Title: Robust Uncertainty Quantification for Factual Generation of Large Language Models
ArXiv ID: 2601.00348
Date: 2026-01-01
Authors: Yuhao Zhang, Zhongliang Yang, Linna Zhou
📝 Abstract
The rapid advancement of large language model (LLM) technology has facilitated its integration into various domains of professional and daily life. However, the persistent challenge of LLM hallucination has emerged as a critical limitation, significantly compromising the reliability and trustworthiness of AI-generated content. This challenge has garnered significant attention within the scientific community, prompting extensive research efforts in hallucination detection and mitigation strategies. Current methodological frameworks reveal a critical limitation: traditional uncertainty quantification approaches demonstrate effectiveness primarily within conventional question-answering paradigms, yet exhibit notable deficiencies when confronted with non-canonical or adversarial questioning strategies. This performance gap raises substantial concerns regarding the dependability of LLM responses in real-world applications requiring robust critical thinking capabilities. This study aims to fill this gap by proposing an uncertainty quantification scenario in the task of generating with multiple facts. We have meticulously constructed a set of trap questions contained with fake names. Based on this scenario, we innovatively propose a novel and robust uncertainty quantification method(RU). A series of experiments have been conducted to verify its effectiveness. The results show that the constructed set of trap questions performs excellently. Moreover, when compared with the baseline methods on four different models, our proposed uncertainty quantification method has demonstrated great performance, with an average increase of 0.1-0.2 in ROCAUC values compared to the best performing baseline method, providing new sights and methods for addressing the hallucination issue of LLMs.
💡 Deep Analysis
📄 Full Content
Robust Uncertainty Quantification for Factual
Generation of Large Language Models
Yuhao Zhang, Zhongliang Yang*, Linna Zhou
School of Cyberspace Security, Beijing University of Posts and Telecommunications, Beijing, China
{yuhaozhang, yangzl, zhoulinna}@bupt.edu.cn
Abstract—The rapid advancement of large language model
(LLM) technology has facilitated its integration into various do-
mains of professional and daily life. However, the persistent chal-
lenge of LLM hallucination has emerged as a critical limitation,
significantly compromising the reliability and trustworthiness of
AI-generated content. This challenge has garnered significant
attention within the scientific community, prompting extensive re-
search efforts in hallucination detection and mitigation strategies.
Current methodological frameworks reveal a critical limitation:
traditional uncertainty quantification approaches demonstrate
effectiveness primarily within conventional question-answering
paradigms, yet exhibit notable deficiencies when confronted with
non-canonical or adversarial questioning strategies. This perfor-
mance gap raises substantial concerns regarding the dependabil-
ity of LLM responses in real-world applications requiring robust
critical thinking capabilities. This study aims to fill this gap by
proposing an uncertainty quantification scenario in the task of
generating with multiple facts. We have meticulously constructed
a set of trap questions contained with fake names. Based on this
scenario, we innovatively propose a novel and robust uncertainty
quantification method(RU). A series of experiments have been
conducted to verify its effectiveness. The results show that the
constructed set of trap questions performs excellently. Moreover,
when compared with the baseline methods on four different
models, our proposed uncertainty quantification method has
demonstrated great performance, with an average increase of 0.1-
0.2 in ROCAUC values compared to the best performing baseline
method, providing new sights and methods for addressing the
hallucination issue of LLMs.
Index Terms—large language model, fake persons’ biographies
generation, robust uncertainty quantification.
I. INTRODUCTION
The extensive application of large language models (LLMs)
in the field of natural language generation (NLG) has led
to a growing reliance on these models in everyday life.
People increasingly turn to LLMs to assist with reading and
understanding documents [1], support decision-making [2],
and complete various tasks by utilizing the models’ responses
and generated content. This increasing dependence has, in turn,
heightened the importance of the credibility and reliability
of the models’ outputs. However, LLMs are inevitably prone
to the issue of “hallucination” [3]. This phenomenon, where
models may produce content that is obscure or fabricated,
poses a significant challenge to the credibility and reliability
of the outputs.
