📝 Original Info Title: Multi-granularity Interactive Attention Framework for Residual Hierarchical Pronunciation AssessmentArXiv ID: 2601.01745Date: 2026-01-05Authors: Hong Han, Hao-Chen Pei, Zhao-Zheng Nie, Xin Luo, Xin-Shun Xu📝 Abstract Automatic pronunciation assessment plays a crucial role in computer-assisted pronunciation training systems. Due to the ability to perform multiple pronunciation tasks simultaneously, multi-aspect multi-granularity pronunciation assessment methods are gradually receiving more attention and achieving better performance than single-level modeling tasks. However, existing methods only consider unidirectional dependencies between adjacent granularity levels, lacking bidirectional interaction among phoneme, word, and utterance levels and thus insufficiently capturing the acoustic structural correlations. To address this issue, we propose a novel residual hierarchical interactive method, HIA for short, that enables bidirectional modeling across granularities. As the core of HIA, the Interactive Attention Module leverages an attention mechanism to achieve dynamic bidirectional interaction, effectively capturing linguistic features at each granularity while integrating correlations between different granularity levels. We also propose a residual hierarchical structure to alleviate the feature forgetting problem when modeling acoustic hierarchies. In addition, we use 1-D convolutional layers to enhance the extraction of local contextual cues at each granularity. Extensive experiments on the spee-chocean762 dataset show that our model is comprehensively ahead of the existing state-of-the-art methods.
💡 Deep Analysis
📄 Full Content Multi-granularity Interactive Attention Framework for Residual Hierarchical
