We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 7.2M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven posttraining framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of dataalgorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset-Open (excluding the private part, we release 5.3M and downsampled 1.6M versions) publicly available to support future research in the open-source community.
In the past years, large language models (LLMs) like OpenAI's o1 series (Jaech et al., 2024), QwQ (Qwen-Team, 2025), and DeepSeek-R1 (Guo et al., 2025a) have demonstrated strong performance on challenging reasoning tasks in the field of mathematics and broader STEM. The reasoning capabilities in these models typically emerge from post-training techniques such as supervised fine-tuning (SFT) and/or reinforcement learning (RL) based on strong foundation models. However, while many models are open-sourced, the underlying post-training pipeline and training data curation remain undisclosed, creating both challenges and opportunities for future work.
More recently, the open-source community has made substantial efforts to develop dataconstruction recipes and algorithmic strategies for cultivating advanced reasoning capabilities in small-scale models, leading to a series of notable works such as Klear-Reasoner (Su et al., 2025), Ring-Lite (Ling-Team et al., 2025), MiMo (Xiaomi, 2025), OpenThoughts (Guha et al., 2025), Llama-Nemotron (Bercovich et al., 2025), and AceReason-Nemotron Liu et al. (2025b), among others (Fu et al., 2025;Luo et al., 2025;Wen et al., 2025a). However, despite these empirical successes, the community still lacks a unified framework to guide data curation and exploitation through post-training algorithms. It is widely recognized in the LLM community that “data is the new oil”, and the algorithm can only succeed when it effectively captures the desired data distribution. This motivates a central question in training reasoning models:
What does it take to build a Data-algorithm Co-design Engine for Reasoning Models in terms of Effectiveness, Efficiency, and Scalability?
In this report, we address this question from both theoretical and engineering perspectives. We first provide a data-centric view of the widely adopted SFT-RL pipeline (Ouyang et al., 2022) by framing it as a distribution-matching problem. We hypothesize that the first-stage SFT builds a strong proposal distribution that one draws samples for following usage; and the second stage post-training, no matter SFT or RL, shifts the model towards a gold-standard target distribution behind desirable properties such as reasoning ability.
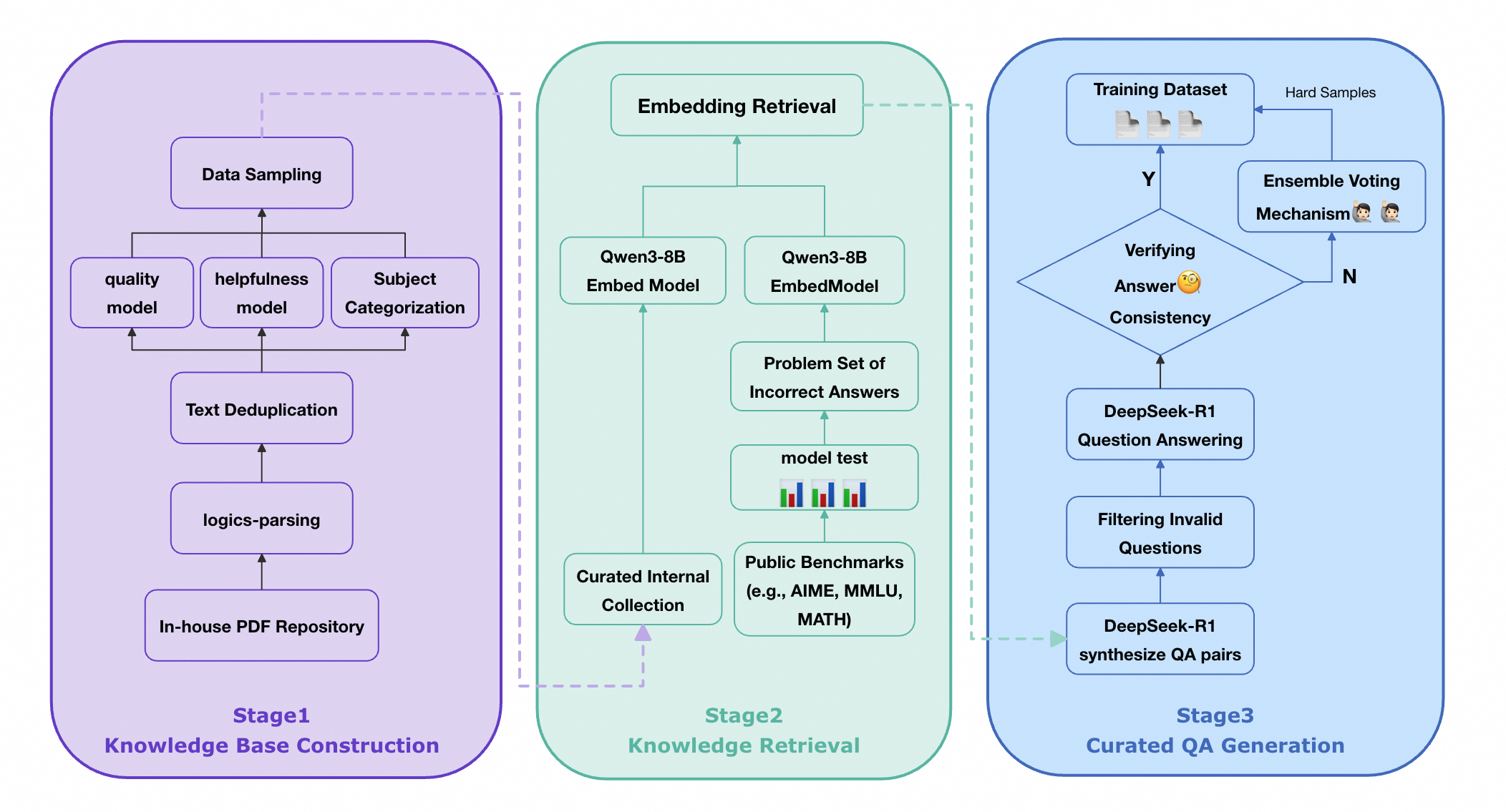
