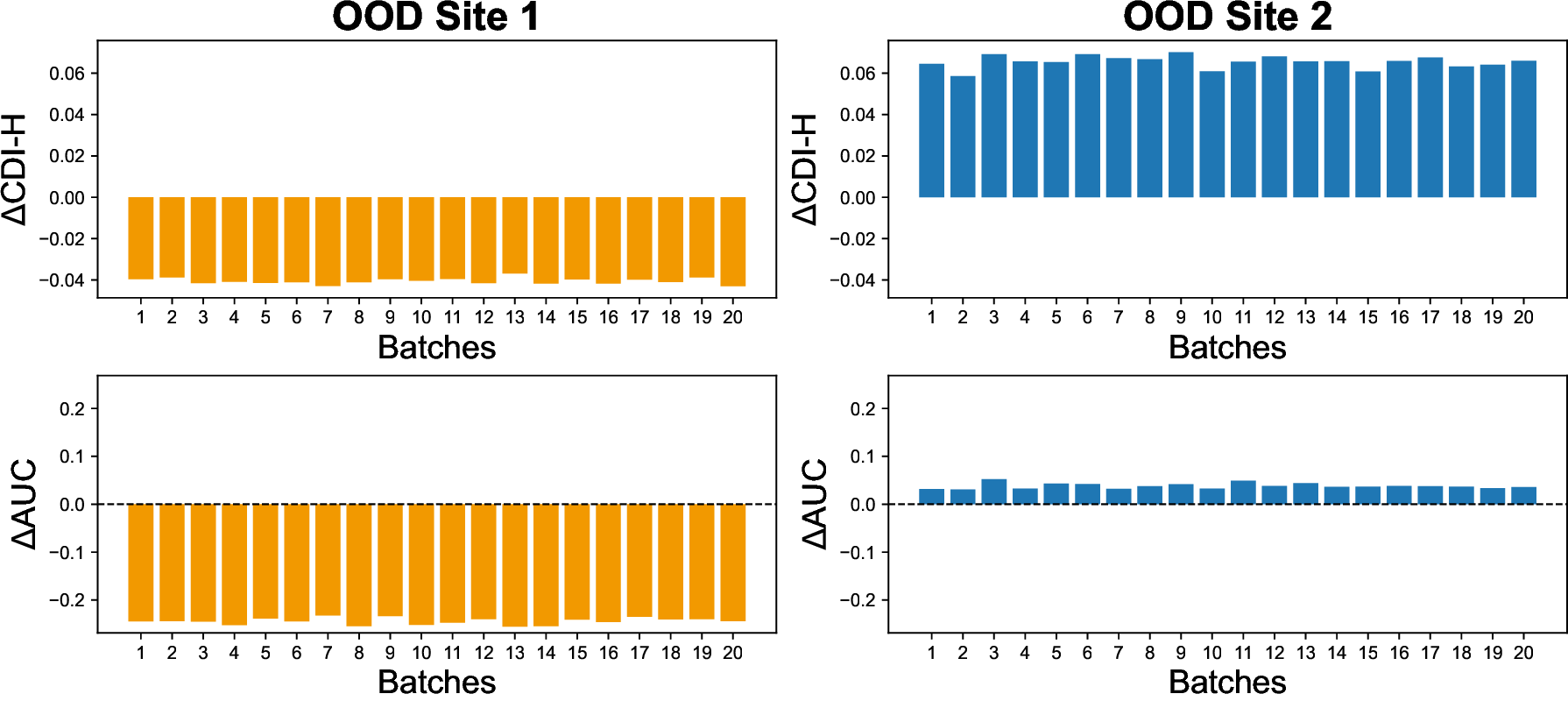
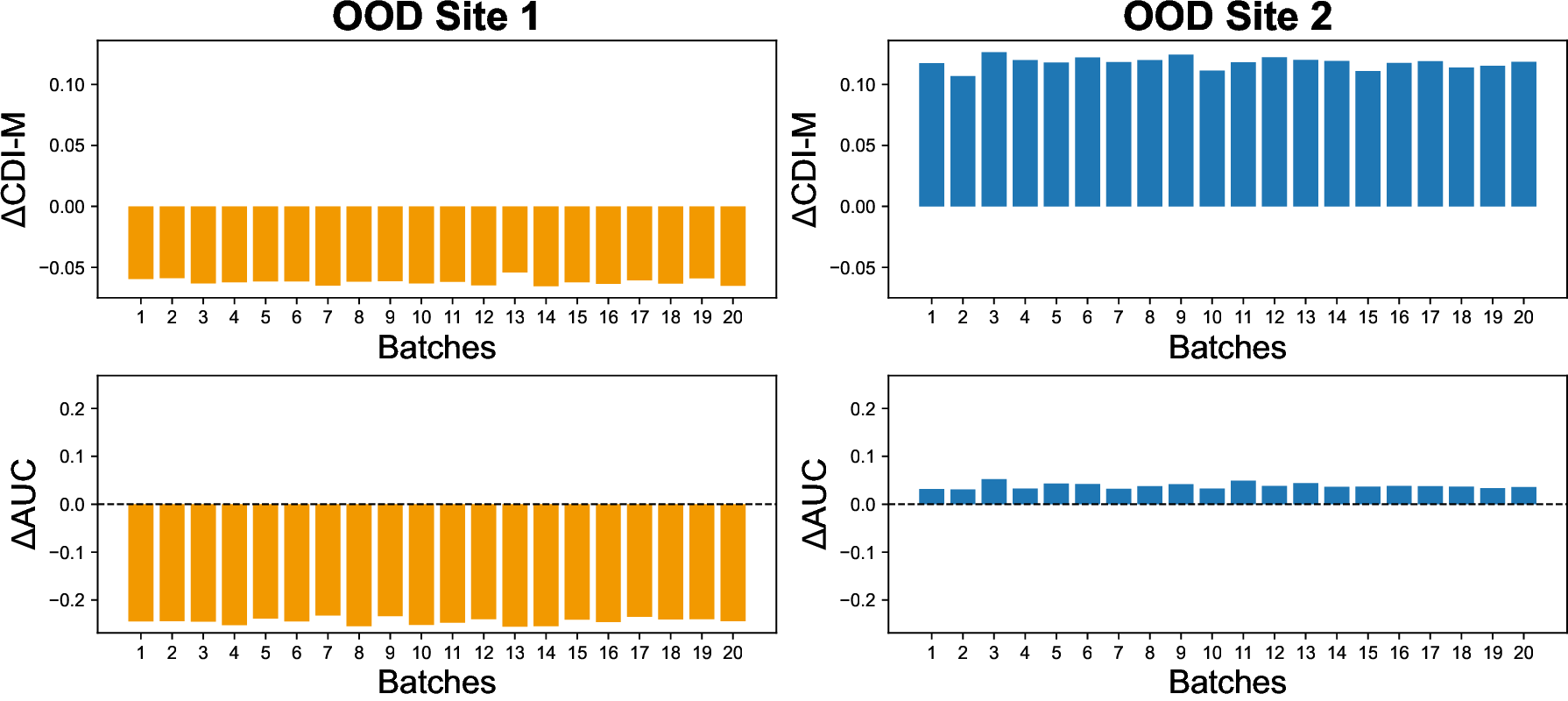
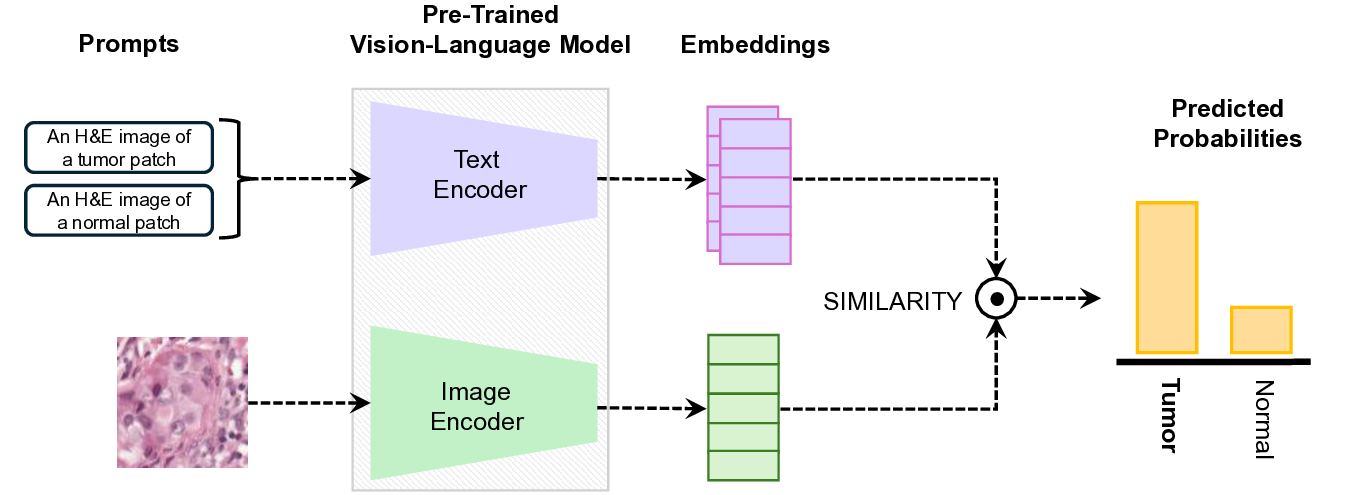
Vision-Language Models have demonstrated strong potential in medical image analysis and disease diagnosis. However, after deployment, their performance may deteriorate when the input data distribution shifts from that observed during development. Detecting such performance degradation is essential for clinical reliability, yet remains challenging for large pre-trained VLMs operating without labeled data. In this study, we investigate performance degradation detection under data shift in a state-ofthe-art pathology VLM. We examine both input-level data shift and output-level prediction behavior to understand their respective roles in monitoring model reliability. To facilitate systematic analysis of input data shift, we develop DomainSAT, a lightweight toolbox with a graphical interface that integrates representative shift detection algorithms and enables intuitive exploration of data shift. Our analysis shows that while input data shift detection is effective at identifying distributional changes and providing early diagnostic signals, it does not always correspond