Deep learning models are widely used across computer vision and other domains. When working on the model induction, selecting the right architecture for a given dataset often relies on repetitive trial-and-error procedures. This procedure is time-consuming, resource-intensive, and difficult to automate. While previous work has explored performance prediction using partial training or complex simulations, these methods often require significant computational overhead or lack generalizability. In this work, we propose an alternative approach: a lightweight, two-stage framework that can estimate model performance before training given the understanding of the dataset and the focused deep model structures. The first stage predicts a baseline based on the analysis of some measurable properties of the dataset, while the second stage adjusts the estimation with additional information on the model's architectural and hyperparameter details. The setup allows the framework to generalize across datasets and model types. Moreover, we find that some of the underlying features used for prediction-such as dataset variance-can offer practical guidance for model selection, and can serve as early indicators of data quality. As a result, the framework can be used not only to forecast model performance, but also to guide architecture choices, inform necessary preprocessing procedures, and detect potentially problematic datasets before training begins.
Training deep learning models often takes a tremendous amount of computing resources. The typical cycle of designing, tuning, and validating models can be slow and expensive, which makes it hard to deploy to diverse scenarios. The aspect of green computing concerns us about how to accomplish deep learning tasks with as minimal energy usage as possible. As a result, having a wise energy-aware plan in advance when dealing with deep learning tasks is especially important. In this work, we aim to have the ability to estimate how well a specific model may perform before the training for convergence. Based on such a prophetic action, we have the choice of proceeding or not proceeding with the complete and precise deep induction procedure. Moreover, the estimated performance may be already good enough when only approximated performance