숨은 마코프 모델에서 일반적인 런·패턴 분포 계산 방법
본 논문은 관측 시퀀스가 주어졌을 때 숨은 상태 시퀀스 내 패턴(런, 경쟁 패턴, 일반화된 후속 패턴 등)의 확률 분포를 효율적으로 계산하는 일반적인 프레임워크를 제시한다. 고차 마코프 의존성을 허용하고, 보조 마코프 체인을 도입해 계산을 단순화한다. DNA CpG 섬 분석을 포함한 두 사례를 통해 방법의 실용성을 입증한다.
저자: ** (원문에 저자 정보가 제공되지 않았으므로, 논문에 명시된 저자명을 그대로 기재해 주세요.) **
본 논문은 숨은 마코프 모델(HMM)에서 관측값이 주어졌을 때 숨은 상태 시퀀스 내 특정 패턴이 발생할 확률 분포를 계산하는 일반적인 방법론을 제시한다. 연구 배경으로는 기존 HMM 이론이 주로 관측 시퀀스의 전체 가능도 계산, 최적 상태 경로(Viterbi) 탐색, 파라미터 추정(EM) 등에 집중했으며, 패턴 발생 확률에 관한 연구는 상대적으로 부족했다는 점을 들었다. 특히 DNA 서열 분석, 음성 인식, 이미지 처리 등에서 “특정 모티프가 몇 번 나타났는가”, “그 모티프의 길이는 어떻게 분포하는가”와 같은 질문은 실질적인 응용에 필수적이다.
논문은 먼저 고차 HMM(숨은 상태가 m‑차 마코프 의존성을 갖는 경우)을 정의하고, 전통적인 전방·후방 알고리즘을 일반화한다. 상태 확장 ˜Xₜ = (X_{t‑m+1},…,X_t) 를 도입해 초기 분포 π(˜X₀)와 전이 확률 p(X_t|˜X_{t‑1})를 정의하고, 관측 확률 γ_t(Y_t|X_t)와 결합해 전방 변수 α_t(˜X_t)=P(Y(1:t),˜X_t)를 재귀적으로 계산한다. 후방 변수 β_t(˜X_t)=P(Y(t+1:T)|˜X_t) 역시 유사하게 정의된다. 이 두 변수를 곱해 전체 관측 시퀀스에 대한 조건부 확률을 얻는다.
다음으로 패턴 정의를 확장한다. 단순 패턴은 심볼 시퀀스 Λ_i 로, 복합 패턴은 여러 단순 패턴의 합집합 Λ = ∪_{i=1}^η Λ_i 로 정의한다. 경쟁 패턴은 c개의 복합 패턴 중 먼저 r_j 번 나타나는 경우를, 일반화된 후속 패턴은 모든 패턴이 지정된 횟수만큼 나타난 뒤의 대기 시간을 의미한다. 이러한 패턴은 “런”(연속된 동일 심볼)이나 “교차”(1011 등) 등 다양한 형태를 포함한다.
패턴 발생을 추적하기 위해 보조 마코프 체인 Z_t 를 구성한다. Z_t는 현재까지 매치된 패턴 접두사의 길이와 현재 숨은 상태 X_t 를 결합한 형태이며, 전이 확률은 원래 HMM 의 전이·발생 확률과 패턴 매칭 로직(접두사 자동화) 의 곱으로 정의된다. 이 보조 체인은 마코프 성질을 유지하면서 패턴 진행 상황을 상태에 내재화한다. 따라서 전방·후방 재귀식에 보조 체인의 전이 행렬을 삽입하면, 특정 시간 T* 에서 패턴이 종료되는 확률을 직접 계산할 수 있다.
카운팅 방식은 두 가지로 나뉜다. 첫 번째는 겹치지 않는 카운팅(SWNO, WPNO)으로, 패턴이 한 번 발생하면 그 이후부터 새 카운트를 시작한다. 두 번째는 겹치는 카운팅으로, 부분적으로 매치된 패턴이 완성될 때마다 카운트를 증가시킨다. 논문은 이 두 방식의 차이를 구체적인 예시(11111, 1011 등)로 설명하고, 실제 데이터 분석 시 선택 가능한 옵션으로 제시한다.
알고리즘 흐름은 다음과 같다. (1) 전방 변수 α_t 를 전부 계산한다. (2) 후방 변수 β_t 를 역순으로 계산한다. (3) 보조 체인의 종료 상태에 해당하는 인덱스를 찾아, α·β 값을 합산해 대기 시간 W(Λ) 의 분포를 얻는다. (4) 필요에 따라 최소 길이, 최소 간격 등 제약을 보조 체인의 상태 공간에 추가해 제한된 분포를 계산한다.
