the lik ely num b er of islands count ed in th e data [see Figur e 4 ]. T he corresp onding pr obabilities of o ccurrences at or b efore certain sequence lo cations under this restriction can also b e foun d and are giv en in Figure 4 (a). Using the Viterbi algorithm, sev en islands in total are found in AL117335. Ho wev er, only tw o of those ha ve more than 200 base pairs and a separation of more than 100 b ase p airs. There are t wo additional islands wh ic h are close to b eing coun ted (one island w h ic h, although longer than 200 base p airs, is only 95 base pairs fr om another, and another one that is only 193 base pairs long). By us in g the CpG island searc her softw are with the same restrictions, three islands w ere found in the sequence. As can b e seen in Figure 4 (b), it is likely that there are tw o or three islands in the data, probably arisin g close to lo cations 2,000, 18,000 and 26,00 0 [see Figure 4 (a)]. While th e first island w as not confi r med by the CpG island searc her soft ware, the lo cations of the latter tw o islands were. Thus, by using a com bination of the distribution estimates and the pr ob ab ilistic plots, an additional p ossible lo cation for a CpG island has b een identified, w hic h , although not satisfying the pr edetermined threshold requir emen ts u sed in the s oft ware, is consisten t with the HMM that is b eing u sed in the present analysis to ident ify CpG islands. One could compu te p robabilities for the length of com bined island s by allo wing the desired pattern to b e a sc an , th us extend in g w ork for scans in Marko vian sequences [see, e.g ., Naus ( 1982 ), Koutras and Alexandr ou ( 1995 )] to the HMM setting. Ho w ev er, careful definitions of wh at consti- tutes a scan w ould need to b e made so that the outpu t wo uld constitute a biologica lly p laus ib le island. DISTRIBUTION S FOR HMM P A TTERNS 21 (a) Probability distribution of num b er r of CpG islands of length at least 200 with a separation gap of at least 100 base pairs having occurred at or b efore d ifferent sequence p ositions. (b) Probability mass funct ion of number of CpG islands of length at least 200, with and without a separation gap of 100 base pairs required. Fig. 4. CpG island distributions for the 44,527 nucle otide gene se quenc e lo cus AL117335 fr om Human Chr omosome 20. The first plot shows the pr ob ability of the numb er of islands r of length at le ast 200 o c curring at or b efor e the various lo c ations of the se quenc e, while the se c ond gives the pr ob ability mass f unction of the numb er of CpG islands of length at le ast 200 using the entir e data se quenc e. The r e quir ement that ther e should b e a gap b etwe en CpG islands of at le ast 100 b ase p airs is ac c ounte d for i n the distributions. 22 J. A. D . AS TON AND D. E. K. MAR TIN Computing these distribu tions can b e computationally exp ensive in terms of CPU time. The programs were written in MA TLAB and run on a standard desktop P C. T o ru n the example for AL133339 with o v er 18,000 base pairs to fi nd island s of length at least 100 takes app ro ximately 8 minutes on a single PC. Ho w ev er, the actual time used in matrix multiplica tion is only 5 seconds, with the need to constan tly reassign the inhomogeneous transition probabilities to lo cations in the transition probability matrix requir in g the rest of the time. Ho we v er, this means that considerable sa vings can b e made when determining the length distribution b y calculating it at once rather than sequen tially , as the submatrices of a large transition matrix can b e used to calculate distr ib utions at eac h time p oint w ithout needing to r eassign probabilities. The calculation for AL117335 with o ve r 44,000 base p airs, islands of at least length 200 and separation gaps of least 100 base pairs take s just ov er 40 min utes on a single P C . Th e use of a PC cluster could certainly facilitate m u c h quic k er computation of these d istributions. 