Title: Optimizing LSTM Neural Networks for Resource-Constrained Retail Sales Forecasting: A Model Compression Study
ArXiv ID: 2601.00525
Date: 2026-01-02
Authors: Ravi Teja Pagidoju
📝 Abstract
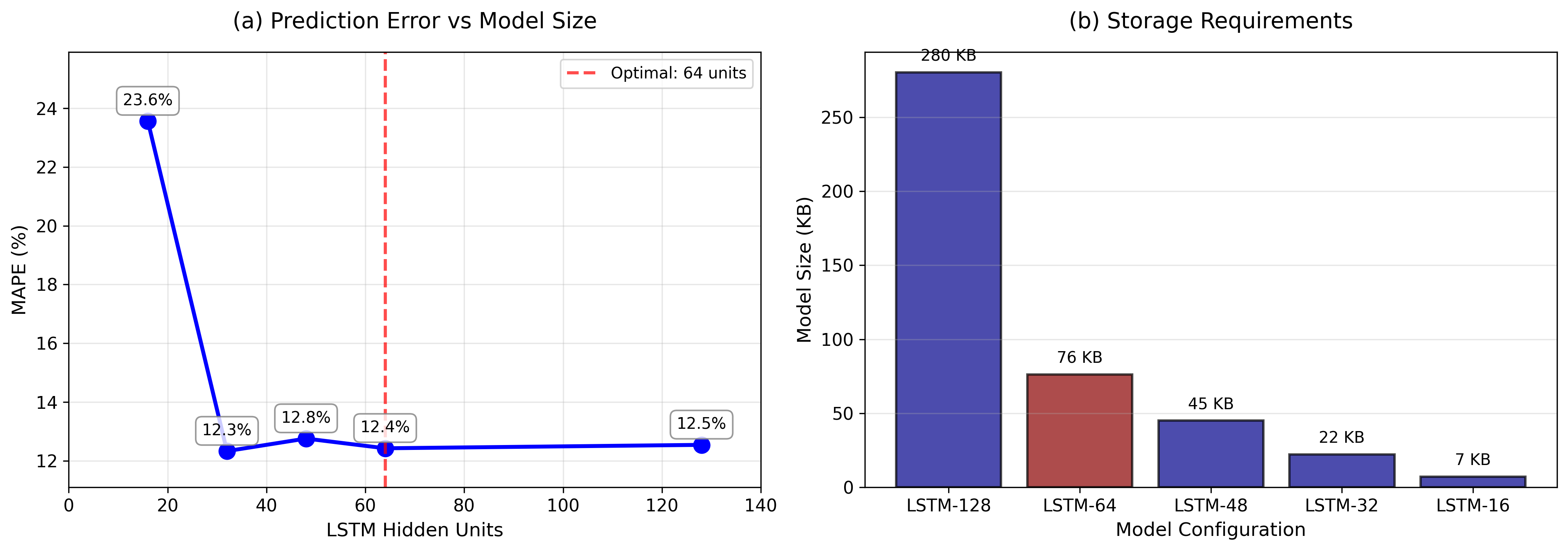
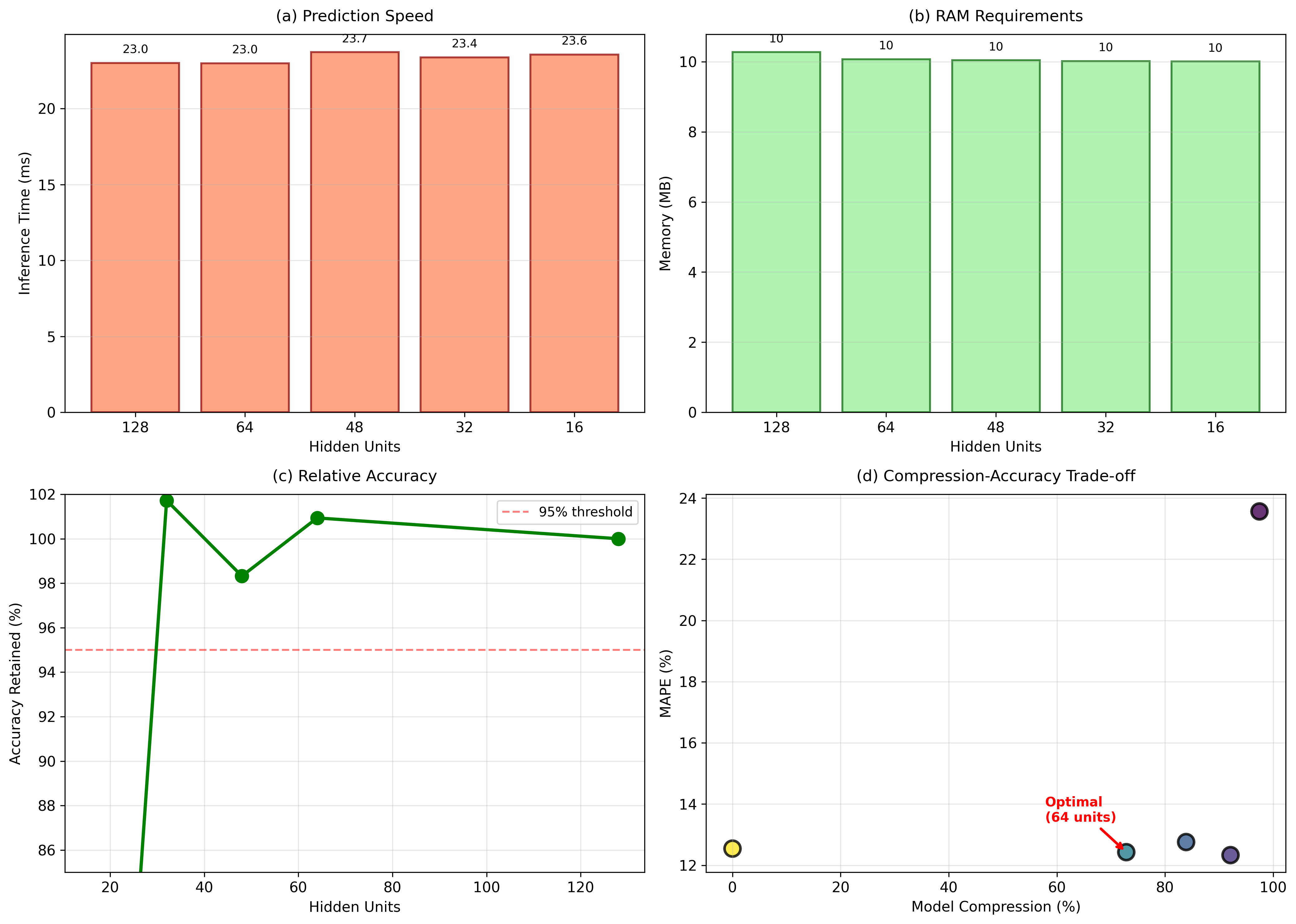
Standard LSTM(Long Short-Term Memory) neural networks provide accurate predictions for sales data in the retail industry, but require a lot of computing power. It can be challenging especially for mid to small retail industries. This paper examines LSTM model compression by gradually reducing the number of hidden units from 128 to 16. We used the Kaggle Store Item Demand Forecasting dataset, which has 913,000 daily sales records from 10 stores and 50 items, to look at the trade-off between model size and how accurate the predictions are. Experiments show that lowering the number of hidden LSTM units to 64 maintains the same level of accuracy while also improving it. The mean absolute percentage error (MAPE) ranges from 23.6% for the full 128-unit model to 12.4% for the 64-unit model. The optimized model is 73% smaller (from 280KB to 76KB) and 47% more accurate. These results show that larger models do not always achieve better results.
💡 Deep Analysis
📄 Full Content
Optimizing LSTM Neural Networks for
Resource-Constrained Retail Sales Forecasting: A
Model Compression Study
Ravi Teja Pagidoju
Software and AI Developer in Retail, USA
Professional MBA student
Campbellsville University
Rpagi719@students.campbellsville.edu
Abstract—Standard LSTM(Long Short-Term Memory) neural
networks provide accurate predictions for sales data in the
retail industry, but require a lot of computing power. It can
be challenging especially for mid to small retail industries.