is needed to justify the model's ability. Overall, the proposed method serves as a beneficial pre-run procedure to save unnecessary computation, in nowadays when machine learning operations (MLOps) has become a focused discipline.
The focused problem is to ask for a hint about the performance of a deep model before the formal training of the model. The hint may suggest that the trained model may or may not work well, then, leading to several action plans: (i) the model may work well and we would like to know the precise model performance after a formal training of the model; (ii) we understand the model’s approximated performance up to certain degree and the approximation is good enough to make further decisions, such as good enough to evaluate between the models that own various settings or parameters; (iii) the model may not work well or work below our expectation and we should avoid the use of such deep model. The computation that is needed to perform the complete training of the deep learner is saved.
A practical solution for the aforementioned problem must satisfy four requirements simultaneously: (i) operate strictly before training, (ii) be computationally lightweight, (iii) generalize across datasets and domains, and (iv) be interpretable enough to inform design choices. Existing approaches may miss one or more of these requirements. The learning curve-based methods still require partial training runs, which go against the idea of avoiding early computation [1]. On the other hand, some other approaches rely on complex surrogates, such as Graph Neural Networks (GNNs), that can take as much time and memory as training the actual model [2]. In addition, many methods act like black boxes, offering limited explanations of why a model might succeed or fail. We lack the possibility from further improving or revising the training strategy. For instance, White et al. [3] proposed BANANAS, a neural predictor that accelerates NAS through path-based encodings, but it remains essentially a predictive surrogate with limited interpretability regarding why certain architectures may perform well.
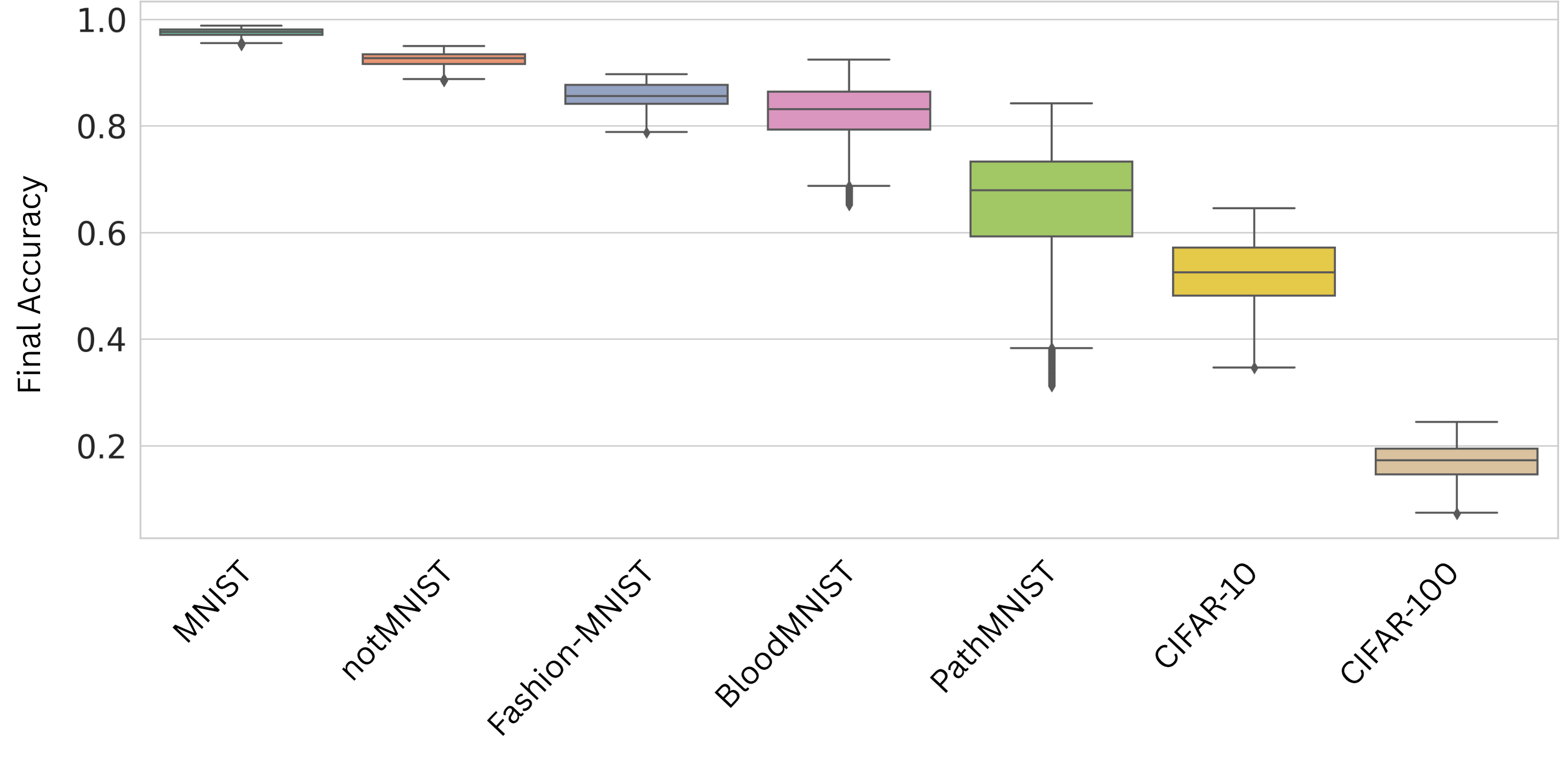
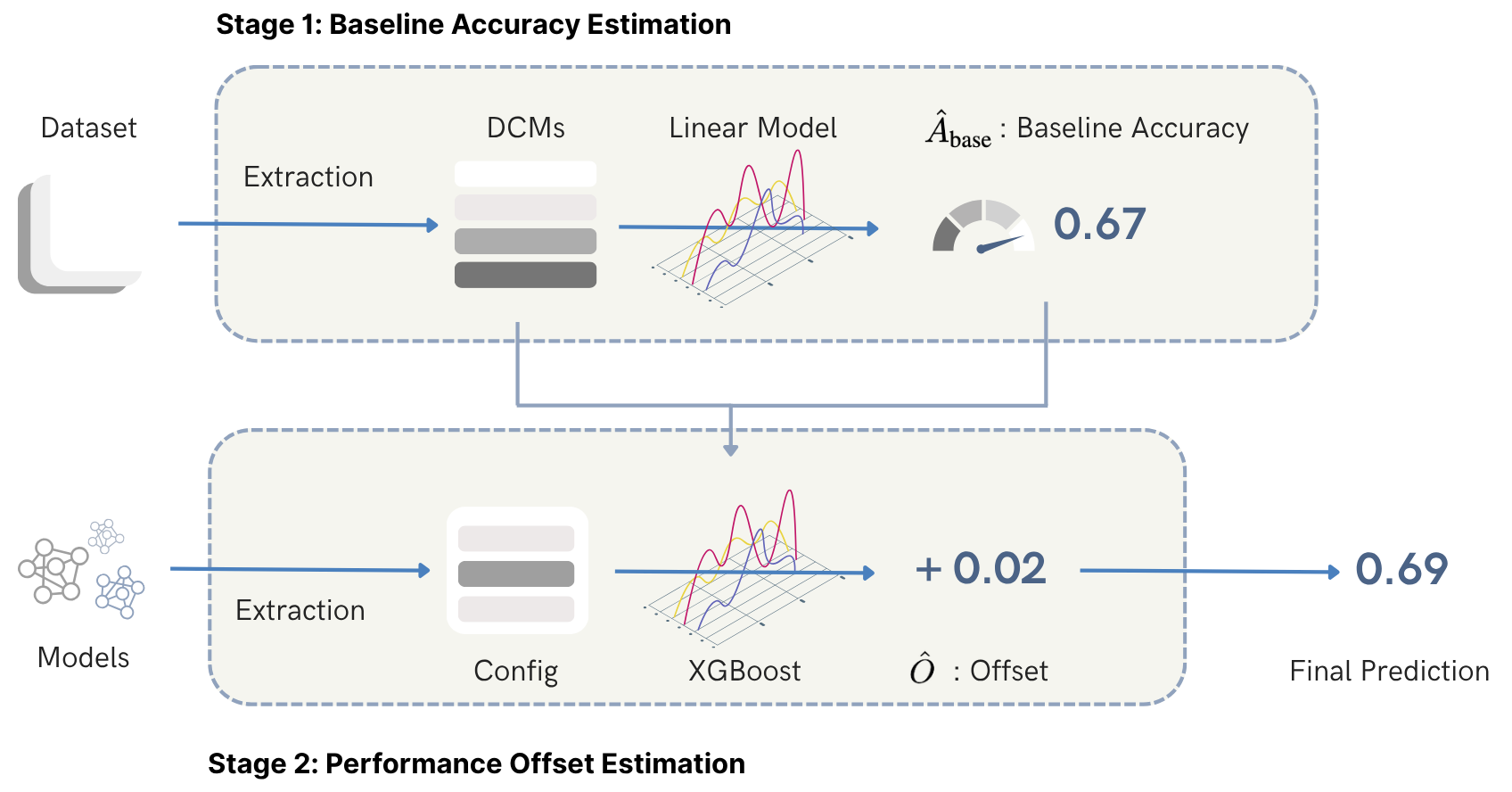
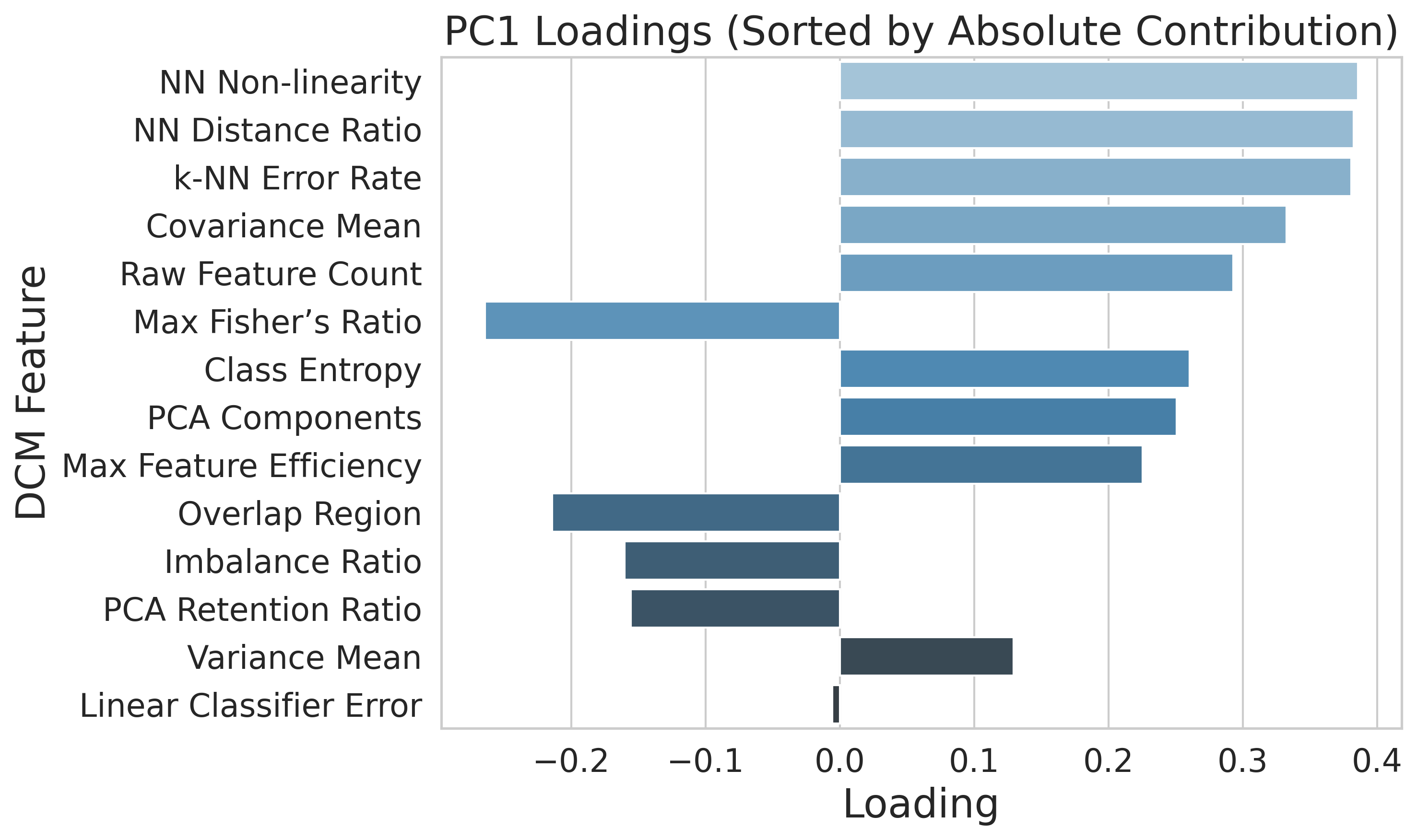
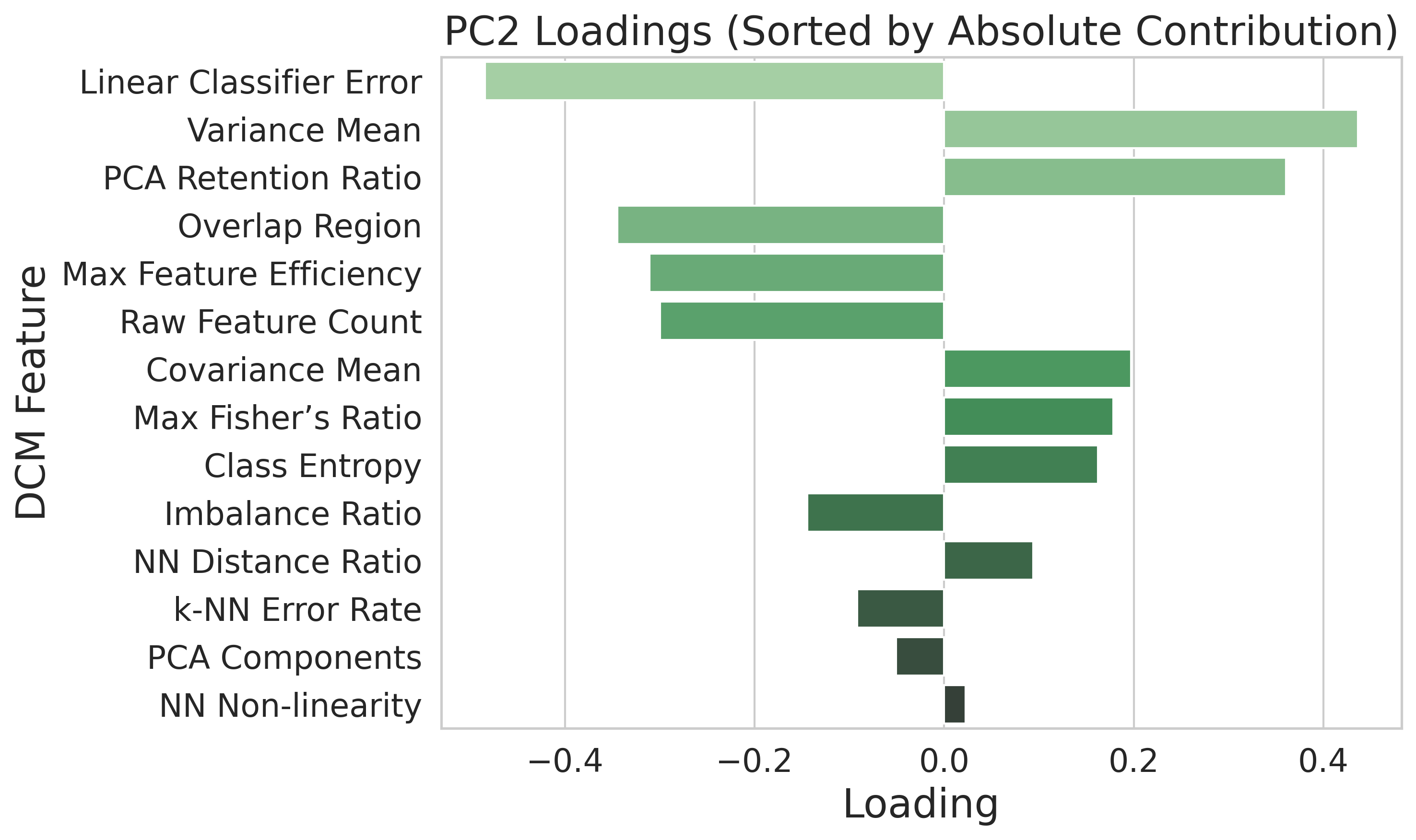
