This paper compares three methodological categories of neural reasoning: LLM reasoning, supervised learning-based reasoning, and explicit model-based reasoning. LLMs remain unreliable and struggle with simple decision-making that animals can master without extensive corpora training. Through disjunctive syllogistic reasoning testing, we show that reasoning via supervised learning is less appealing than reasoning via explicit model construction. Concretely, we show that an Euler Net trained to achieve 100.00% in classic syllogistic reasoning can be trained to reach 100% accuracy in disjunctive syllogistic reasoning. However, the retrained Euler Net suffers severely from catastrophic forgetting (its performance drops to 6.25% on already-learned classic syllogistic reasoning), and its reasoning competence is limited to the pattern level. We propose a new version of Sphere Neural Networks that embeds concepts as circles on the surface of an n-dimensional sphere. These Sphere Neural Networks enable the representation of the negation operator via complement circles and achieve reliable decisionmaking by filtering out illogical statements that form unsatisfiable circular configurations. We demonstrate that the Sphere Neural Network can master 16 syllogistic reasoning tasks, including rigorous disjunctive syllogistic reasoning, while preserving the rigour of classical syllogistic reasoning. We conclude that neural reasoning with explicit model construction is the most reliable among the three methodological categories of neural reasoning.
Reliable decision-making is crucial in high-stakes applications. Although LLMs have achieved unprecedented success in many ways, exemplified in human-like communication (Biever, 2023), playing Go (Silver et al., 2017;Schrittwieser et al., 2020), predicting complex protein structures (Abramson et al., 2024), or weather forecasting (Soliman, 2024), they still make errors in simple reasoning (Mitchell, 2023). In addition, LLMs are prone to making accurate predictions with incorrect explanations (Creswell et al., 2022;Zelikman et al., 2022;Park et al., 2024), and have not yet achieved the reliability necessary for high-stakes applications, i.e., decision-making in biomedicine (Wysocka et al., 2025). In some cases, syllogistic reasoning may appear deceptively simple, such as in the following:
