This paper presents a comparative study of a custom convolutional neural network (CNN) architecture against widely used pretrained and transfer learning CNN models across five real-world image datasets. The datasets span binary classification, fine-grained multiclass recognition, and object detection scenarios. We analyze how architectural factors, such as network depth, residual connections, and feature extraction strategies, influence classification and localization performance. The results show that deeper CNN architectures provide substantial performance gains on fine-grained multiclass datasets, while lightweight pretrained and transfer learning models remain highly effective for simpler binary classification tasks. Additionally, we extend the proposed architecture to an object detection setting, demonstrating its adaptability in identifying unauthorized auto-rickshaws in real-world traffic scenes. Building upon a systematic analysis of custom CNN architectures alongside pretrained and transfer learning models, this study provides practical guidance for selecting suitable network designs based on task complexity and resource constraints.
Image classification has become one of the most widely adopted applications of deep learning, powering real-world systems in urban monitoring, agriculture, environmental assessment, and automated quality control. Convolutional Neural Networks (CNNs) have played a central role in these advances due to their ability to learn hierarchical visual features directly from raw images. Despite the strong performance of wellestablished architectures, designing compact and task-specific CNN models remains important, particularly when datasets vary widely in scale, domain complexity, and visual distributions.
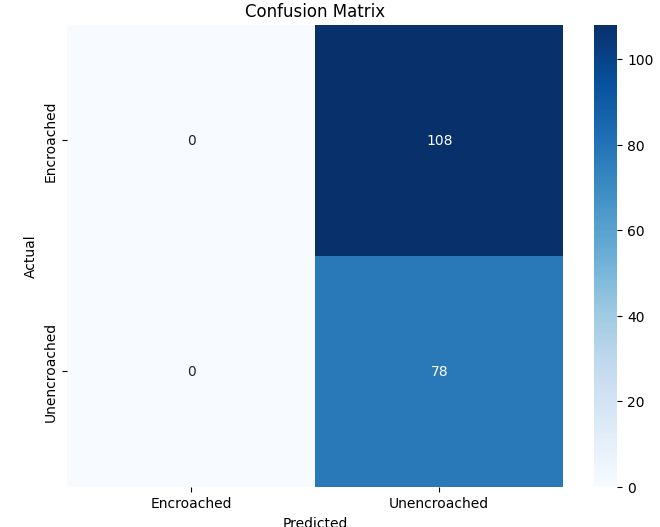
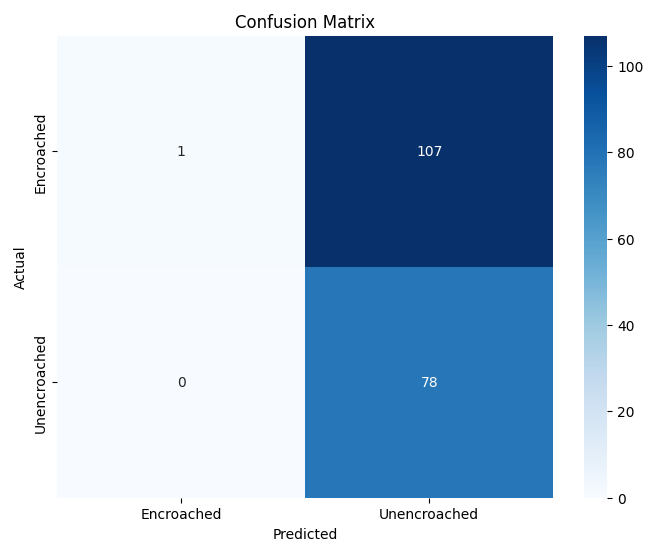