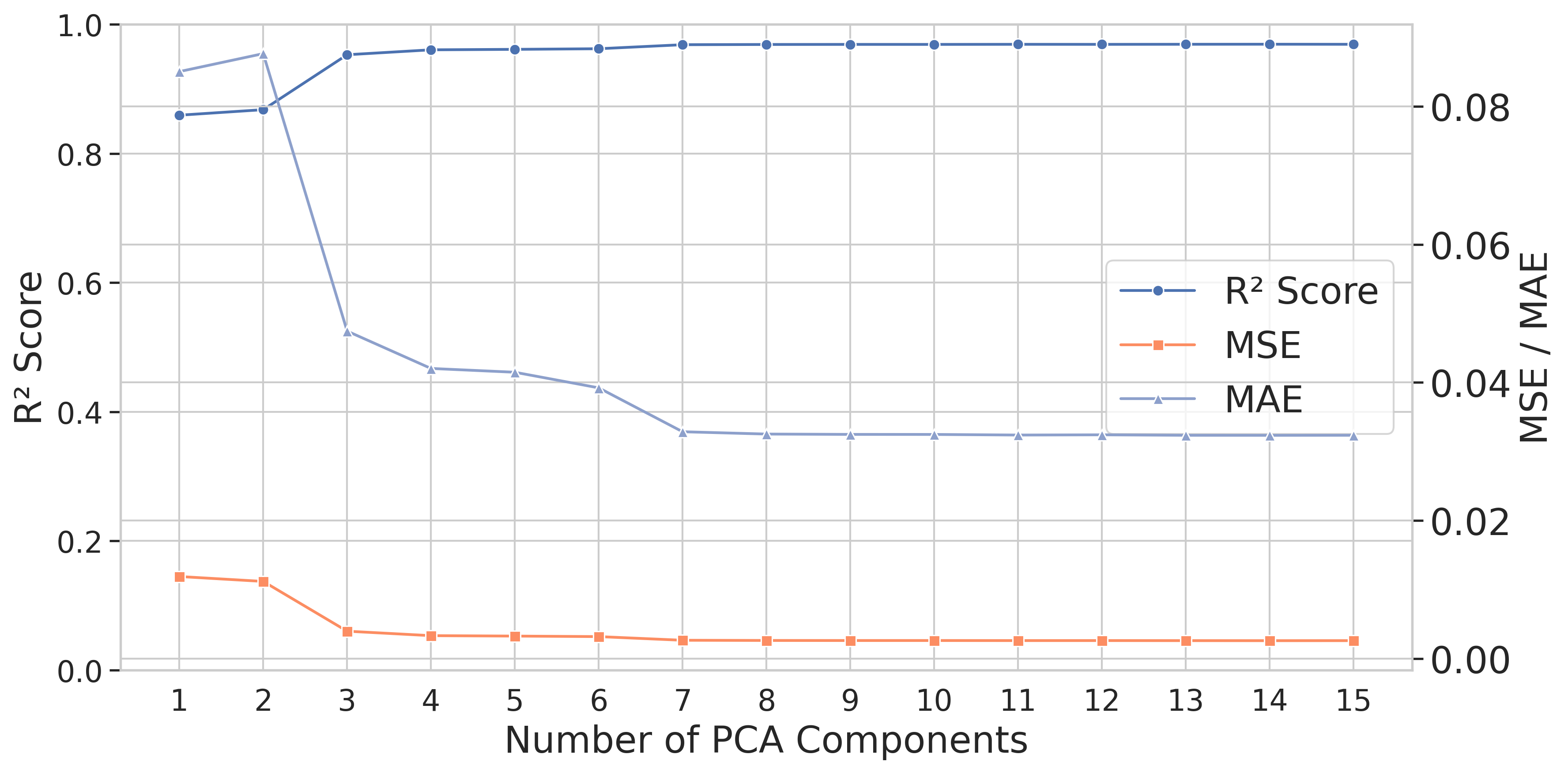
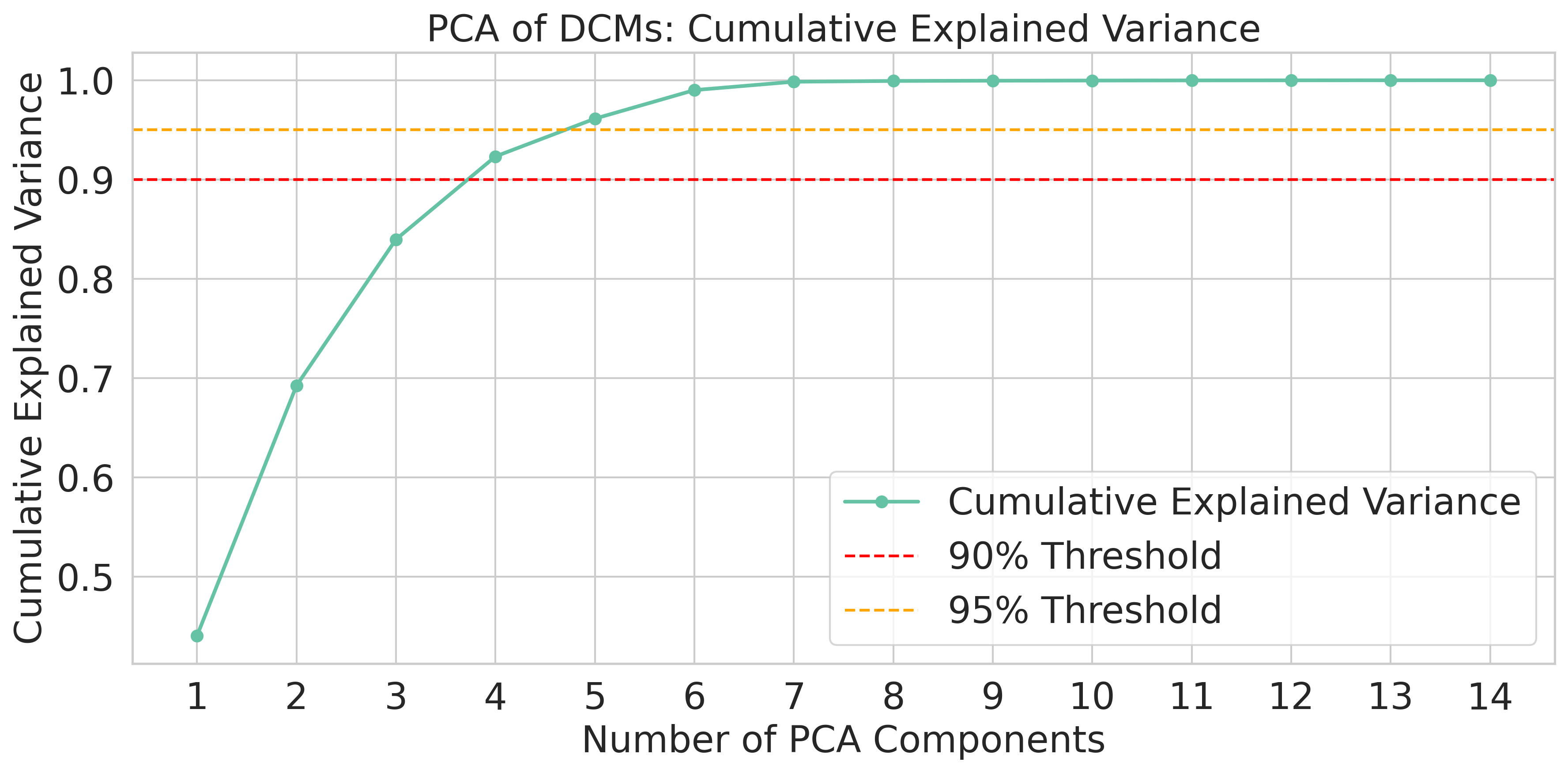
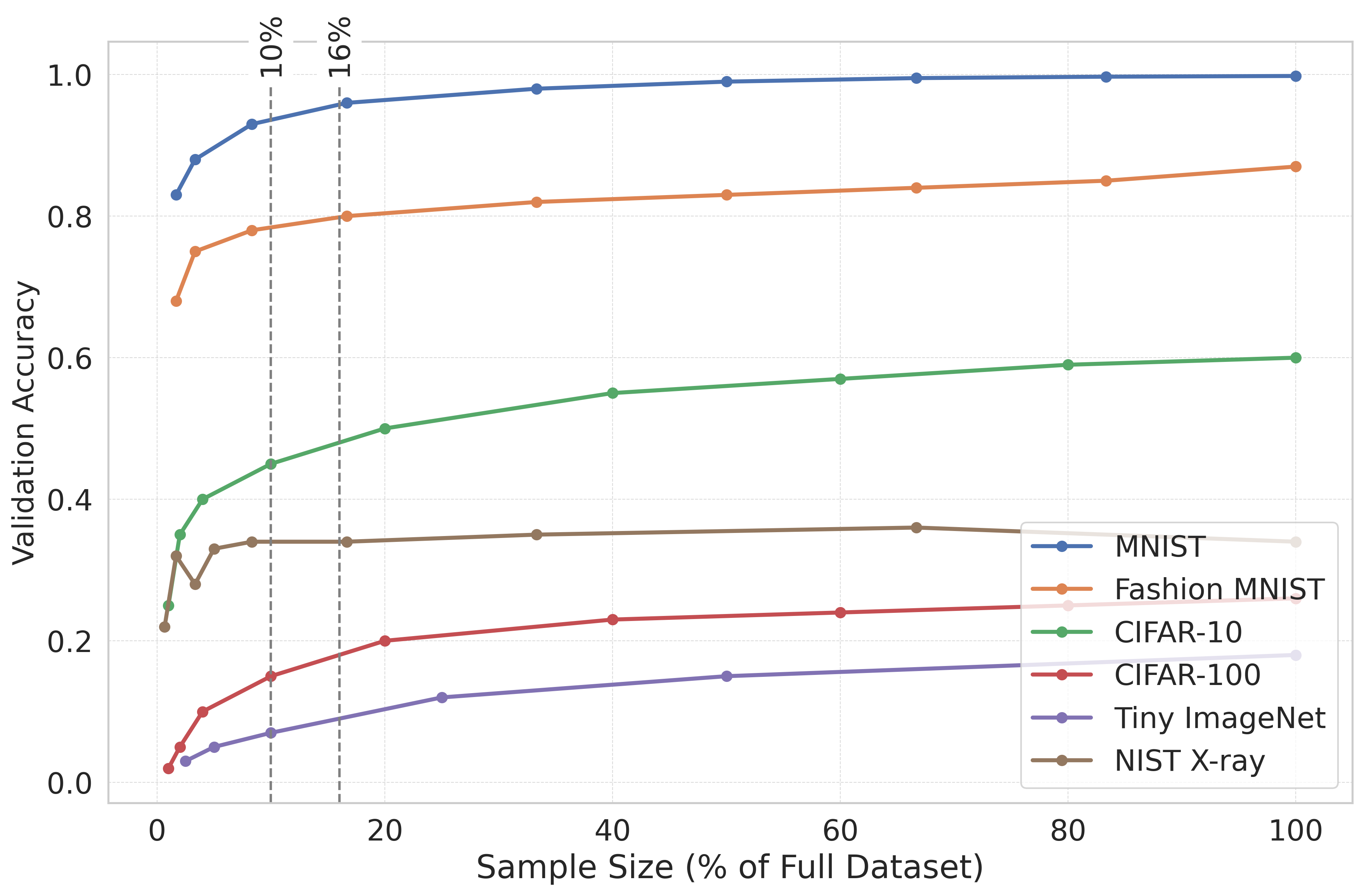
In this paper, we propose an efficient two-stage framework to predict model’s performance before its formal training given a dataset and the chosen learning model. The novel design in the framework is to separate the predictive problem into two stages. The first stage is to estimate how difficult the dataset is. The more difficult the dataset is, the harder for a deep model to output accurate prediction on the data. The data difficulty may imply highly overlapped regions between data that own different labels in the supervised sense, or between different groups of data in the unsupervised sense. Other difficulty may have non-smooth decision boundaries between data that own different characteristics, or data may contain latent features. The data difficulty surely can influence the performance of whatever chosen deep model that may be applied to the dataset. In the first stage, we use a set of predefined complexity measures to estimate a baseline performance level based on the dataset characteristics alone.