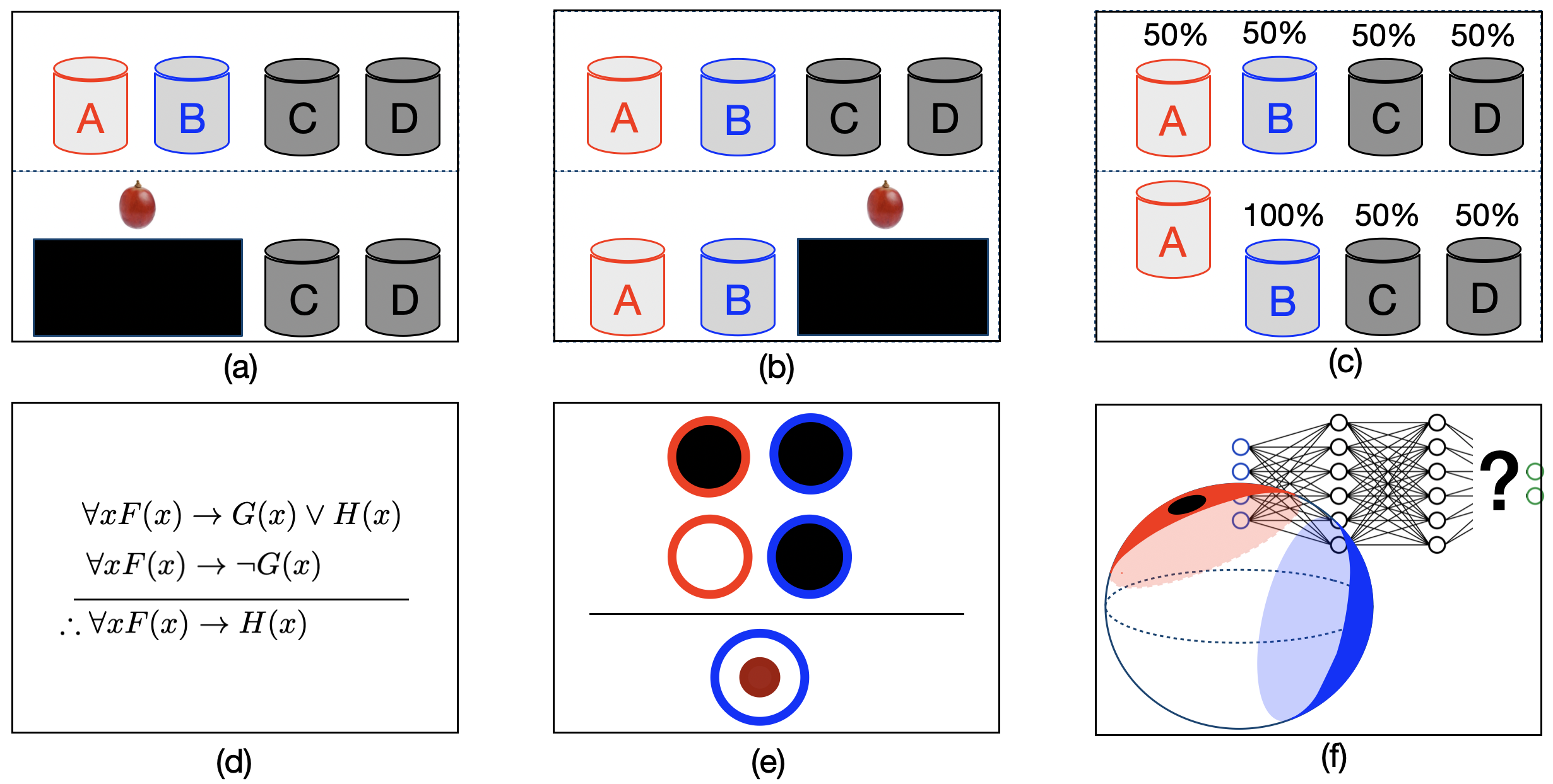
All members of the Diseases of Hemostasis pathway are members of the general Disease pathway. Gene GP1BB is a member of Diseases of hemostasis pathway. Gene GP1BB is a member of Disease pathway. ∴ However, Eisape et al. (2024) show that although LLMs perform better than average humans in syllogistic reasoning, their accuracy remains limited to around 75%, and larger models do not consistently outperform smaller ones. Lampinen et al. (2024) come to the convergent conclusions that, in abstract reasoning such as syllogism, LLMs may achieve above-chance performances in familiar situations but exhibit numerous imperfections in less familiar ones. Wysocka et al. (2025) tested LLMs in several types of generalised syllogistic reasoning, e.g., generalised modus ponens, disjunctive syllogism, in the context of high-stakes biomedicine, and found that zero-shot LLMs achieved an average accuracy between 70% on generalised modus ponens and 23% on disjunctive syllogism. Crucially, both