5. Discussion. Distributions asso ciated with ru ns and patterns in ran - dom sequences are usually computed based on some mo del, but with no additional in f ormation. Here, a metho d is introduced to compute su c h prob- abilities in situations where T observ ations of an obs erv ed sequence hav e b een realized, b ut where the patterns of in terest o ccur in an und erlying state sequence. The observ ation sequence give s incomplete or noisy infor- mation concerning the v alues of the unobserved sequence. A hidden Marko v mo del of an arbitrary order m is us ed to mo del this situation. Using the metho dology of th is pap er, distrib u tions asso ciated with patterns in an un- derlying state sequence ma y b e computed either up to ind ex T , or to an index T ∗ > T . Probabilities are compu ted by asso ciating with the un derlying state se- quence a Mark o v c h ain that lies in its absorb ing state if and only if the pattern of interest has o ccurred . This allo w s the computation of probabili- ties throu gh basic p r op erties of Mark ov c hains. Th e t y p es of patterns th at ma y b e inv estigated are of a general nature and the distributions can b e found for a v ariet y of features, in cluding, bu t not limited to, the wa iting time for a pattern to o ccur, the maximal length of a run or rep eated pat- tern and the n u m b er of pattern o ccurrences, all conditional on the observ ed data and p ossibly sub ject to additional constraints. As h as b een seen, these features h a ve direct relev ance to many applications. The computations themselv es ma y b e quite intensiv e, but are made sim- pler b y the m th ord er forw ard-bac kward algorithm, whic h pr o vides a qu ic k metho d to determin e the transition p robabilities for the underlying state sequence, and thus also for th e auxiliary Mark ov chain. Th e num b er of ad- ditional states needed in S Z o ve r those required for S X dep end s on sev eral DISTRIBUTION S FOR HMM P A TTERNS 23 factors. Wh ile the worst case scenario is that the n u m b er of additional states increases exp onen tially with the ord er of Mark ovia n dep end ence, patterns are often asso ciated with on ly a small num b er of states of S X , and the n u m- b er of additional states required then increases exp onenti ally in only these states. T his is esp ecially tru e in cases su ch as simple patterns or small com- p oun d patterns, as in the examp les. In simple patterns, for example, ru n s of one symb ol, only one state is asso ciated w ith the pattern, and thus, the n u m b er of add itional states do es not increase at all. The complexit y also in- creases w ith the length of pattern, th e num b er of p atterns to b e f ound an d the length of the data, bu t the increases are only of linear order. It shou ld also b e noted that the structure of these trans ition matrices can b ecome in- credibly sp arse, whic h aids computation considerably . As an example, if the order of the u nderlying Mark ovia n sequence was c h an ged to second order in the CpG islands examp le, approximate ly four times as many s tates w ould b e needed for eac h computation, although most of these will ha ve transition probabilities of zero b et ween them. In practice, th e slo west part of compu tation often arises from the need to con tinually r eassign th e transition probabilities to ap p ropriate lo cations in the transition pr obabilit y m atrix, du e to the inhomogeneous nature of the auxiliary Marko v c h ain. Th