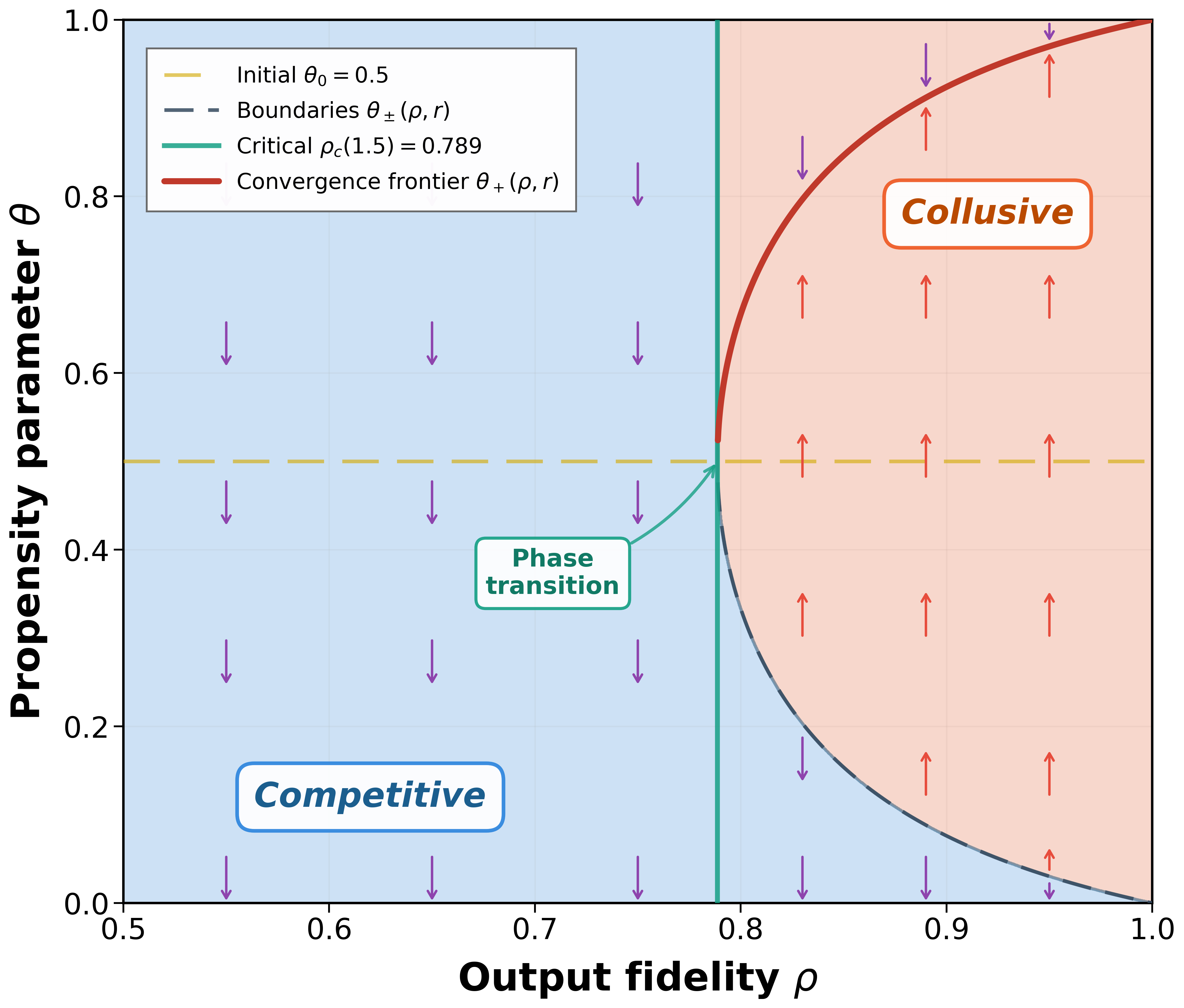
We investigate how the widespread adoption of large language models (LLMs) for pricing decisions can facilitate collusion among competing sellers. We develop a theoretical framework to analyze a duopoly in which both sellers delegate pricing to the same pre-trained LLM characterized by two parameters: a propensity parameter that captures the model's internal preference for high-price recommendations, and an output fidelity parameter that measures the alignment between this preference and the generated outputs. The LLM updates its propensity through retraining the model. Somewhat surprisingly, we find that the seemingly prudent practice of configuring LLMs for robustness and reproducibility in high-stakes pricing tasks gives rise to collusion through a phase transition. Specifically, we establish a critical output-fidelity threshold that governs long-run market behavior. Below this threshold, competitive pricing is the unique long-run outcome regardless of initial conditions. Above this threshold, the system exhibits bistability, with both competitive and collusive pricing being locally stable, and the realized outcome is determined by the model's initial preference. The collusive pricing outcome resembles tacit collusion: prices are elevated on average, but occasional low-price recommendations create plausible deniability and prevent detection. When output fidelity is perfect, full collusion emerges from any interior starting point. Moreover, for finite training batches with batch size b, we show that infrequent model retraining, driven by computational costs, further amplifies collusion. Specifically, when the initial preference lies in the region that leads to collusive pricing, the probability of collusion approaches one as batch size increases, as larger batches suppress stochastic fluctuations that might otherwise drive the system toward competitive pricing. The region of indeterminate outcomes shrinks at a rate of O(1/ √ b), so that larger batches convert more initial conditions into predictably collusive trajectories.
