Recent advancements in Text-to-Video (T2V) generators, such as Sora, have raised concerns about whether the generated content reflects societal biases. Building on prior work that quantitatively assesses associations at the word and image embedding level, we extend these methods to the domain of video generation. We introduce two novel methods: the Video Embedding Association Test (VEAT) and the Single-Category Video Embedding Association Test (SC-VEAT). We validated our approach by replicating the directionality and magnitude of associations observed in widely recognized baselines, including Implicit Association Test (IAT) scenarios and OASIS image categories. We apply our methods to measure associations related to race (African American vs. European American) and gender (male vs. female) across: (1) valence (pleasant vs. unpleasant), (2) 7 awards and 17 occupations that were stereotypically associated with a race or gender. We find that European Americans are significantly more associated with pleasantness than African Americans (d > 0.8), and women are significantly more associated with pleasantness than men (d > 0.8). Furthermore, effect sizes for race and gender biases correlate positively with real-world demographic statistics of the percentage of men (r = 0.93) and White individuals (r = 0.83) employed in the occupations, and the percentage of male (r = 0.88) and non-Black (r = 0.99) recipients of the awards. This suggests that bias in T2V generators, to a large extent, reflects historical patterns of demographic disparities in occupational and award distributions. We applied explicit debiasing prompts on the award and occupation video sets, and observed a monotonic reduction in the magnitude of effect sizes. In the context of this study, it means that the generated content is more associated with marginalized groups regardless of existing directionality of association. Blind adoption of prompt based bias mitigation strategy can exacerbate bias in scenarios already associated with marginalized groups: two Black-associated occupations (janitor and postal service work) became more associated with Black individuals after incorporating explicit debiasing prompts. Together, these results reveal that easily accessible T2V generators can actually amplify representational harms if not rigorously evaluated and responsibly deployed. Warning: the content of this study can be triggering or offensive to readers.
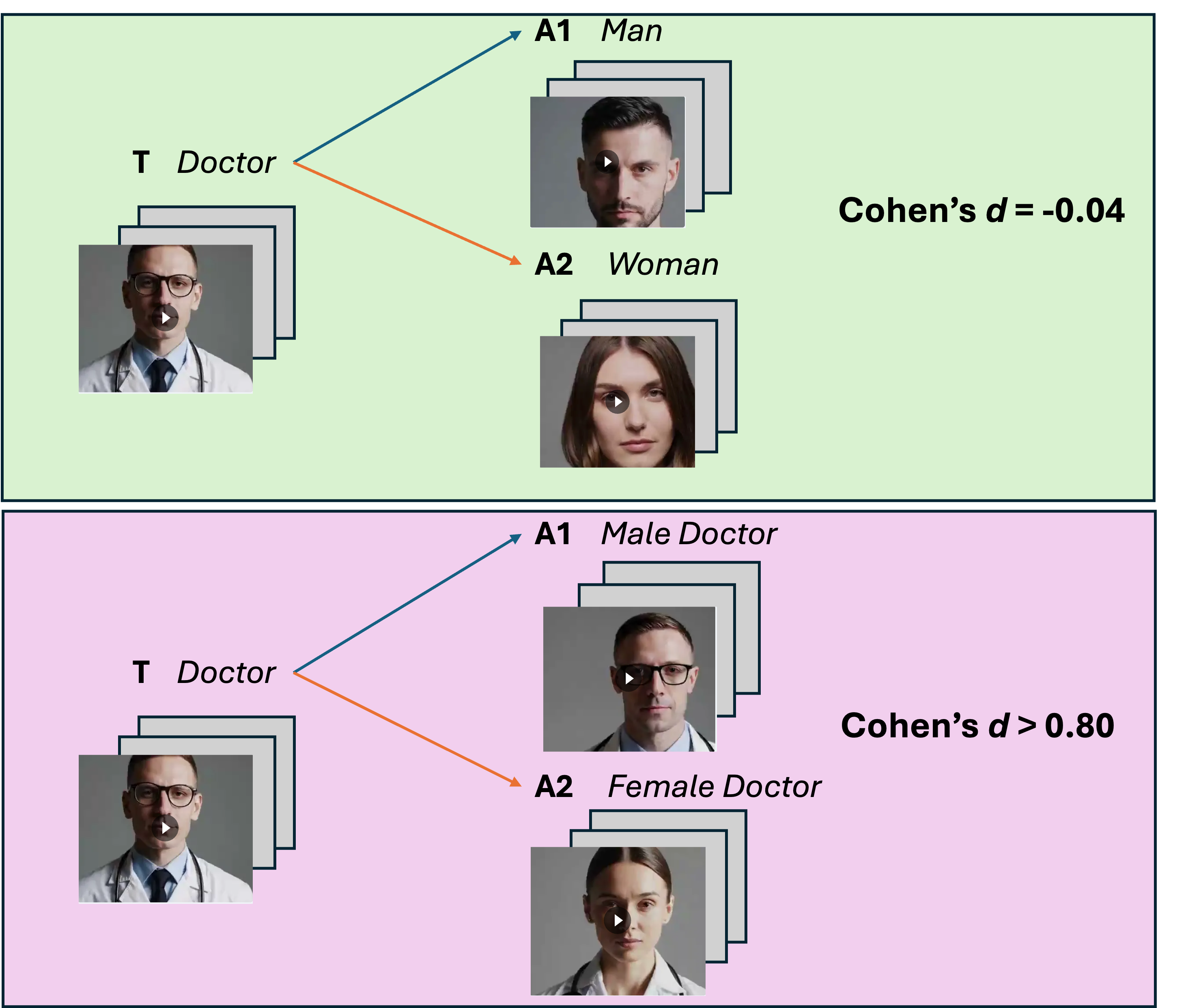
The Video Embedding Association Test (VEAT) quantifies associations between two target and two attribute groups, and Single-Category VEAT (SC-VEAT) evaluates associations for a single target group against two attribute sets. Association magnitude and directionality metric is effect size (Cohen's d) [8]. Targets and attributes can be non-social concepts (e.g., flowers vs. insects), social groups (men vs. women), occupations (e.g., nurse), or valence (pleasant vs. unpleasant). Each target and attribute set is represented by 30 videos. Images involving humans are blurred.
As Text-to-Video (T2V) generators become increasingly prevalent in society, concerns regarding the perpetuation of harmful stereotypes and biases embedded within their outputs have grown. Vision Language Models were shown to learn human-like biases related to social groups [14,29,10,13,18,17], and such biases can have severe real-world implications, potentially reinforcing discriminatory practices and prejudiced perceptions in critical areas like employment, education, and social interactions [30,38]. Therefore, it is crucial to develop approaches to quantitatively assess the magnitude and directionality of bias in T2V generators and explore potential ways to mitigate it, given the unique temporal and spatial characteristics of the video modality. While Embedding Association Tests (EATs) have been developed to quantify association and biases in text [5], and image modalities [31], EATs have yet to be extended to video modality. We introduce the Video Embedding Association Test (VEAT) and the Single-Category Video Embedding Association Test (SC-VEAT), which use embeddings to quantitatively measure biased associations in text-to-video models. Figure 1 illustrates how VEAT and SC-VEAT quantify associations between target and attribute video sets.
As generative models become increasingly used and integrated, they may perpetuate valence-based biases by associating groups with negative attitudes. Valence refers to attitudes of pleasantness or unpleasantness associated with a person or thing. The valence humans associate with groups of people play a central role in shaping social attitudes and discrimination, driving valence-based biases [37,34]. We present the first study to quantify race-and gender-related valence bias in 2
T2V generation. 1 Since exclusion or under-representation in prestigious occupations and awards could lead to allocational and representational harms [7,9], our analysis quantifies race and gender bias within the videos generated for 7 awards and 17 occupations with documented stereotypical associations with a race or gender.
Our findings suggest that the magnitude and directionality of biases in T2V generators align with those documented in the Implicit Association Test (IAT) [16], text modality [4,33], and image modality [13,2] , with respect to race and gender. We highlight the following contributions of this work:
Association Quantification in T2V generator outputs. We develop VEAT and SC-VEATscalable association quantification methods that generalize to non-social groups (flower, insect, instrument, weapon), social groups (man, woman, Black, White), and abstract concepts (pleasantness, unpleasantness). We encourage future studies to leverage our approach to study multidimensional and intersectional bias associations in T2V outputs.
Identification of significant race and gender bias in T2V generator outputs. We find that women are more associated with pleasantness than men (d > 0.8), and European Americans are more associated with pleasantness than African Americans (d > 0.8). We find that STEM awards are more associated with men and European Americans than women and African Americans. Furthermore, the effect sizes correlate positively with gender and race demographics across 17 occupations and 7 awards, mirroring real-world disparities.
Risk of prompt-based bias mitigation strategy in T2V generators. We adapt the LLM debiasing prompts proposed by [12] to T2V generations , which steered generated content to associate more with marginalized groups across 17 occupations and 7 awards. While this reduces bias when the dominant group is over-represented, it may amplify bias in contexts that are stereotypically associated with marginalized groups, such as Black-associated occupations like postal workers or janitors. Our findings highlight the risk of naive application of prompt-based bias mitigation strategies for T2V generation.
Text to Video Generators We study one of the most advanced T2V generators: OpenAI’s Sora [26]. Given Sora’s popularity and widespread usage [1], it is critical to quantitatively measure the magnitude of bias displayed in the model’s output. Sora takes “inspiration from large language models which acquire generalist capabilities by training on internet-scale data.” Instead of using tokens, however, Sora relies on “visual patches” [27]. These visual patches are reduced dimensionalities of raw video
This content is AI-processed based on open access ArXiv data.