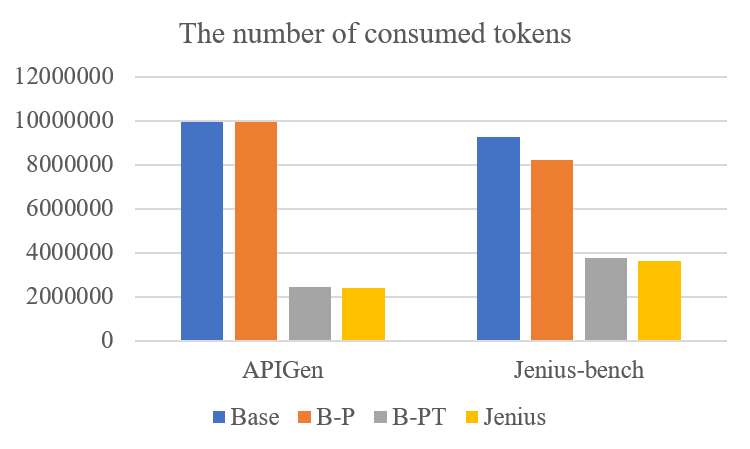
As agent systems powered by large language models (LLMs) advance, improving performance in context understanding, tool usage, and long-horizon execution has become critical. However, existing agent frameworks and benchmarks provide limited visibility into execution-level behavior, making failures in tool invocation, state tracking, and context management difficult to diagnose. This paper presents Jenius-Agent, a system-level agent framework grounded in real-world deployment experience. It integrates adaptive prompt generation, context-aware tool orchestration, and layered memory mechanism to stabilize execution and improve robustness in long-horizon, tool-augmented tasks. Beyond system design, we introduce an evaluation methodology that jointly measures procedural fidelity, semantic correctness, and efficiency. This framework makes agent behavior observable as a structured execution process and enables systematic analysis of failure modes not captured by output-only metrics. Experiments on Jenius-bench show substantial improvements in task completion rate, with up to a 35% relative gain over the base agent, along with reduced token consumption, response latency, and tool invocation failures. The framework is already deployed in Jenius (https://www.jenius.cn), providing a lightweight and scalable solution for robust, protocol-compatible autonomous agents.
In the context of the increasing capability of large language models (LLMs), LLM-based autonomous agents have become a new paradigm for AI applications (Yao et al., 2023;Xi et al., 2025;Wang et al., 2024). These agents are capable of understanding instructions, invoking tools, reasoning and planning, and performing complex tasks, and are widely used in a variety of fields such as research assistants, process automation, retrieval-augmented generation, and code generation and debugging (Dubey et al., 2024;Masterman et al., 2024;Qin et al., 2024;Singh et al., 2025). Although current intelligent agent systems (e.g., AutoGPT, LangChain Agents, BabyAGI) (Yang et al., 2023;Topsakal & Akinci, 2023;Nakajima, 2023) have begun to take shape, there are still numerous challenges in their generality, stability, and manageability, especially in task precision, response reliability, and system stability in situations with many tasks (Cemri et al., 2025).
Most existing agent systems rely on fixed prompts and predefined tool-use workflows, limiting their ability to understand task intent, select tools dynamically, and manage context effectively (e Aquino et al., 2025;Qin et al., 2024;Schick et al., 2023). Numerous works have shown that dynamic prompt, tool retrieval, and memory management play a key role in optimizing agent execution. For instance, MCP-Zero (Fei et al., 2025) enables active tool discovery for unseen tasks, while multi-agent designs (Zhou et al., 2025) enhance planning and coordination through optimized prompts and collaboration strategies. The Model Context Protocol (MCP) (Hou et al., 2025) standardizes context exchange, ensuring reliable tool invocation across systems. Together, these advances underscore that robust prompting, intelligent tool access, and effective memory are essential for high-quality agent execution.
Despite recent advances, autonomous agent pipelines still face three key challenges. First, fixed or generic prompts often misinterpret user intent and fail to adapt to evolving task states, causing unstable behavior and inconsistent outputs. Second, static tool lists or handcrafted rules cannot reliably choose the right tools under ambiguity or across domains, leading to unnecessary or incorrect calls. Finally, long dialogues accumulate redundant context, increasing token cost and diluting salient signals, which weakens reasoning quality.
Beyond system design, evaluating long-horizon, toolaugmented agents remains underdeveloped. Existing benchmarks emphasize final outputs or single-step tool calls. They fail to capture execution failures such as missing tools, incorrect ordering, or partial completion. This gap motivates an execution-centric evaluation perspective.
