Title: Multi-Dimensional Prompt Chaining to Improve Open-Domain Dialogue Generation
ArXiv ID: 2601.01037
Date: 2026-01-03
Authors: Livia Leong Hui Teng
📝 Abstract
Small language models (SLMs) offer significant deployment advantages but often struggle to match the dialogue quality of larger models in open-domain settings. In this paper, we propose a multi-dimensional promptchaining framework that integrates Naturalness, Coherence, and Engagingness dimensions to enhance human-likeness in open-domain dialogue generation. We apply the framework to two SLMs-TinyLlama and Llama-2-7B-and benchmark their performance against responses generated by substantially larger models, including Llama-2-70B and GPT-3.5 Turbo. We then employ automatic and human evaluation to assess the responses based on diversity, contextual coherence, as well as overall quality. Results show that the full framework improves response diversity by up to 29%, contextual coherence by up to 28%, and engagingness as well as naturalness by up to 29%. Notably, Llama-2-7B achieves performance comparable to substantially larger models, including Llama-2-70B and GPT-3.5 Turbo. Overall, the findings demonstrate that carefully designed prompt-based strategies provide an effective and resource-efficient pathway to improving open-domain dialogue quality in SLMs.
💡 Deep Analysis
📄 Full Content
Multi-Dimensional Prompt Chaining to Improve Open-Domain Dialogue
Generation
Livia Leong Hui Teng
Nanyang Technological University
lleong013@e.ntu.edu.sg
Abstract
Small language models (SLMs) offer signifi-
cant deployment advantages but often strug-
gle to match the dialogue quality of larger
models in open-domain settings. In this pa-
per, we propose a multi-dimensional prompt-
chaining framework that integrates Naturalness,
Coherence, and Engagingness dimensions to
enhance human-likeness in open-domain dia-
logue generation. We apply the framework to
two SLMs—TinyLlama and Llama-2-7B—and
benchmark their performance against responses
generated by substantially larger models, in-
cluding Llama-2-70B and GPT-3.5 Turbo. We
then employ automatic and human evaluation
to assess the responses based on diversity, con-
textual coherence, as well as overall quality.
Results show that the full framework improves
response diversity by up to 29%, contextual
coherence by up to 28%, and engagingness as
well as naturalness by up to 29%. Notably,
Llama-2-7B achieves performance compara-
ble to substantially larger models, including
Llama-2-70B and GPT-3.5 Turbo. Overall, the
findings demonstrate that carefully designed
prompt-based strategies provide an effective
and resource-efficient pathway to improving
open-domain dialogue quality in SLMs.
1
Introduction
Large language models (LLMs) have revolution-
ized natural language processing, demonstrating
remarkable capabilities in understanding context
and generating human-like responses (Devlin et al.,
2019). These advances in open-domain dialogue
generation enable more meaningful and engaging
conversations with users, with promising applica-
tions ranging from enhanced user engagement to
mental health support (Siddals et al., 2024). Re-
cent researches has focused on improving response
quality through various approaches, including gen-
erating more diverse responses (Liu et al., 2023;
Lee et al., 2023; Sun et al., 2023), adapting flexible
strategies or frameworks (Shu et al., 2023; Wang
et al., 2022), and incorporating social norms and
expressions (Varshney et al., 2024).
However, these advances are predominantly con-
fined to large-scale models that require substantial
computational resources to operate efficiently. In
contrast, Small Language Models (SLMs) offer sig-
nificant advantages in terms of computational effi-
ciency, cost-effectiveness, and adaptability (Wang
et al., 2024), but struggle to achieve comparable di-
alogue quality. To bridge this performance gap
between LLMs and SLMs, prompt-based tech-
niques - especially few-shot in-context learning
- has emerged as a promising approach for enhanc-
ing model performance without additional training
or modifying model parameters, with demonstrated
effectiveness for both LLMs (Brown et al., 2020)
and SLMs (Schick and Schütze, 2021).
Hence, in this paper, we introduce a novel mul-
tidimensional prompt chaining framework that en-
ables SLMs to achieve performance comparable to
larger models in open-domain dialogue generation.
Prompt chaining decomposes complex tasks into
sequential subtasks, where intermediate outputs
from one prompt feed into subsequent prompts.