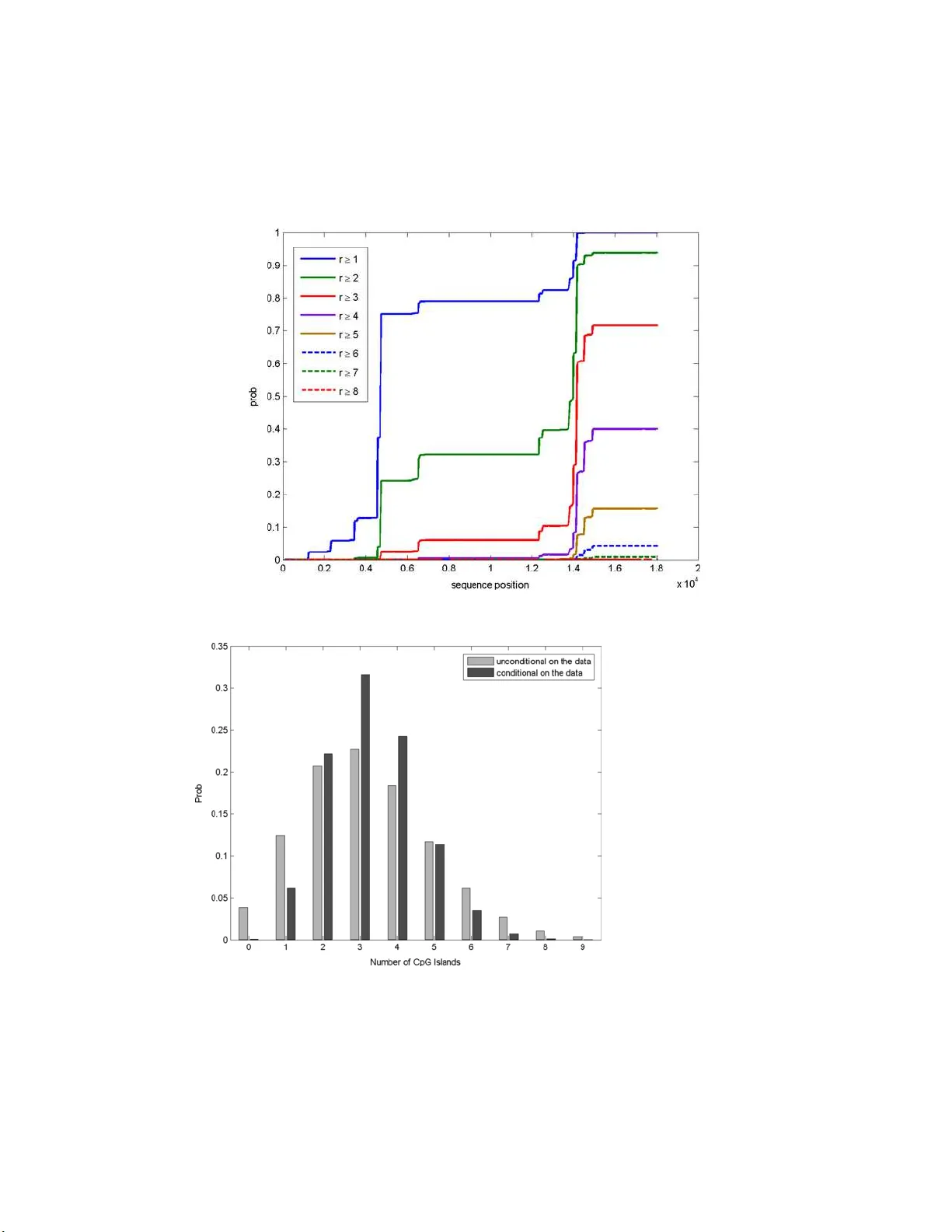
두 가지 실험이 제시된다. 첫 번째는 지질학적 데이터에서 단순 런(연속된 동일 심볼) 패턴을 적용해 방법론을 시연한다. 여기서는 관측값이 부분적으로만 주어졌을 때(예: T < T*)에도 대기 시간 분포를 추정할 수 있음을 보여준다. 두 번째는 인간 DNA 서열에서 CpG 섬을 탐지하는 복합 패턴 모델을 구축한다. CpG 섬은 C와 G가 인접해 있는 비율이 높은 구간으로, 섬의 시작·종료를 두 개의 숨은 상태(섬 내부, 섬 외부)로 모델링한다. 기존 방법은 Viterbi 경로를 사용해 섬을 단일 구간으로 결정했지만, 본 논문은 전체 조건부 분포를 이용해 섬의 개수, 길이, 간격 등에 대한 사후 확률을 제공한다. 특히 최소 섬 길이 100bp, 최소 간격 200bp 같은 생물학적 제약을 보조 체인에 포함시켜, 실제 데이터에서 Viterbi 결과와 차이가 나는 경우(섬 개수가 과소/과대 추정, 길이가 비현실적으로 길어지는 현상)를 정량적으로 설명한다.
결론에서는 제안된 프레임워크가 HMM 기반 데이터 마이닝에서 패턴 존재 확률을 정밀하게 추정할 수 있는 강력한 도구임을 강조한다. 고차 의존성, 다양한 패턴 정의, 겹침/비겹침 카운팅, 제약 조건 통합 등 여러 확장을 자연스럽게 지원한다는 점에서 기존 Viterbi‑기반 접근법을 보완한다. 향후 연구 방향으로는 연속 관측값(예: 연속형 신호)과의 결합, 대규모 상태 공간에 대한 효율적인 근사 알고리즘, 실시간 스트리밍 데이터에 대한 온라인 업데이트 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기