This study starts from the basic execution process of autonomous agents and introduces three complementary optimization modules addressing the above issues:
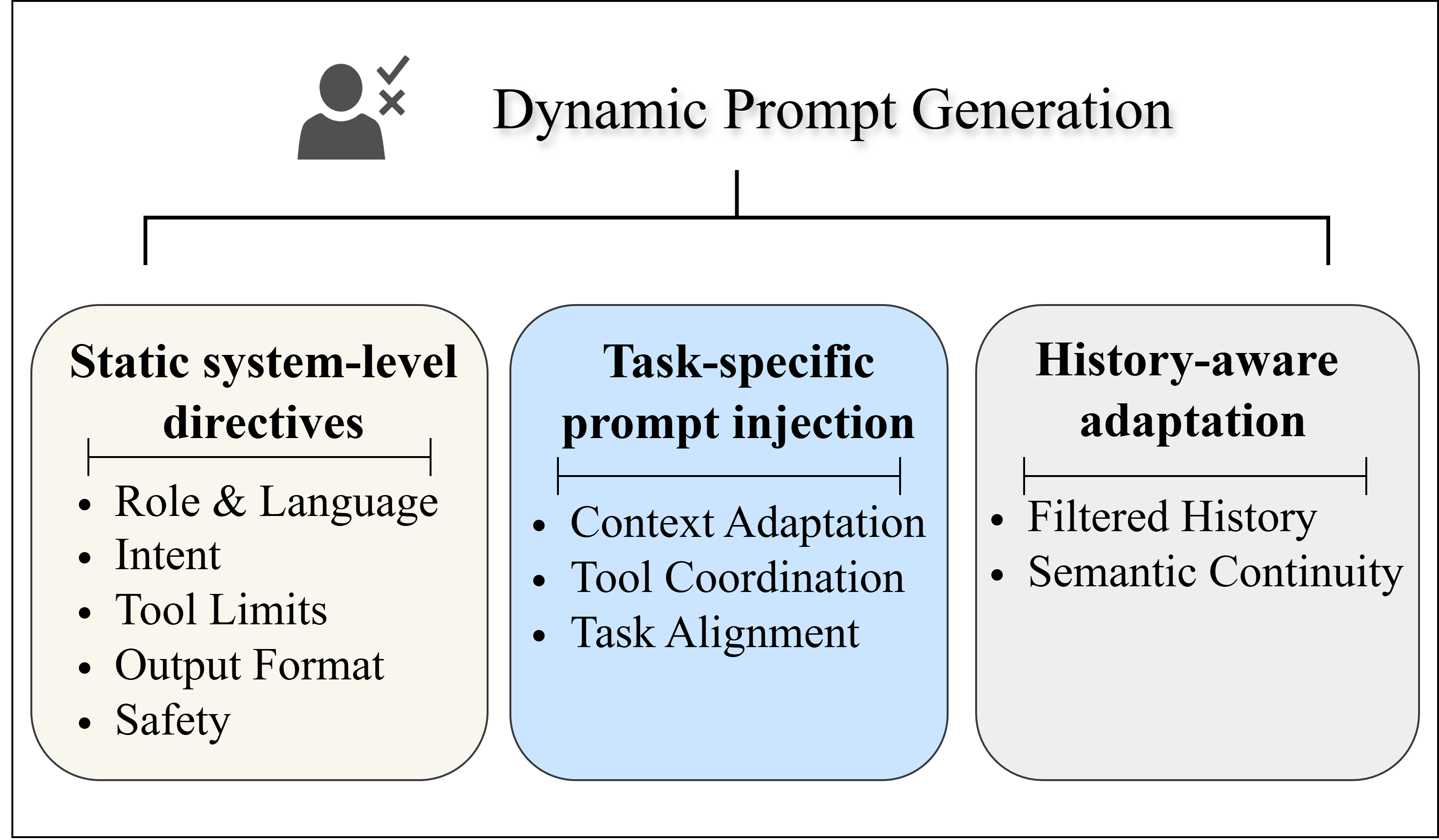
• Task Understanding and Prompt Optimization: Structured intent recognition was combined with refined system prompts and templates to adapt instructions to current state and goals, reducing misinterpretation and stabilizing task alignment. • Tool Retrieval: Dynamic retrieval and adaptive tool access were used to match user intent with context-relevant tools and to handle ambiguous user requests. • Hierarchical Memory Management: Redundant dialogue history was pruned to control token length, preserving essential semantics and stabilizing reasoning in longhorizon interactions.