This paper examines LSTM model compression by gradually
reducing the number of hidden units from 128 to 16. We used
the Kaggle Store Item Demand Forecasting dataset, which has
913,000 daily sales records from 10 stores and 50 items, to
look at the trade-off between model size and how accurate the
predictions are. Experiments show that lowering the number of
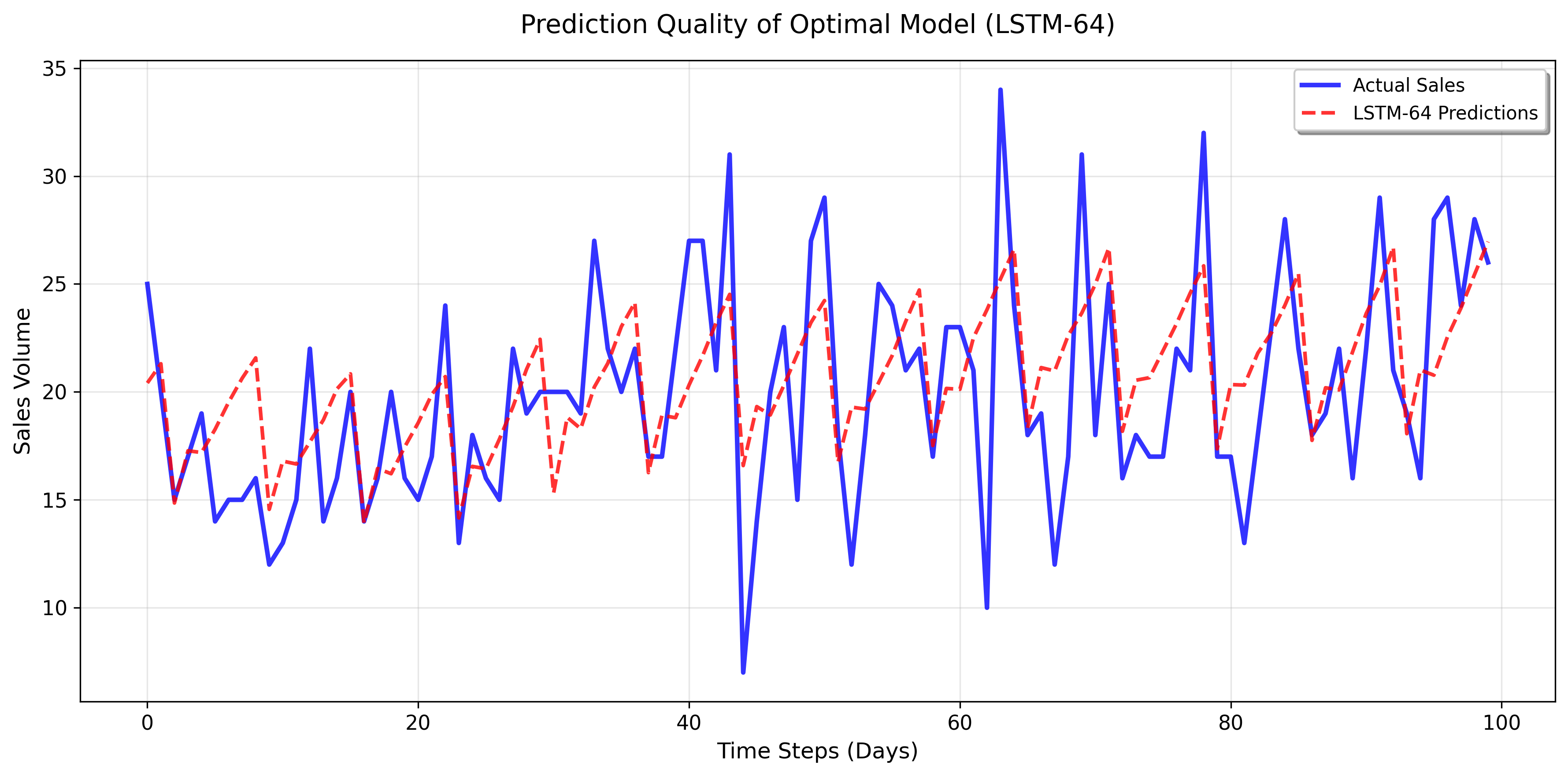
hidden LSTM units to 64 maintains the same level of accuracy
while also improving it. The mean absolute percentage error
(MAPE) ranges from 23.6% for the full 128-unit model to 12.4%
for the 64-unit model. The optimized model is 73% smaller (from
280KB to 76KB) and 47% more accurate. These results show that
larger models do not always achieve better results.
