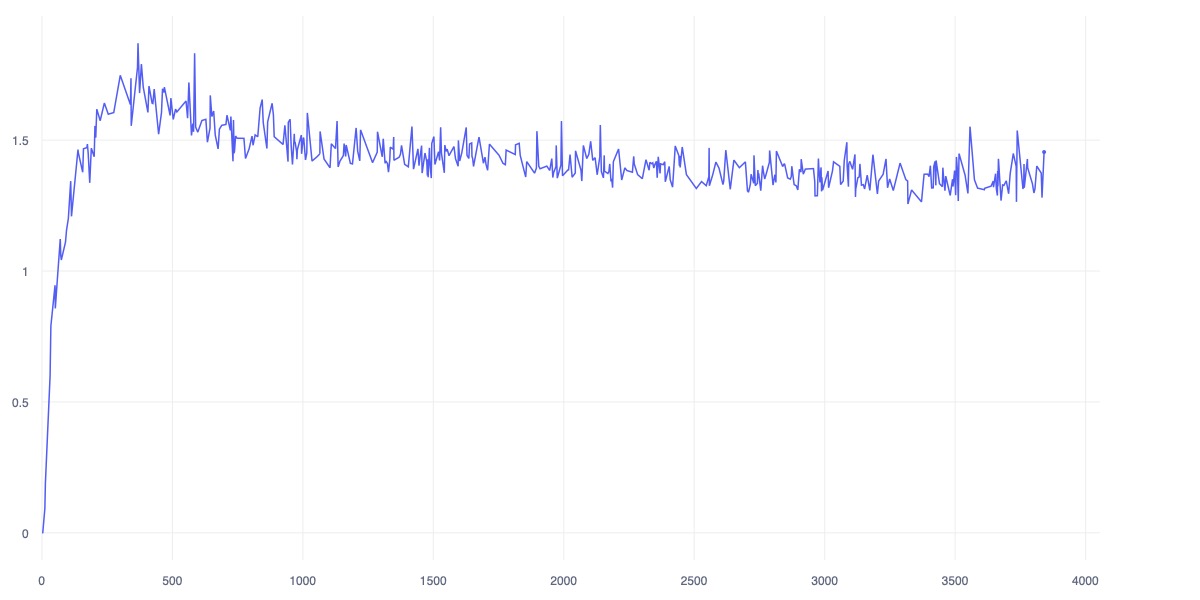
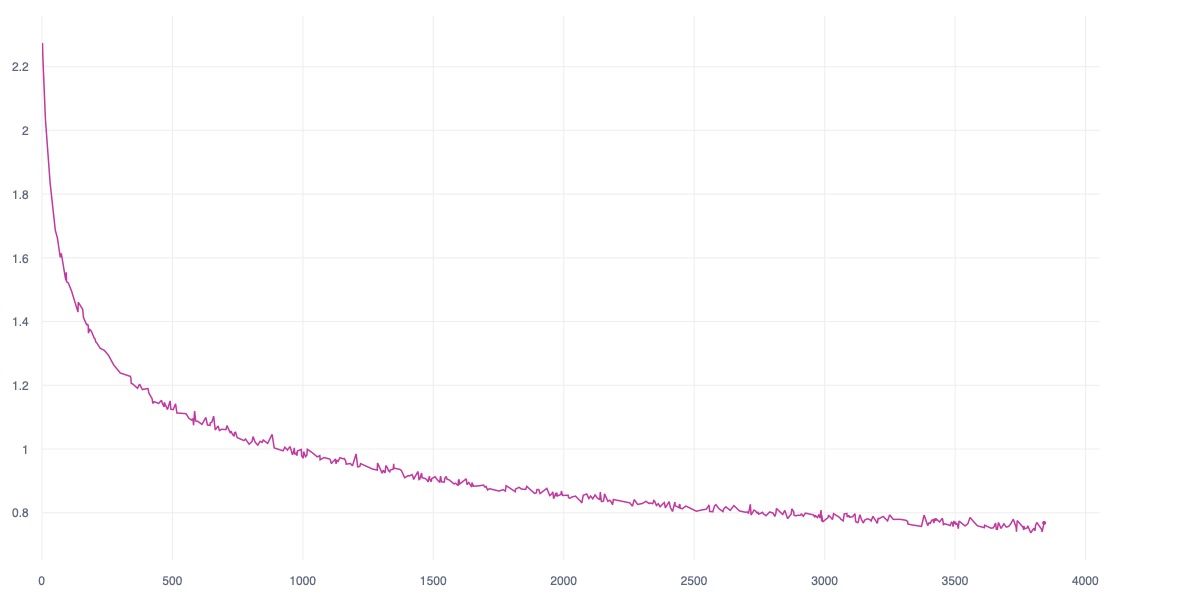
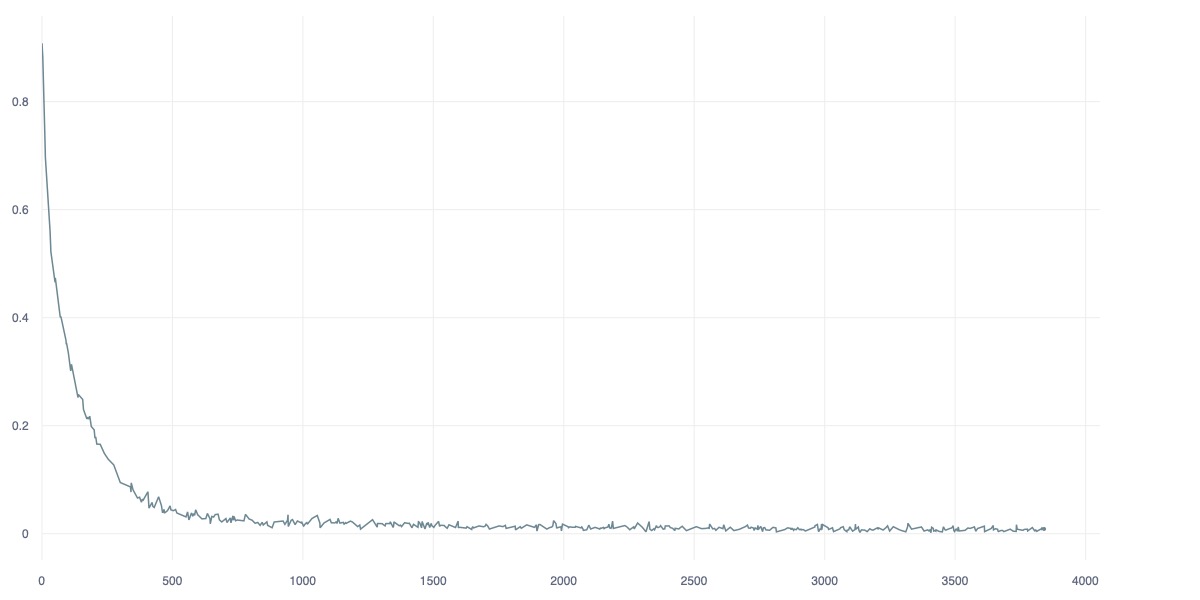
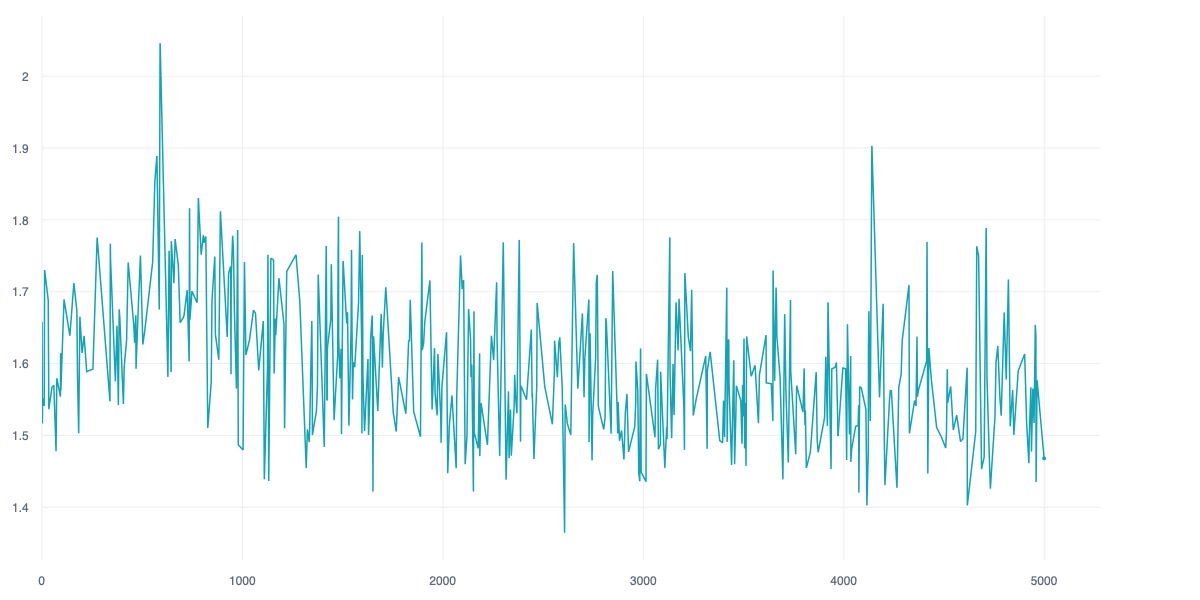
Current attempts of Reinforcement Learning for Autonomous Controller are data-demanding while the result are under-performed, unstable and unable to grapple and anchoring on the concept of safety, and over-concentrate on noise feature dues to the nature of pixel reconstruction. While current Self-Supervised Learning approachs that learning on high-dimensional representation by leveraging the Joint Embedding Predictive Architecture (JEPA) is interesting and effective alternative, as the idea is mimicking the natural of human's brain in acquiring new skill using imagination and minimal sample of observations. This study introduces Hanoi-World, a JEPA-based world model that using recurrent neural network (RNN) for making longterm horizontal planning with effective inference time. Experiments conducted on Highway-Env package with difference enviroment showcase the effective capability of making driving plan while safety-awareness with considerable collision rate in comparison with SOTA baselines.
Since the first experiment on an Autonomous Vehicle (AV) was conducted in 1986 at Carnegie Mellon University [1], the research domain of developing self-driving vehicles has made significant progress, both in technical and practical applications in the real world. The vehicles are expected to operating safetly while handling the challenges of uncertainty, partial observability, and multi-agent enviroment (interaction between the ego-vehicle and the surroundings vehicles, and obstacle as pedestrians, etc.) [2,3]. However, as [4] suggest, these challenges does limit the feasibility on deploying and experimenting on such reinforced-learning based controller, and prior work only based on naive transfering paradigms from the physical-enviroment which lead to training instability dues to noise, and data-fragmentation [4][5][6].
From the technical perspective, the decision of AV have traditionally relied on simmulator for experience rollout, and the planning algorithms with reinforcement learning with the assumption of data-abundance as [7,8], whereas, the classical attempts -such as Monte Carlo Tree Search (MCTS) or belief-space planning under partially observable Markov decision processes (POMDPs) require massive computational overhead within the simmulator for experiment rolling-out without doing the policy training [9][10][11], while these method does offering for resolving the uncertainty, but the scalability is limited [12]. Additionally such rolling-out strategy tend to amplifying the error over-the-longtime horizon, and lead to the raise of the model inaccuracy [13,14]. Additionally, the observationlevel prediction tends to priortize the visual, and kinematic fidelity as the reconstruction challenge, which may not truely encapsulated the decision-relevant manifold, and leading to inefficencies in object control [15][16][17].
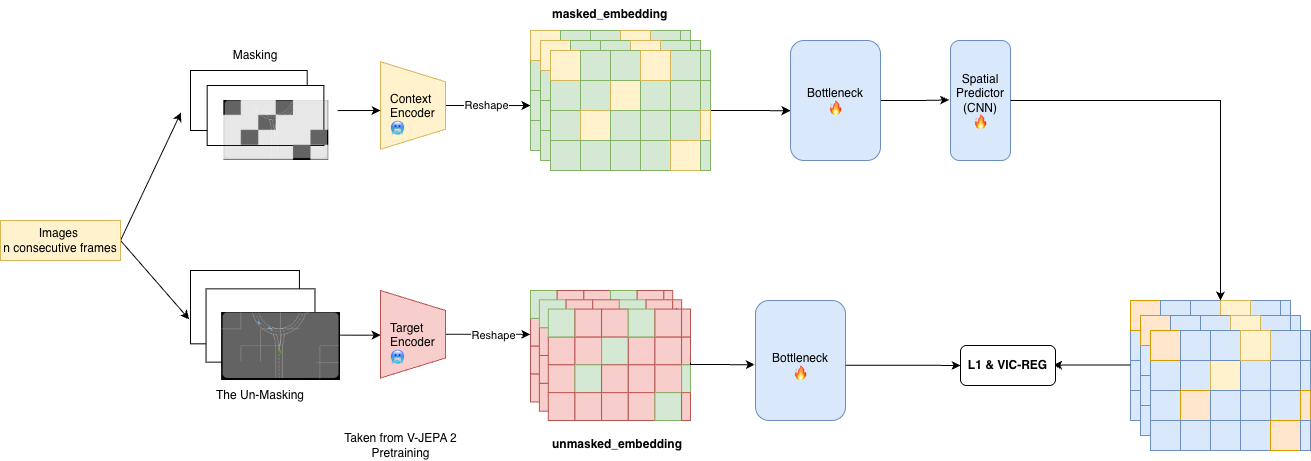
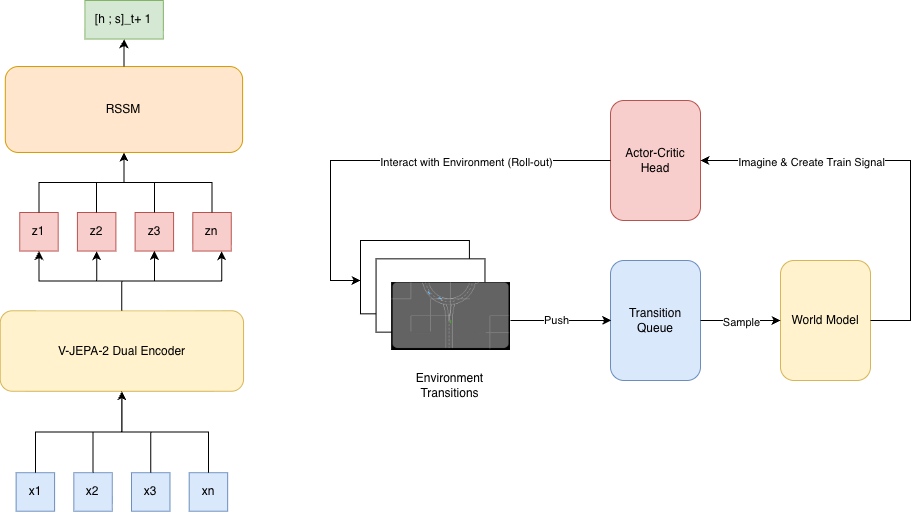