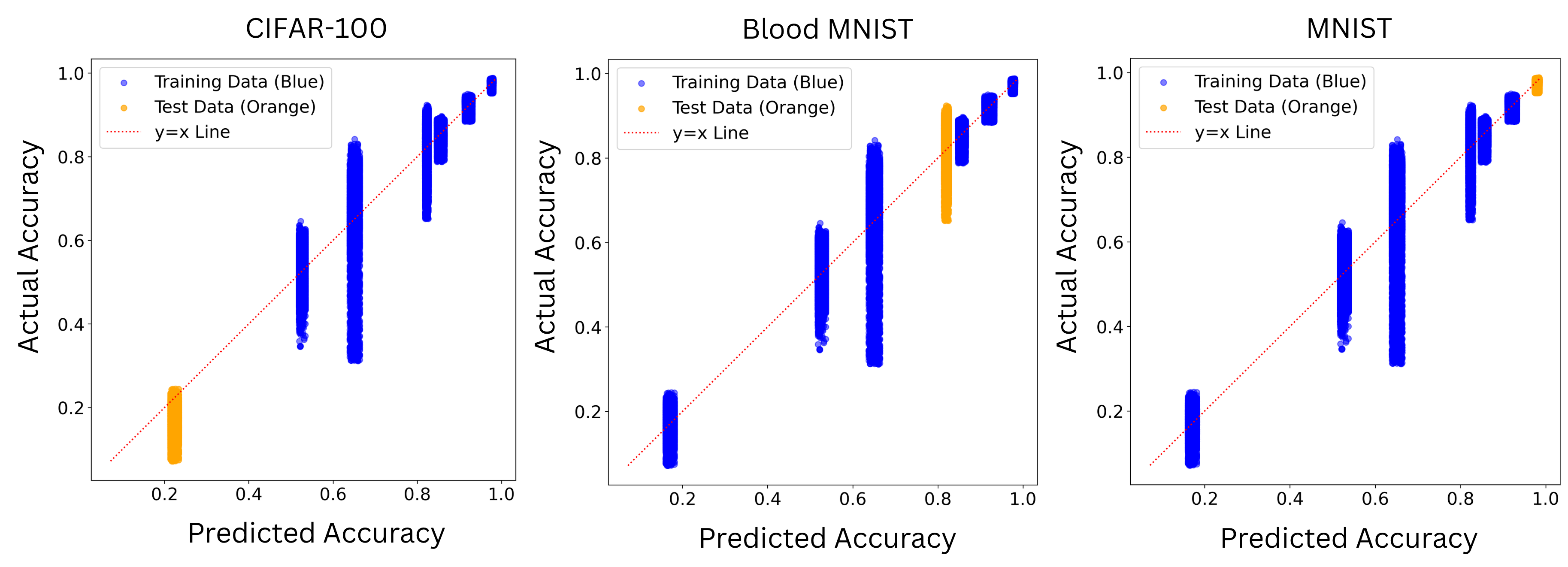
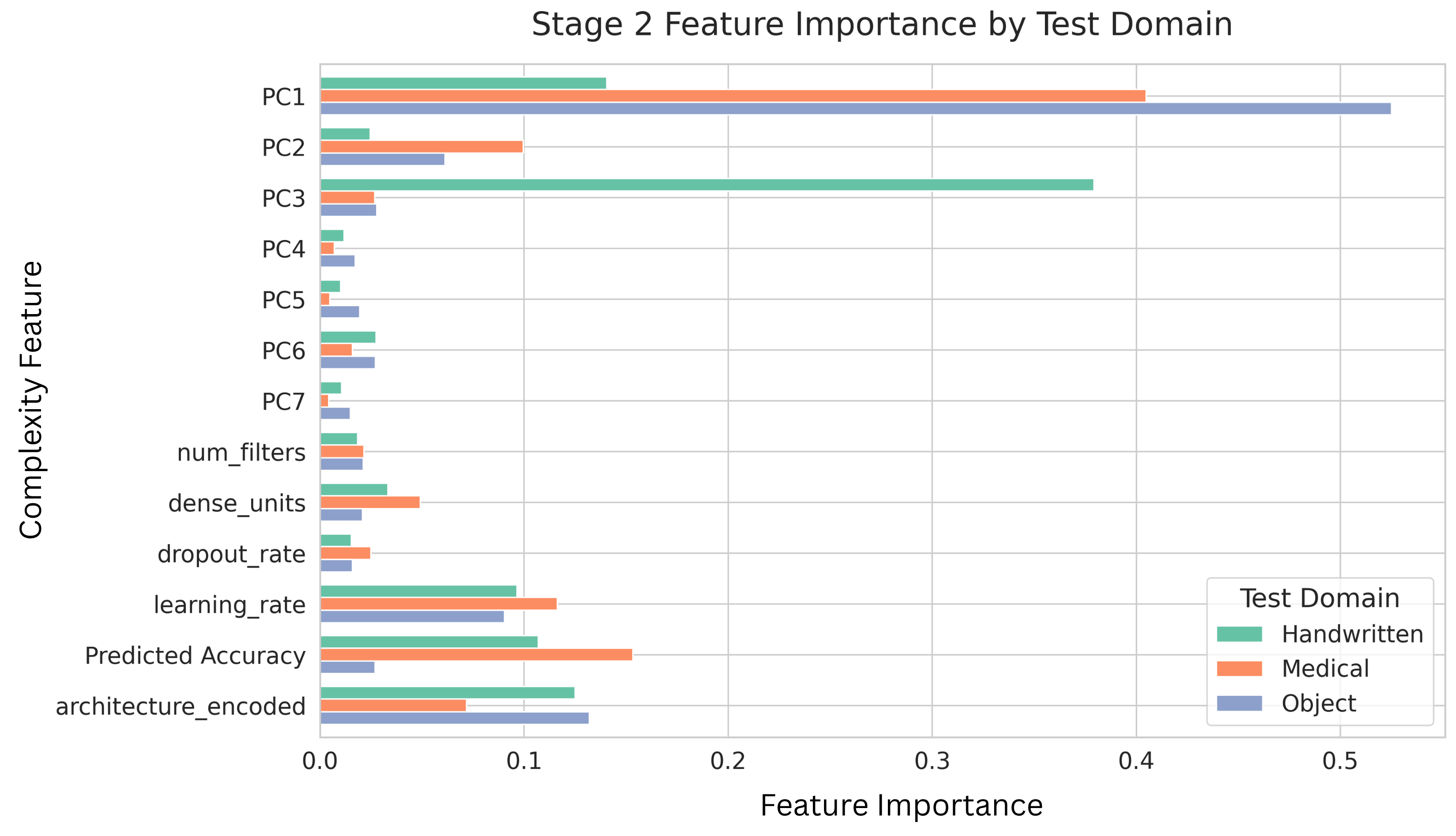
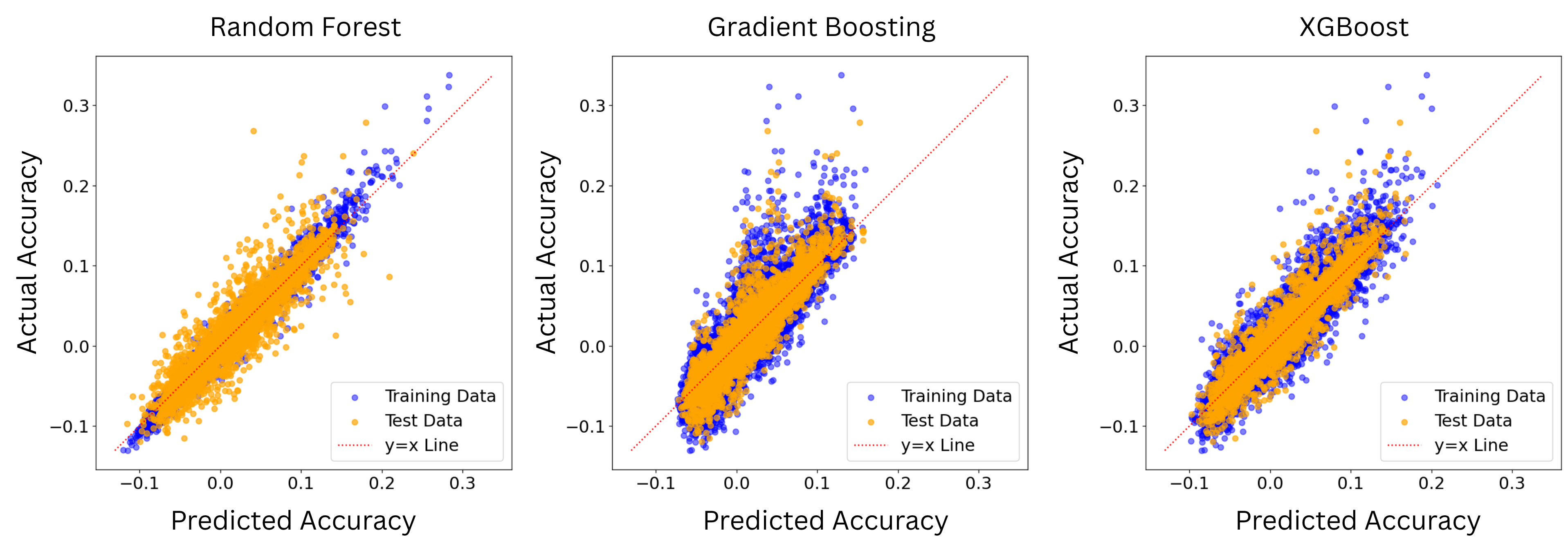
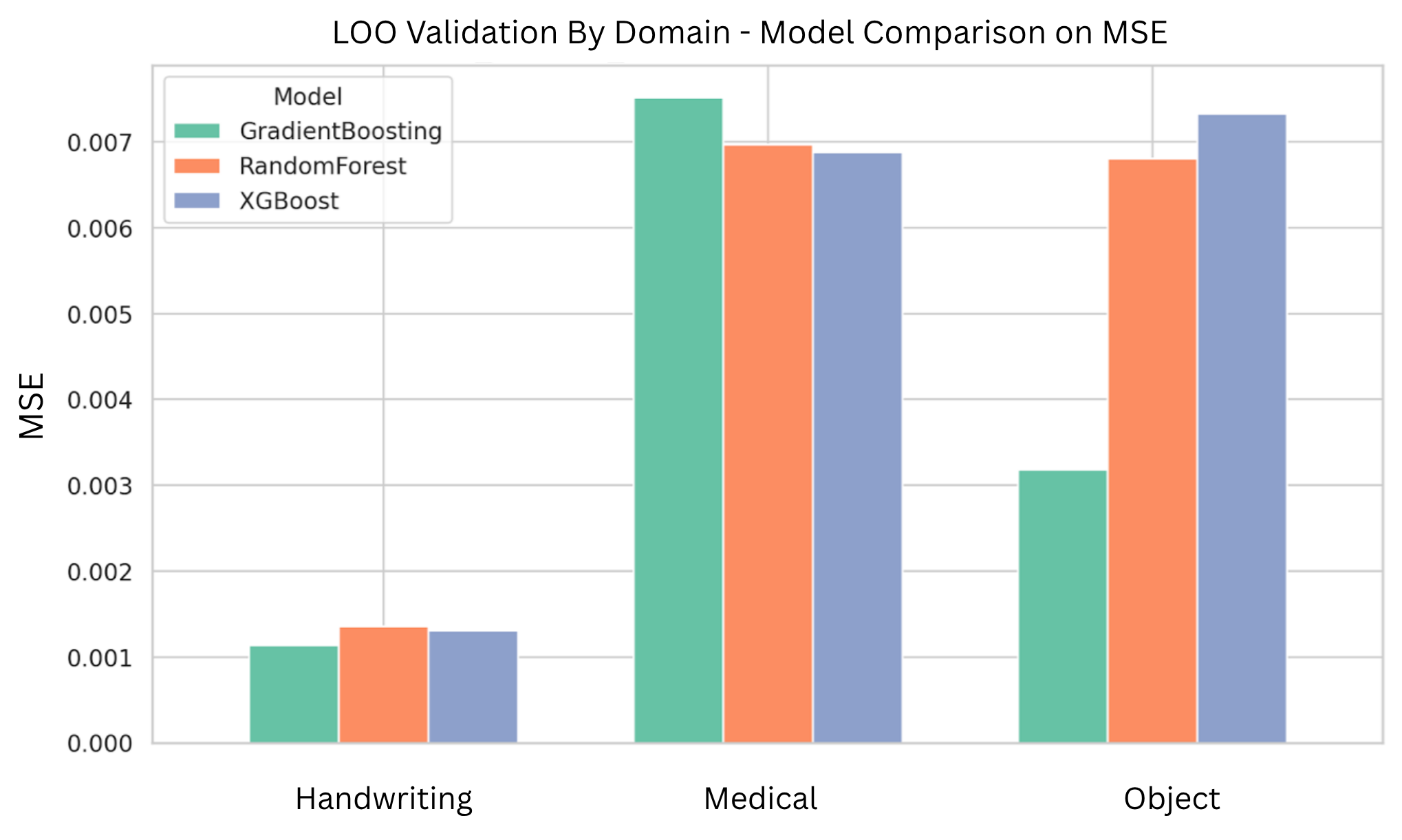
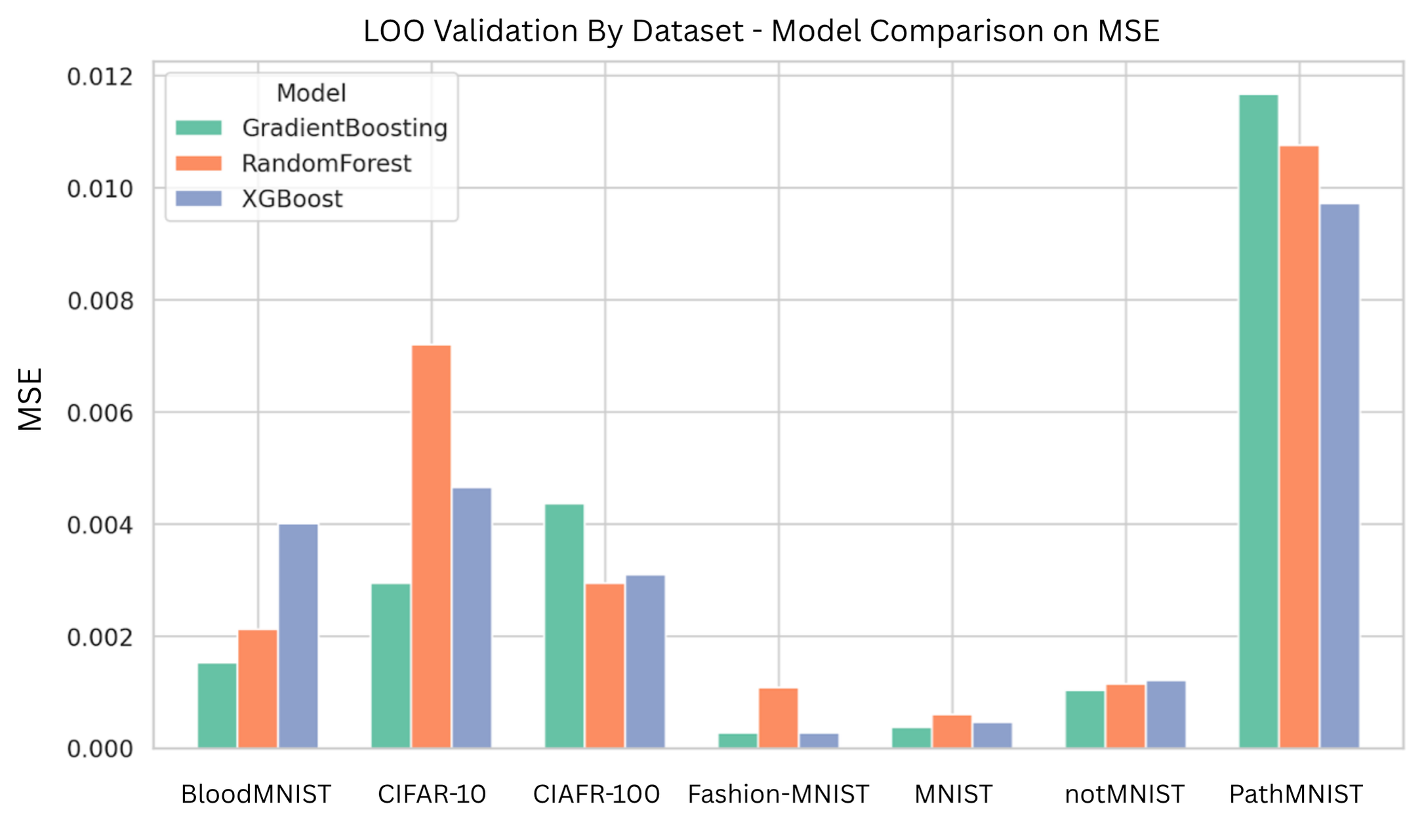
The second stage is to confirm the model performance prediction result once the deep model architecture is decided. Given the baseline prediction from the first stage, we may have certain deviation for different chosen deep models. Therefore, we confirm how much offset from the baseline prediction is once the deep model is chosen or the deep architectures are decided. Compared to the one stage designation, the proposed decomposed framework reflects two types of factors that may have impact on the model’s performance. The dataset difficulty governs the first-order performance and it well captures the dataset characteristics that may influence the deep model performance, while the model’s architecture and hyperparameters may contribute the higher-order, and conditional deviations that should be handled by a nonlinear learner. We describe these components and their empirical support in Section IV-B.
We summarize the key properties and contributions in this work as follows:
• A Two-Stage Predicti
This content is AI-processed based on open access ArXiv data.