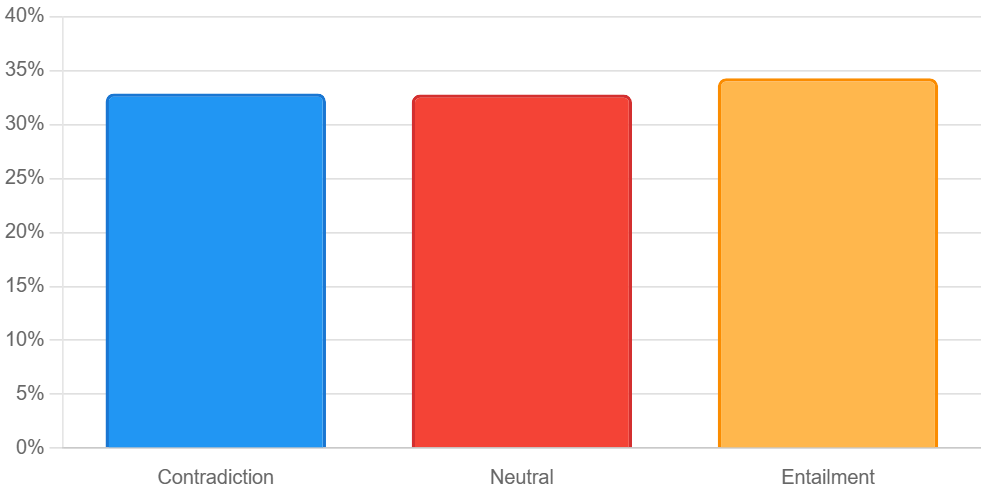
Quantization is widely used to accelerate inference and streamline the deployment of large language models (LLMs), yet its effects on selfexplanations (SEs) remain unexplored. SEs, generated by LLMs to justify their own outputs, require reasoning about the model's own decision-making process, a capability that may exhibit particular sensitivity to quantization. As SEs are increasingly relied upon for transparency in high-stakes applications, understanding whether and to what extent quantization degrades SE quality and faithfulness is critical. To address this gap, we examine two types of SEs: natural language explanations (NLEs) and counterfactual examples, generated by LLMs quantized using three common techniques at distinct bit widths. Our findings indicate that quantization typically leads to moderate declines in both SE quality (up to 4.4%) and faithfulness (up to 2.38%). The user study further demonstrates that quantization diminishes both the coherence and trustworthiness of SEs (up to 8.5%). Compared to smaller models, larger models show limited resilience to quantization in terms of SE quality but better maintain faithfulness. Moreover, no quantization technique consistently excels across task accuracy, SE quality, and faithfulness. Given that quantization's impact varies by context, we recommend validating SE quality for specific use cases, especially for NLEs, which show greater sensitivity. Nonetheless, the relatively minor deterioration in SE quality and faithfulness does not undermine quantization's effectiveness as a model compression technique.
Deploying LLMs efficiently at scale has motivated extensive research on quantization (Dettmers et al., 2022;Frantar et al., 2023;Lin et al., 2024). Quantization achieves model compression and efficient deployment (e.g., of on-device LLMs) by reducing parameter precision and bit allocation, delivering substantial size reductions while preserving most functionality (Gray and Neuhoff, 1998). Previous work has investigated quantization's influence on various model dimensions, such as multilinguality (Marchisio et al., 2024), bias (Gonçalves and Strubell, 2023), and alignment (Jin et al., 2024). An important capability dimension that may be affected by quantization is the capability of a model to explain itself. Self-explanations (SEs) are statements generated by models to justify their own decisions (Agarwal et al., 2024;Madsen et al., 2024), which are deemed to be an effective and convincing way to deliver explanations to users and enhance the transparency of black-box LLMs (Huang et al., 2023;Randl et al., 2025). Nevertheless, SE may obfuscate the true reasoning process of LLMs (Turpin et al., 2023;Tutek et al., 2025), and we hypothesize that quantization may exacerbate this, since LLMs are directly optimized for task performance but learn to generate faithful SEs more indirectly. Moreover, quantized models have been widely adopted in prior work for many types of SE generation (Wang et al., 2024;Liu et al., 2024;Bhattacharjee et al., 2024;Giorgi et al., 2025). However, the impact of quantization on SEs, specifically on whether SEs remain faithful to a model's inner workings and whether their quality can be largely preserved, remains unexplored and has yet to be comprehensively characterized.