Pronunciation Assessment
Hong Han, Hao-Chen Pei, Zhao-Zheng Nie, Xin Luo, Xin-Shun Xu*
School of Software, Shandong University, Jinan, China
sparkinhan@163.com, {202235343, 202435350}@mail.sdu.edu.cn,
luoxin.lxin@gmail.com, xuxinshun@sdu.edu.cn
Abstract
Automatic pronunciation assessment plays a crucial role in
computer-assisted pronunciation training systems. Due to
the ability to perform multiple pronunciation tasks simul-
taneously, multi-aspect multi-granularity pronunciation as-
sessment methods are gradually receiving more attention
and achieving better performance than single-level model-
ing tasks. However, existing methods only consider unidi-
rectional dependencies between adjacent granularity levels,
lacking bidirectional interaction among phoneme, word, and
utterance levels and thus insufficiently capturing the acous-
tic structural correlations. To address this issue, we propose
a novel residual hierarchical interactive method, HIA for
short, that enables bidirectional modeling across granulari-
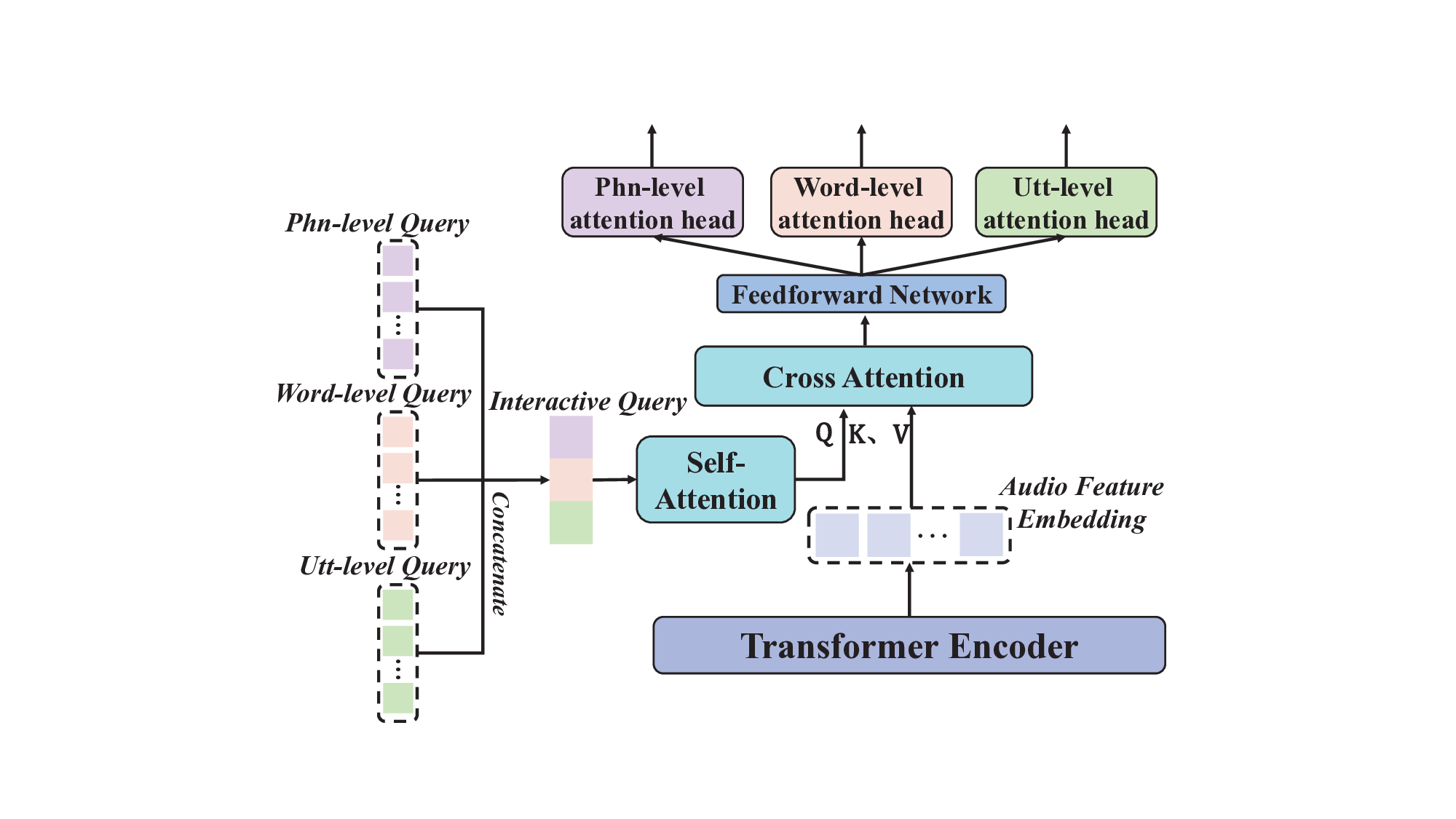
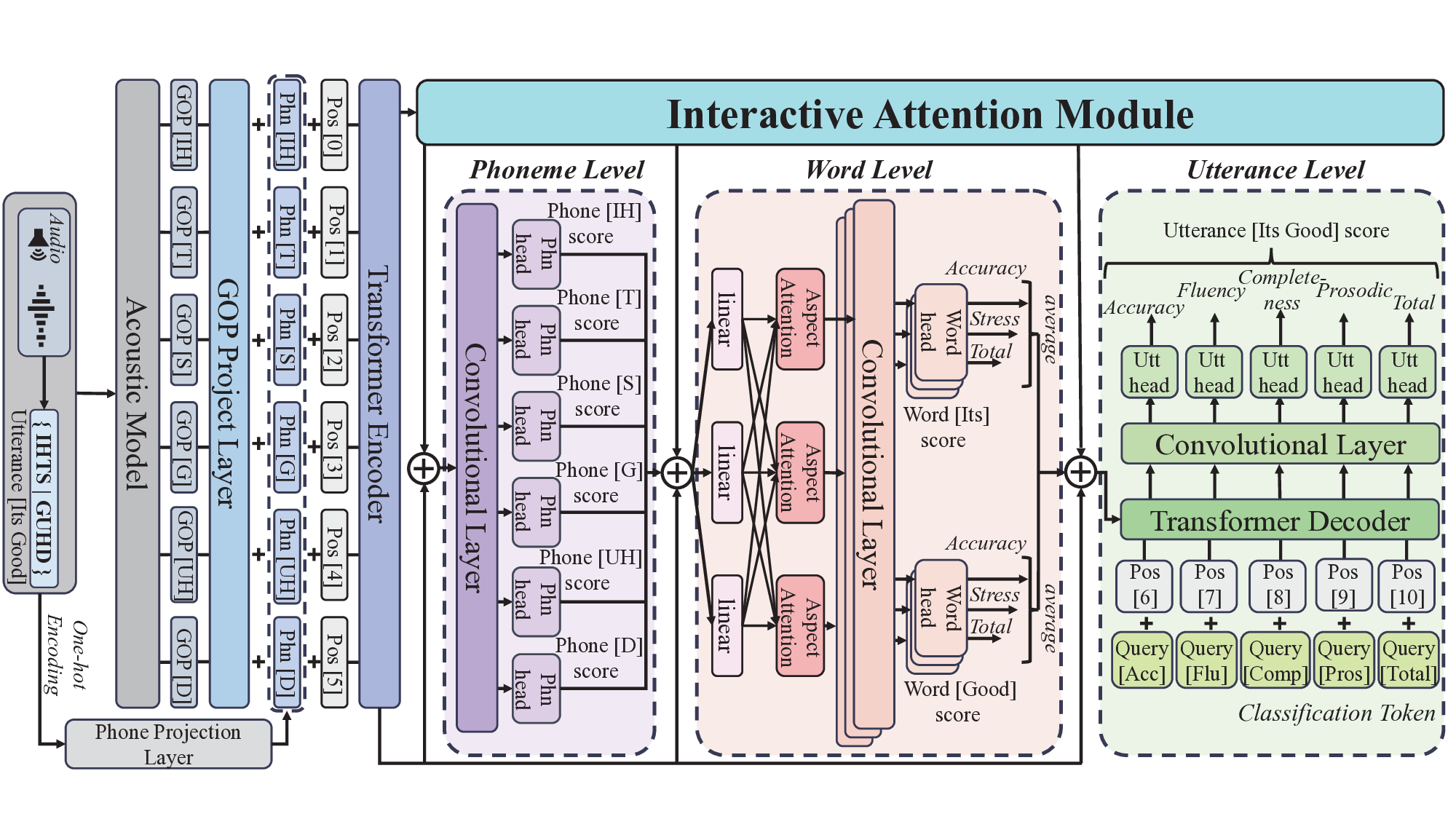
ties. As the core of HIA, the Interactive Attention Module
leverages an attention mechanism to achieve dynamic bidi-
rectional interaction, effectively capturing linguistic features
at each granularity while integrating correlations between dif-
ferent granularity levels. We also propose a residual hierarchi-
cal structure to alleviate the feature forgetting problem when
modeling acoustic hierarchies. In addition, we use 1-D con-
volutional layers to enhance the extraction of local contextual
cues at each granularity. Extensive experiments on the spee-