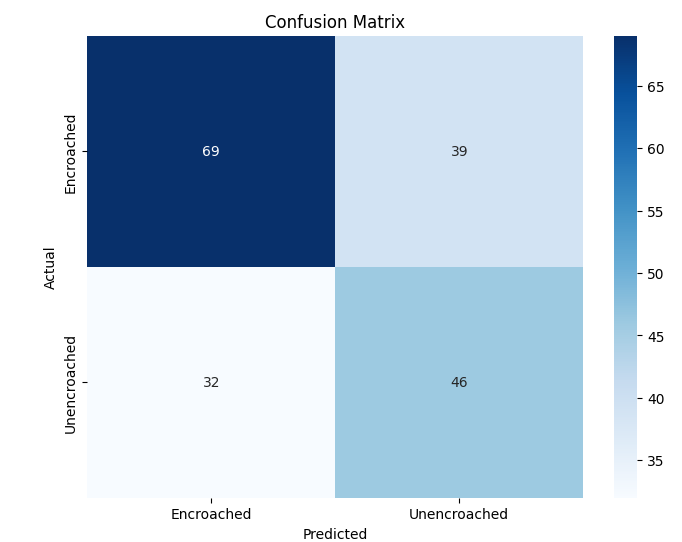
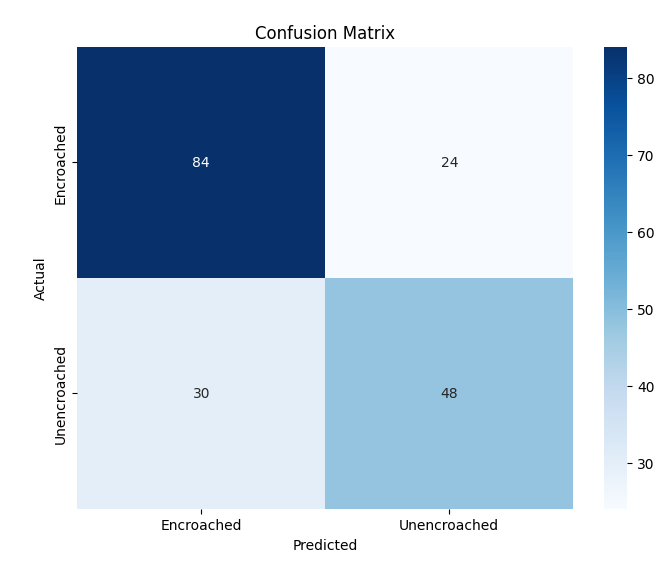
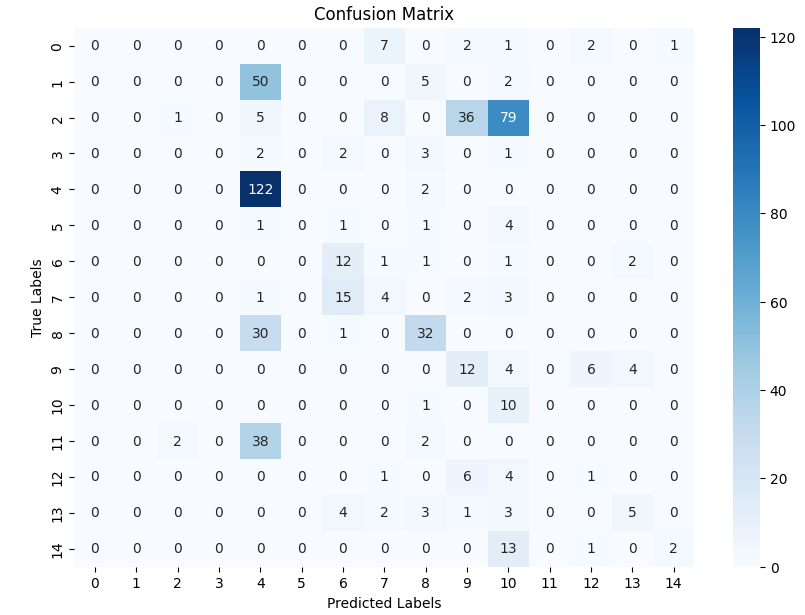
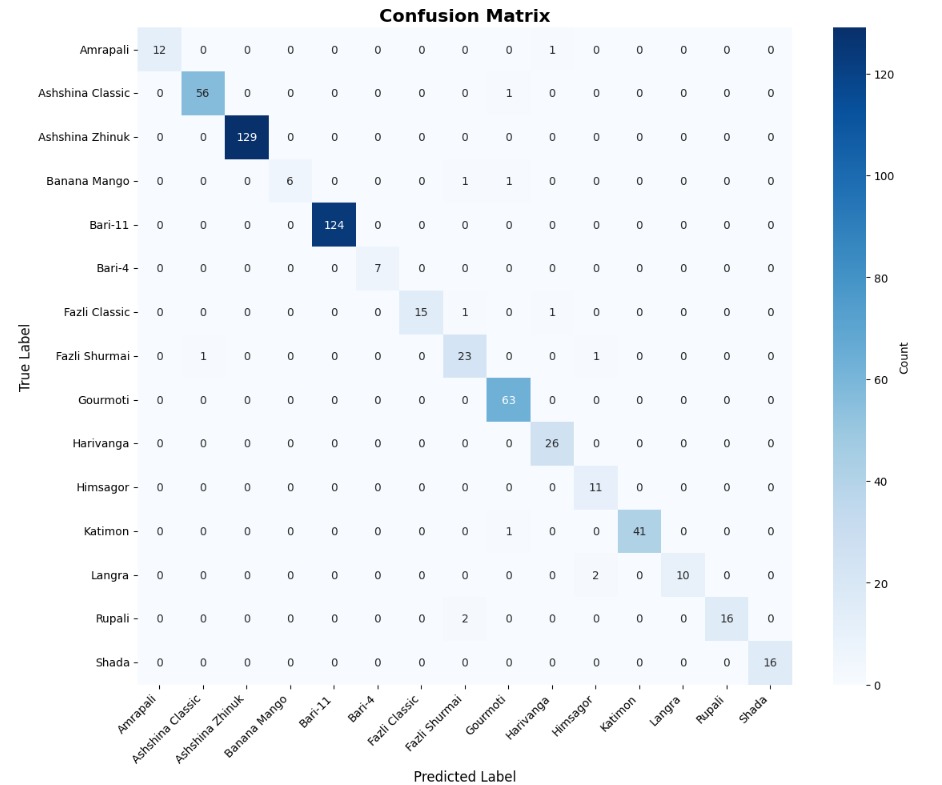
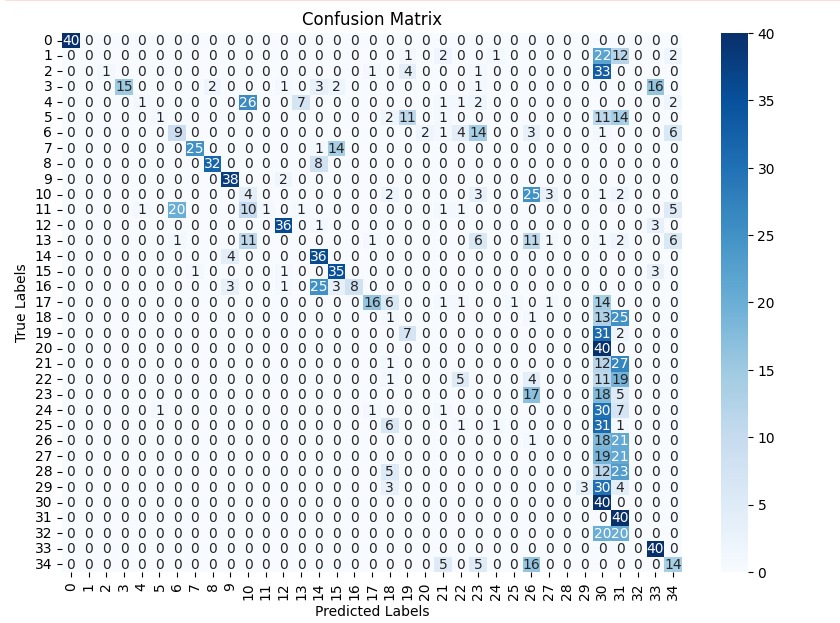
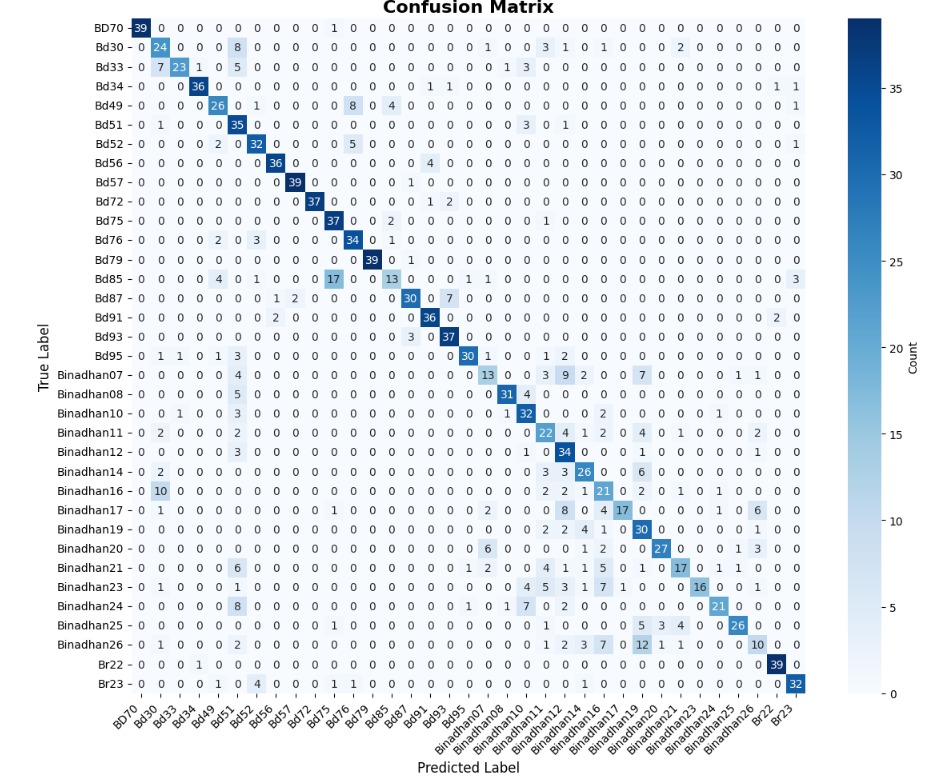
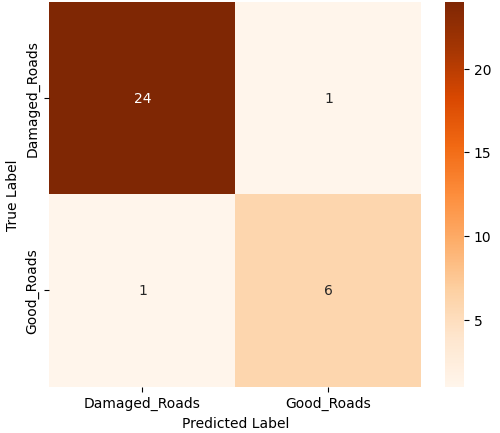
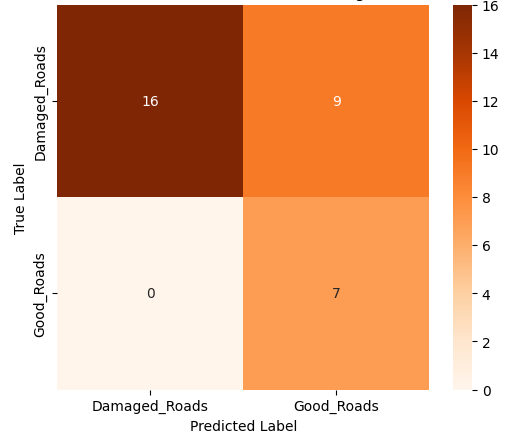
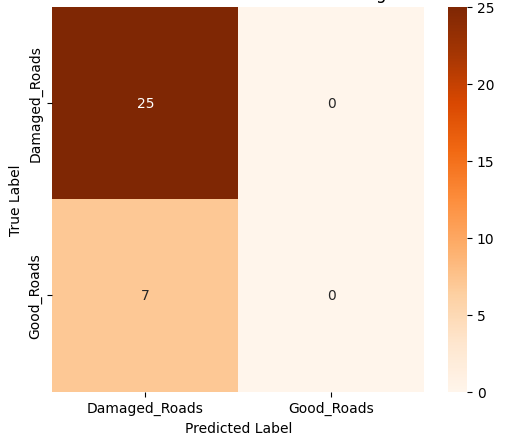
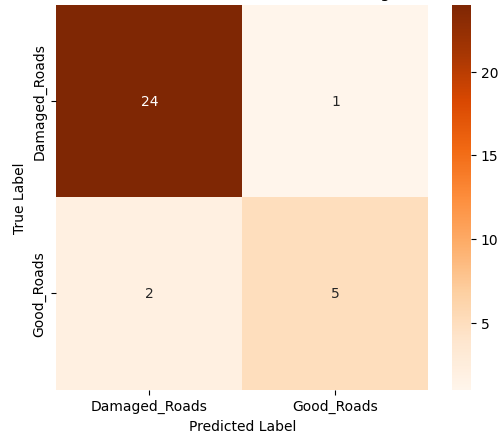
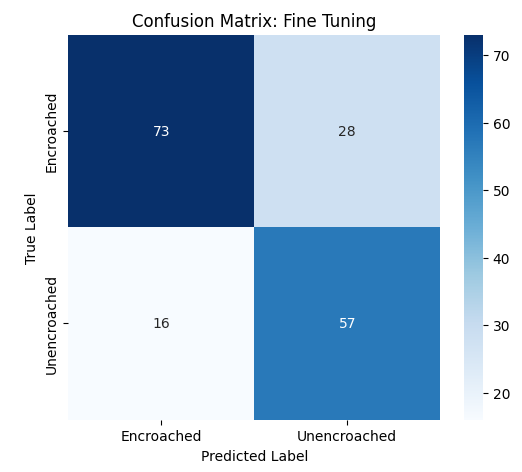
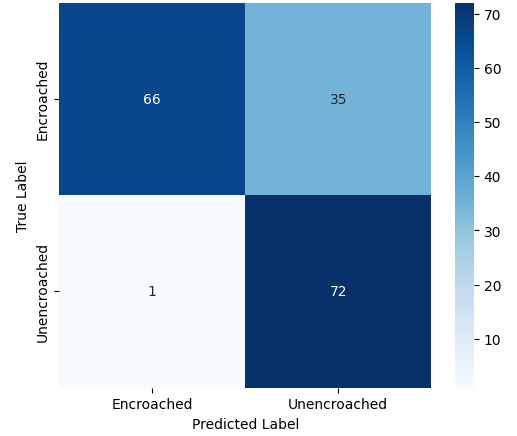
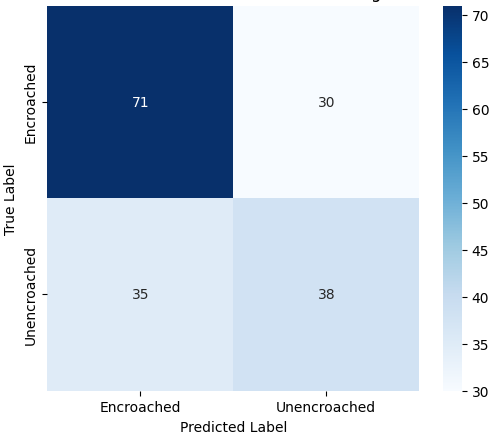
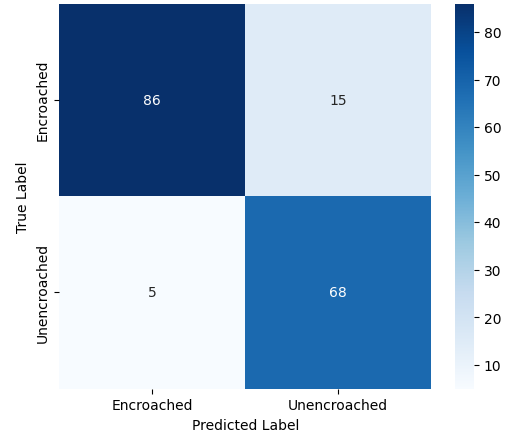
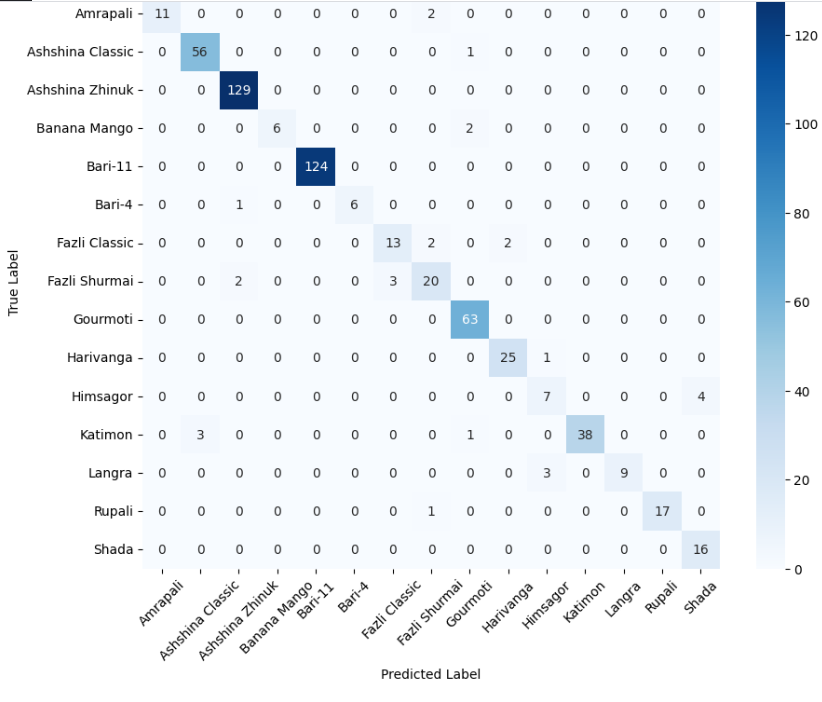
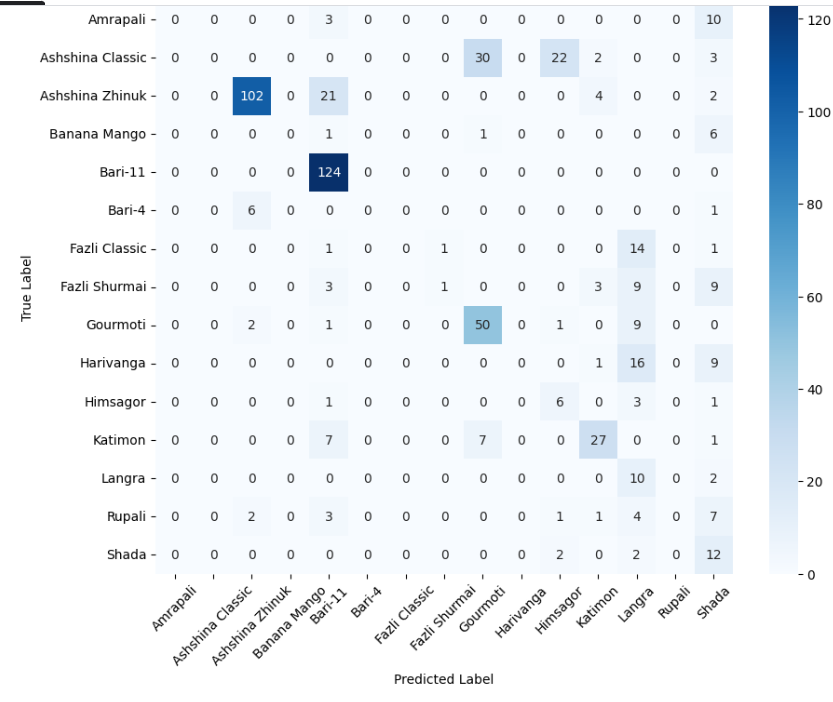
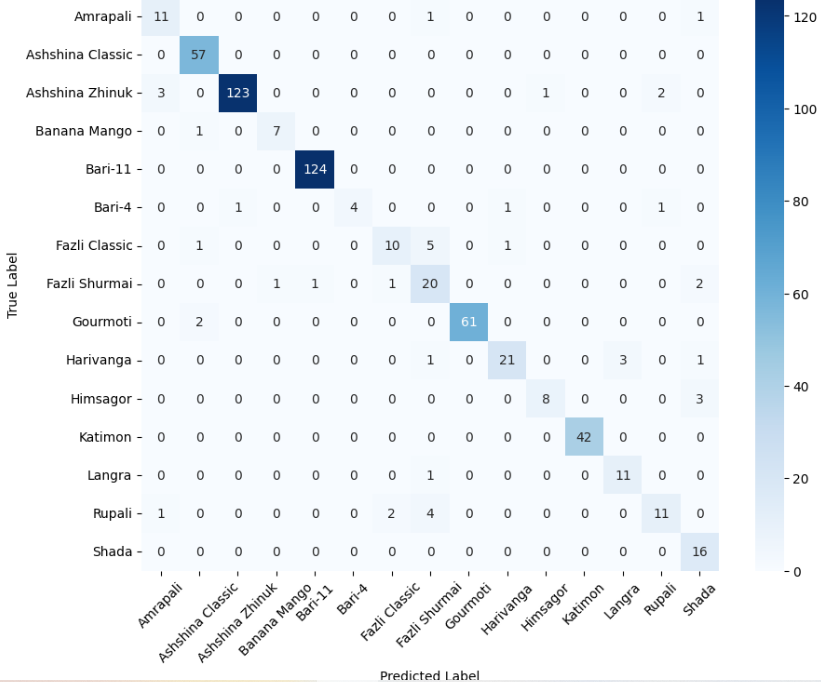
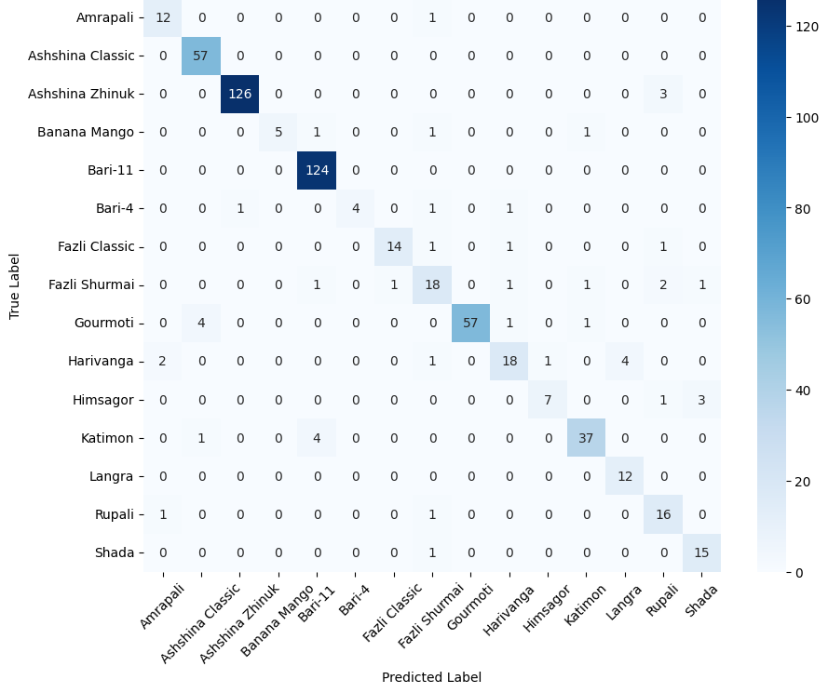
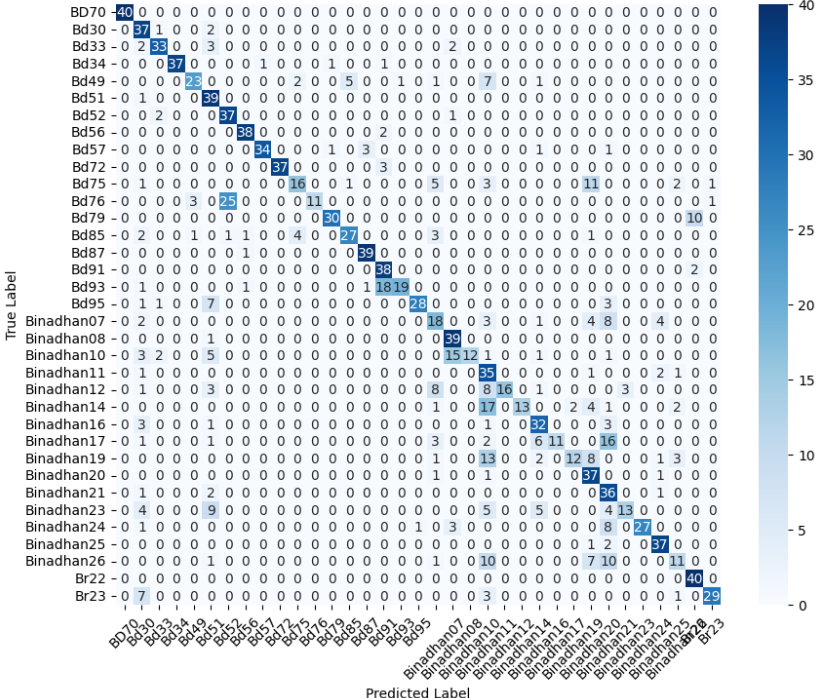
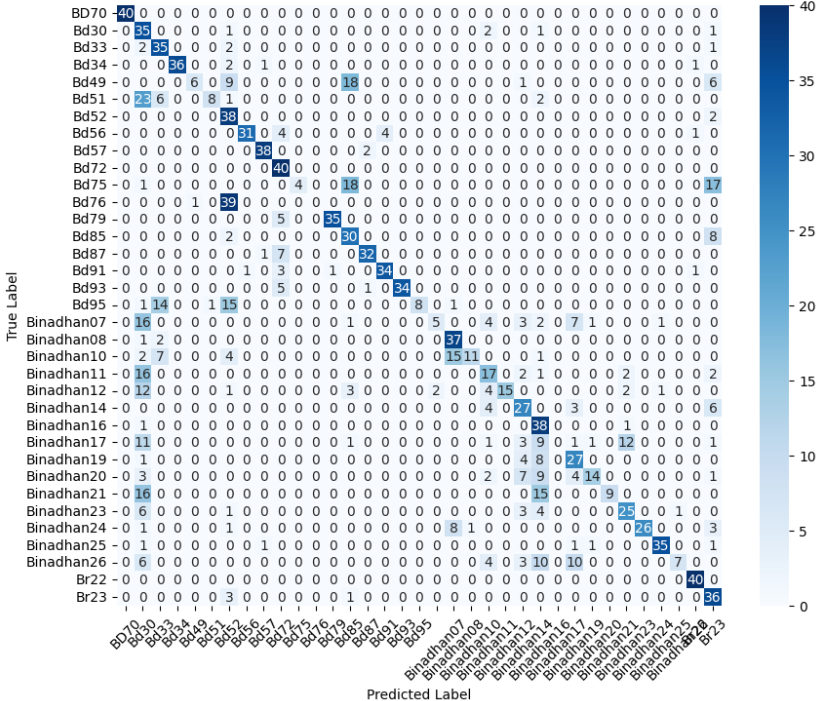
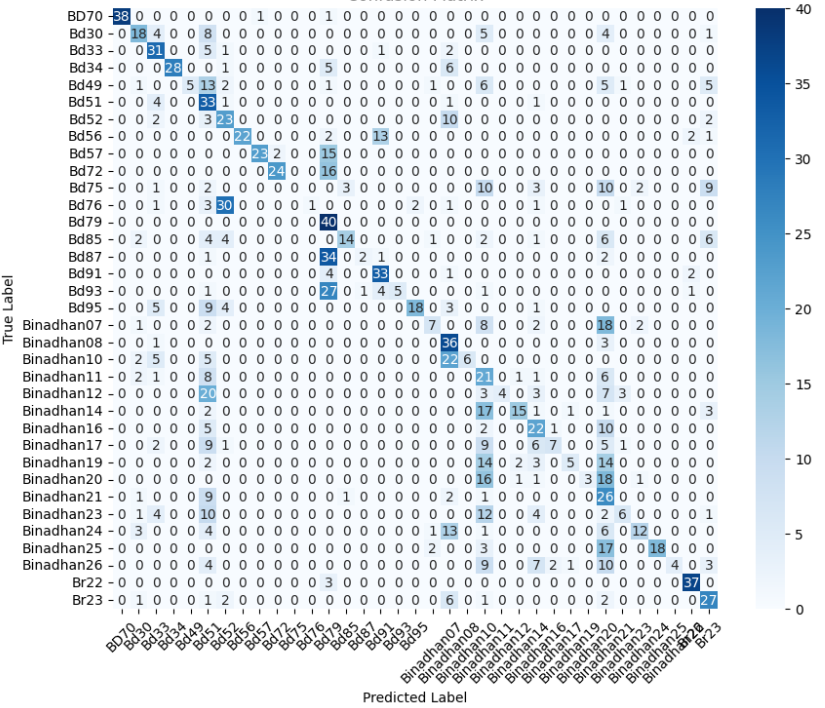
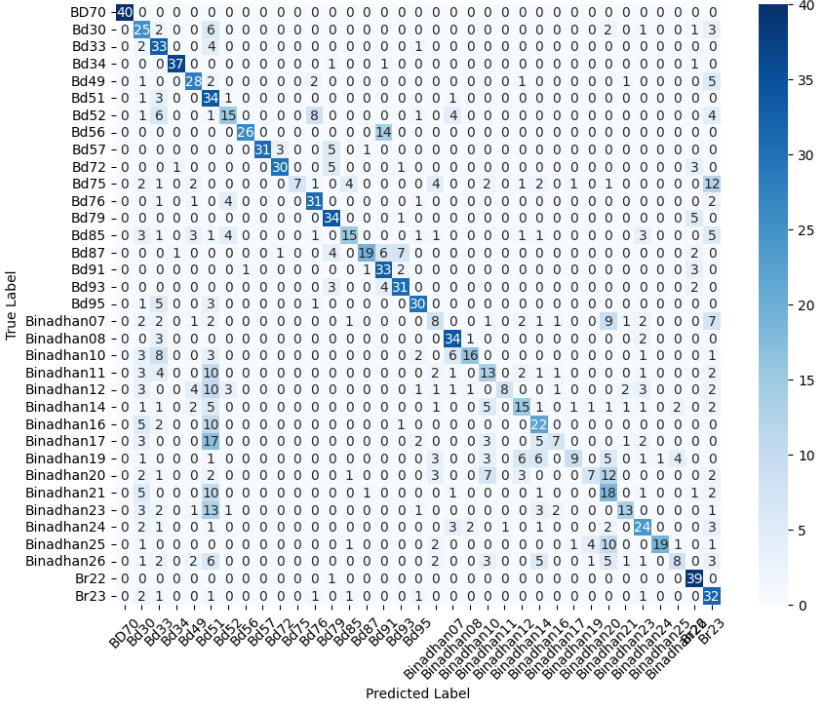
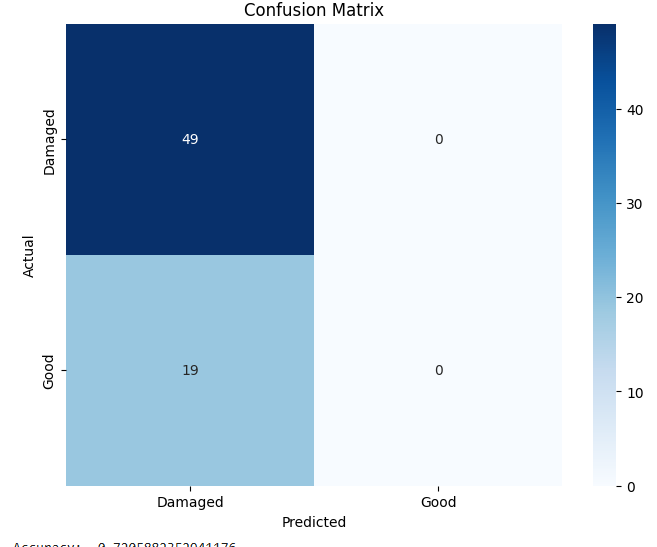
