We present judgeWEL, a dataset for named entity recognition (NER) in Luxembourgish, automatically labelled and subsequently verified using large language models (LLM) in a novel pipeline. Building datasets for under-represented languages remains one of the major bottlenecks in natural language processing, where the scarcity of resources and linguistic particularities make large-scale annotation costly and potentially inconsistent. To address these challenges, we propose and evaluate a novel approach that leverages Wikipedia and Wikidata as structured sources of weak supervision. By exploiting internal links within Wikipedia articles, we infer entity types based on their corresponding Wikidata entries, thereby generating initial annotations with minimal human intervention. Because such links are not uniformly reliable, we mitigate noise by employing and comparing several LLMs to identify and retain only high-quality labelled sentences. The resulting corpus is approximately five times larger than the currently available Luxembourgish NER dataset and offers broader and more balanced coverage across entity categories, providing a substantial new resource for multilingual and low-resource NER research.
Recent advances in large language models (LLMs) have redefined the scope of natural language processing (NLP), shifting attention from classification and sequence-labelling tasks to increasingly complex generative applications. This transformation has enabled conversational systems that integrate reasoning, translation, and summarisation within a single multi-task architecture (Brown et al., 2020;Touvron et al., 2023;Jiang et al., 2023). Yet, the reach of these technologies remains uneven. For many less-resourced and under-represented languages, the benefits are limited: they continue to lack fundamental resources such as labelled corpora that support even basic supervised learning tasks, including sequence labelling and text classification (Joshi et al., 2020;Adelani et al., 2022).
Building datasets for such languages remains particularly challenging. Obstacles typically include a scarcity of written material, limited linguistic expertise, and the absence of sustained funding, all of which reinforce a cycle of underrepresentation. When coupled with limited prior research, these constraints make it difficult to bootstrap the resources necessary for progress (Hettiarachchi et al., 2025). In these circumstances, creative and data-efficient strategies for dataset construction are essential. This is the case for Luxembourgish, the national language of Luxembourg and one of three official languages alongside German and French. Despite its official status, Lux-embourgish is the only national language of an EU member state not represented at the EU administrative level, thus remaining absent from standardised resources such as Europarl (Koehn, 2005).
Luxembourgish is under-represented in NLP (Joshi et al., 2020) compared to its larger neighbours German and French, though it shares deep historical and structural ties with both. It evolved from the Moselle Franconian dialect (Gilles, 2019), displaying strong affinities with German while integrating extensive French lexical and grammatical. Code-switching and borrowing are common, particularly in informal written communication, giving the language a dynamic character that further complicates computational treatment. Despite these challenges, the language’s roughly 400,000 speakers (Gilles, 2019), ongoing standardisation efforts, and renewed digital interest make this an opportune moment to improve NLP for Luxembourgish.
In this paper, we present a new methodology for the automatic creation of a named entity recognition (NER) dataset. The methodology is designed to achieve broad and reliable coverage with minimal human supervision. To overcome the bottleneck of manual annotation, we combine distant supervision from Wikipedia (Wikipedia contributors, 2001) and Wikidata (Vrandečić and Krötzsch, 2014) with LLM-based quality control, leveraging the ability of current large models to judge annotation consistency even in languages not officially supported.
We hypothesise that certain LLMs can reliably distinguish high-quality annotated sentences from those containing missing or incorrect tags, thus enabling efficient filtering and scalable dataset construction. Our main contributions1 are as follows:
(1) An open pipeline for automatically constructing annotated NER datasets using Wikipedia, Wikidata, and LLM-based judgements.
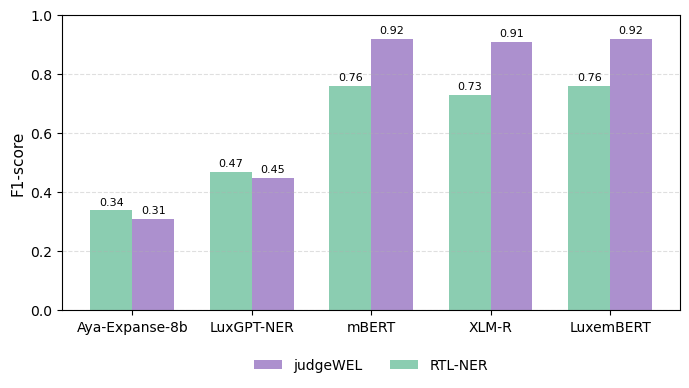
(2) The judgeWEL dataset for Luxembourgish NER, consisting of 28,866 sentences featuring five entity types.
In this section, we summarise related works in the field of NER. Section 2.1 covers general work, Section 2.2 approaches in low-resource (LR) settings, and Section 2.3 focuses on resources for Luxembourgish. This includes existing language resources, both in terms of data and models.
NER is a fundamental Information Extraction and NLP task that identifies and classifies entities (e.g., people, locations, organizations, dates) via sequence labeling schemes such as BIO (Ramshaw and Marcus, 1995a). It builds the base for applications like question answering, translation, summarization, and knowledge base construction.
Research on NER was started with MUC-6 (Sundheim, 1995). Early rule-based systems used linguistic heuristics (Mikheev et al., 1999;Weischedel et al., 1996) and gazetteers (Rau, 1991;Farmakiotou et al., 2000;Nadeau et al., 2006), the latter forming the basis for knowledge-based methods exploiting ontologies (Mendes et al., 2011;Rizzo and Troncy, 2012). These approaches required no labelled data and training but lacked (cross-domain) scalability.
Recent work explores generative and LLM approaches. Zero-shot NER with LLMs as standalone remains challenging (Xie et al., 2023;Hu et al., 2024), but improvements are achieved through prompt engineering and few-shot learning with approaches like PromptNER (Ashok and Lipton, 2023), GL-NER (Zhu et al., 2024), and ProML (Chen et al., 2023). Hybrid frameworks like Su-perICL (Xu et al., 2024) and LinkNER (Zhang et al., 2024) further integrate LLM reasoning with finetuned NER models to enhan
This content is AI-processed based on open access ArXiv data.