zero-shot and few-shot LLMs demonstrated pronounced sensitivity to surface-level lexical variations. Despite these limitations, evaluating the reasoning performance of LLMs on syllogistic tasks (and beyond) can provide insights into the origins of (human) rationality (Lampinen et al., 2024) and help identify alternative methods for reliable neural reasoning and decision-making. LLMs acquire human-like communication and reasoning abilities by training on large-scale linguistic corpora. However, proficiency in communication does not necessarily equate to proficiency in reasoning (Fedorenko et al., 2024). On the contrary, reasoning and decision-making are abilities that do not necessarily depend on extensive language acquisition. For example, clever monkeys can get grapes through disjunctive syllogistic decision-making (Ferrigno et al., 2021), suggesting that syllogistic reasoning can be elicited through visual-spatial inputs, independent of linguistic abilities. While recent evaluations indicate that LLMs remain unable to achieve robust syllogistic reasoning, in this work, we revisit (Ferrigno et al., 2021)’s experiments to seek alternative neural architectures and neural reasoning methods. We distinguish three categories of neural networks for syllogistic reasoning (illustrated in Figure 1) as follows:
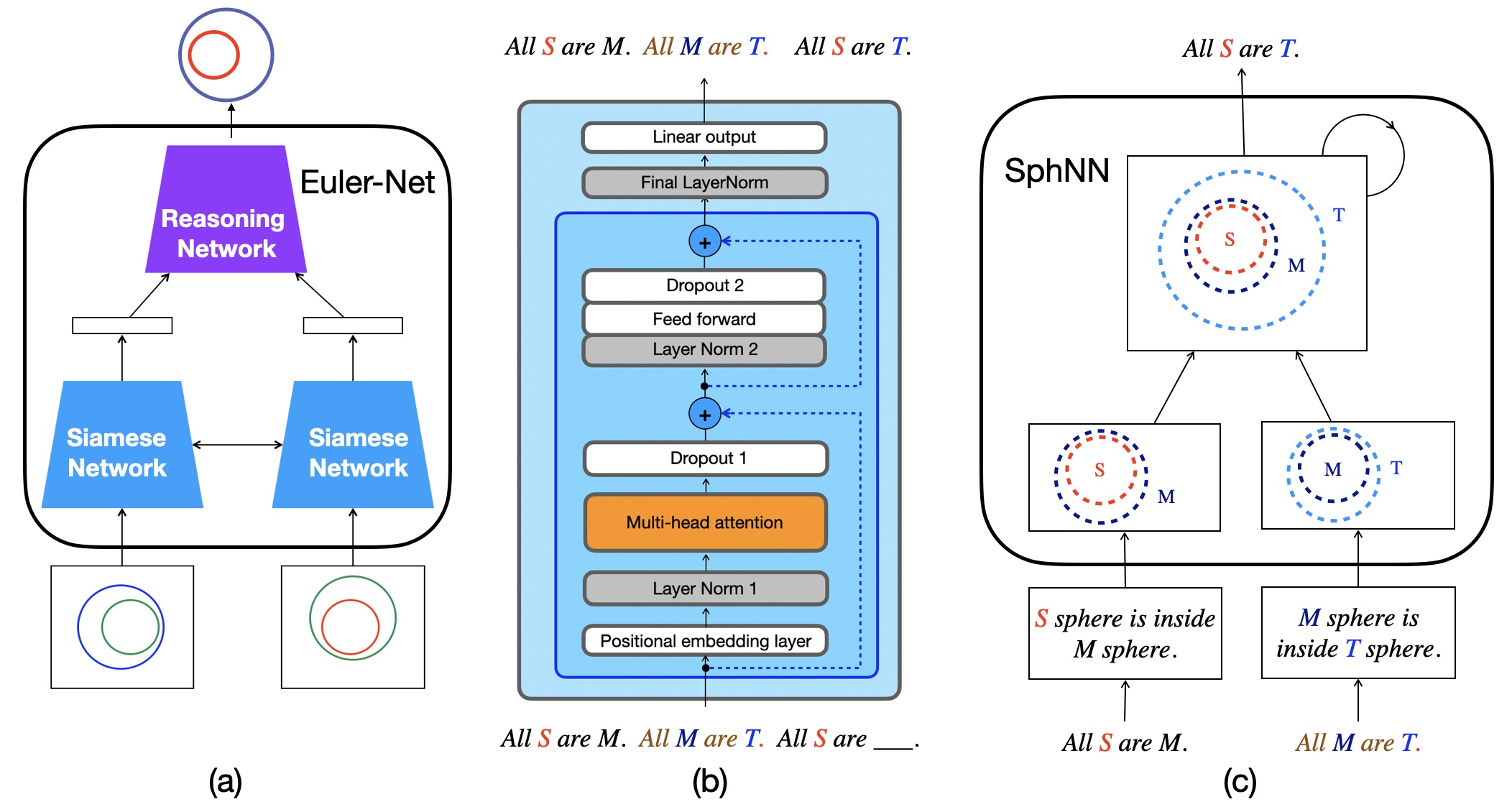
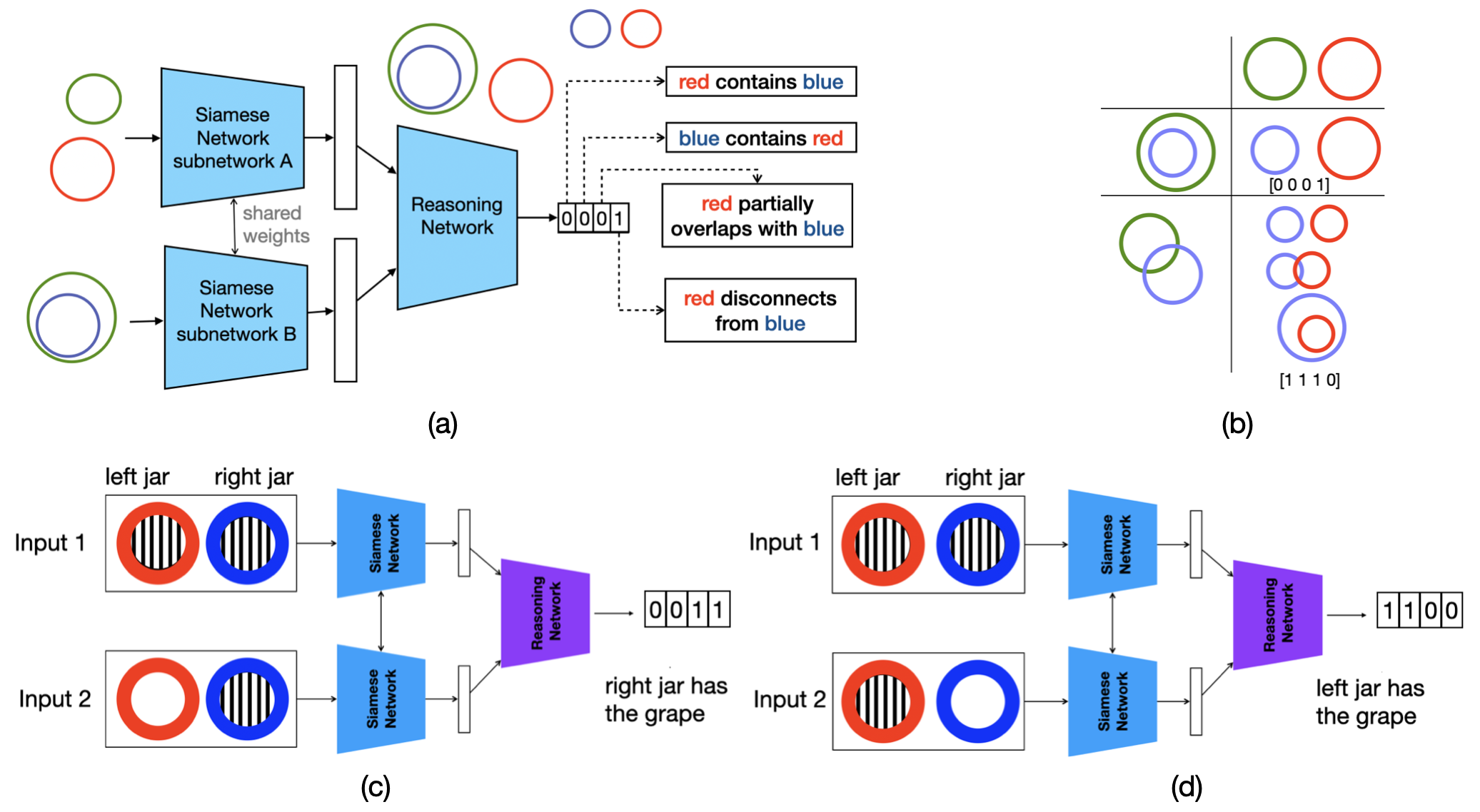
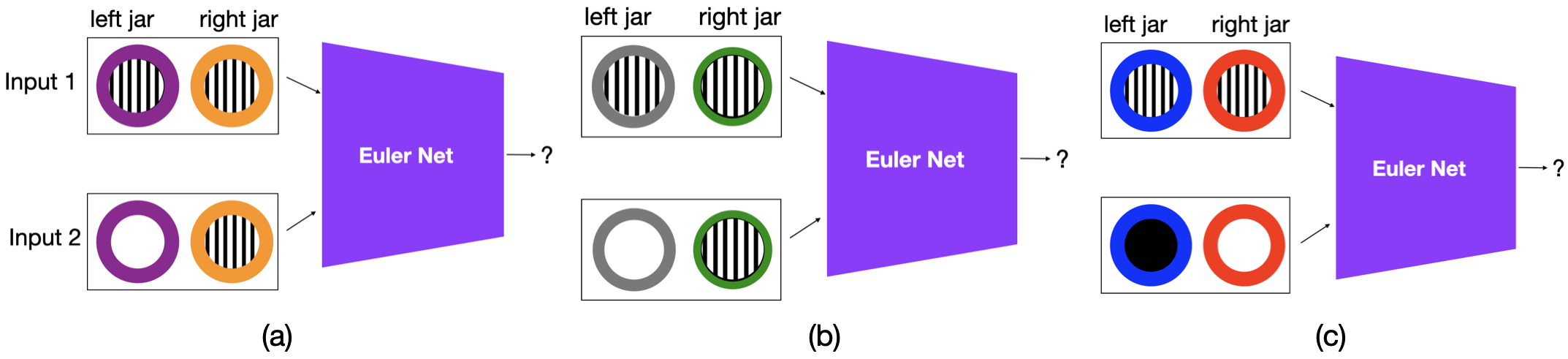
Supervised networks with image inputs. Inspired by the structural similarity between deep Convolution Neural Networks (CNN) (He et al., 2016) and visual cortex (Yamins and Di-Carlo, 2016), Euler Nets are special CNNs that perform Aristotelian syllogistic reasoning with Euler diagrammatic-styled image-inputs (Wang et al., 2018(Wang et al., , 2020)).
Supervised networks with linguistic inputs. The popular neural network architecture is the Transformer (Vaswani et al., 2017), which underpins LLMs (Google, 2023;Touvron et al., 2023;OpenAI, 2023;Jiang et al., 2023;Mistral, 2023). The basic training method is masked word prediction (Raschka, 2024) using Transformers. Given the text all Greeks are human. all humans are mortal. therefore, all Greeks are , LLMs are trained to predict mortal.