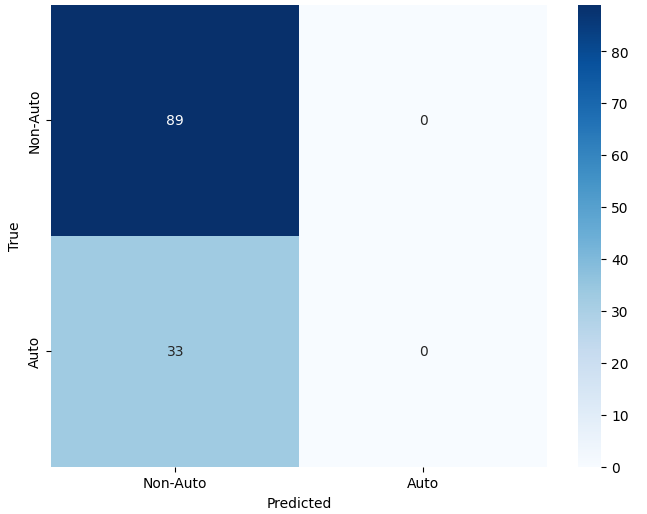
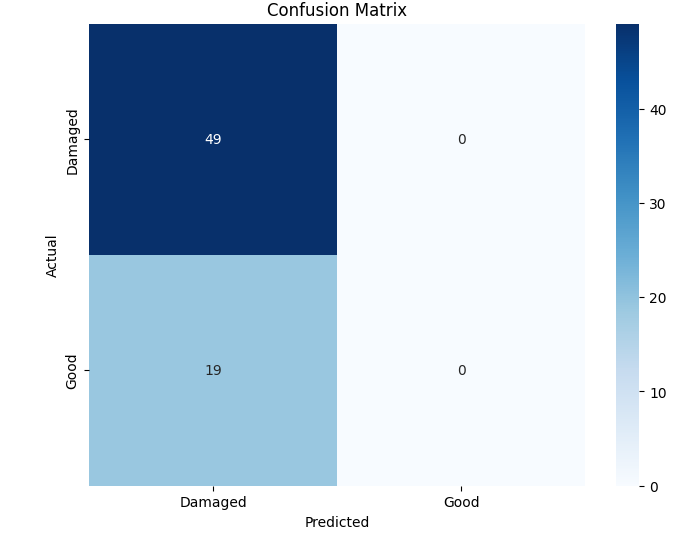
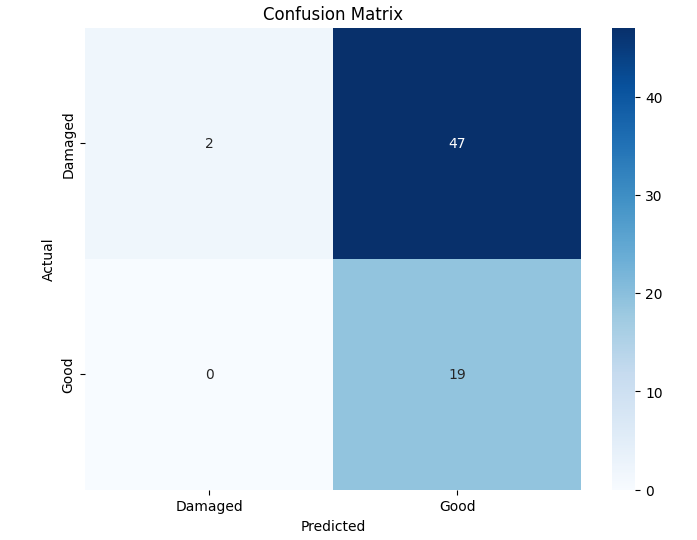
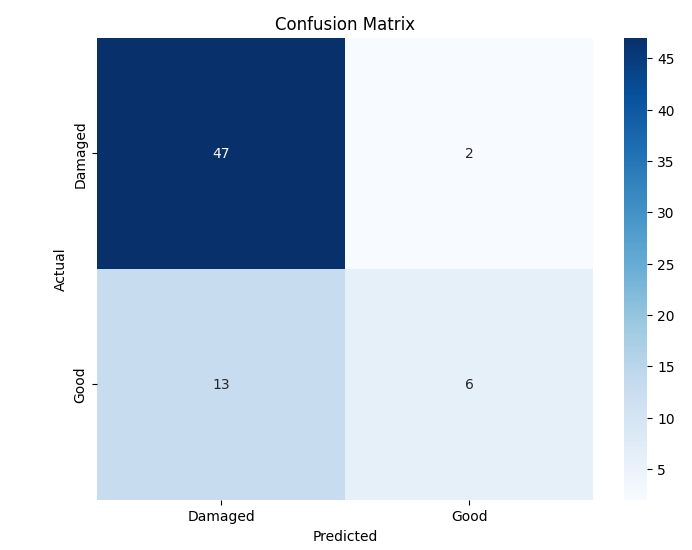
In this study, we evaluate the performance of CNN-based models across five diverse image datasets spanning both binary and multiclass settings. These datasets cover practical real-world challenges: road surface analysis, footpath encroachment detection, fruit variety recognition, and paddy species classification. The Road Damage [1] and FootpathVision [2] datasets represent binary classification tasks focused on urban infrastructure monitoring, where images capture conditions such as damaged versus undamaged roads or encroached versus clear sidewalks. In contrast, the MangoIm-ageBD [3] and PaddyVarietyBD [4] datasets present large-scale multiclass problems involving the identification of multiple mango varieties and microscopic paddy kernels, respectively. Additionally, we