Building on this formulation, we push the boundaries of reasoning models by: (i) implementing a rigorous data curation pipeline to produce a scalable, broad-coverage, and high-quality long CoT dataset as a foundational proposal distribution; (ii) designing an optimized posttraining pipeline that utilizes the curated data effectively and efficiently to improve the model’s reasoning capabilities.
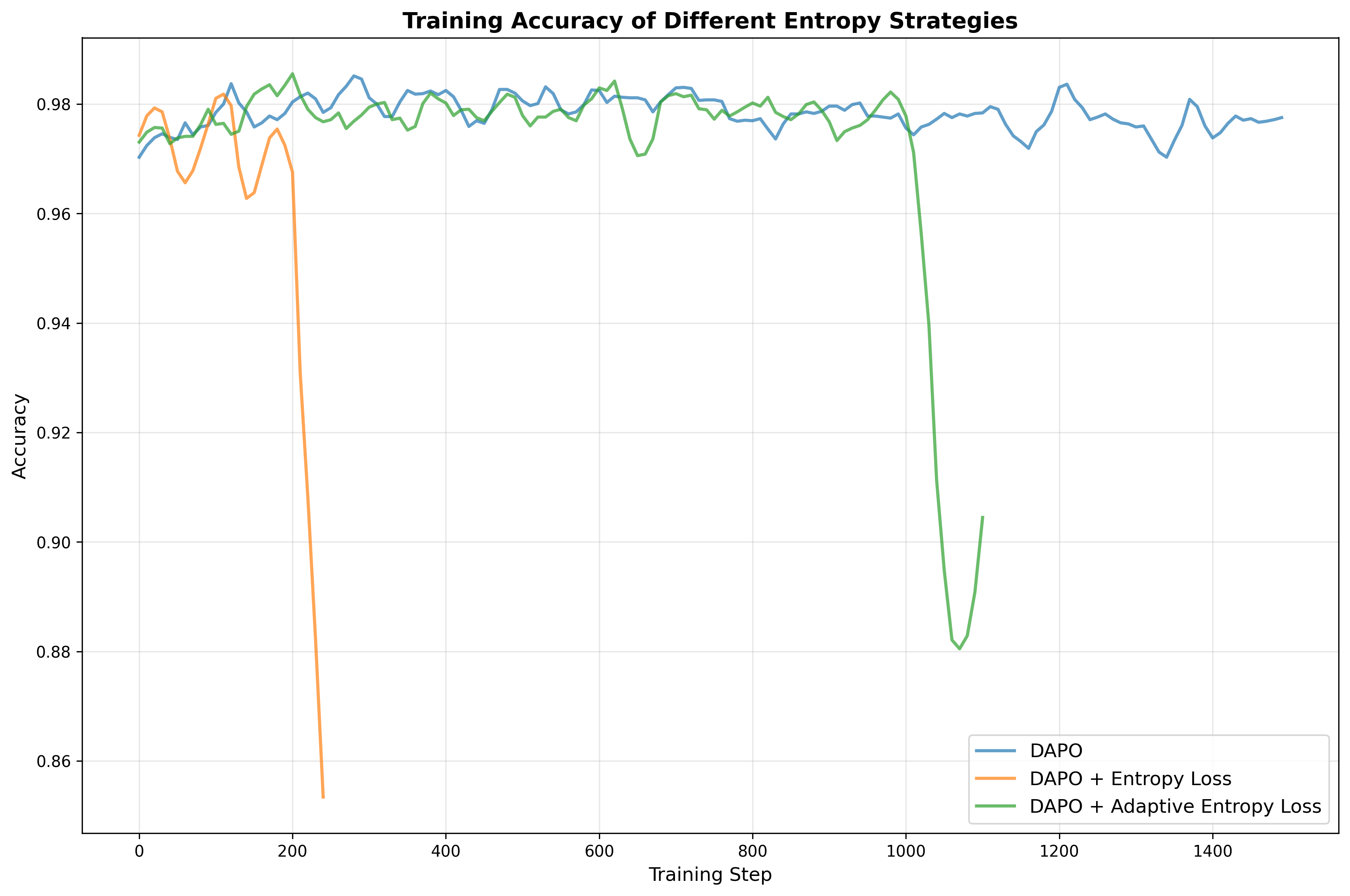
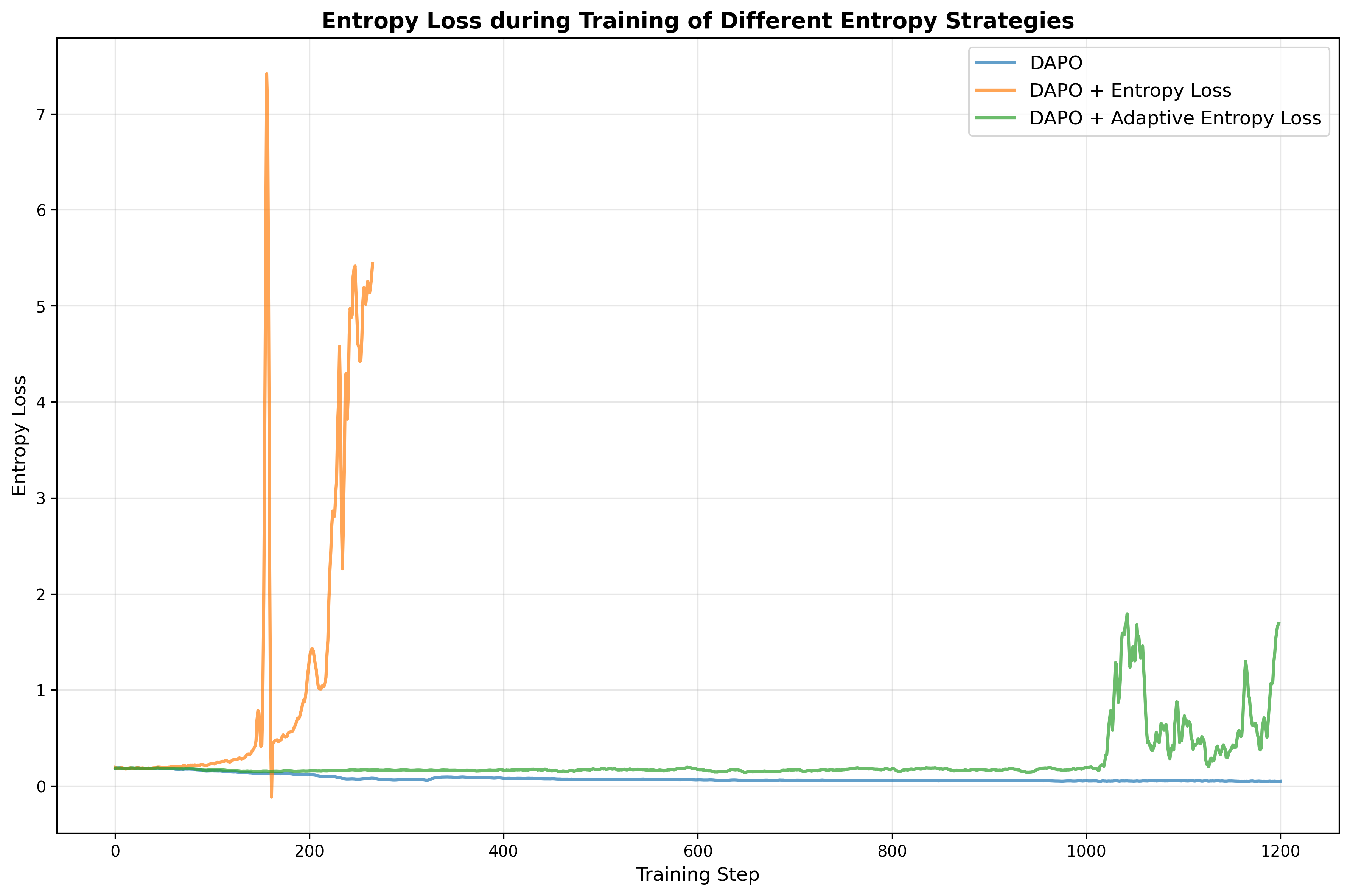
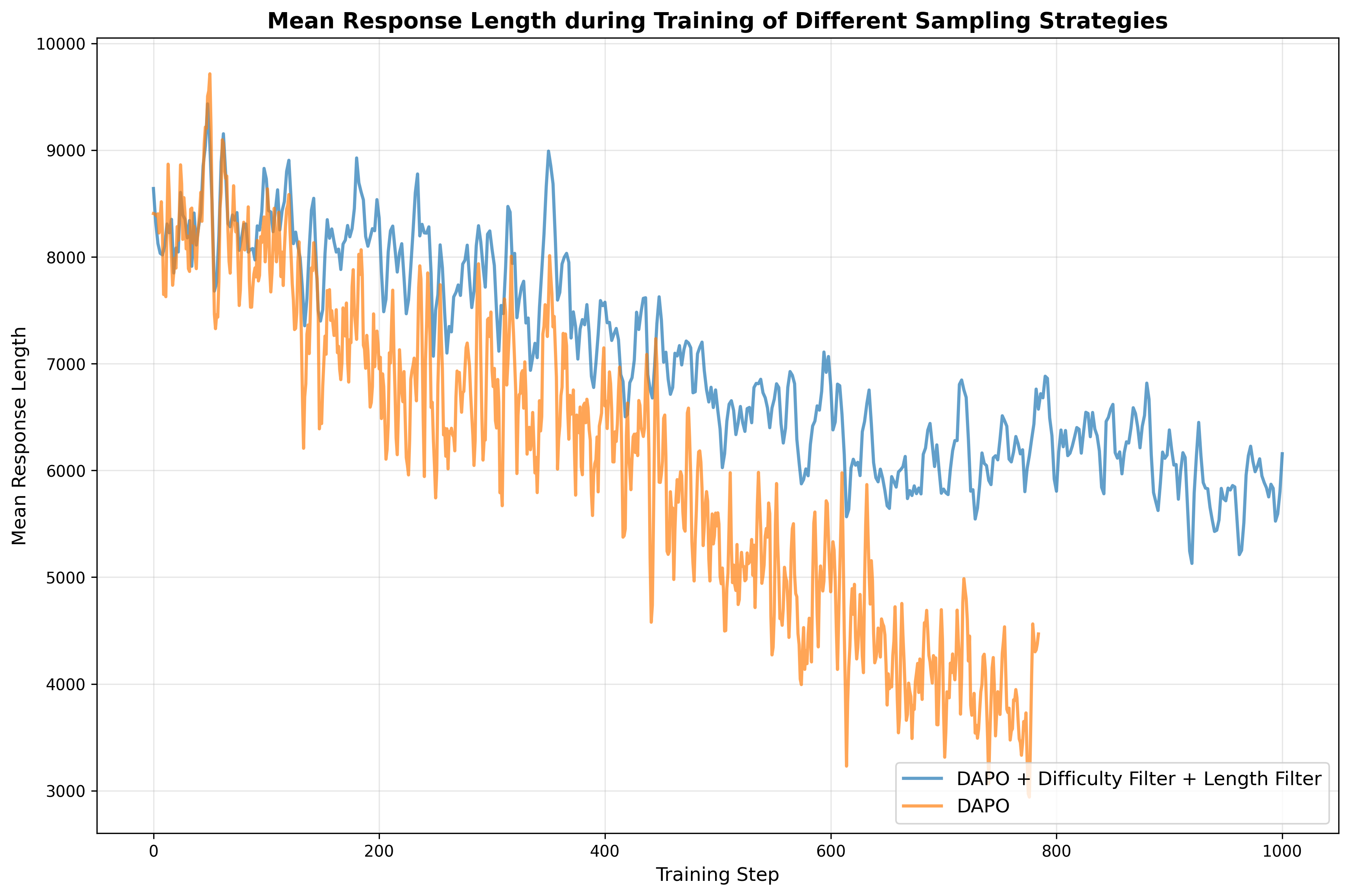
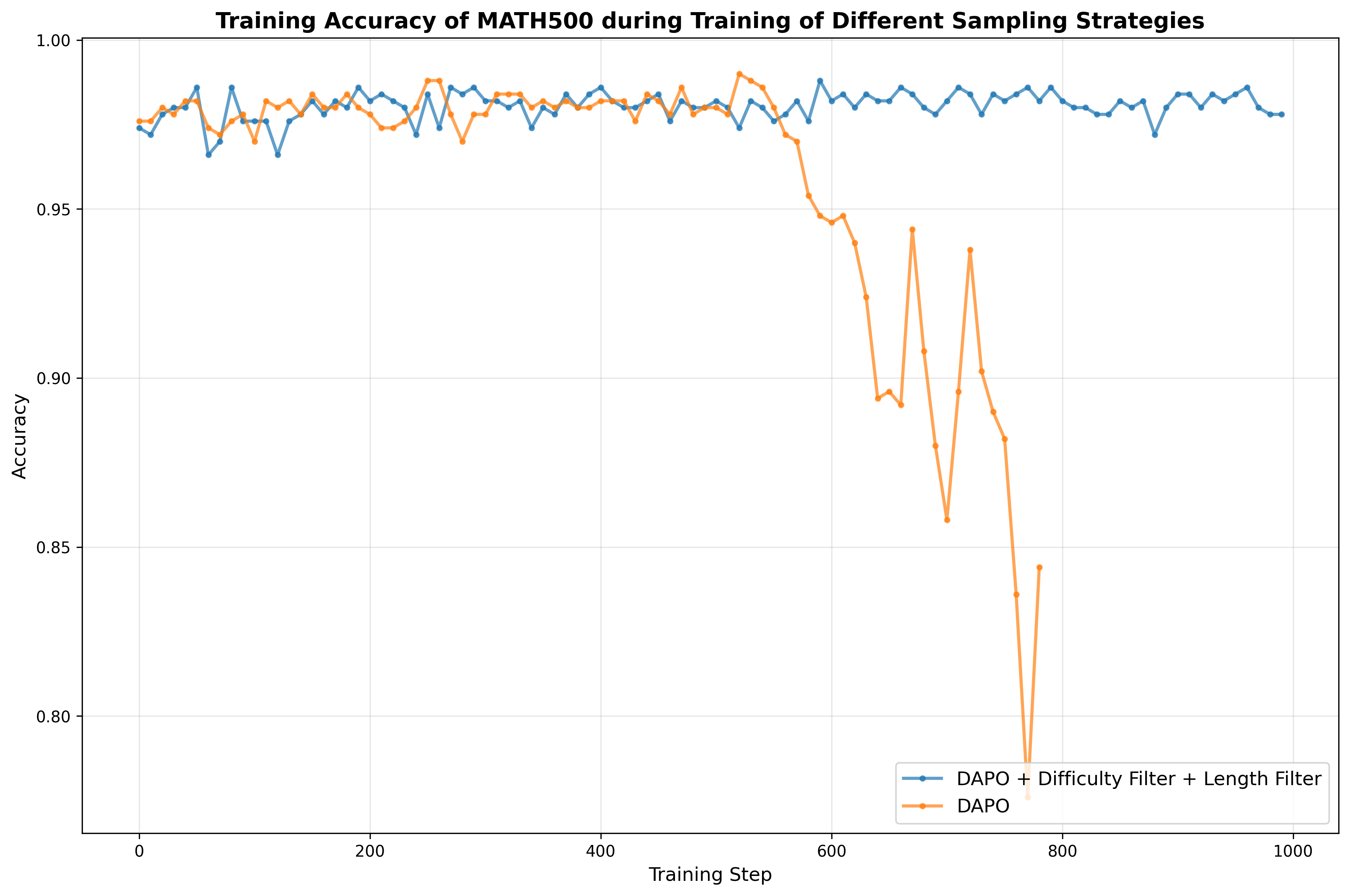
Specifically, we curate reasoning data from publicly available datasets and further augment it with synthetic examples generated from documents parsed by Logics-Parsing (Chen et al., 2025a). Coupled with a fine-grained, difficulty-aware stratified sampling strategy, extensive experiments show that our curated Logics-STEM-SFT-Dataset already equips LLMs with strong foundational reasoning capabilities. Moreover, we adopt a failure-driven post-training paradigm to further align the model with the gold-standard