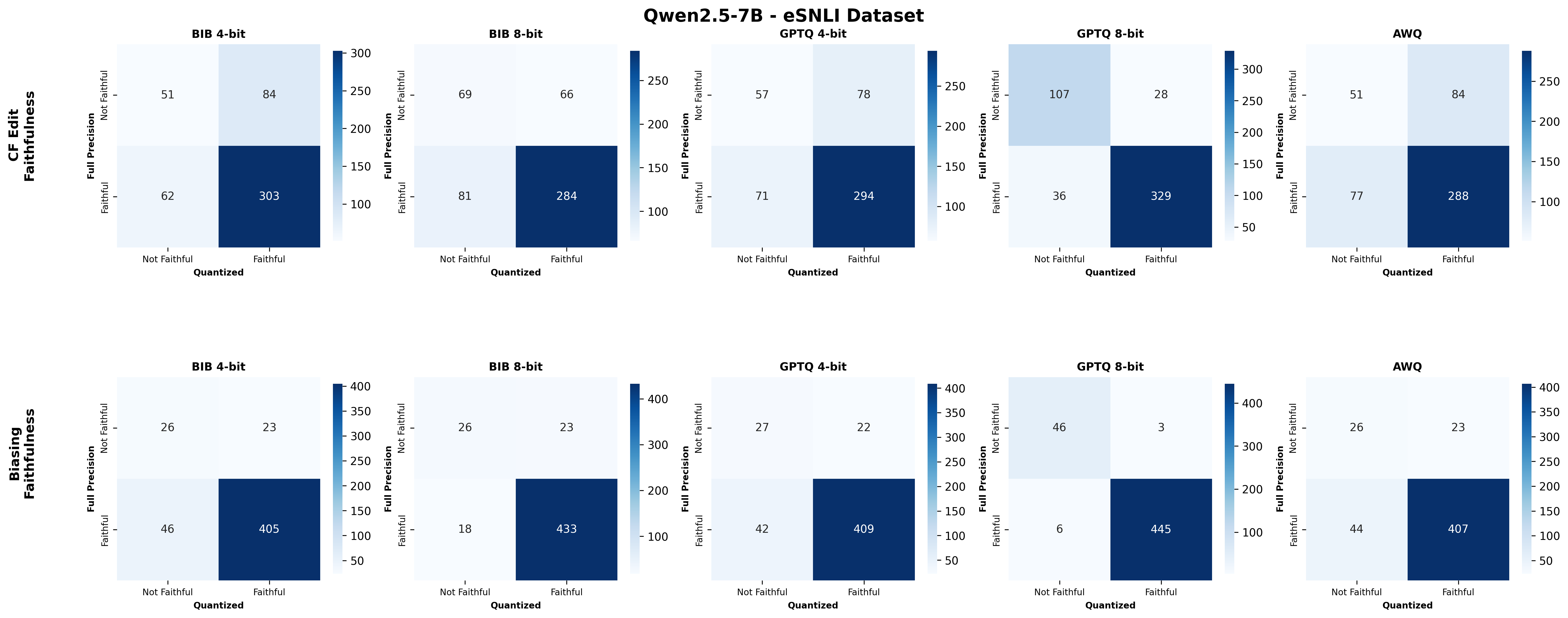
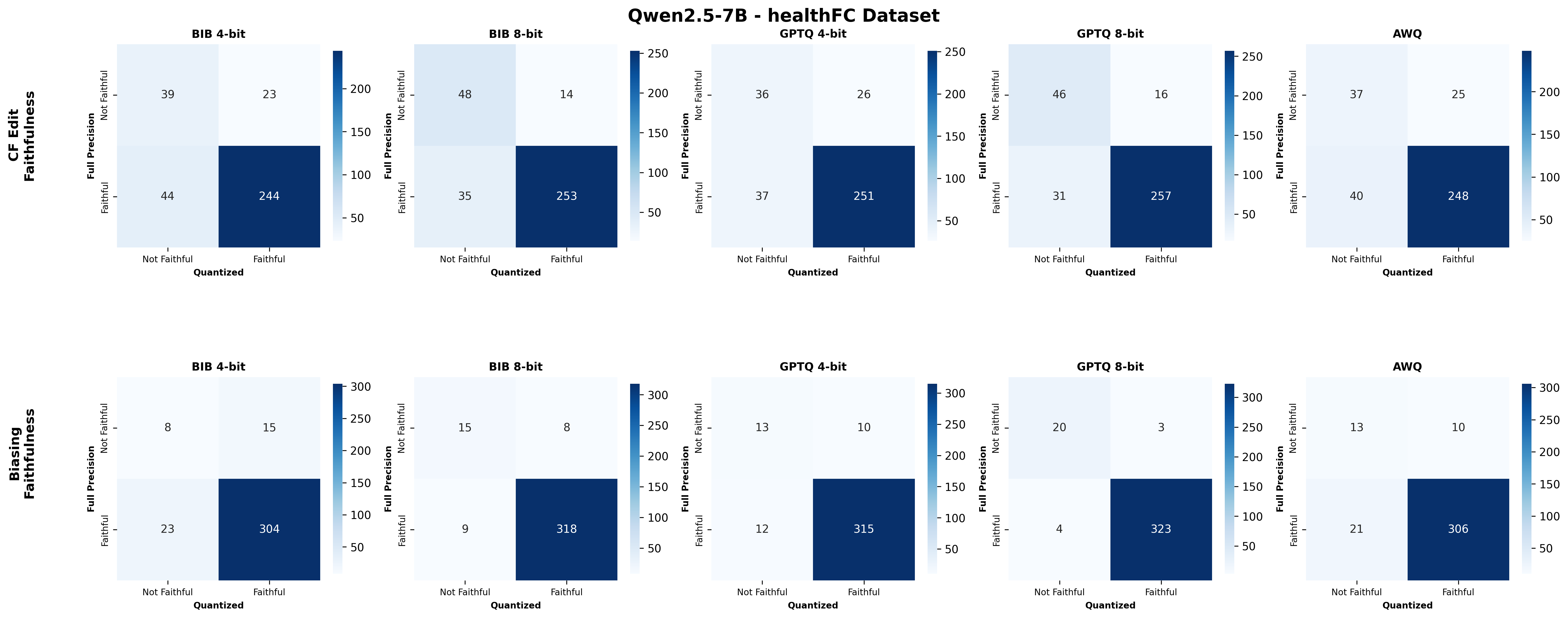
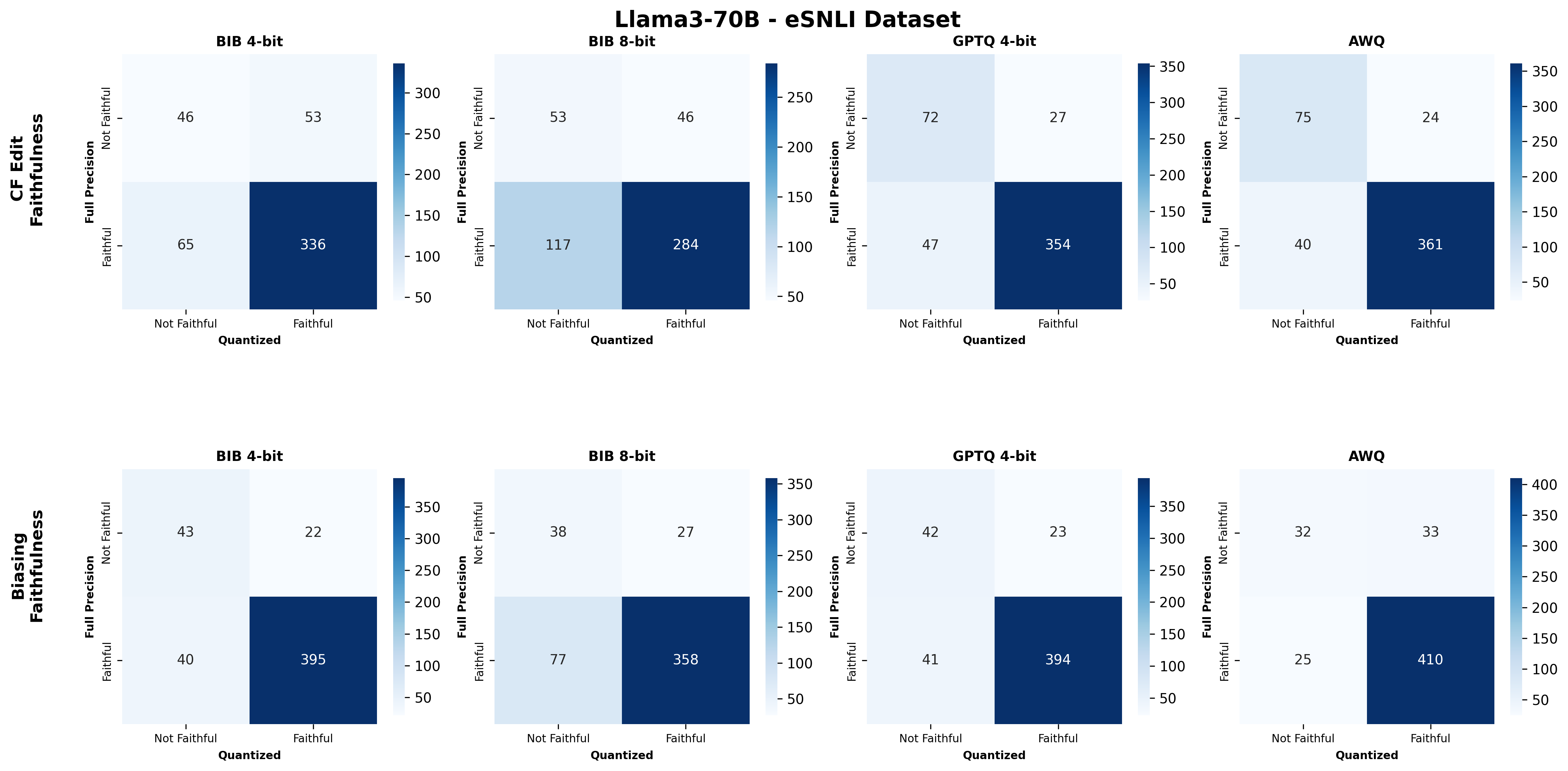
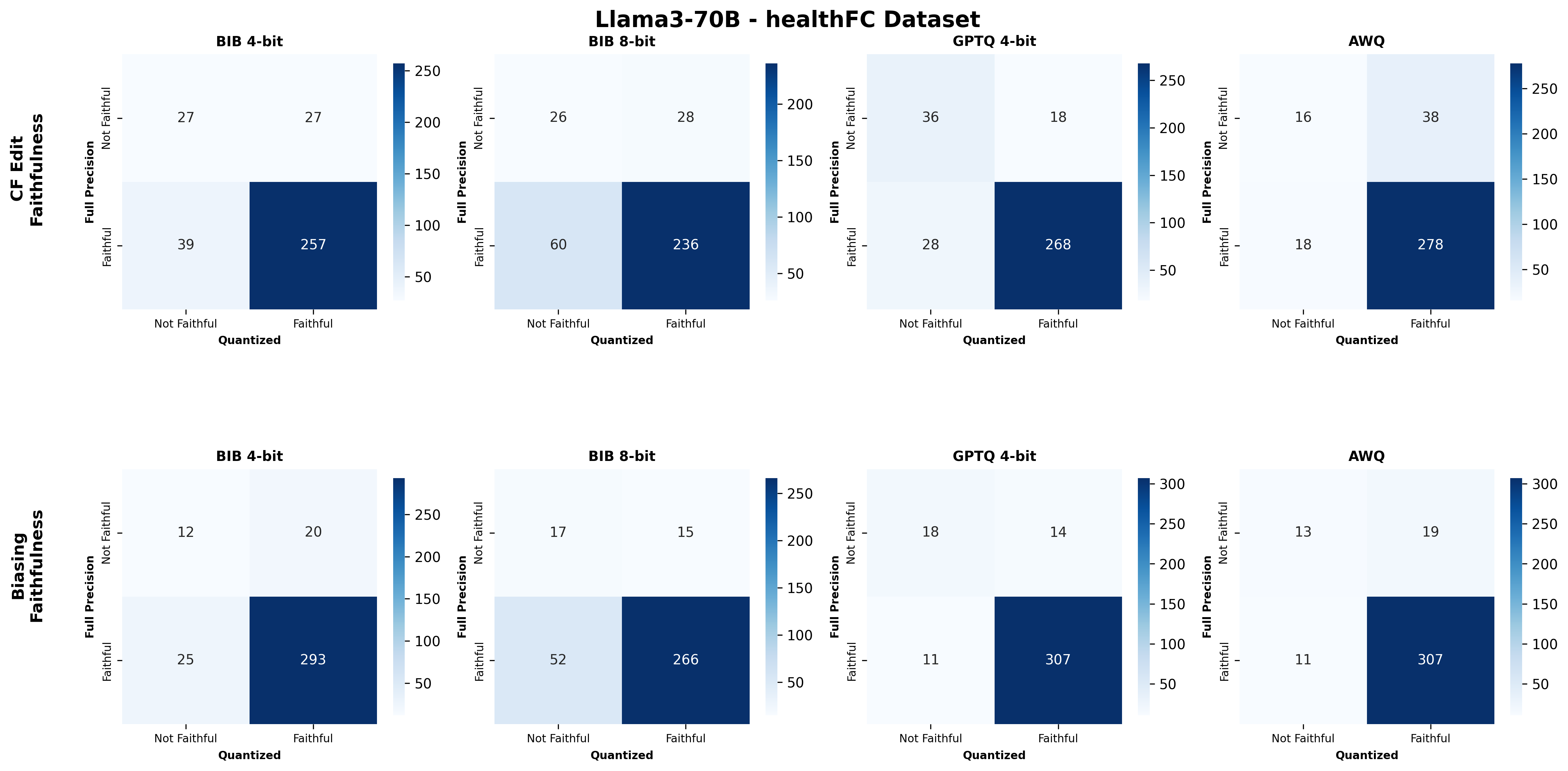
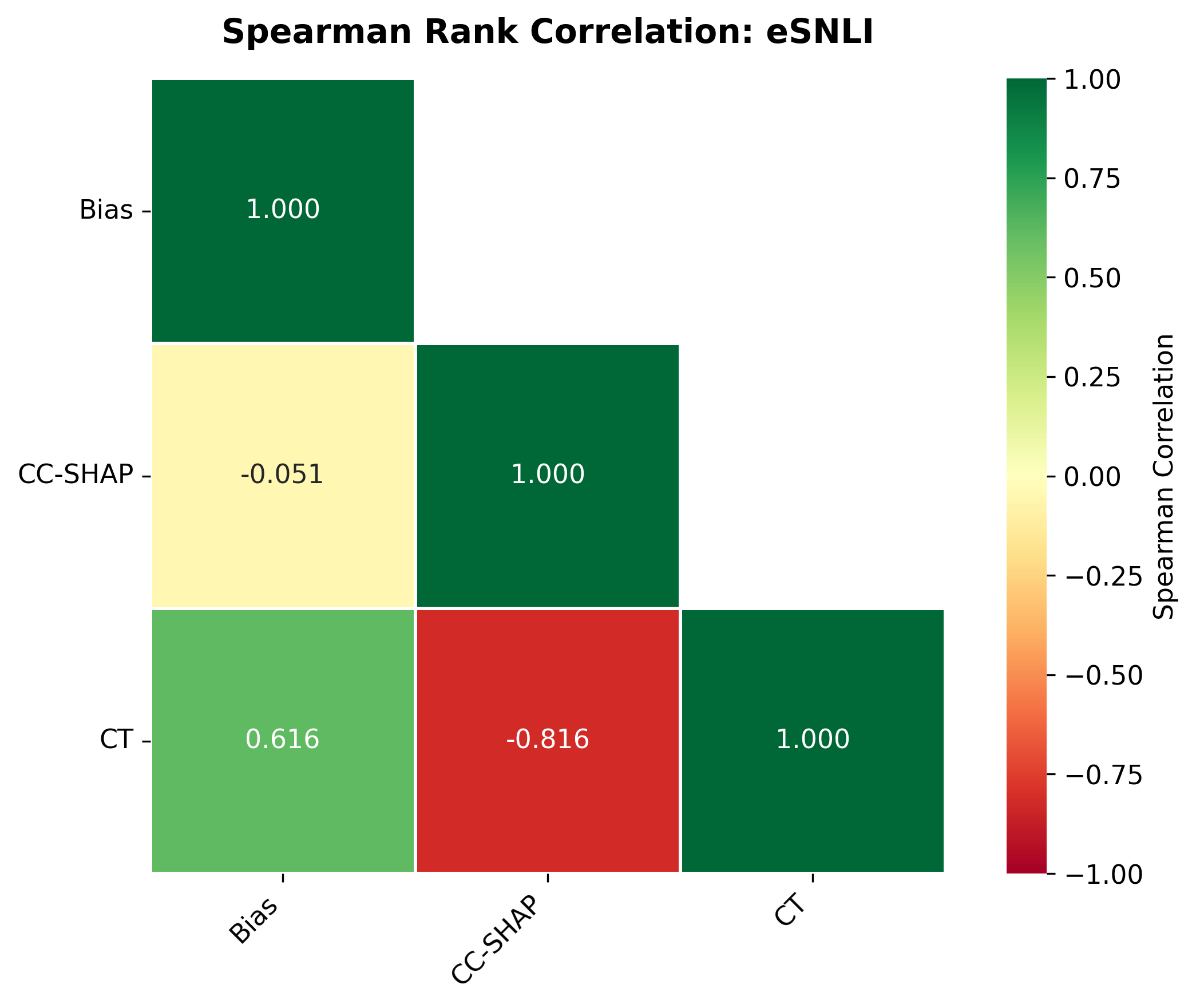