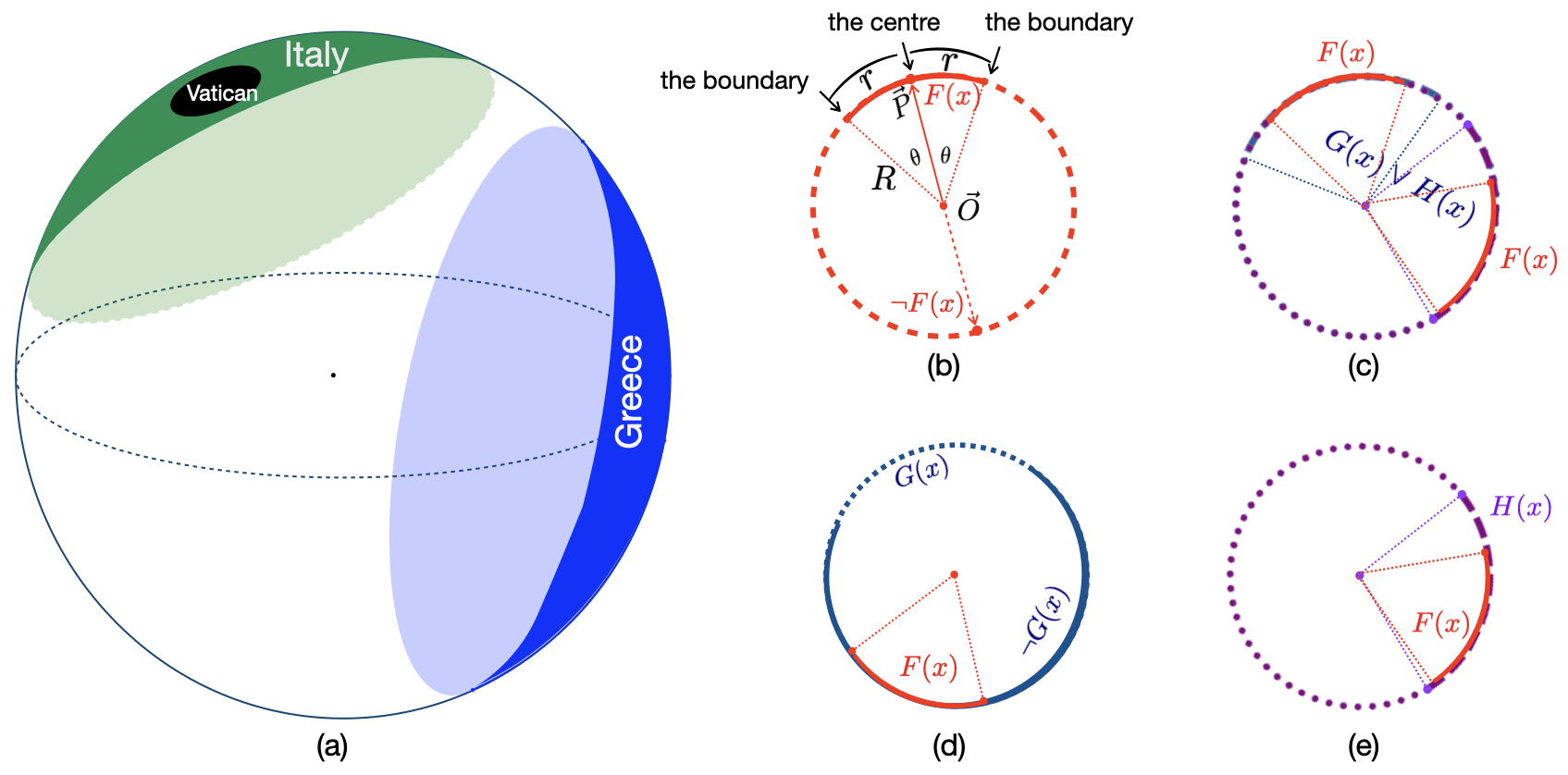
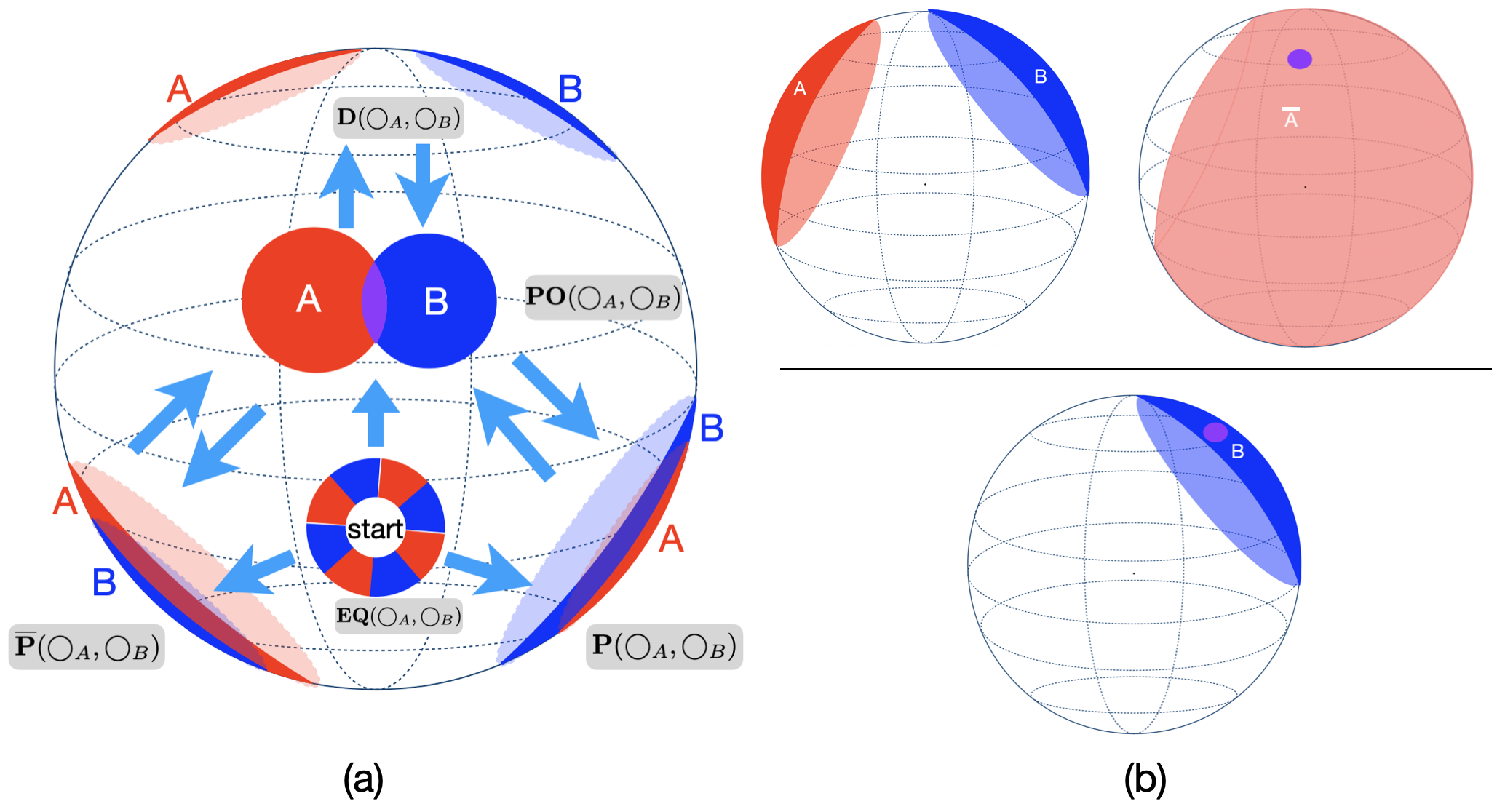
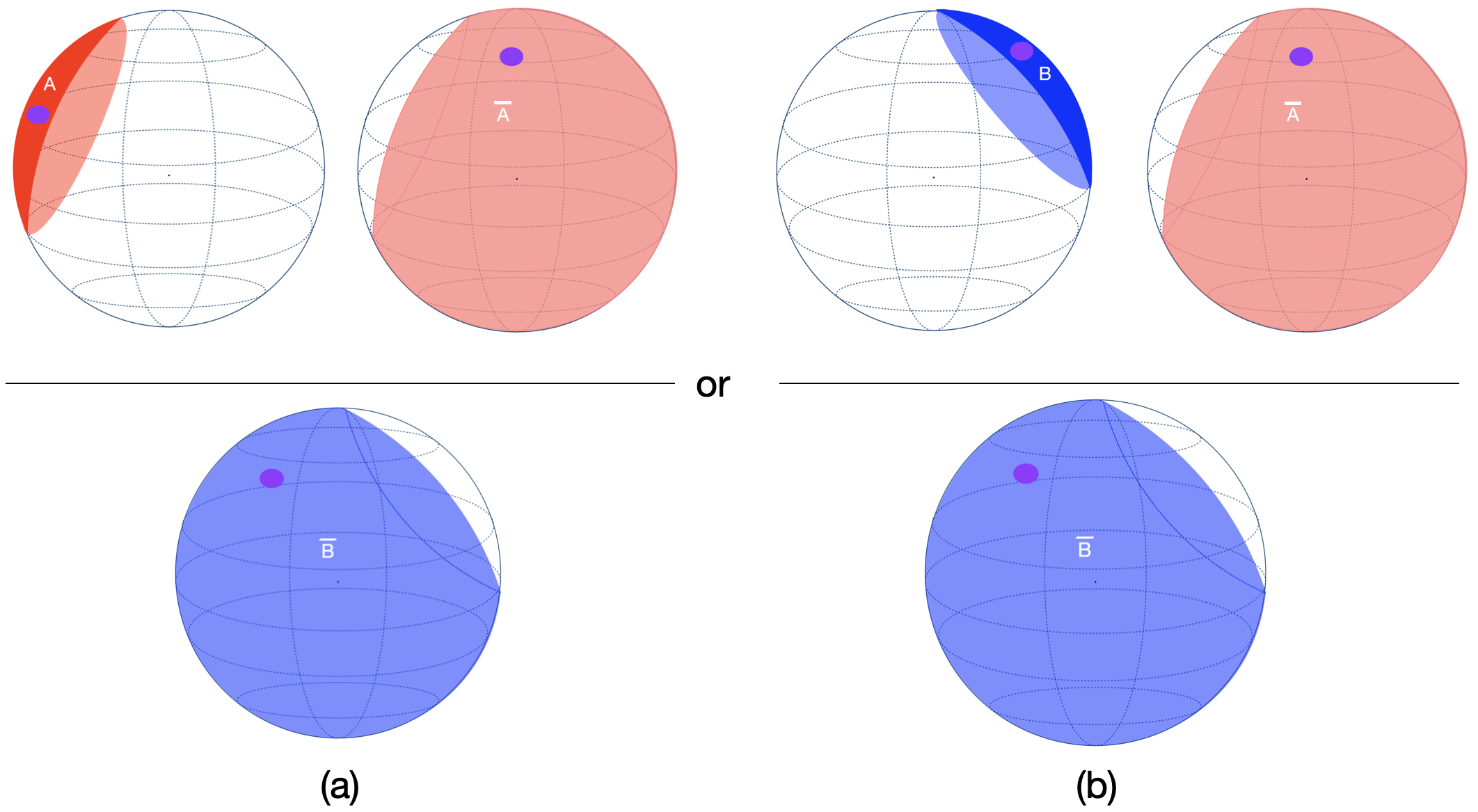
Neural networks that reason through explicit model construction. Sufficient empirical experiments advocate the model theory for reasoning that reasoning is a process of constructing and inspecting mental models (Johnson-Laird and Byrne, 1991;Knauff et al., 2003;Goodwin and Johnson-Laird, 2005;Knauff, 2009Knauff, , 2013)). In line with the mental model theory, Sphere Neural Networks perform Aristotelian syllogistic reasoning by constructing Euler diagrams in the Euclidean or Hyperbolic space (Dong et al., 2024(Dong et al., , 2025)). They are proven to achieve the rigour of symbolic-level logical reasoning.
In this paper, we compare reasoning performances between Category 1 supervised neural networks with image inputs and Category 3 neural networks through explicit model construction (in the Appendix, we report the performance of OpenAI GPT-5 and GPT-5-nano in syllogistic reasoning). We challenge them on various kinds of syllogistic-style decision-making, which are the core of many high-stakes applications, e.g., legal judgments (Deng et al., 2023;Constant, 2023), medical
This content is AI-processed based on open access ArXiv data.