to actual performance degradation. Motivated by this observation, we further study output-based monitoring and introduce a label-free, confidence-based degradation indicator that directly captures changes in model prediction confidence. We find that this indicator exhibits a close relationship with performance degradation and serves as an effective complement to input shift detection. Experiments on a largescale pathology dataset for tumor classification demonstrate that combining input data shift detection and output confidence-based indicators enables more reliable detection and interpretation of performance degradation in VLMs under data shift. These findings provide a practical and complementary framework for monitoring the reliability of foundation models in digital pathology.
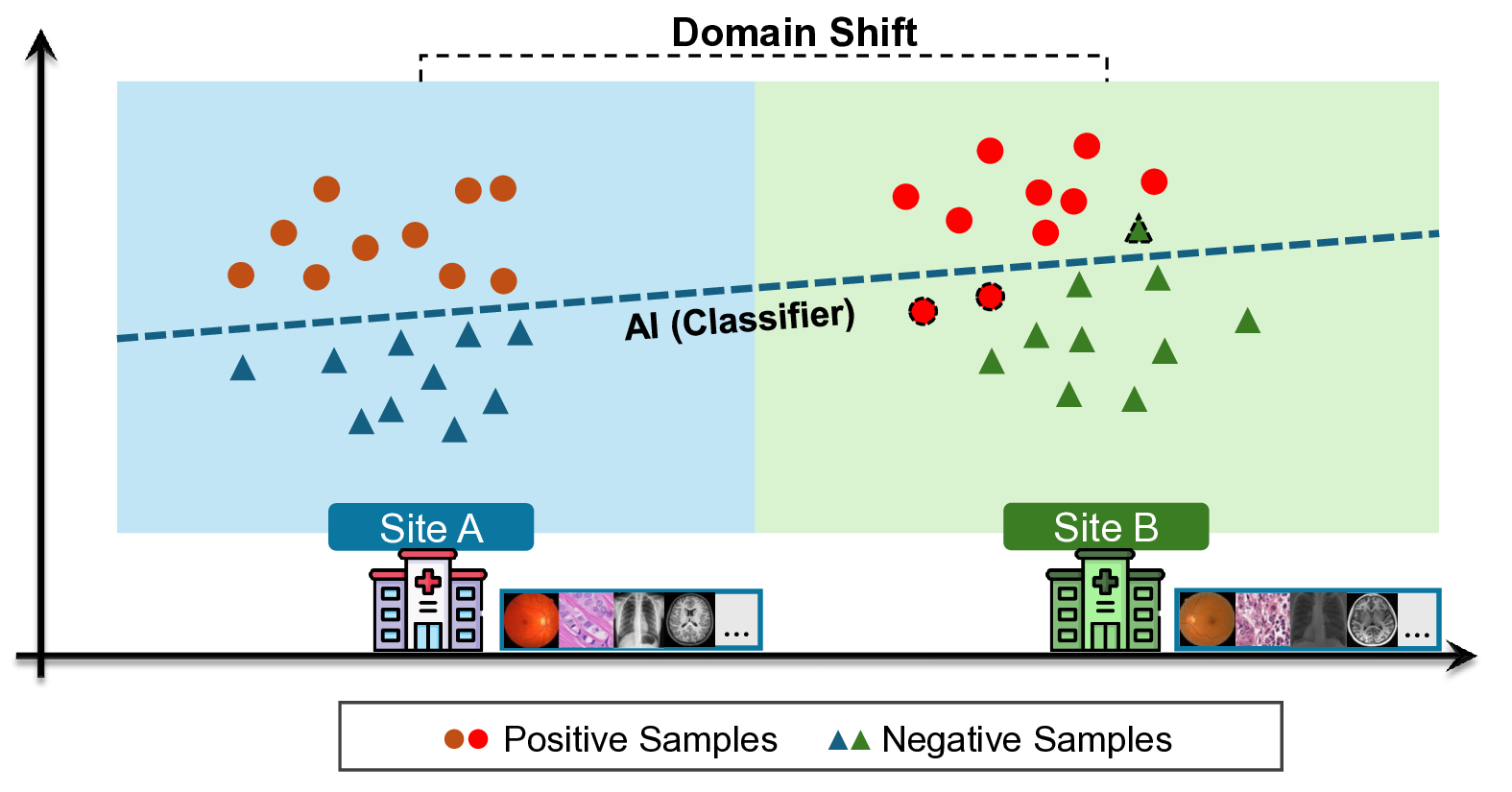
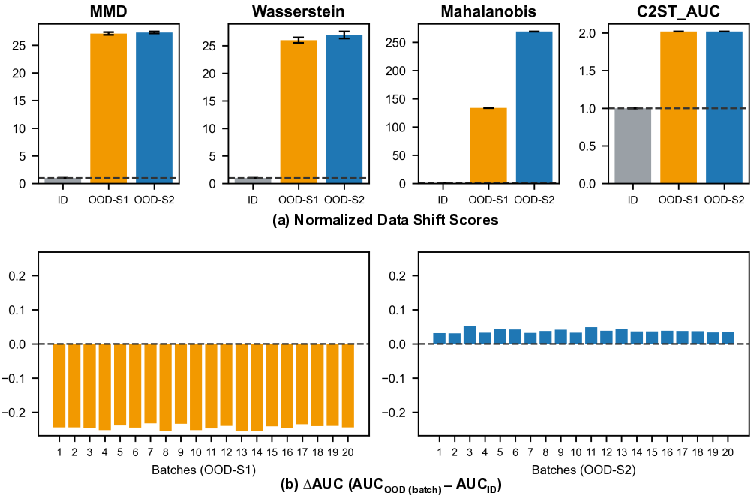
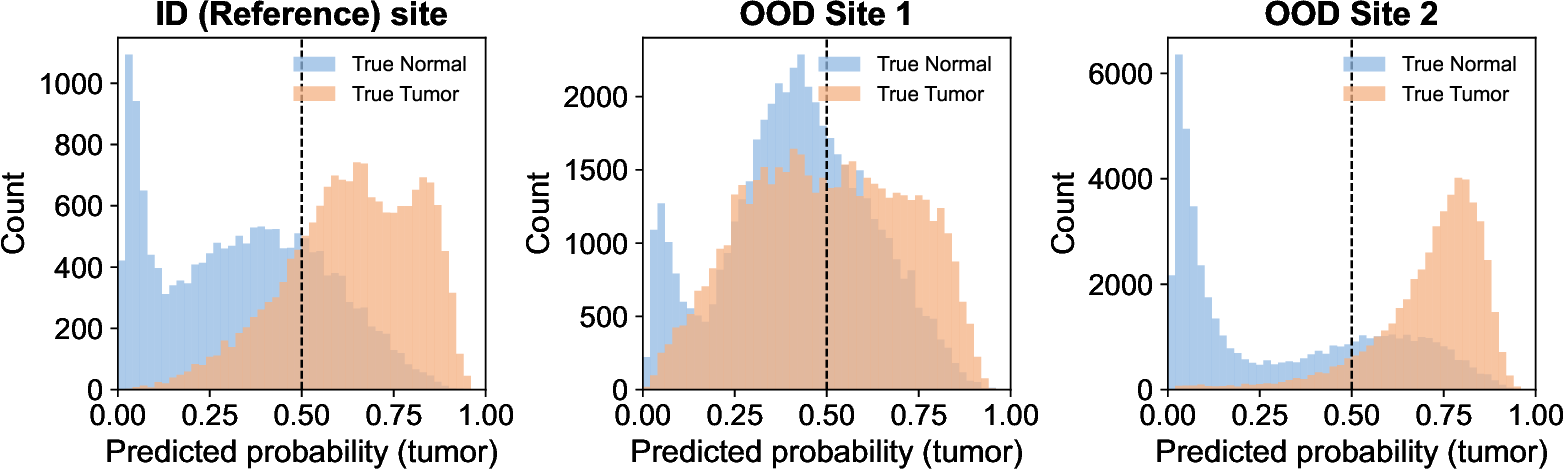
R ECENT advances in Vision-Language Models (VLMs) have greatly expanded the capabilities of artificial intelligence in medicine [1]- [4]. By jointly encoding visual and textual information, VLMs (e.g., CLIP [1]) and their medical adaptations have enabled flexible zero-shot