The hallucinations of LLMs can be categorized into factual
hallucinations and faithfulness hallucinations [4]. Faithfulness
*Zhongliang Yang is the corresponding author of this paper. And our code
is available at https://github.com/EdwardChang5467/robust uncertainty.
hallucinations mainly evaluate whether the output is faithful to
the input, while factual hallucinations primarily assess whether
the generated content is consistent with reality. Faithfulness
hallucinations can be identified simply by assessing the rele-
vance between the output and the input. Factual hallucinations,
characterized by their fine-grained nature and scattered distri-
bution, are less likely to be intuitively detected [5]. Models
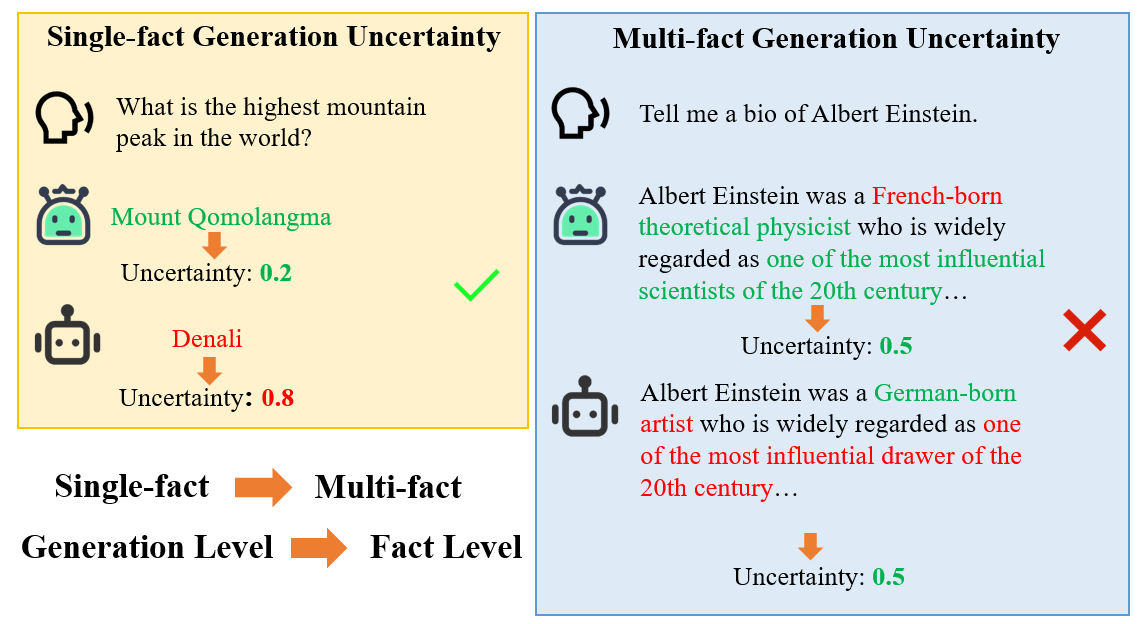
Fig. 1.
The difference in uncertainty quantification between single-fact
generation and multi-fact generation.
may generate content that appears coherent and persuasive
on the surface. For instance, in the task of generating bi-
ographies of real individuals, they may produce outputs con-
taining wrong or fake facts. Alternatively, when inadvertently
prompted by users to generate biographies of fictional indi-
viduals, the models may proceed with the task as if it were
normal. Given the intractability of eliminating hallucinations
in LLMs, we can address this issue by measuring the uncer-
tainty of model-generated outputs externally. By highlighting
answers with high uncertainty, we can alert users to potential
inaccuracies.
Currently, several methods for quantifying the uncertainty
of LLMs’ generations have been proposed. However, these
methods typically consider the uncertainty at the level of the
entire generated text. They rely on the content of the gener-
ated text and the logits information of the generated tokens
for calculation, and are primarily designed to verify single
facts [6]. Nevertheless, when the generated content involves
multiple facts, these existing methods still have limitations
in accurately measuring the uncertainty in such cases. There
can be situations where factual errors exist, but the measur