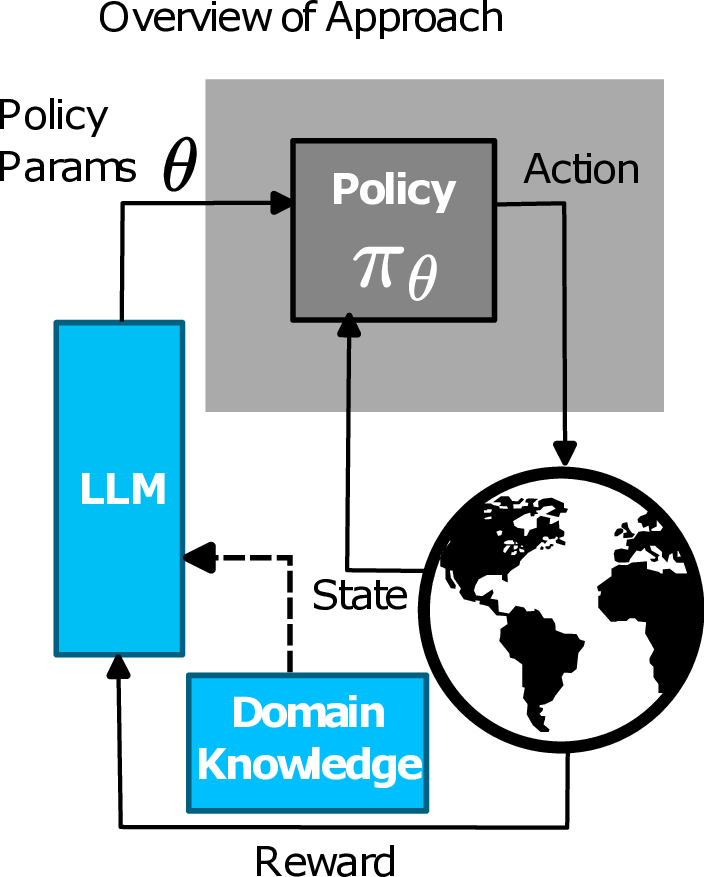
Prompted Policy Search: Reinforcement Learning through Linguistic and Numerical Reasoning in LLMs
Prompted Policy Search(ProPS)는 기존 강화학습 패러다임에 근본적인 변화를 시도한다. 전통적인 RL 알고리즘은 주로 환경으로부터 얻는 스칼라 보상에 기반해 정책을 업데이트한다. 이 접근법은 수학적으로는 깔끔하지만, 실제 문제에서는 목표 설명, 제약 조건, 인간 전문가의 조언 등 텍스트 형태의 풍부한 메타 정보를 무시한다는 한계가 있다. ProPS는 이러한 한계를 극복하기 위해 대형 언어 모델(LLM)을 정책 최적화의 핵심 엔진으로 활용한다. 구체적으로, 에이전트가 환경에서 얻은 보상과 함께 “목표는 ‘공을 잡아
Learning