e transition p robabilities can all b e calculated quic kly outside the algorithm, bu t assigning them to the correct p ositions in the M t matrix can b e time consuming. This migh t b e o ve rcome, ho wev er, b y using computer languages that sp ecialize in th is sort of op eration. Ho w- ev er, in order to circumv en t this pr oblem when calculating distributions of run lengths, the distributions can b e calculated at eac h time p oin t usin g submatrices of a large tr ansition matrix, rather than doing it sequen tially . An alternativ e metho d for calculating the distribu tions is to sample from the conditional distr ib ution of the states through the conditional transition probabilities giv en b y Lemma 3.1 and then empir ically calculat e the dis- tributions of p attern lengths and n um b er of patterns from these samples. F or esp ecially complex p atterns, this could wel l lead to impr o veme n ts in the computation time, although the computed distr ibution w ould th en b e appro ximate. Ho wev er, given the inhomogeneous n ature of the transition probabilities and the large num b er of s amp les needed to get accurate d istri- butions for long sequences, unless th e patterns are quite complicated, this metho d is likely to b e less efficien t. F or example, to estimate d istr ibutions of CpG islands of length at least 100, the computational cost of generating one sample from the distribution (requirin g 64 transition p robabilities at eac h p oint) is 1 / 50 of the cost of findin g th e exact d istr ibution (requir in g 3217 transition p robabilities at eac h time p oint). Thus, only 50 samples could b e dra w n b efore the sampling metho d is more computationally exp ensive. This ratio obviously decreases as the length of the pattern increases, but only linearly (e.g., to find the exact distribution of islands of length at least 500 24 J. A. D . AS TON AND D. E. K. MAR TIN requires app ro xim ately 16,000 transition probab ilities at eac h p oint ). While the ov erhead of assigning the pr ob ab ilities to the tr ansition matrices hav e not b een in clud ed in this calculatio n , the storage requiremen ts for generat- ing large num b ers of samples and then searc h ing these samp les hav e also not b een included. These th ings b eing consid ered, as the patterns get m ore complicated in terms of num b er or length, computation thr ough sampling will b ecome relativ ely more efficien t, and ma y well b e appropriate in some applications, esp ecially for fi n ding the distribution of th e longest run . In the examples here, using the sampling metho d s would not b e compu tationally adv an tageous, and, as they also d o not lead to exact distributions, they were not u s ed. While the results of this p ap er facilitate the computation of general wait- ing time probabilities, other p ossible applications of the metho d ology exist, an example b eing c hange p oin t problems. Indeed, the CpG island example ab o ve could b e considered as a problem of detecting c h ange p oints b et we en CpG island s and non- CpG island s with Figures 2 (a)– 4 (a) giving information ab out the lo cations of those change p oin ts. Tw o iss u es h a ve n ot b een addressed in this pap er. First, in many in- stances, the transition p robabilities of the un derlying state sequence need to b e estimated, not an easy task since the s equ ence is hidd en. There has b een considerable wo rk on this problem [see Capp´ e, Moulines and Ryd´ en ( 2005 ) for th e latest in tec h niques in this area]. In this w ork, it is assu med that appropriate v alues for the transition probabilities hav e b een estimated, with the estimated parameters b eing used as input to compute the desired w ait- ing time d istributions. There