Inspiration from human’s capability of acquiring new skill as driving by leveraging the capability of imaginary on the plausible future scenario based on the current interaction with the enviroment -the affordance based theory, and human memory [17][18][19], which can be formalized into the model-designing implementation as using representation using the self-supervised learning paradigm for learning the enviorment dynamicity. Joint-Embedding Predictive Architectures (JEPA) propose learning latent spaces by directly predicting future representations, without reconstructing raw observations, but only structure alignment between encoder and enforcing the information variability, but not stochasticity on noise for preventing the embedding collaspe as [20]. State-of-the-art model as V-JEPA-2 extends the idea to large-scale video data for learning the action dynamicity in the yeilded representation from the passive-observation, which can be used later for producing training signal for lightweight action-conditioned controller [16]. In parallel, the recurrent state-space models (RSSMs) have been shown to provide an effective mechanism for maintaining compact latent memories that approximate Markovian dynamics under partial observability with the capability of long-term planning using minimal ammount of representation [21,22]. The attempts of using encoder with long-term RSSM planning model show-case the efficiency and overhead-minimalizing with increasing in training utility than MCTS based approach, while still yeild out sensory grouded action from agents.
Based on these aforementioned works, this result argue that world-model designing can be potential benefit from the high-quality self-supervised learning embedding from pretrained encoder as V-JEPA 2 and combine with the usage of long-term planner which can reduce and minimalize the cost of inference while remaining accuracy, and tunable model driving quality.
The contribution of this studies include 4 keys essential contributions as follow:
• A unified perspective on world-model design for autonomous vehicles that emphasizes predictive, representation-level modeling over observation-level simulation which is called HanoiWorld.
• Suggesting a JEPA-based encoding strategy, inspired by V-JEPA-2 fine-tuning, for learning decision-relevant latent representations from large-scale video data.
• The integration of an RSSM-based latent memory to support approximate Markovian state transitions under partial observability.
• A demonstration that a simple MLP-based actor-critic controller can be trained effectively within the learned latent world model, avoiding expensive planning algorithms and complex policy architectures.
The rest of the paper shall be showcased as follows; Section 2 focusing on the related works and provide the whole conceptual and theoretical foundation on the challenges and related solution; Section 3 discusses the suggested proposed world-model designing; Section 4 will attempts to provide the experiment description, the usecase and result discussion. Finally, the report shall be conclude on Section 5.
Additionally,
This content is AI-processed based on open access ArXiv data.