The rapid adoption of algorithms in commercial decision-making has attracted increasing regulatory scrutiny. In March 2024, the Federal Trade Commission (FTC) and the Department of Justice (DOJ) issued a joint statement warning that algorithmic pricing systems can facilitate illegal collu-sion, even in the absence of explicit agreements among competitors. 1 Subsequent enforcement signals have only intensified: in August 2025, DOJ Assistant Attorney General Gail Slater announced that algorithmic pricing investigations would significantly increase as deployment of the technology becomes more prevalent. 2 This regulatory concern is particularly salient as sellers increasingly rely on large language models (LLMs) for pricing decisions, an area the regulation has not yet addressed. A 2024 McKinsey survey of Fortune 500 retail executives found that 90% have begun experimenting with generative AI solutions, with pricing and promotion optimization emerging as a priority use case. 3 In Europe, 55% of retailers plan to pilot generative AI-based dynamic pricing by 2025, building on the 61% who have already adopted some form of algorithmic pricing. 4 Industry applications are already operational: Wang et al. (2025) report that Alibaba has deployed an LLM-based pricing system on its Xianyu platform to provide real-time price recommendations for sellers.
This heightened regulatory pressure coincides with remarkable market concentration in the LLM industry. As of 2025, ChatGPT commands approximately 62.5% of the business-to-consumer AI subscription market, while 92% of Fortune 500 companies report using OpenAI products. 5 This confluence of concentrated AI infrastructure and heightened antitrust concern raises a fundamental question: Can the widespread adoption of LLMs for pricing decisions facilitate collusion across competing sellers?
The possibility that algorithms might learn to collude has been studied extensively in the context of machine learning/reinforcement learning (RL). Banchio and Mantegazza (2022) demonstrate that Q-learning agents can converge to supracompetitive prices in repeated games through trialand-error learning. However, such collusion typically requires extensive training periods and millions of interactions, providing some reassurance that computational barriers might limit practical concern. LLMs present a fundamentally different paradigm. Unlike RL agents that learn pricing strategies from scratch through repeated market interactions, LLMs arrive pretrained on vast corpora of human knowledge, including business strategy, economic theory, and pricing practices.
We identify two sources of collusion risk unique to LLM-based decision-making and illustrate the contrast between LLM-based and RL-based approaches in Figure 1. Specifically, the first source is the shared knowledge infrastructure that arises from market concentration. Given the dominant position documented above, competing sellers frequently delegate pricing decisions to the same LLM provider. When multiple sellers query the same model, their adopted recommendations may become correlated through the model’s internal latent preferences, a structural tendency toward certain pricing strategies encoded in its weights. This correlation creates implicit coordination without any communication between sellers: even if each seller queries the LLM independently, the common underlying preference induces positive correlation in their pricing actions. Moreover, shared knowledge persists even when sellers use different LLM providers. Leading LLMs are often distilled into smaller models by competitors, transferring embedded pricing heuristics from dominant providers to the broader ecosystem. 6 In addition, pretraining corpora across providers draw from largely overlapping public sources, including business literature, economic textbooks, and strategic discussions that extensively document the profitability of coordinated pricing. Alignment procedures such as reinforcement learning from human feedback (RLHF) further homogenize model behavior, as evaluators or users at different companies apply similar standards of “helpfulness” and “reasonableness.” This raises a fundamental question: Does shared knowledge infrastructure, whether through common providers or homogenized training, lead to correlated pricing recommendations that translate into market-level collusion?
The second source of risk is the data sharing policies that govern model improvement. Major LLM providers collect user interaction data to refine their models, creating feedback loops between seller behavior and model updates. Google’s Gemini, for instance, uses a “Keep Activity” setting that is enabled by default for users aged 18 and over, allowing the platform to analyze conversations and use uploaded files, images, and videos for AI training.7 Anthropic’s August 2025 policy change similarly made data sharing the default setting, with five-year retention for users who consent. 8xAI off
This content is AI-processed based on open access ArXiv data.