could, ho wev er, b e an appreciable effect of the estimation p ro cess on the p robabilities that are ev entually determined . An area of fu ture work is to determine the effect of small errors in parameter estimation on the outpu t w aiting time d istributions for patterns. Second, in this pap er th e assump tion is made that the length T of the ob- serv ation sequence is fixed th roughout the exp eriment . In man y applications, suc h as for DNA sequences, this assu mption is appropriate, but in others, observ ations ma y come in a con tin ual stream, yielding a sequent ial analysis problem. While, in pr inciple, there is no restriction on using the metho ds of this pap er to up date distributions when a new obs er v ation arriv es, computa- tionally , this task ma y b e very b urden s ome. New transition matrices for the underlying state sequence wo uld b e needed after ev ery new observ ation, not only for fu ture p oint s but also for those in the p ast as w ell, as the b ac kward probabilities wo uld c hange for all t . Whether appro ximations can b e found to ease this bur den will also b e a topic for fu ture consideration. It is well kno wn that one of the main problems asso ciated with higher- order HMMs, and h igher-order Marko v chains in general, is the gro win g n u m b er of p arameters as the order of dep endence increases. Th is is one of the reasons why higher-ord er HMMs are not u s ed more frequently . How ev er, DISTRIBUTION S FOR HMM P A TTERNS 25 the metho ds presented here ma y b e applied to v arious forms of higher-order HMMs, in clud ing m o dels with r ed uced p arameter sets, such as that prop osed b y Raftery ( 1985 ). In deed, the Old F aithful geyser example demonstrates a second-order HMM with a reduced parameter set. In conclusion, this pap er h as su ggested a general app r oac h to the compu - tation of w aiting time distributions for patterns in states of HMMs that is easy to implement , and ye t also flexible enough to b e applicable to a wide v ariet y of app lications in science and engineering. APPENDIX A: DERIV A TION OF ALGORITHM Let φ ( i ) 0 ,t b e th e initial distribution for the Mark o v chain asso ciated w ith the i th o ccurrence, i = 2 , 3 , . . . , r , wh en th e chain starts at time t . S ince i > 1, the chain will start in one of the conti n u ation states. Define W { Λ i ( k ) } to b e th e wa iting time for the i th o ccur r ence of the pattern. Then P ( W { Λ i ( k ) } ≤ t ) (21) = X 0 ≤ t 1 ≤ t P ( W { Λ i − 1 ( k ) } = t 1 ) × P ( W { Λ i ( k ) } ≤ t | W { Λ i − 1 ( k ) } = t 1 ) . This can b e simplified u sing a renewa l argum en t. The second term in th e summation in ( 21 ) is the same as P ( W { Λ( k ) } ≤ ( t − t 1 )), assuming that th e c hain starts at time t 1 (the c h ain is inhomogeneous, and th u s, the starting time is needed), as the pr obabilit y of the i th occur rence conditioned on the ( i − 1)st can b e calculated using th e s ame pr obabilit y structures as those of the first o ccur rence (bu t s tarting in one of th e cont in u ation states). Hence, ( 21 ) equals X 0 ≤ t 1 ≤ t P ( W { Λ i − 1 ( k ) } = t 1 ) P ( W { Λ( k ) } ≤ ( t − t 1 )) (22) = X 0 ≤ t 1 ≤ t P ( W { Λ i − 1 ( k ) } = t 1 ) φ ( i ) 0 ,t 1 t Y j = t 1 +1 M j ! U (Γ) b y Theorem 3.2 , where the p ro du ct is taken to b e an id en tity matrix if t 1 = t . Define ψ ( i ) 0 ,t 1 = P ( W { Λ i − 1 ( k ) } = t 1 ) φ ( i ) 0 ,t 1 = [ P ( W { Λ i − 1 ( k ) } ≤ t 1 ) (23) − P ( W { Λ i − 1 ( k ) } ≤ t 1 − 1)] φ ( i ) 0 ,t 1 . 