Rather than evaluating isolated modules, this paper builds a unified framework named Jenius, which improves task accuracy, efficiency, and contextual robustness, aligned with emerging agent communication protocols (e.g., MCP, ACP, A2A) (IBM BeeAI, 2024;Google, 2024).
The main contributions are summarized as follows:
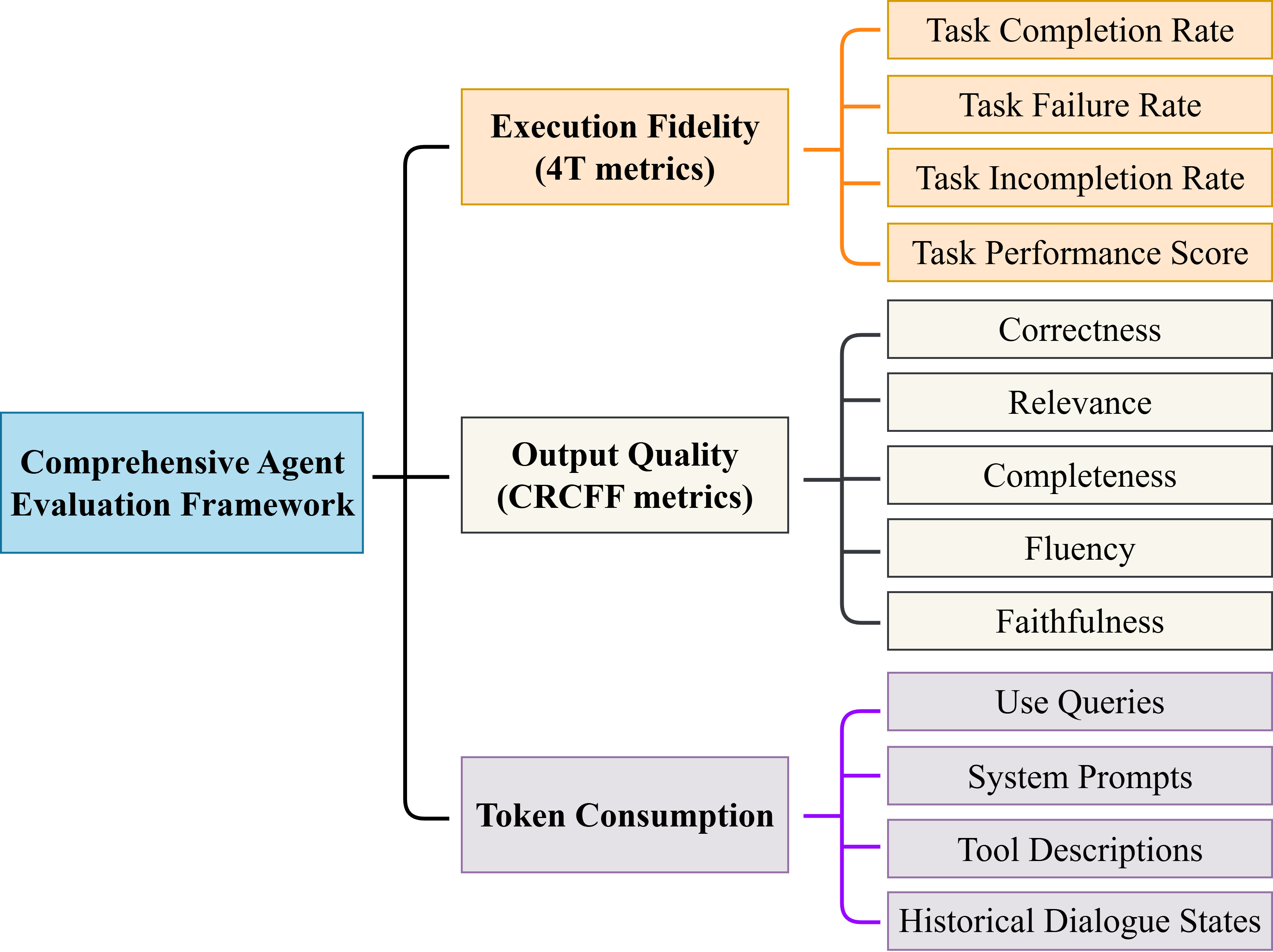
• We introduced a system-level execution abstraction that models agents as structured processes with explicit state, tool interactions, and failure modes. • We proposed a modular optimization framework integrating adaptive prompting, context-aware tool orchestration, and hierarchical memory management to mitigate context noise, tool misuse, and harmful prompting; • We improved task grounding and execution robustness through adaptive prompt generation and context-aware tool usage, while introducing preliminary defense strategies to strengthen the system’s resilience to malicious or erroneous inputs; • We designed a comprehensive evaluation framework that jointly measures procedural fidelity (4T), semantic quality (CRCFF), and efficiency, enabling diagnosis of real-world agent failures; • We also conducted extensive experiments both public and real-world datasets, demonstrating consistent gains in task accuracy, response quality, token efficiency.