chocean762 dataset show that our model is comprehensively
ahead of the existing state-of-the-art methods.
Introduction
In the field of language learning, computer-assisted pronun-
ciation training system (CAPT) (Eskenazi 2009; Tejedor-
Garc´ıa et al. 2020), utilizing computer technology to assist
language learners in improving their pronunciation skills,
provides interactive training methods with immediate feed-
back. As the core component of CAPT, automatic pronunci-
ation assessment (APA) (Li, Wu, and Meng 2017; Kheir, Ali,
and Chowdhury 2023) aims to rate the quality of a speaker’s
pronunciation and provides detailed feedback to better as-
sist foreign language learning. Early researches on APA
tend to be centered around signal granularity of speech data,
such as assessing pronunciation accuracy at phoneme level
(Wang and Lee 2012) or detecting various aspect at word
or utterance levels (Tepperman and Narayanan 2005; Arias,
*Corresponding Author
Copyright © 2026, Association for the Advancement of Artificial
Intelligence (www.aaai.org). All rights reserved.
Utterance
Word
Phoneme
Its good
Its
good
IH
T
S
G
UH
D
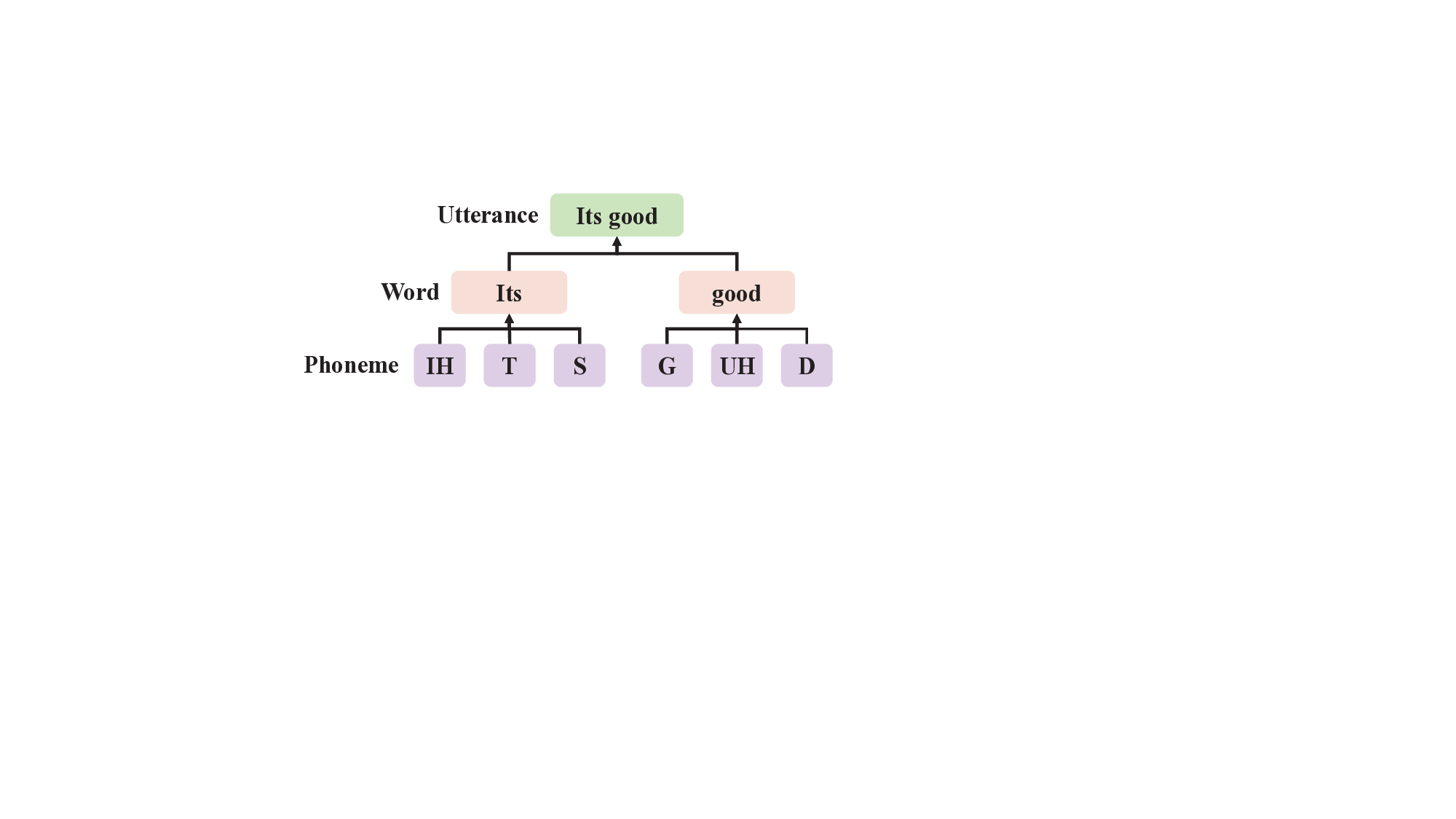
Figure 1: Schematic diagram of the acoustic hierarchical structure
with a sample utterance ”Its good”.
Yoma, and Vivanco 2010). These single-granularity assess-
ment methods perform well in some specific tasks they are
designed to address, but they have many limitations. In par-
ticular, they do not take the natural complexity and multi-
granularity nature of speech into account (Lin et al. 2020).
The granularities among the pronunciation assessment
tasks are not separated from each other (Cincarek et al.
2009), and they have some implicit correlations as shown in
