Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains such as social networks, molecular chemistry, and more. A crucial component of GNNs is the pooling procedure, in which the node features calculated by the model are combined to form an informative final descriptor to be used for the downstream task. However, previous graph pooling schemes rely on the last GNN layer features as an input to the pooling or classifier layers, potentially under-utilizing important activations of previous layers produced during the forward pass of the model, which we regard as historical graph activations. This gap is particularly pronounced in cases where a node's representation can shift significantly over the course of many graph neural layers, and worsened by graph-specific challenges such as over-smoothing in deep architectures. To bridge this gap, we introduce HISTOGRAPH, a novel two-stage attention-based final aggregation layer that first applies a unified layer-wise attention over intermediate activations, followed by node-wise attention. By modeling the evolution of node representations across layers, our HISTOGRAPH leverages both the activation history of nodes and the graph structure to refine features used for final prediction. Empirical results on multiple graph classification benchmarks demonstrate that HISTOGRAPH offers strong performance that consistently improves traditional techniques, with particularly strong robustness in deep GNNs.
Graph Neural Networks (GNNs) have achieved strong results on graph-structured tasks, including molecular property prediction and recommendation (Ma et al., 2019;Gilmer et al., 2017;Hamilton et al., 2017). Recent advances span expressive layers (Maron et al., 2019;Morris et al., 2023;Frasca et al., 2022;Zhang et al., 2023a;b;Puny et al., 2023), positional and structural encodings (Dwivedi et al., 2023;Rampášek et al., 2022;Eliasof et al., 2023a;Belkin & Niyogi, 2003;Maskey et al., 2022;Lim et al., 2023;Huang et al., 2024), and pooling (Ying et al., 2018;Lee et al., 2019;Bianchi et al., 2020;Wang et al., 2020;Vinyals et al., 2015;Zhang et al., 2018;Gao & Ji, 2019;Ranjan et al., 2020;Yuan & Ji, 2020). However, pooling layers still underuse intermediate activations produced during message passing, limiting their ability to capture long-range dependencies and hierarchical patterns (Alon & Yahav, 2020;Li et al., 2019;Xu et al., 2019).
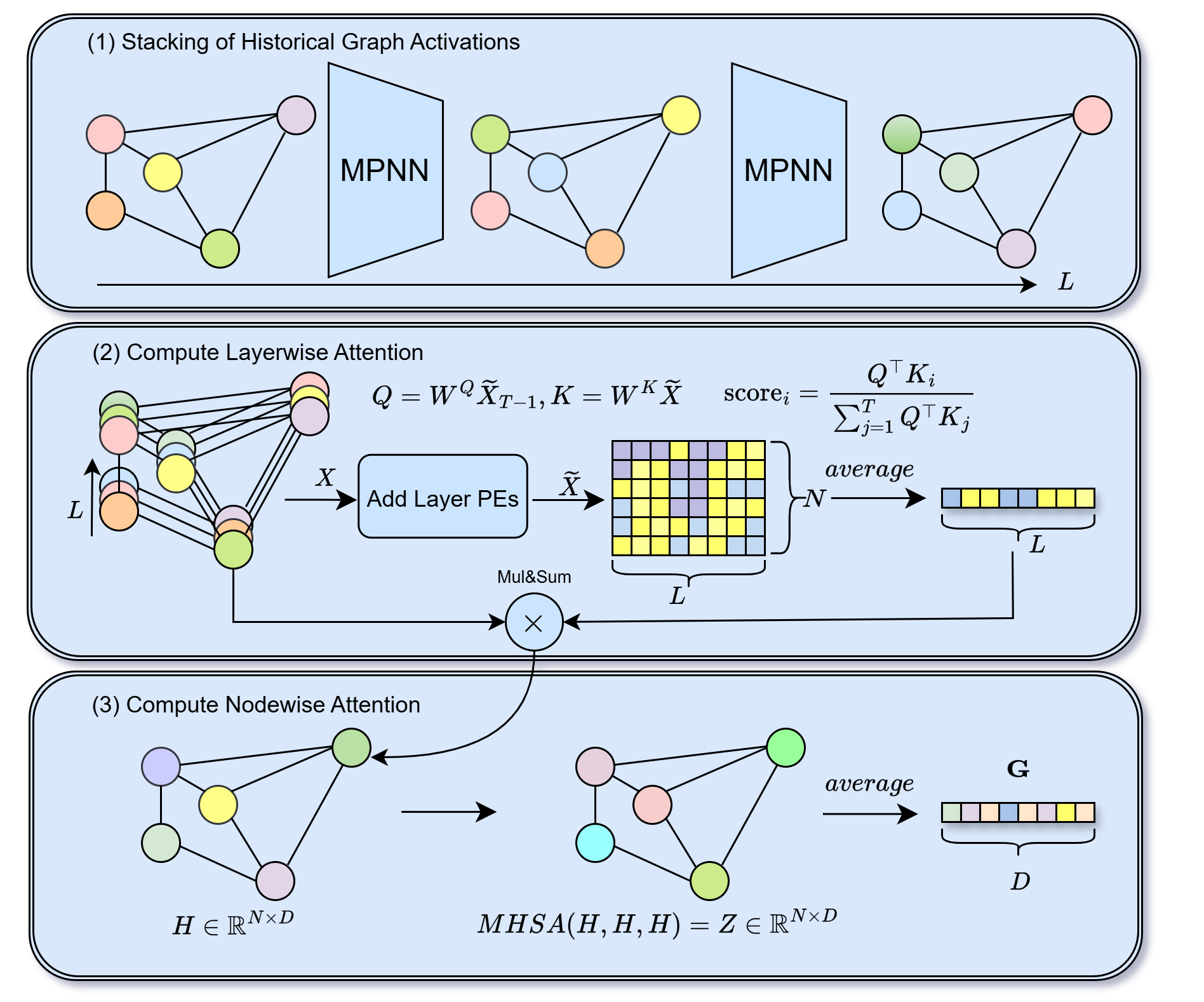
In GNNs, layers capture multiple scales: early layers model local neighborhoods and motifs, while deeper layers encode global patterns (communities, long-range dependencies, topological roles) (Xu et al., 2019), mirroring CNNs where shallow layers detect edges/textures and deeper layers capture object semantics (Zeiler & Fergus, 2014). Greater depth can overwrite early information (Li et al., 2018;Eliasof et al., 2022) and cause over-smoothing, making node representations indistinguishable (Cai & Wang, 2020;Nt & Maehara, 2019;Rusch et al., 2023). We address this by leveraging (1) Given input node features X 0 and adjacency A, a backbone GNN produces historical graph activations X 1 , .., X L-1 . (2) The Layer-wise attention module uses the final-layer embedding as a query to attend over all historical states while averaging across nodes, yielding per-node aggregated embeddings H. (3) A Node-wise self-attention module refines H by modeling interactions across nodes, producing Z, then averaged if graph embeddings G is wanted. historical graph activations, the representations from all layers, to integrate multi-scale features at readout (Xu et al., 2018).