include an Auto-Rickshaw Detection [5] dataset that introduces an object-recognition challenge, where the goal is to differentiate motorized auto-rickshaws from visually similar non-motorized rickshaws in complex traffic scenes. This dataset adds a spatial localization component and provides insight into how classification-oriented CNN architectures adapt to images containing multiple overlapping objects. Together, these datasets provide a comprehensive evaluation environment with varying image resolutions, visual characteristics, and class distributions.
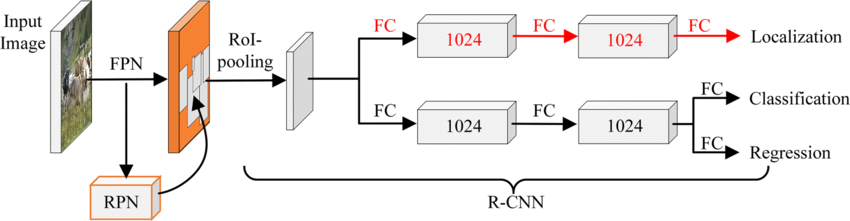
Given this diversity, relying solely on standard deep architectures may not yield optimal performance or adaptability across tasks. This motivates the exploration of custom CNN designs tailored to specific feature patterns and dataset characteristics. In this work, we investigate a custom convolutional architecture