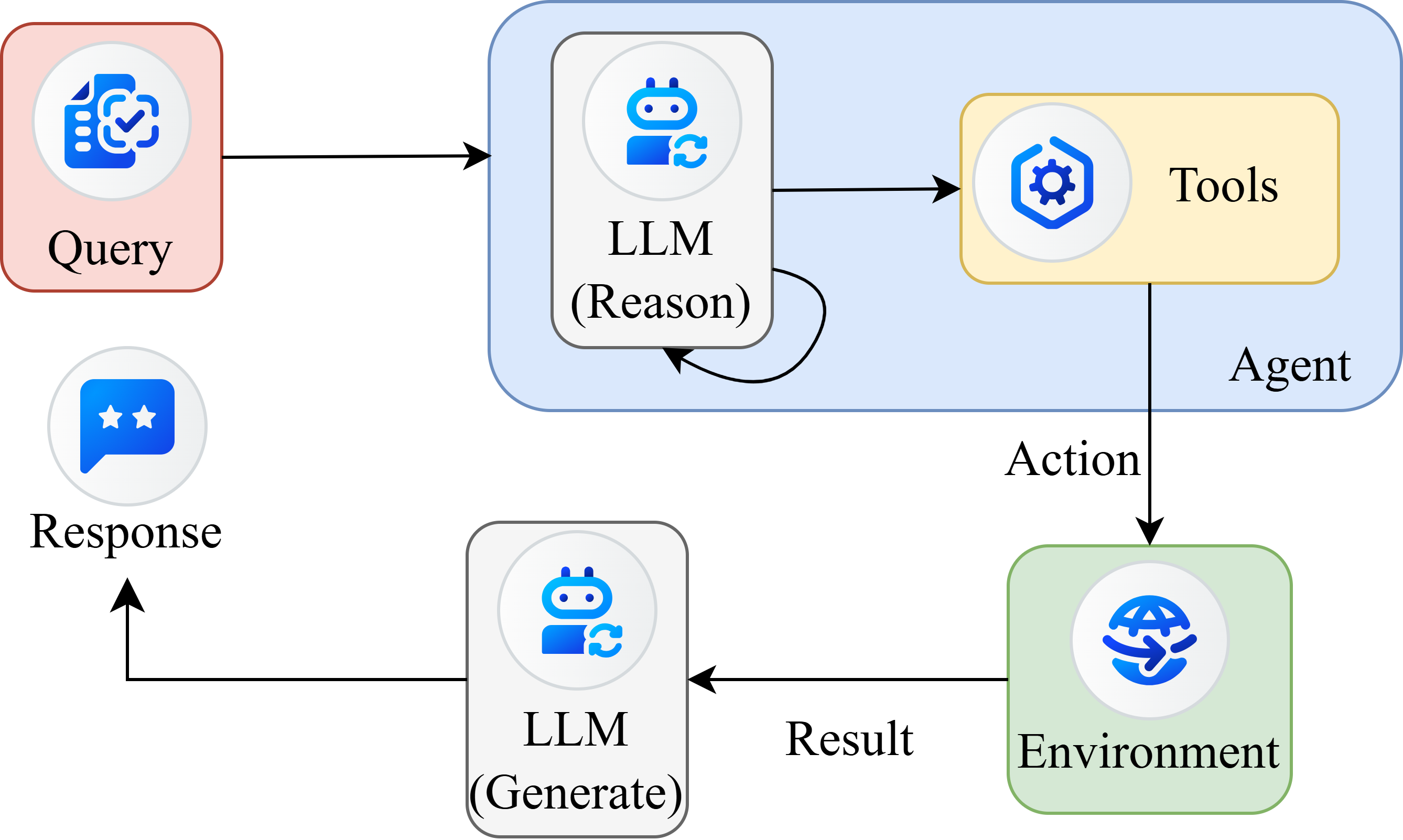
With the rapid advancement of LLMs, research on agent systems has expanded in multiple directions. A typical ReAct (Yao et al., 2022) style autonomous agent workflow, illustrated in Figure 1, follows an interleaved cycle of reasoning, action,
This content is AI-processed based on open access ArXiv data.