classification, image-report retrieval, and caption generation across clinical imaging modalities. In digital pathology, VLMs offer a promising foundation for computational diagnosis in pathology. Despite these advantages, the long-term reliability of VLMs in clinical deployment remains uncertain. Once deployed, these models may encounter input data that significantly differ from the observed distribution, arising from variations in scanners, staining procedures, or acquisition sites. This is the well-known domain (data) shift problem [5]- [8]. Such data shifts, as shown in Fig. 1, can cause performance degradation, compromising the safety and trustworthiness of AI-assisted diagnostic systems [9]. Detecting degradation is therefore critical to prevent clinical risks and guide model maintenance.
However, detecting performance degradation in large pretrained pathology VLMs presents several fundamental challenges. First, despite the rapid adoption of VLMs in medical imaging, their post-deployment reliability, particularly performance degradation under real-world data shift, has not been systematically studied. Second, in practical medical settings, ground-truth labels are often unavailable after deployment, making direct detection of performance degradation using standard metrics such as accuracy or AUC infeasible.
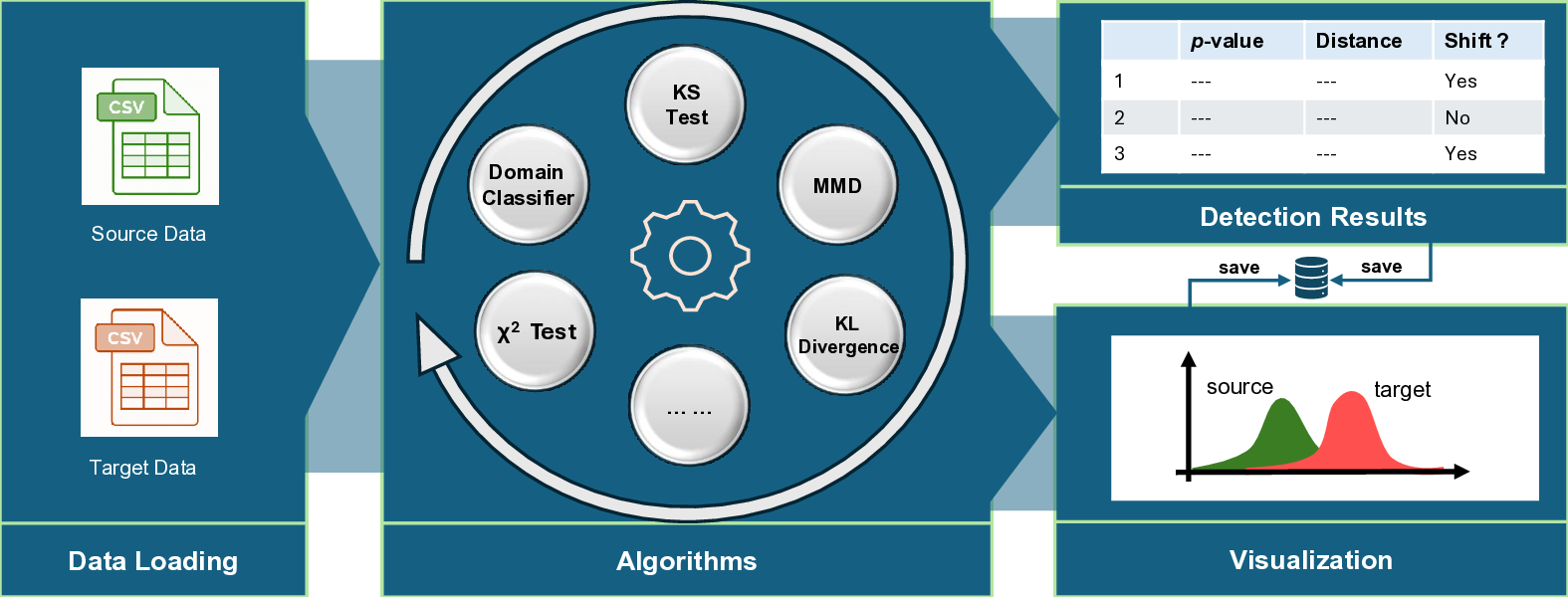
To address this challenge, we investigate performance degradation under data shift in a state-of-the-art pathology VLM by jointly analyzing input data shift and output-level prediction. To support systematic exploration of input data shift, we develop DomainSAT, a lightweight GUI-based toolbox that integrates representative shift-detection algorithms, enabling intuitive inspection of data shifts across datasets. Our analysis confirms that input-level shift detection plays an important role in identifying distributional changes and providing warning signals, but also shows that input data shifts alone are not always predictive of downstream performance degradation.
Motivated by this observation, we further examine outputlevel signals and introduce a simple yet effective, labelfree confidence-based performance degradation indicator. This indicator captures changes in the model’s predictive confidence under shifting data conditions. The underlying intuition is that as a VLM operates farther from its reliable regime, its output confidence distribution becomes less separable and more uncertain which is a sign of performance degradation.
We evaluate the proposed framework using a largescale pathology dataset spanning multiple medical sites with scanner-induced variability. Experimental results demonstrate that output-based confidence indicators closely track performance degradation, while input-level shift detection provides complementary diagnostic context. Together, these signals enable more reliable monitoring and interpretation of performance degradation in pathology VLMs under data shift.
The main contributions of this study are threefold:
• An in-depth investigation of data-shift-induced performance degradation in a state-of-the-art pathology VLM. • A label-free Confidence-based Degradation Indicator (CDI), which provides an effective signal for VLM degradation without requiring ground-truth labels. • DomainSAT, a lightweight GUI toolbox that integrates representative shift-detection methods and facilitates intuitive visualization of data shift patterns. These components provide a practical framework for reliability monitoring of foundation models in digital pathology, with the DomainSAT toolbox publicly available at https: //github.com/guanharry/DomainSAT.
Vision-Language Models (VLMs) learn joint representations of images and text, enabling zero-shot classification and retrieval. General-purpose VLMs such as CLIP [1], BLIP-2 [10], and LLaVA [11] have demonstrated strong generalization across diverse visual domains. Motivated by their success, several medical VLMs have been developed to improve clinical outcomes. These include MedCLIP [2], BiomedCLIP [12], and LLaVA-Med [3], which leverage paired medical image-text data to enhance medical understanding.
In digital pathology, domain-specific VLMs have recently emerged to address the unique challenges of high-resolution histopathology images and fine-grained tissue semantics. Notably, PathGen-CLIP [13], the state-of-the-art model used in this study, is trained on 1.6 million pathology image-text pairs. PathGen-CLIP provides strong pathology-specific embeddings and has demonstrated very good performance in tumor classification tasks. Despite rapid progress, the reliability and performance degradation of pathology VLMs under real-world data shift remain largely unexplored,
This content is AI-processed based on open access ArXiv data.