and compare it against progressively simplified variants and an evolved baseline model to understand how different architectural choices influence performance across multiple domains. Our goal is to provide a systematic analysis of how modifications in convolutional structure, residual connections, and feature extraction depth affect classification accuracy on heterogeneous real-world datasets. To complement this analysis, we evaluate two widely used pretrained CNN architectures-MobileNet and EfficientNet-under both pretrained and transfer learning setups, and compare their performance against the best-performing variants of our custom CNN across multiple image classification tasks. For the object detection dataset, we adopt state-of-the-art detection frameworks, namely YOLO and Faster R-CNN, to assess localization and recognition performance in complex traffic scenes.
In this section, we introduce a custom convolutional neural network designed to efficiently extract hierarchical visual features across diverse image classification tasks. Our goal was to balance model complexity and representational power, enabling robust recognition across datasets with varying visual characteristics while keeping the parameter count manageable for practical deployment.
The architecture is organized into modular components that progressively transform raw image inputs into high-level semantic representations. We begin with a compact convolutional feature extractor to capture low-level spatial patterns, followed by a series of residual blocks incorporating depthwise separable convolutions for computational efficiency. Finally, a classification head aggregates global information and produces the final predictions.
This design allows the network to learn multi-scale features, handle complex spatial dependencies, and maintain robustness across different object categories, visual domains, and environmental conditions. Each component of the architecture is described in detail below.
To initiate feature extraction, our custom CNN begins with three stacked 3×3 convolutional layers. This design is inspired by the VGG family of networks, which demonstrated that stacking smaller convolutional kernels (e.g., 3×3) can be more effective and parameter-efficient than using a single large kernel. The use of multiple nonlinearities between layers also allows the model to learn more complex local patterns.
The configuration of the initial block is as follows:
• The first layer is a 3×3 convolution with 32 filters and a stride of 2, followed by Batch Normalization and ReLU activation. The stride reduces the spatial resolution while preserving important low-level features. • The second layer is another 3×3 convol
This content is AI-processed based on open access ArXiv data.