Index Terms—LSTM compression, neural network optimiza-
tion, retail forecasting, edge computing, model efficiency
I. INTRODUCTION
Forecasting retail sales data is very important for planning
day-to-day operations and managing inventory. Retailers lose
approximately 1.75% of their annual sales due to stock short-
ages and excess inventory, typically caused by poor forecasting
[1]. Deep learning models, especially Long Short-Term Mem-
ory (LSTM) networks, have outperformed traditional methods
by reducing errors by 20-30%. [2].
It is challenging to deploy an LSTM network. According
to [3], a standard LSTM with 128 hidden units needs an
infrastructure of 4 to 8 GB of memory and particular hardware
to support. This can be challenging for small and medium-
sized stores to compute and figure out accurate forecast data
because they do not have the computing power they need.
Medium-sized stores make up 65% of the global retail market,
but their IT(Tech) budgets typically range from $50,000 to
$100,000 annually [4].
Model compression could address the problem by making
neural networks smaller while maintaining the same or higher
accuracy. Previous compression research has focused on com-
puter vision tasks [5]; however, retail forecasting introduces
distinct challenges with temporal dependencies and seasonal
0Code available at: https://github.com/RaviTeja444/sales-forecast-LSTM
patterns. No previous study has assessed the correlation be-
tween LSTM architecture size and forecast accuracy in the
context of retail applications.
This paper examines the LSTM compression for forecasting
retail sales. We address the following research question: What
is the minimal LSTM architecture that preserves or improves
forecast accuracy? Our contributions are as follows.
• Systematic evaluation of LSTM network sizes from 16
to 128 hidden units on real retail data
• Discovery that moderate compression (64 units) actually
improves the accuracy
• Practical guidelines for model selection based on the
accuracy-efficiency trade-off
II. RELATED WORK
A. LSTM in Retail Forecasting
LSTM networks excel at capturing long-term dependencies
in sequential data [6]. Bandara et al. [2] showed that the
LSTM models reduced the forecast errors by 25% compared
to the ARIMA models in the retail industry. They built their
architecture with 128 hidden units per layer, and it needed
GPU acceleration to work in the real world.
Recent research analyzes attention mechanisms to improve
LSTM performance. Lim et al. [7] achieved the best results
with Temporal Fusion Transformers, which combines LSTM
with multi-head attention. But these changes made the compu-
tational needs rise to 8GB of memory and 50ms of inference
time for each prediction. This made it even harder for stores
with limited resources to use them. Deep learning approaches
for retail forecasting are further validated by recent surveys
of RNN methods for forecasting [8] and results from the M5
competition [9].
B. Neural Network Compression
There are different ways to reduce the neural network size
through Model Compression techniques:
Pruning: According to Han et al. [5], removing unnecessary
connections can cut the size of the model by 60 to 80% with
little loss of precision. But pruning usually requires special
hardware to perform sparse matrix operations quickly.
arXiv:2601.00525v1 [cs.LG] 2 Jan 2026
Quantization: Jacob et al. [10] showed that changing 32-bit
floating-point weights to 8-bit integers has cut memory use by
75% and maintains accuracy within 1–2%. This method works
especially well for edge deployment.
Architecture Reduction: Frankle and Carbin [11] proposed
the lottery ticket hypothesis, showing that smaller networks
can perform similarly to larger networks when they are prop-
erly set. Thi