Fig. 1. Acoustic signals are typically characterized by their
intricate hierarchical structure, with pronunciation results at
lower granularity levels affecting higher granularity levels
(Al-Barhamtoshy, Abdou, and Jambi 2014). However, mod-
eling a single granularity level cannot fully reveal this im-
plicit relations between different granularity levels.
Recently, to comprehensively study acoustic features at
multiple levels of granularity in read-aloud scenario, re-
search endeavors integrate multi-aspect multi-granular pro-
nunciation assessment tasks into a single model to simulta-
neously evaluate multiple aspects of pronunciation includ-
ing accuracy, fluency, prosody, and completeness within a
unified model across different granularities (i.e., phoneme,
word, and utterance).
However, existing methods have some limitations. GOPT
(Gong et al. 2022) can effectively handle different granular-
ity scoring tasks when modeling multi-granularity tasks in
parallel, but lacks interaction between granularities, which
may restrict the modeling of complex correlations between
different granularities. HiPAMA (Do, Kim, and Lee 2023)
uses a hierarchical structure to capture granularity depen-
dencies, but its information flow is unidirectional, failing
to consider bidirectional interaction. Gradformer (Pei et al.
arXiv:2601.01745v1 [cs.CL] 5 Jan 2026
2024) focuses on utterance modeling and fails to capture
the correlations between phoneme and word levels. Hier-
GAT (Yan and Chen 2024) uses graph neural networks for
hierarchical modeling, but its fixed graph structure limits
the dynamic interaction between different g
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.