reasoning distribution. Concretely, after the first-stage SFT, we perform targeted knowledge retrieval and synthesize data around the model’s failure regions to guide a second-stage SFT or RL. This yields two alternative pipelines: SFT-RL and SFT-SFT. We systematically test our method under both SFT-RL and SFT-SFT pipelines and show that our approach substantially improves the model’s reasoning ability.
Consequently, we present Logics-STEM, a reasoning model finetuned from Qwen3 that achieves outstanding performance on multiple key reasoning benchmarks. At 8B scale, as shown in fig. 1, Logics-STEM-8B outperforms Klear-Reasoner-8B, DeepSeek-R1-0528-Distill-8B and Qwen3-8B, scoring 90.42% on AIME2024, 87.08% on AIME2025, 74.79% on HMMT2025, 62.5% on BeyondAIME and 73.93% on GPQA-Diamond.
In summary, the contributions of our work are listed as follows.
• We formulate the SFT-RL pipeline as a distribution matching problem and design a failuredriven post-training framework that leverages targeted knowledge retrieval and data synthesis around model failure regions to effectively and efficiently guide SFT and RL. • We design a data curation engine that effectively utilizes publicly available data and augments it with synthetic examples generated from documents. We then produce Logics-STEM-SFT-Dataset, a high-quality and diverse dataset that represents one of the largest-scale open-source long chain-of-thought corpora at 10M scale. • Our reasoning model, Logics-STEM, outperforms other open source models of comparable size on STEM reasoning benchmarks. We release Logics-STEM (8B and 32B) at both the SFT and RL stages, along with the open version of Logics-STEM-SFT-Dataset, to support further research and development within the open-source community.
After pre-training, SFT followed by RL has become a widely ad
This content is AI-processed based on open access ArXiv data.