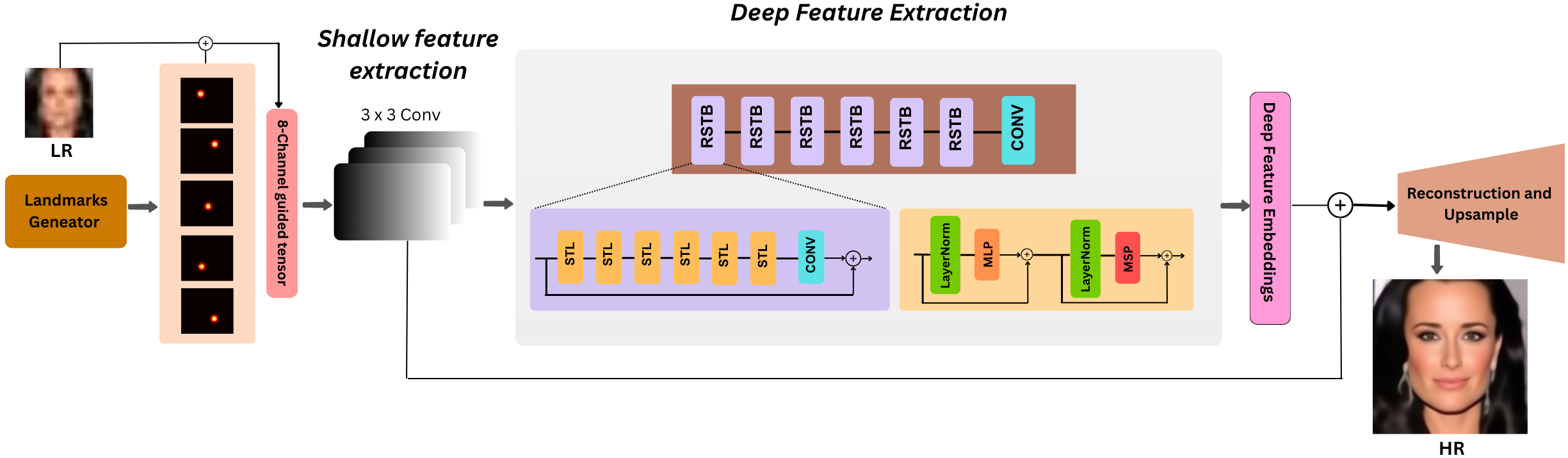
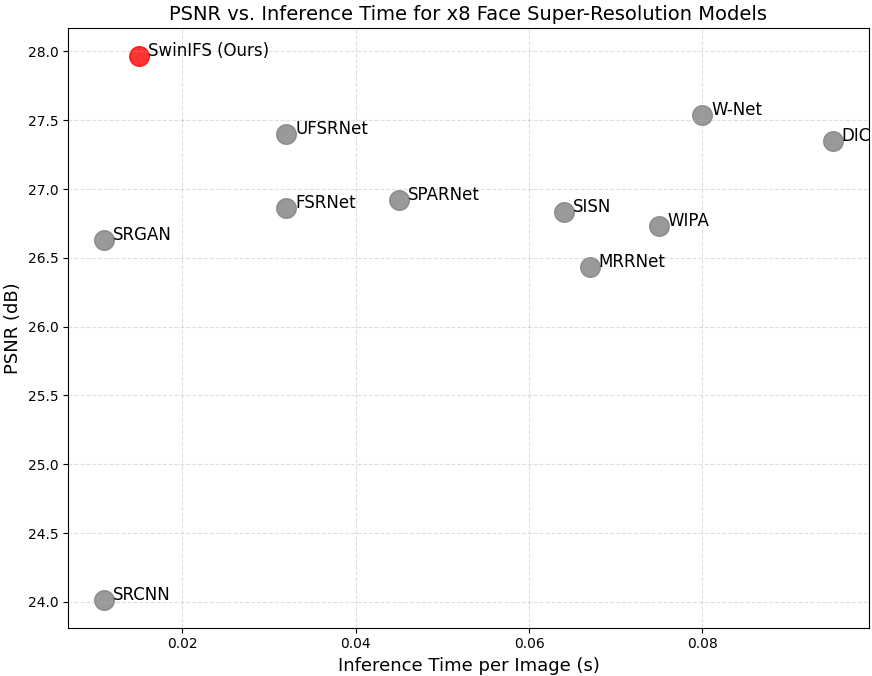
Face super-resolution aims to recover high-quality facial images from severely degraded low-resolution inputs, but remains challenging due to the loss of fine structural details and identity-specific features. This work introduces SwinIFS, a landmark-guided super-resolution framework that integrates structural priors with hierarchical attention mechanisms to achieve identity-preserving reconstruction at both moderate and extreme upscaling factors. The method incorporates dense Gaussian heatmaps of key facial landmarks into the input representation, enabling the network to focus on semantically important facial regions from the earliest stages of processing. A compact Swin Transformer backbone is employed to capture long-range contextual information while preserving local geometry, allowing the model to restore subtle facial textures and maintain global structural consistency. Extensive experiments on the CelebA benchmark demonstrate that SwinIFS achieves superior perceptual quality, sharper reconstructions, and improved identity retention; it consistently produces more photorealistic results and exhibits strong performance even under 8× magnification, where most methods fail to recover meaningful structure. SwinIFS also provides an advantageous
Face super-resolution (FSR) aims to reconstruct high-resolution (HR) facial images from low-resolution (LR) inputs while preserving structural coherence and identityspecific details. Reliable recovery of facial features is essential for applications such as surveillance, biometrics, forensics, video conferencing, and media enhancement [1,2]. Unlike generic super-resolution [3,4], FSR benefits from the strong geometric regularity of human faces, where the spatial arrangement of key components (eyes, nose, mouth) provides valuable prior information for reconstruction. The LR observation process is typically modeled as
where I HR is the HR image, I LR is the LR image, k denotes the blur kernel, ↓ s is the downsampling operator, and η represents noise. In practical environments, degradation is further compounded by compression artifacts, illumination variations, and sensor noise. At moderate upscaling factors (e.g., 4×), some structural cues remain; however, at extreme scales (e.g., 8×; 16× inputs), most identity cues are lost, rendering the reconstruction highly ill-posed.
Early face hallucination methods relied on interpolation, example-based patch retrieval, or sparse coding [5]. Although pioneering, these approaches produced overly smooth results and lacked robustness to domain variation. The introduction of deep learning significantly advanced SR performance. CNN-based methods [6][7][8] improved texture reconstruction but remained limited by their local receptive fields, often leading to globally inconsistent facial structures.
Generative adversarial networks (GANs) improved perceptual realism by learning to synthesize sharper textures [9]. FSRNet [10] and Super-FAN [11] demonstrated that combining GAN objectives with facial priors such as landmarks or parsing maps enhances structural alignment. However, GAN-based methods are susceptible to hallucinating unrealistic details and may compromise identity preservation, especially when LR inputs are highly degraded.