26 J. A. D . AS TON AND D. E. K. MAR TIN Then ( 23 ) equals X 0 ≤ t 1 ≤ t ψ ( i ) 0 ,t 1 t Y j = t 1 +1 M j ! U (Γ) , (24) whic h when expanded out equals t z }| { ( . . . ( ψ ( i ) 0 , 0 M 1 + ψ ( i ) 0 , 1 ) M 2 + · · · + ψ ( i ) 0 ,t − 2 ) M t − 1 + ψ ( i ) 0 ,t − 1 ) M t + ψ ( i ) 0 ,t ) U (Γ) , (25) where the probabilit y of seeing th e ( i − 1)st o ccurrence at time 0 is defined to b e 0 and h ence, ψ ( i ) 0 , 0 = 0. If ψ (1) 0 , 0 ≡ ψ 0 and ψ (1) 0 ,t ≡ 0 , t > 0, then the algorithm giv en in ( 16 )–( 17 ) iterativ ely ca lculates the set of s ums and p r o ducts of eac h b r ac ke t give n in ( 25 ) for all i = 1 , . . . , r o ccurrences simultaneo usly in i b efore the multiplicatio n with U (Γ). In the ab ov e it h as b een imp licitly assumed that only one state leads to absorption, as in the CpG island example (the deterministic output Y t guar- an tees this), and as suc h φ ( i ) 0 ,t 1 is a un it ve ctor with a 1 in the initial state. Ho we v er, the algorithm can b e easily mo difi ed in the case where there are m u ltiple states leading to absorp tion. This mo d ification is needed, for ex- ample, in the case when calculating CpG island distributions un conditional on th e data, where f ou r states can lead to absorption. Ac kn o wledgments. The authors would like to express th eir sincere thanks to Professor Ch en g-Der F uh for his careful r eading of an earlier v ersion of the man u script and his ve ry h elpful suggestions. The authors w ould also lik e to expr ess their gratitude to the editor, the asso ciate editor and the referee, whose s uggestions help ed greatly to impro v e the pap er. REFERENCES Aston, J. A. D. and Mar tin, D. E. K. (2005). W aiting time distributions of comp eting patterns in h igher-order Mark ovian sequ ences. J. Appl. Pr ob ab. 42 977–988. MR2203816 Azzalini , A. and Bow man, A. W. (1990). A lo ok at some d ata on the Old F aithful geyser. Appl. Statist. 39 357–365. Balakrishnan, N. and Koutras, M. (2002). Runs and Sc ans wi th Applic ations . Wiley , New Y ork. MR1882476 Barlo w, K. (2005 ). AL133339 locus of chromosome 20. EMBL/GenBank/DDBJ databases. Baum, L. E. and Eagon, J. A. (1967). An equality with applications to statistical esti- mation for probabilistic functions of finite state Marko v chains. B ul l . Amer. M ath. So c. 73 360–363. MR0210217 Bird, A. ( 1987). CpG islands as gene markers in th e vertebrate nucleus. T r ends in Ge- netics 3 342–347. Capp ´ e, O., Mouline s, E. and R yd ´ en, T. (2005). Infer enc e in Hidden Markov Mo dels . Springer, New Y ork. MR2159833 DISTRIBUTION S FOR HMM P A TTERNS 27 Cheung, L. W. K. (2004). Use of runs statistics for pattern recognition in genomic DNA sequences. J. Com put. Biol. 11 107–124. Ching, W.-K., Ng, M . K. and Fung, E. (2003). Higher-order hidden Mark ov mo dels with applications to DN A sequences. Le ctur e Notes in Comput. Sci. 2690 535–539. Springer, Berlin. Churchill, G. A. (1989). Sto chastic mod els for heterogeneous DNA sequences. Bul l . Math. Biol. 51 79–94. MR0978904 Co x, D. R . (1955). The analysis of non-Marko vian sto chastic pro cesses by the inclusion of sup p lementary v ariables. Pr o c. Cambridge Philos. So c. 51 433–441 . MR0070093 Durbin, R., Eddy, S., Krogh, A. and Mitchison, G. (1998). Biolo gic al Se quenc e Anal- ysis . Cambridge Univ. Press. Fu, J. C. and Chan g , Y. M. (2003). On ordered series and later w aiting time distributions in a sequence of Marko v dep endent multis tate trials. J. Appl. Pr ob ab. 40 623–6 42. MR1993257 Fu, J. C. and Koutras, M. V. (1994). D istribution theory of runs: A Marko v chain approac h. J. Amer. Statist. Asso c. 89 1050–1058. MR1294750 Gu ´ eguen, L. (2005). Sarment: Python mo dules for HMM analysis and partitioning of sequences. Bioi nformatics 21 3427–342 8. Hamil ton, J. D. (1989). A n ew approach to the economic analysis of non stationary time series and t he bu siness cycle. Ec onometric a 57 357–384. MR0996941 Har vey, A . C . (1989). F or e c asting , Structur al Time Series Mo dels and the Kal man Fi lter . Cam b rid ge U niv. Press. Hw ang, G. U., Ch oi, B . D. and Kim, J.