Our framework leverages this approach to itera-
tively refine generated responses through a struc-
tured chain in which each prompt focuses on en-
hancing a distinct dimension of response quality,
specifically contextual coherence, naturalness, and
engagingness. Through systematic experimenta-
tion with various few-shot learning configurations,
we provide empirical evidence that our approach
significantly enhances response quality across both
quantitative metrics and qualitative assessments,
enabling SLMs to perform on par with substan-
tially larger and more resource-intensive LLMs.
The remainder of this paper is organized as fol-
lows: We first present our methodology, includ-
ing the few-shot generation approach and response
generation workflow. We then describe our experi-
1
arXiv:2601.01037v1 [cs.CL] 3 Jan 2026
mental variations and evaluation metrics, followed
by automatic metrics and human evaluation results
and discussion of our findings.
2
Methodology
In this paper, we propose an In-Context Learn-
ing prompt chaining framework to improve the
coherence, engagingness and naturalness of open-
domain dialogue responses.
We selected these
three dimensions to prioritize human-likeness in
open-ended conversational settings (Zhong et al.,
2022; Finch and Choi, 2020; Gopalakrishnan et al.,
2019). The quality of the performance is then eval-
uated, typically based on multiple dimensions of
the response, namely, coherence, engagement and
naturalness.
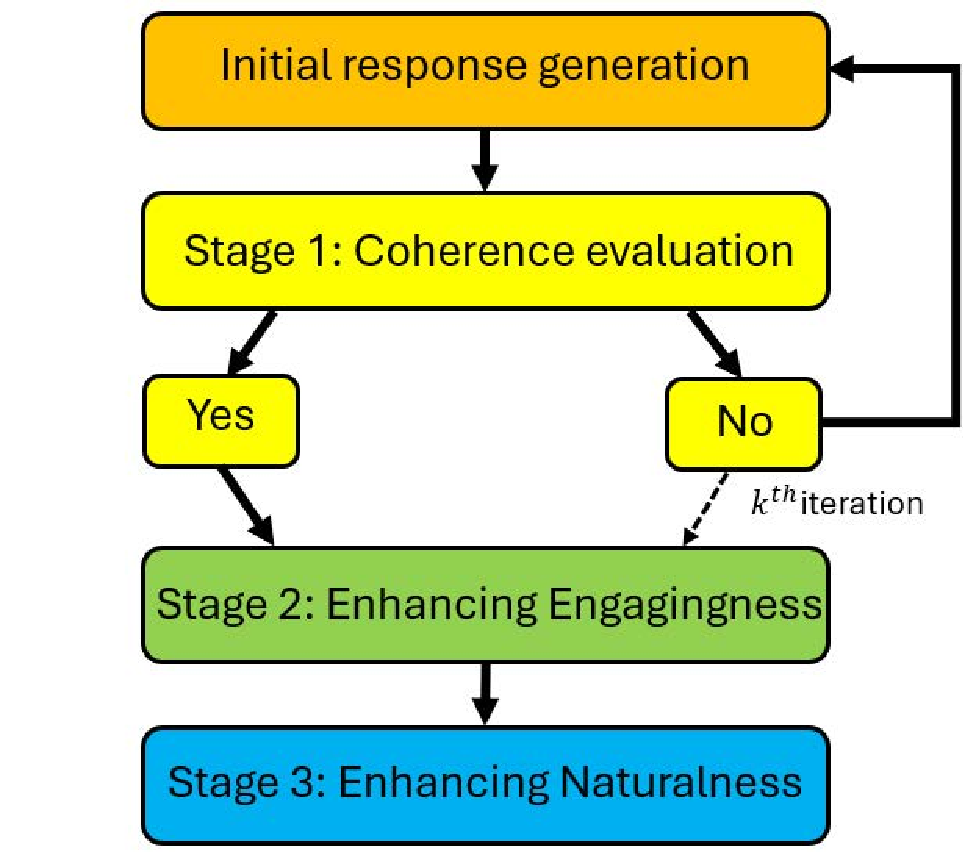
The framework iterates refinement based on spe-
cific qualitative criteria, as illustrated/outlined be-
low.
Figure 1: Workflow of the response generation frame-
work. The process includes: initial response generation,
(1) coherence evaluation with up to k iterations, (2) en-
gagingness improvement if coherence is