Transformer architectures have recently emerged as powerful tools for image restoration due to their ability to capture long-range dependencies through selfattention [12,13]. The Swin Transformer [14] introduces hierarchical window-based attention, offering an effective balance of global modeling and computational efficiency. Despite their strengths, Transformers alone struggle when key facial cues are absent in severely degraded inputs. Incorporating explicit geometric priors can alleviate this ambiguity.
Facial landmarks provide compact, reliable structural information about the geometry of key facial regions. When encoded as heatmaps, they supply spatial guidance that helps maintain feature alignment, facial symmetry, and identity consistency during reconstruction [10,15]. Motivated by these insights, this work proposes a landmark-guided multiscale Swin Transformer framework designed to address both moderate (4×) and extreme (8×) FSR scenarios.
Our proposed method fuses RGB appearance information with landmark heatmaps to jointly model facial texture and geometry. The Swin Transformer backbone captures global contextual relationships, while landmark priors enforce structural coherence. This unified approach enables robust reconstruction across multiple upscaling factors and significantly improves identity fidelity. Experiments on CelebA demonstrate that the proposed framework achieves superior perceptual quality, structural accuracy, and quantitative performance compared to representative CNN, GAN, and Transformerbased baselines.
Face super-resolution has evolved significantly over the past two decades, transitioning from early interpolation schemes to modern deep learning, adversarial, and transformer-based frameworks. Unlike generic single-image super-resolution (SISR), FSR requires strong preservation of identity and facial geometry, making structural modeling a core research challenge [10,16].
Early work relied on interpolation and example-based methods [17,18]. Although computationally efficient, these approaches produced overly smooth textures and failed to recover high-frequency facial details. Learning-based extensions, including sparse coding and manifold models [5,19], partially improved texture synthesis but struggled under severe degradation and exhibited limited generalization.
Deep learning significantly advanced FSR performance. CNN-based architectures such as SRCNN [6], VDSR [7], and EDSR [8] demonstrated that hierarchical feature learning could outperform traditional methods. Face-specific extensions, including FSRNet [10] and URDGN [10,20], incorporated structural priors, such as landmark heatmaps or facial parsing maps. These models improved alignment and structural consistency, but their reliance on pixel-wise losses often produced smooth outputs and limited high-frequency synthesis.
The introduction of GAN frameworks shifted the focus toward perceptual realism. SRGAN [9] demonstrated sharper textures using adversari
This content is AI-processed based on open access ArXiv data.