Several works have explored the importance of deeper representations, residual connections, and expressive aggregation mechanisms to overcome such limitations (Xu et al., 2018;Li et al., 2021;Bresson & Laurent, 2017). Close to our approach are specialized methods like state space (Ceni et al., 2025) and autoregressive moving average (Eliasof et al., 2025) models on graphs, that consider a sequence of node features obtained by initialization techniques. Yet, these efforts often focus on improving stability during training, without explicitly modeling the internal trajectory of node features across layers. That is, we argue that a GNN’s computation path and the sequence of node features through layers can be a valuable signal. By reflecting on this trajectory, models can better understand which transformations were beneficial and refine their final predictions accordingly.
In this work, we propose HISTOGRAPH, a self-reflective architectural paradigm that enables GNNs to reason about their historical graph activations. HISTOGRAPH introduces a two-stage self-attention mechanism that disentangles and models two critical axes of GNN behavior: the evolution of node embeddings through layers, and their spatial interactions across the graph. The layer-wise module treats each node’s layer representations as a sequence and learns to attend to the most informative representation, while the node-wise module aggregates global context to form richer, context-aware outputs. HISTOGRAPH design enables learning representations without modifying the underlying GNN architecture, leveraging the rich information encoded in intermediate representations to enhance many graph related predictions (graph classification, node classification and link prediction).
We apply HISTOGRAPH in two complementary modes: (1) end-to-end joint training with the backbone, and (2) post-processing as a lightweight head on a frozen pretrained GNN. The end-to-end variant enriches intermediate representations, while the post-processing variant trains only the head, yielding substantial gains with minimal overhead. HISTOGRAPH consistently outperforms strong GNN and pooling baselines on TU and OGB benchmarks (Morris et al., 2020;Hu et al., 2020), demonstrating that computational history is a powerful, general inductive bias. Figure 1 overviews HISTOGRAPH.
(1) We introduce a self-reflective architectural paradigm for GNNs that leverages the full trajectory of node embeddings across layers; (2) We propose HISTOGRAPH, a two-stage self-attention mechanism that disentangles the layer-wise node embeddings evolution and spatial aggregation of node features; (3) We empirically validate HISTOGRAPH on graph-level classification, node classification and link prediction tasks, demonstrating consistent improvements over state-ofthe-art baselines; and, (4) We show that HISTOGRAPH can be employ
This content is AI-processed based on open access ArXiv data.