-K. (2002). The wa iting time analysis of a discrete-time qu eue with arriv als as a d iscrete autoregressiv e pro cess of order 1. J. Appl. Pr ob ab. 39 619–629. MR1928895 Ko ski, T. (2001). Hidden Markov Mo dels for Bioinformatics . Kluw er Academic Publish- ers, Dordrecht. MR1888250 Ko u tras, M. V. and Alexa ndrou, V. A . ( 1995). Run s, scans and urn mo del d is- tributions: A unified Marko v chain app roac h . Ann. I nst. Statist. Math. 47 743 –766. MR1370288 Kro g h, A. (1997). Two metho ds for impro v in g p erformance of an HMM and t heir ap- plication for gene find ing. In Fif th I nternational Confer enc e on Intel ligent Systems f or Mole cular Bi ol o gy (T. Gaasterland et al., eds.) 179–186. AAA I Press. Kro g h, A., Mian, I. S. and Haussler, D. (1994). A h idden Mark ov model that finds genes in E. c oli DNA. Nuclei c A cids R ese ar ch 22 1501–1531. Li, J. and Gra y, R. M. (2000). Image Se gmentation and Compr ession Using Hidden Markov Mo dels . Kluw er A cademic Publishers. Lindgren, G . ( 1978). Marko v regime models for mixed distribu t ions and switc hing re- gressions. Sc and. J. Statist. 5 81–91. MR0497061 Macdonald, I. L. and Zucchini, W. (1997). Hidden Markov and other Mo dels for Discr ete-value d Time Series . Chapm an and H all, London . MR1692202 Mar tin, D. E. K. and A ston, J. A. D. (2007). W aiting time distribution of generalized later p attern s. T o app ear. Naus, J. I. (1982). Approximations for distributions of scan statistics. J. Amer. Statist. Asso c. 77 177–183. MR0648042 Perkins, S. (1997). Inside Old F aithful: Scientists lo ok d ow n the th roat of a geyser. Scienc e News Oct 11 1997 232. Rabiner, L. R . (1989). A t u torial on hidden Mark o v models and selected applications in sp eech recognition. Pr o c e e dings of the IEEE 77 257–286 . 28 J. A. D . AS TON AND D. E. K. MAR TIN Rafter y, A. E. (1985). A mo del for high-order Marko v chains. J. R oy. Statist. So c. Ser. B 47 528–539. MR0844484 Reiner t, G., Schba th, S. and W a terman, M. S. (2005). Probabilistic and statistical prop erties of finite words in finite sequences. In L othair e : Appli e d Combinatorics on Wor ds (J. Berstel and D. Perrin, eds.). Cam bridge Univ. Press. MR2165687 Saxono v, S. , Berg, P. and Brutla g, D. L. (2006). A genome-wide analysis of CpG dinucleotides in the human genome distinguishes tw o distinct classes of promoters. Pr o c. Natl. A c ad. Sci. USA 103 1412–1417. Sims, C. A . and Zha, T. (2006). W ere there regime switches in US monetary p olicy? Amer ic an Ec onomi c R eview 96 54–81. Smith, M. (2007). AL117335 locus of chromoso me 20. EMBL/GenBank/DDBJ databases. T akai, D. and Jones, P. A. (2002). Comprehensiv e analysis of CpG islands in human chromo somes 21 and 22. Pr o c. Natl. A c ad. Sci. USA 99 3740–3745. T akai, D. and Jones, P. A. (2003). The CpG island searcher: A new WWW resource. In Silic o Bi olo gy 3 0021. Viterbi, A. (1967). Error b ounds for conv olutions codes and an asymptotically opt imal decod ing algorithm. IEEE T r ans. I nform. The ory 13 260–269 . Yuan, M. and Ken dziorski, C. (2006). H idden Marko v mo dels for microarra y time course d ata in multiple biological cond itions. J. A mer. Statist. Asso c. 101 1323–1334. Institute of St a tistical Science Ac ademia Sinica 128 Academia R oad, Sec 2 T aipei 11529 T aiw an R OC E-mail: jaston@stat.sinica.edu.t w Dep ar tment of St a tistics Nor th Carolina S t a te University Campus Box 82 03 2501 F oun ders Drive Raleigh, Nor th Carolina 27695-8 203 USA E-mail: martin@stat.ncsu.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment