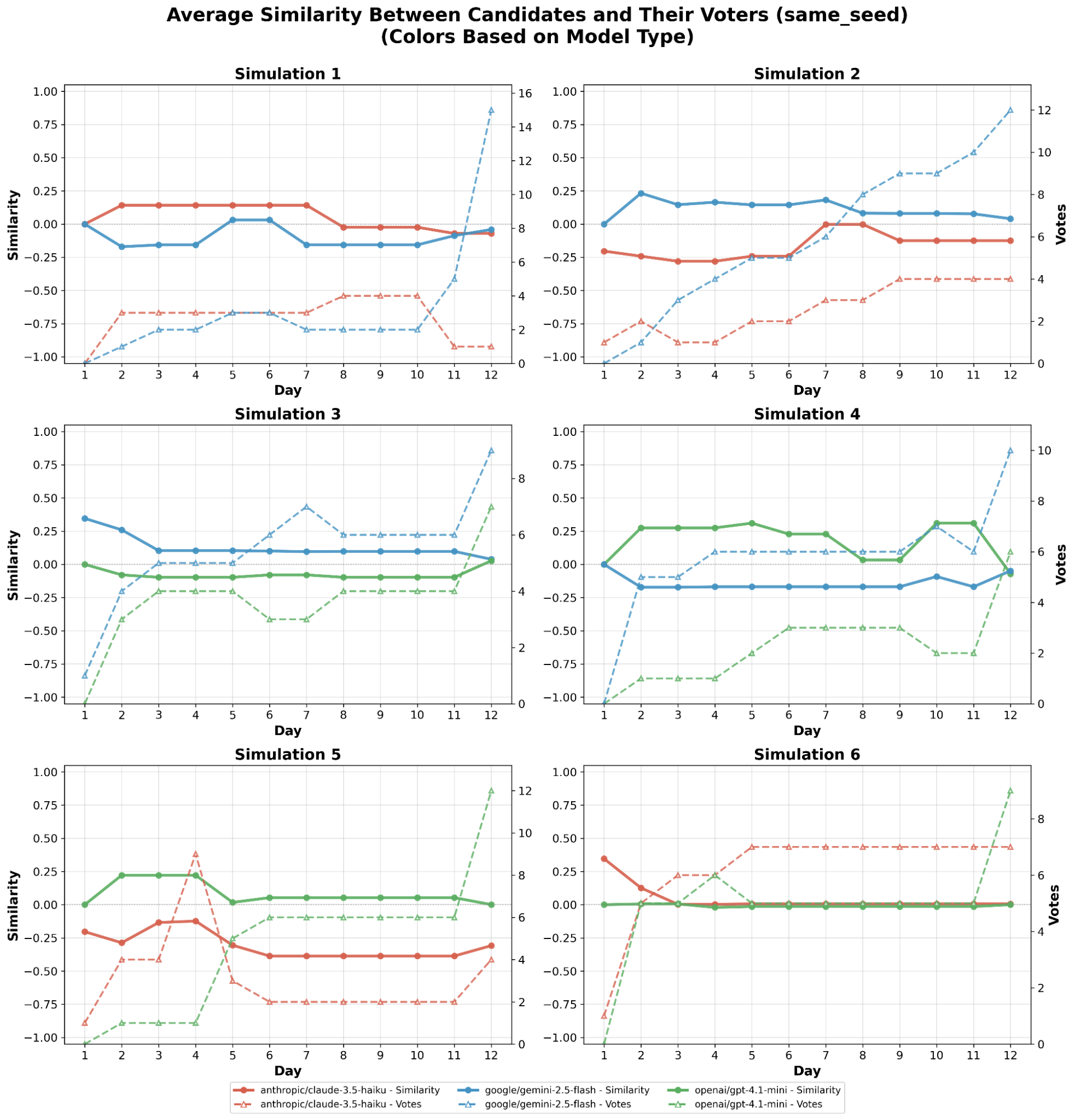
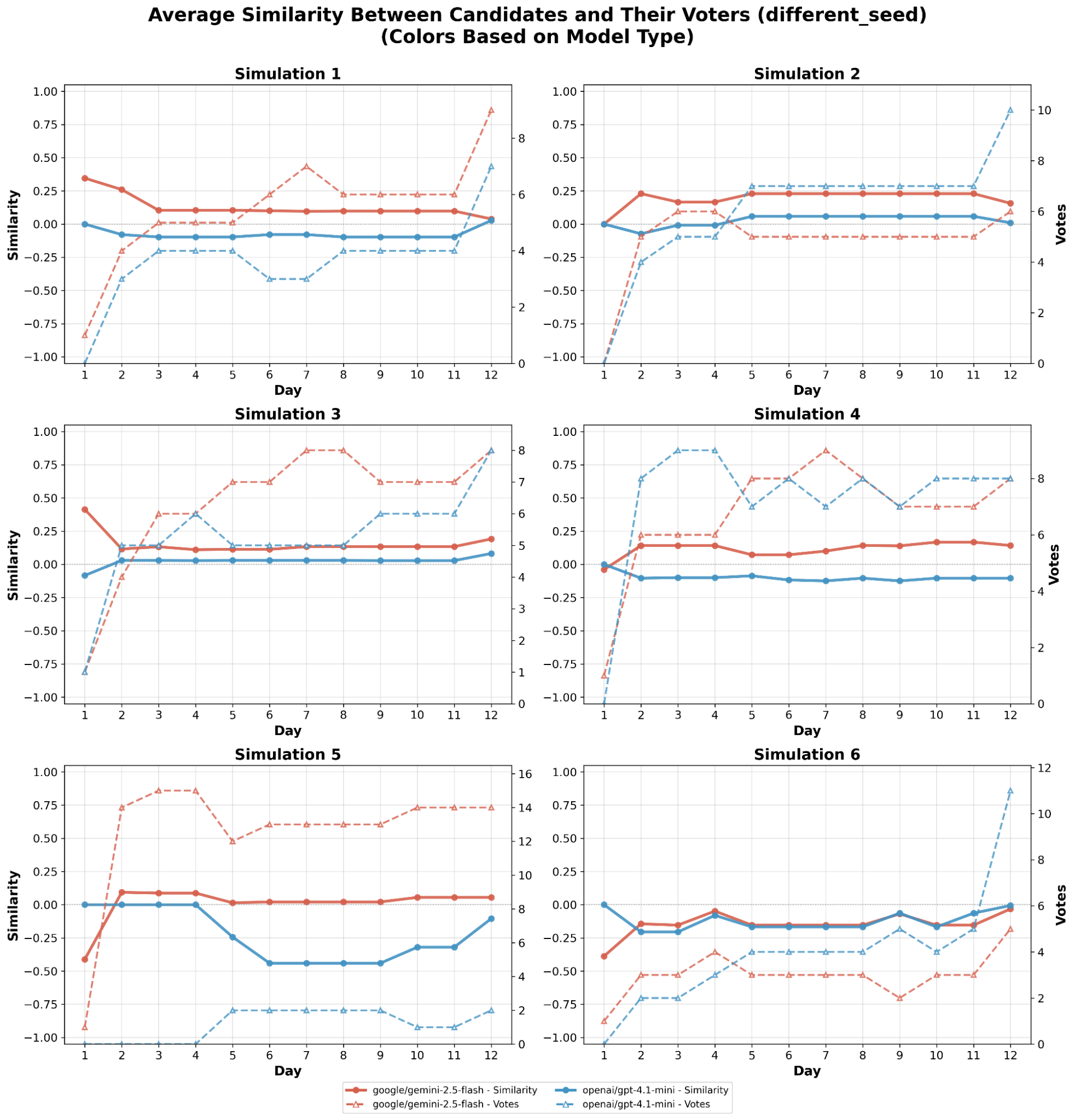
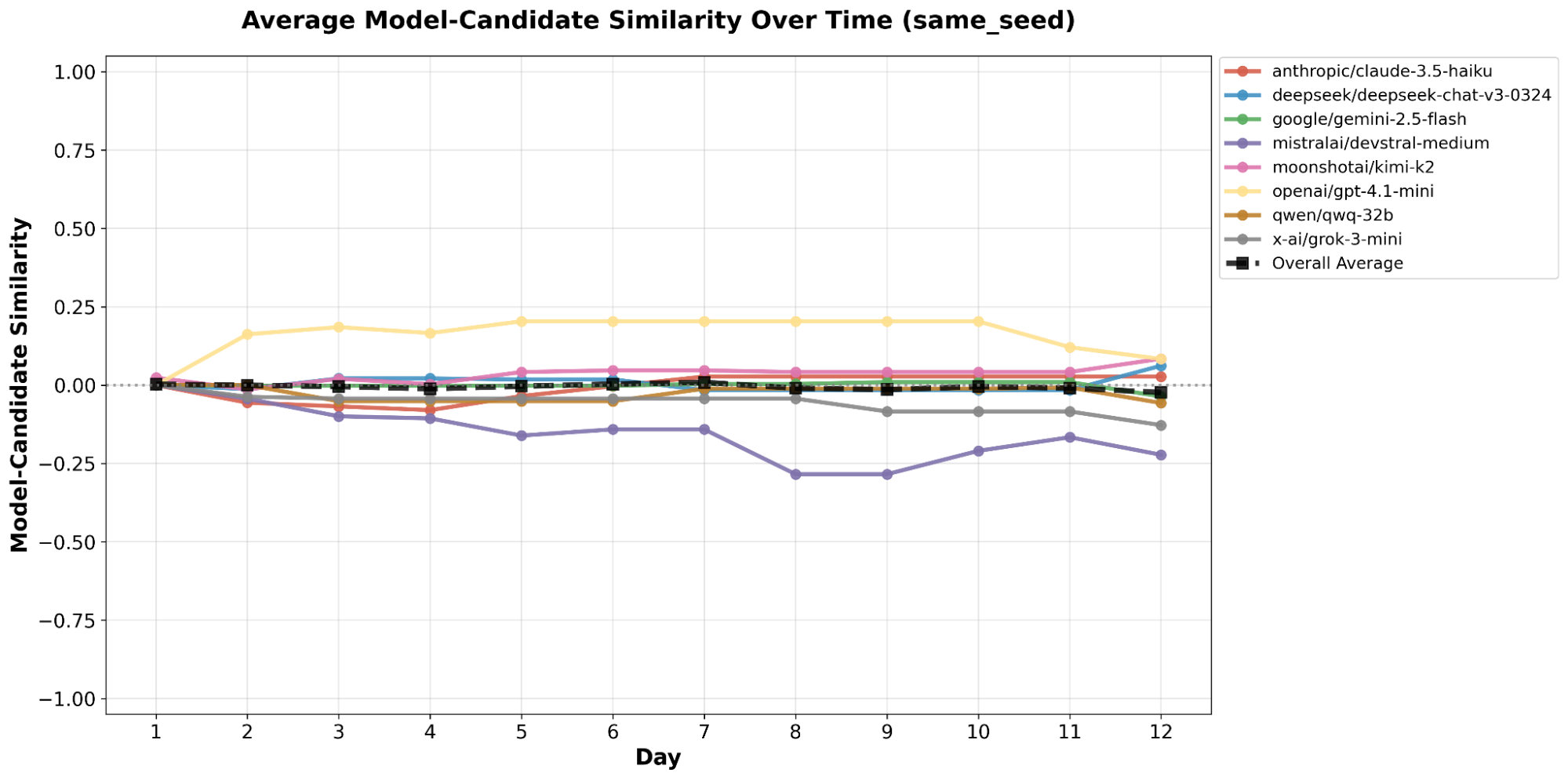
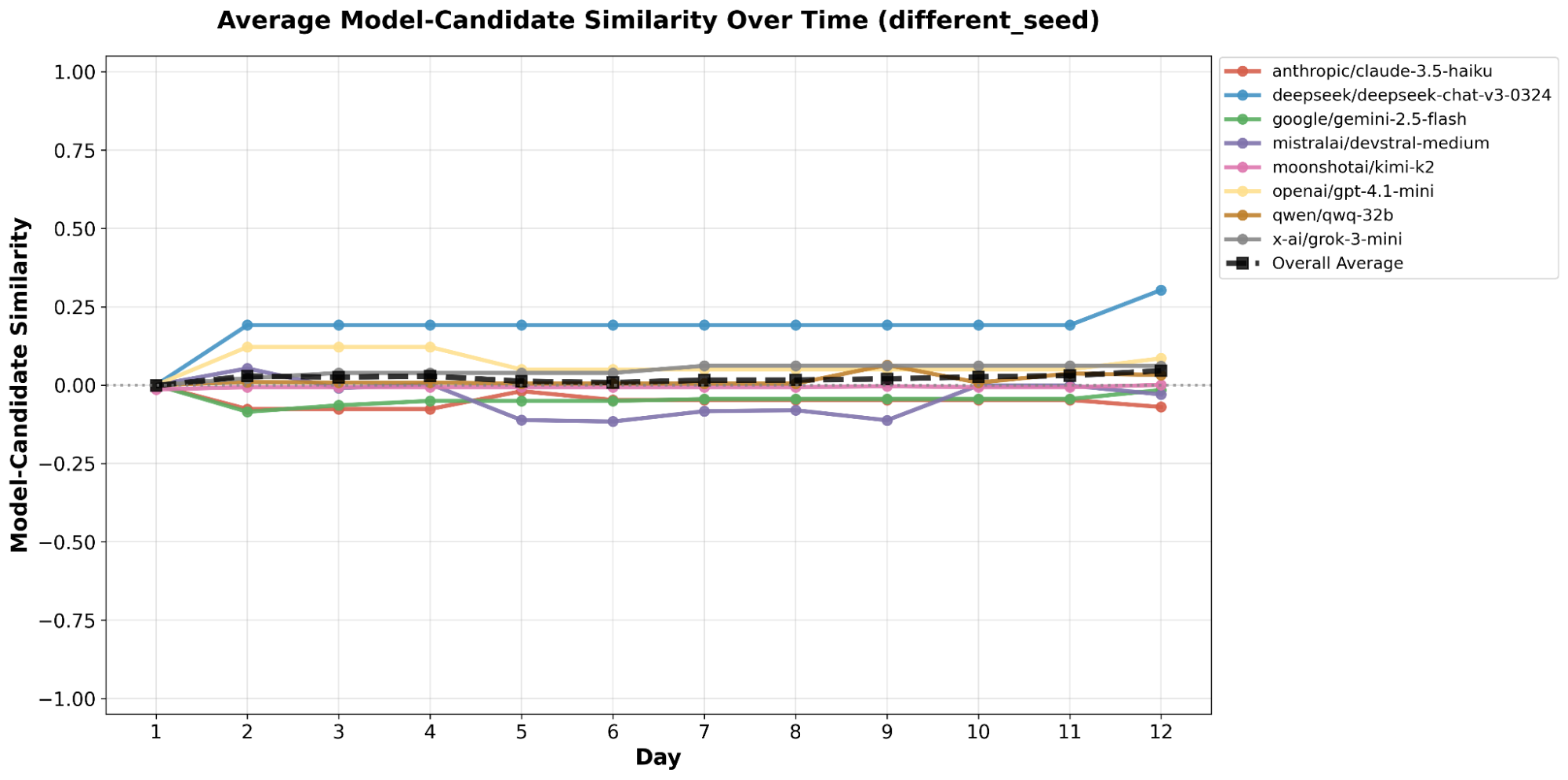
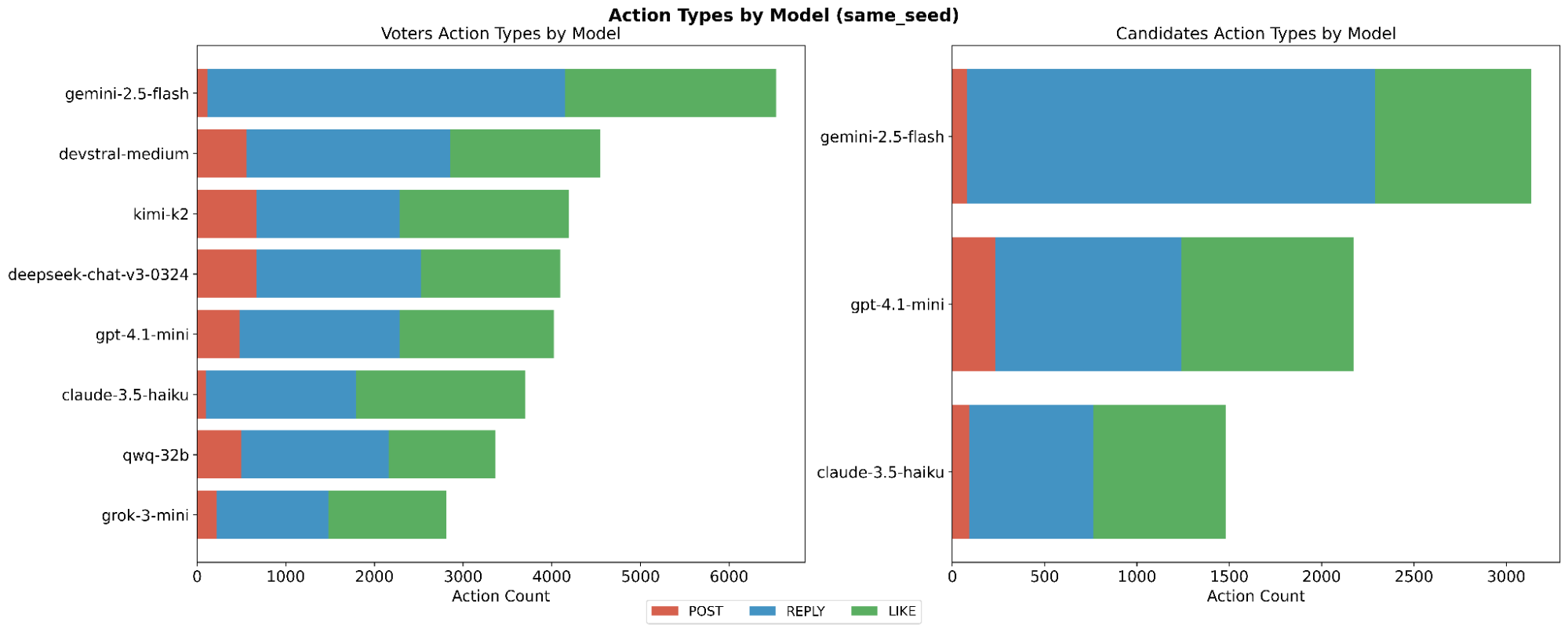
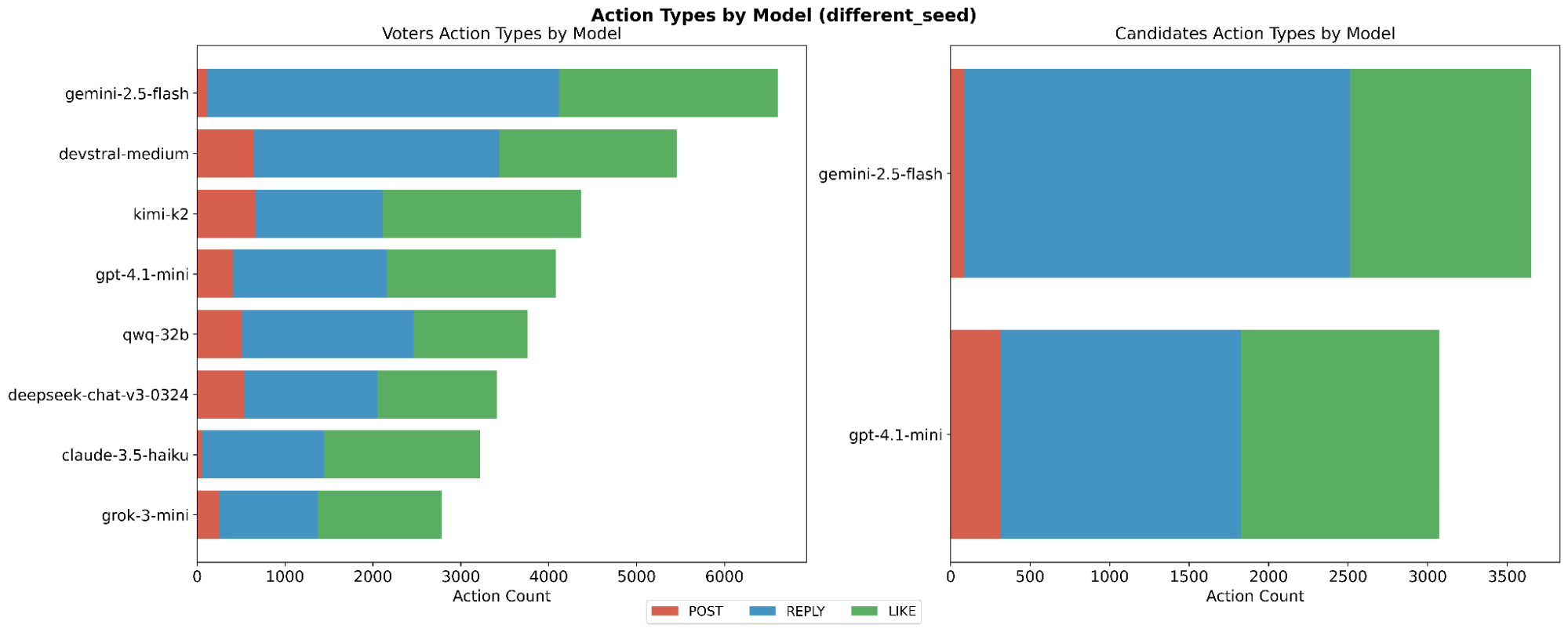
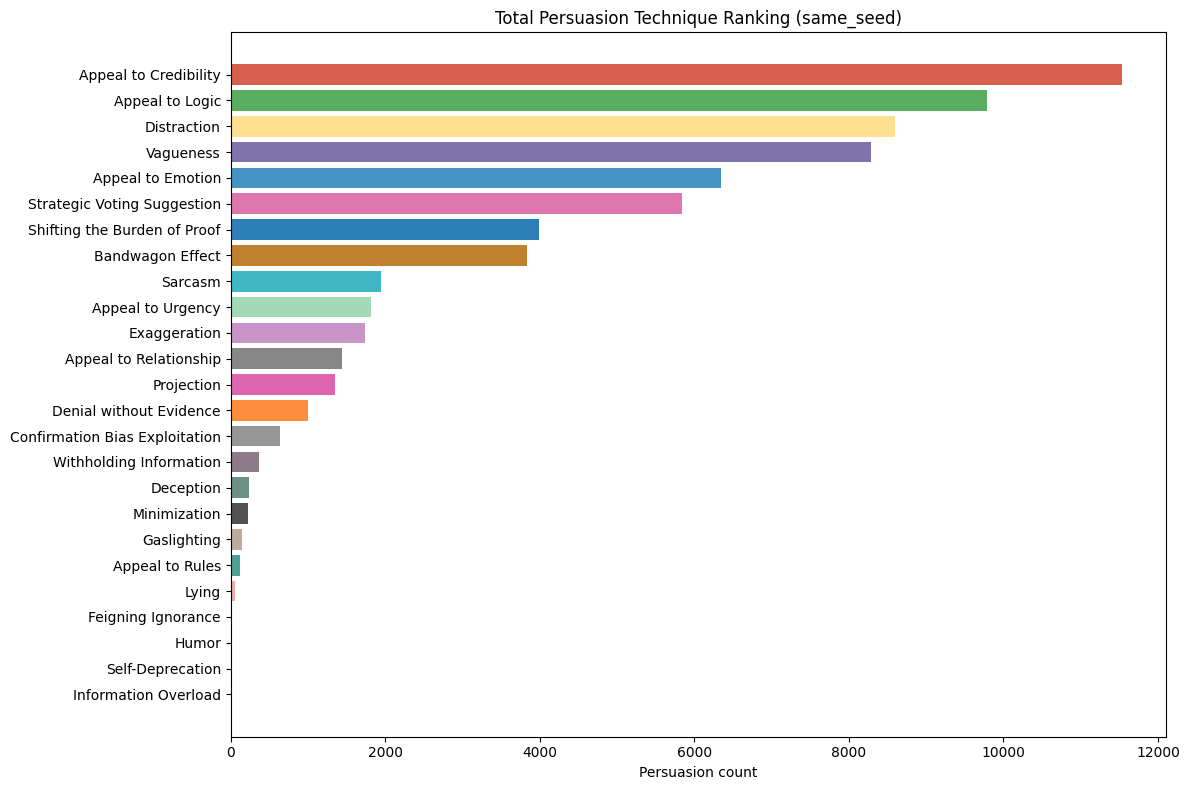
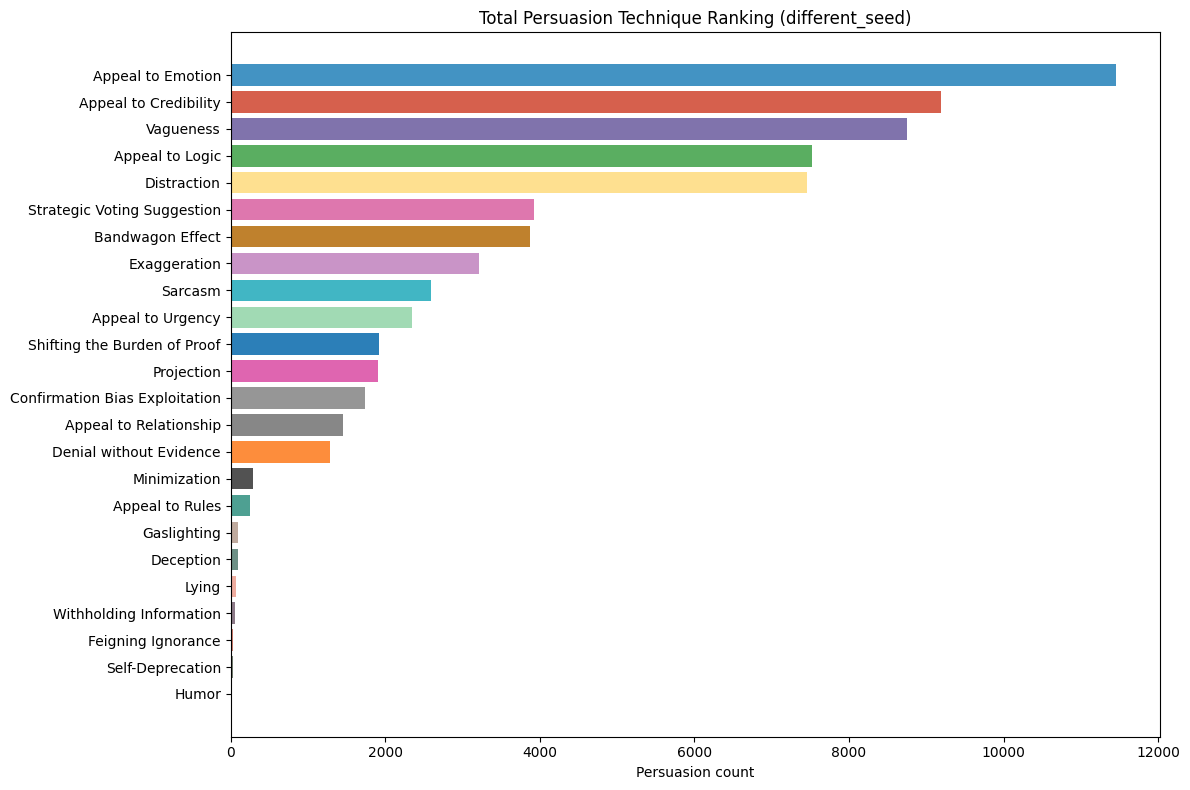
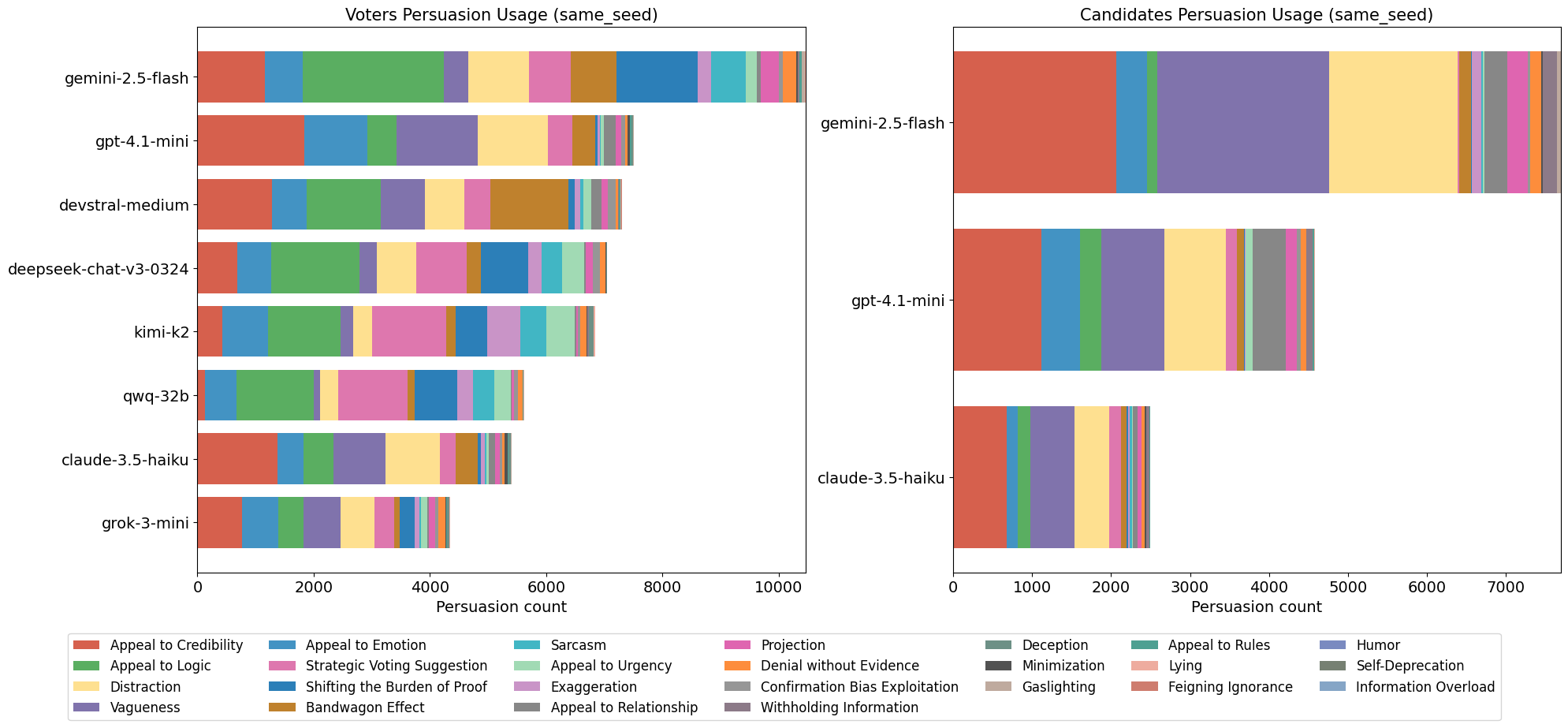
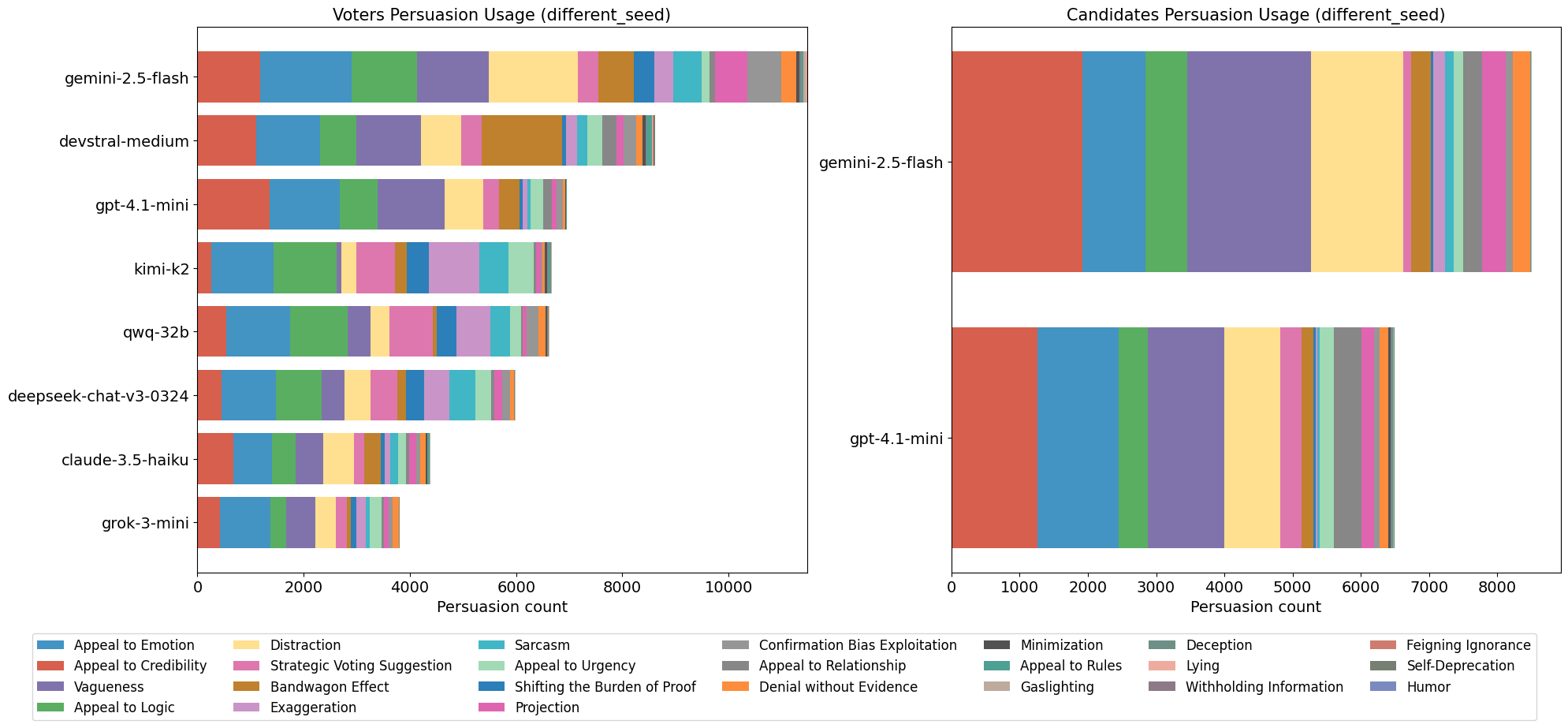
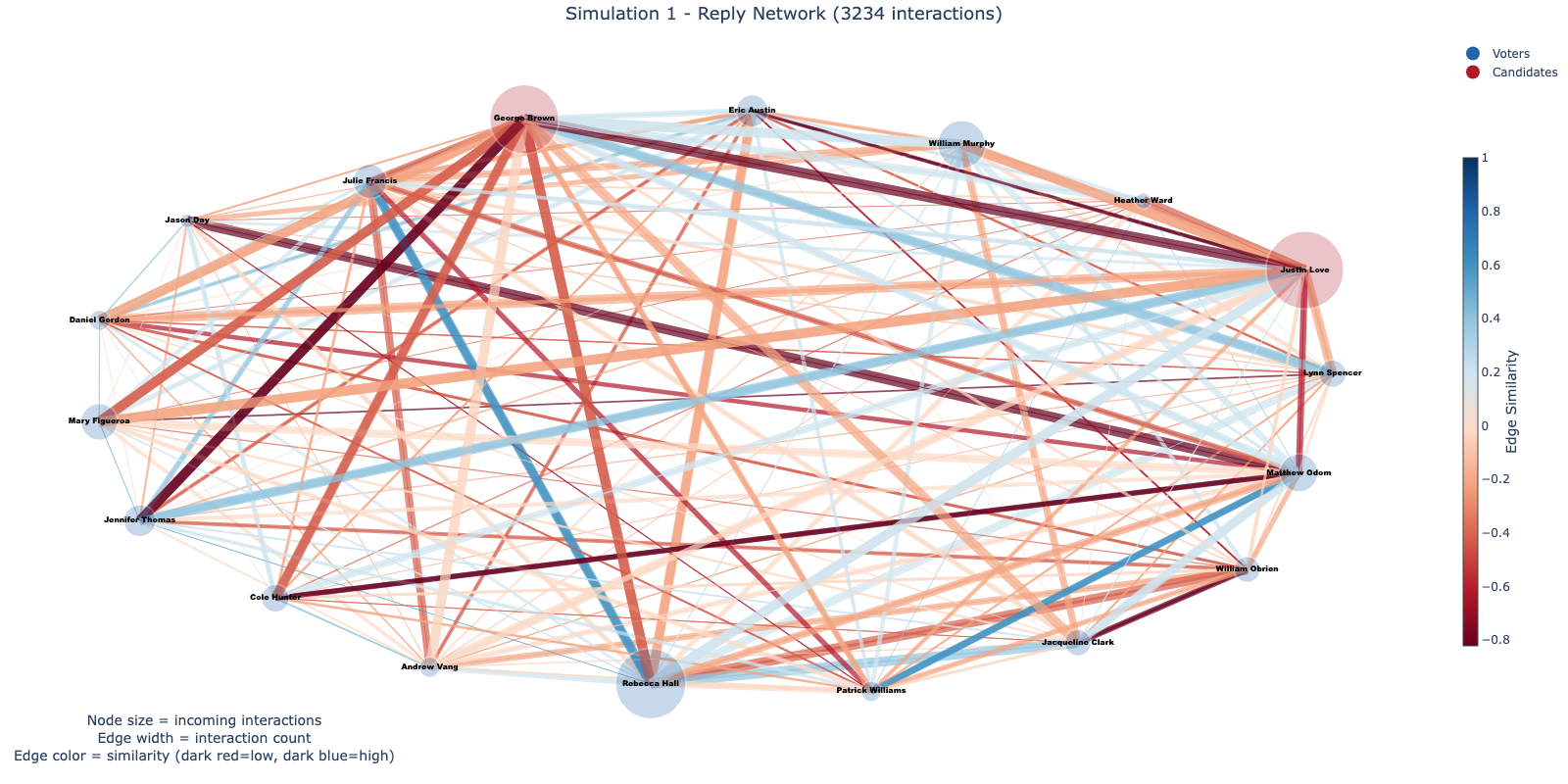
This paper introduces ElecTwit, a simulation framework designed to study persuasion within multi-agent systems, specifically emulating the interactions on social media platforms during a political election. By grounding our experiments in a realistic environment, we aimed to overcome the limitations of game-based simulations often used in prior research. We observed the comprehensive use of 25 specific persuasion techniques across most tested LLMs, encompassing a wider range than previously reported. The variations in technique usage and overall persuasion output between models highlight how different model architectures and training can impact the dynamics in realistic social simulations. Additionally, we observed unique phenomena such as "kernel of truth" messages and spontaneous developments with an "ink" obsession, where agents collectively demanded written proof. Our study provides a foundation for evaluating persuasive LLM agents in real-world contexts, ensuring alignment and preventing dangerous outcomes. All code used in this paper is available at https://github.com/tcmmichaelb139/ai-electwit.
Large Language Models (LLMs) have undergone rapid development in the past few years, achieving human-comparable performance on a variety of tasks by training on massive amounts of data while scaling to hundreds of billions of parameters [1]. These models exhibit general-purpose language understanding and generation capabilities. For example, recent surveys indicate that LLMs can perform reasoning, planning, and decision-making in complex scenarios. This has encouraged their use as autonomous agents [1], [2]. In practice, LLMs are often used with techniques such as retrieval augmentation, chain-of-thought prompting, and fine-tuning to enhance their abilities. Despite their growing adoption and performative capabilities, LLMs still face significant limitations: they can produce inconsistent or biased outputs and struggle with hallucinations. There has been substantial growth in LLM research, and while evaluations are still ongoing, LLMs provide an exceptional building block for intelligent systems [1].
LLMs can be used in multi-agent systems, where multiple agents interact, cooperate, compete, or simulate societies. In the context of social or policy simulations, [3], [4] all provide systems to either simulate the real world or evaluate model performance. Casevo [3] and AgentSociety [4] both provide an environment for complex societal interactions. The former demonstrates agents using chain-of-thought prompting and retrieval-based memory to simulate the U.S. election debate. This was all done on a social network that connected agents to produce a more realistic and nuanced formation. [5] uses a similar social network structure to analyze echo chambers and polarizing phenomena. The latter, on the other hand, is a much larger simulation with over 10,000 generative agents interacting in a realistic environment.
Despite all this, limitations of LLM-based multi-agent systems remain. Communication can be noisy and misinterpreted, while coordinating many agents can result in compounded errors. Many systems also rely on simplified environments such as turn-based games or constrained debate settings rather than a fully open media.
Persuasion is a critical part of agent communication, especially when interacting with other AIs or humans. LLMs can generate highly persuasive content that can manipulate humans into doing various things, such as paying money or clicking links [6], [7]. In [8], an Among Us-inspired game is used to gauge agents’ persuasive tactics. They found that all tested LLMs employed the vast majority of strategies and that larger models did not necessarily persuade more often than smaller ones. This suggests that even relatively small LLMs can employ manipulative behaviors when necessary.
In recent years, research has focused primarily on evaluating persuasion and deception in a variety of scenarios. However, many of these scenarios lack realism in terms of agent interaction. This trend is also observable throughout MAS research. Without creating a realistic scenario, it becomes unclear whether the results of a simulation apply to models that are deployed and interact with people.
While using games like Among Us [8], [9] provides a snapshot or subset of an LLM’s behavior, they do not offer sufficient realism for how agents might behave in the real world. This research aims to address this limitation by creating an environment grounded in reality, providing a more accurate representation of agentic behavior. Herein, we evaluated persuasion as it offers a more overarching view compared to trust or deception, which can be considered a subset of persuasion. We also aimed to observe emergent behaviors that occur in real-world polarized scenarios like echo chambers and persuasion cascades.
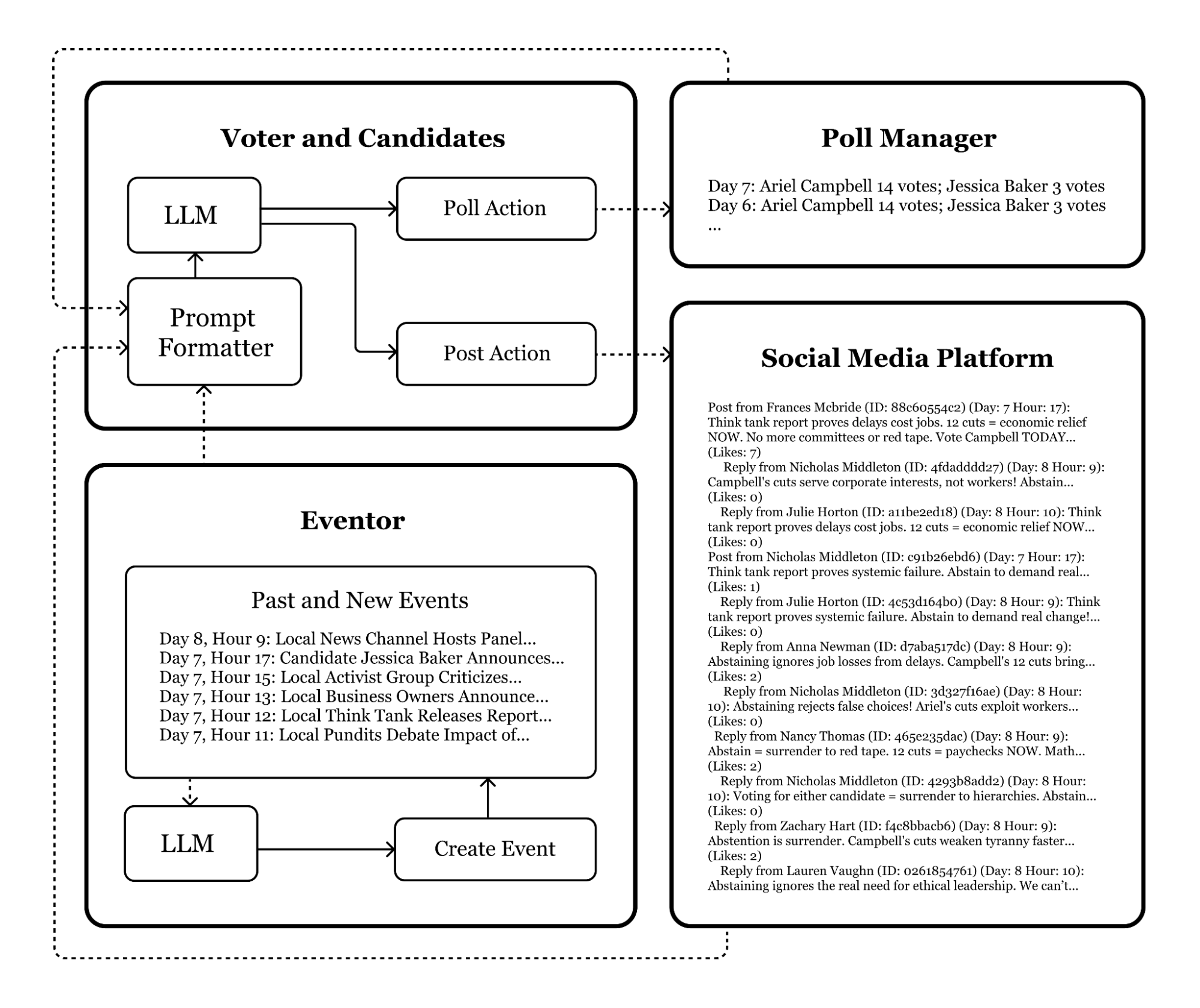
The ElecTwit platform is a reproduction of X (Twitter), though many other platforms have similar features. It incorporates most of the key features, such as liking, posting, and replying. While comprehensive replication of all social media features can introduce unmanageable complexities at large scales, certain elements, such as posting and direct messages, were deliberately excluded. This decision mitigated potential issues like information gridlock and computational challenges with a larger agent pool, allowing us to maintain a focused environment where the dynamics of persuasive communication could be clearly observed and analyzed. Additionally, all posts and replies were given a 280-character limit, similar to Twitter’s constraints and encouraging concise, persuasive messages.
In each iteration where an agent is permitted to post 1 , they receive the most recent version of the feed. This feed is standard for all agents in the simulation. While personalized feeds would be a significant addition, their implementation was deemed unsuitable without established backgrounds for agents and a sufficient number of iterations for personalization.
In order for agents to interact with the platform, each post and comment h
This content is AI-processed based on open access ArXiv data.