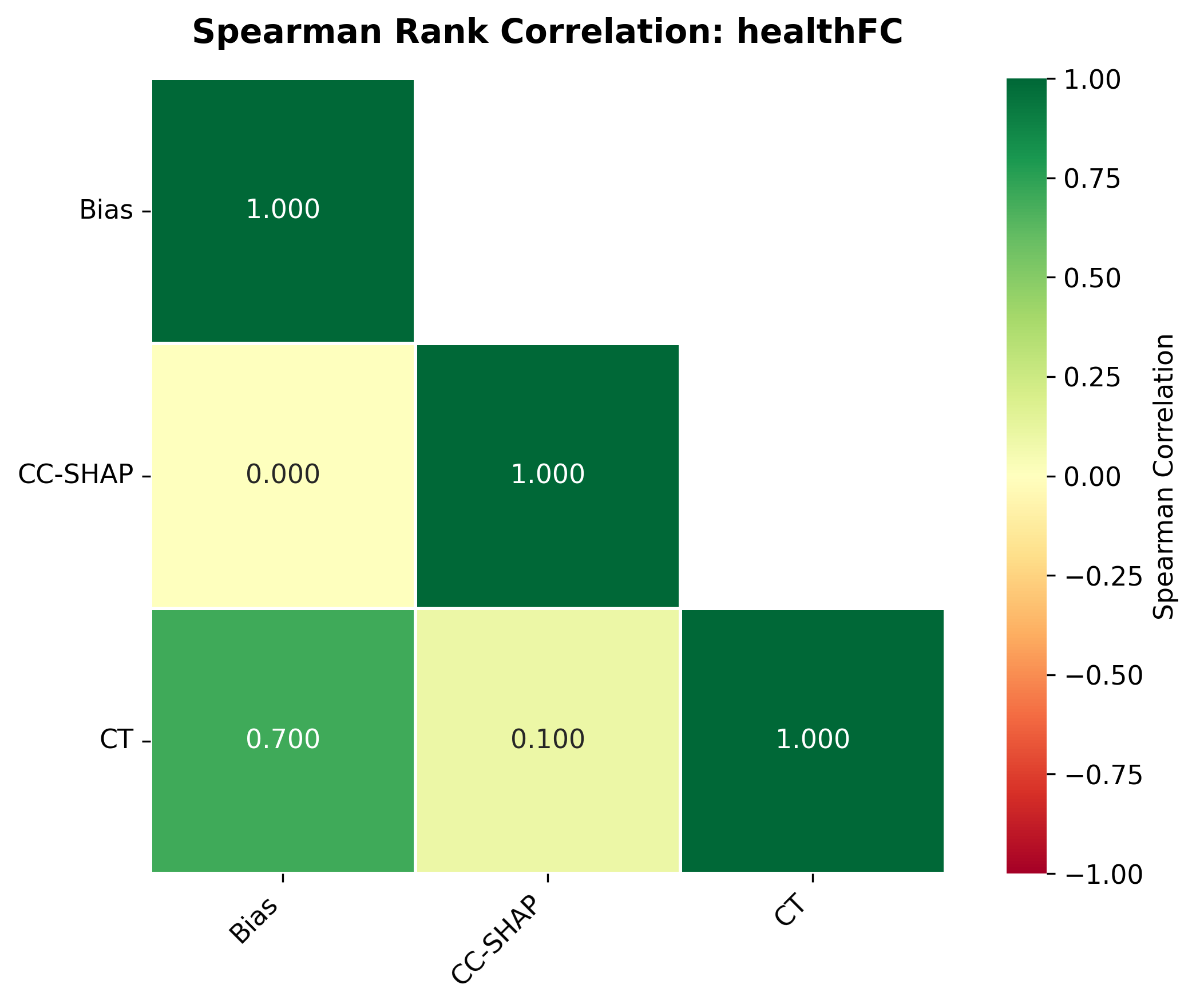
We bridge this gap through a comprehensive study on how quantization affects both the quality and faithfulness of SEs. Our study encompasses two distinct types of free-text SEs: natural language explanations and counterfactual examples (Figure 1). First, we perform comprehensive automatic evaluations of SE quality across three datasets and six models of varying sizes under full precision and three quantization approaches with different bit widths ( §5.1). We show that different types of SEs exhibit varying levels of sensitivity to quantization, though quantization generally leads to moderate degradation in SE quality (up to 4.4%). Unexpectedly, larger quantized models do not always outperform smaller full-precision models in generating high-quality SEs, nor do LLMs with lower bit precision consistently lag behind their higher bit-precision counterparts.
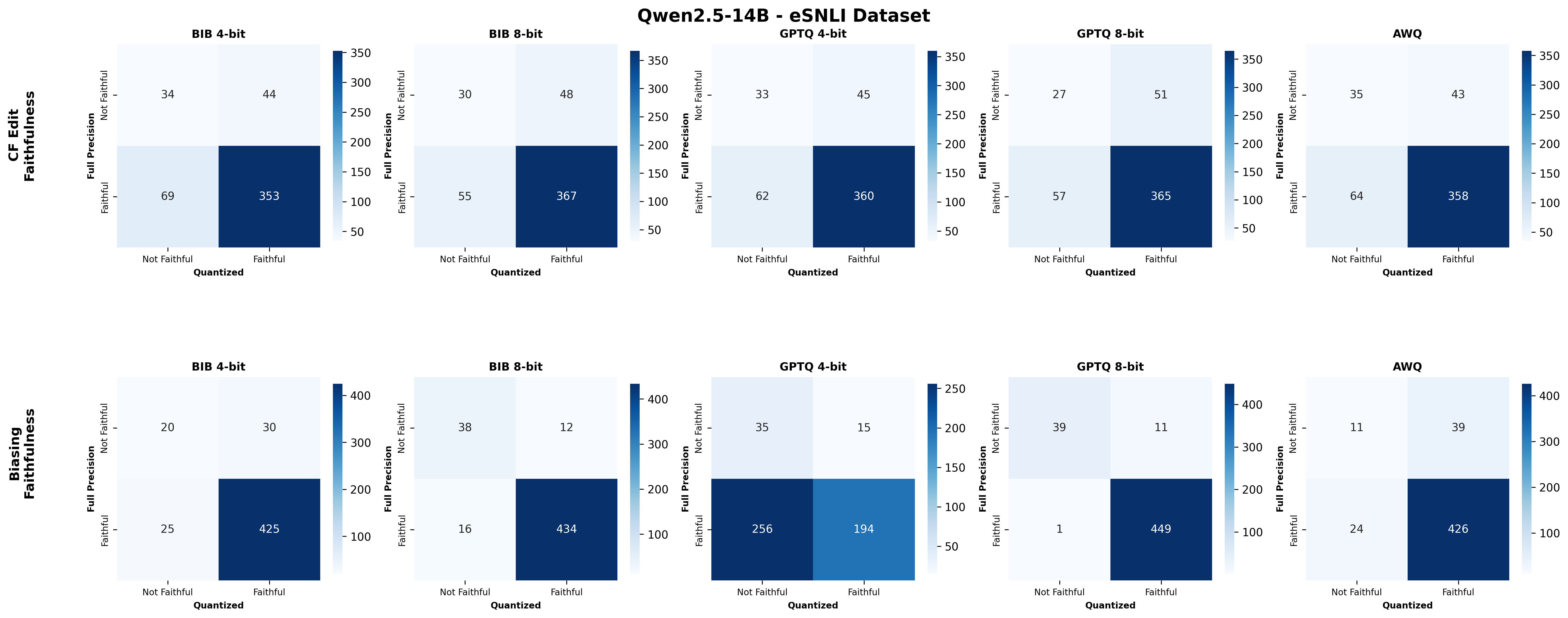
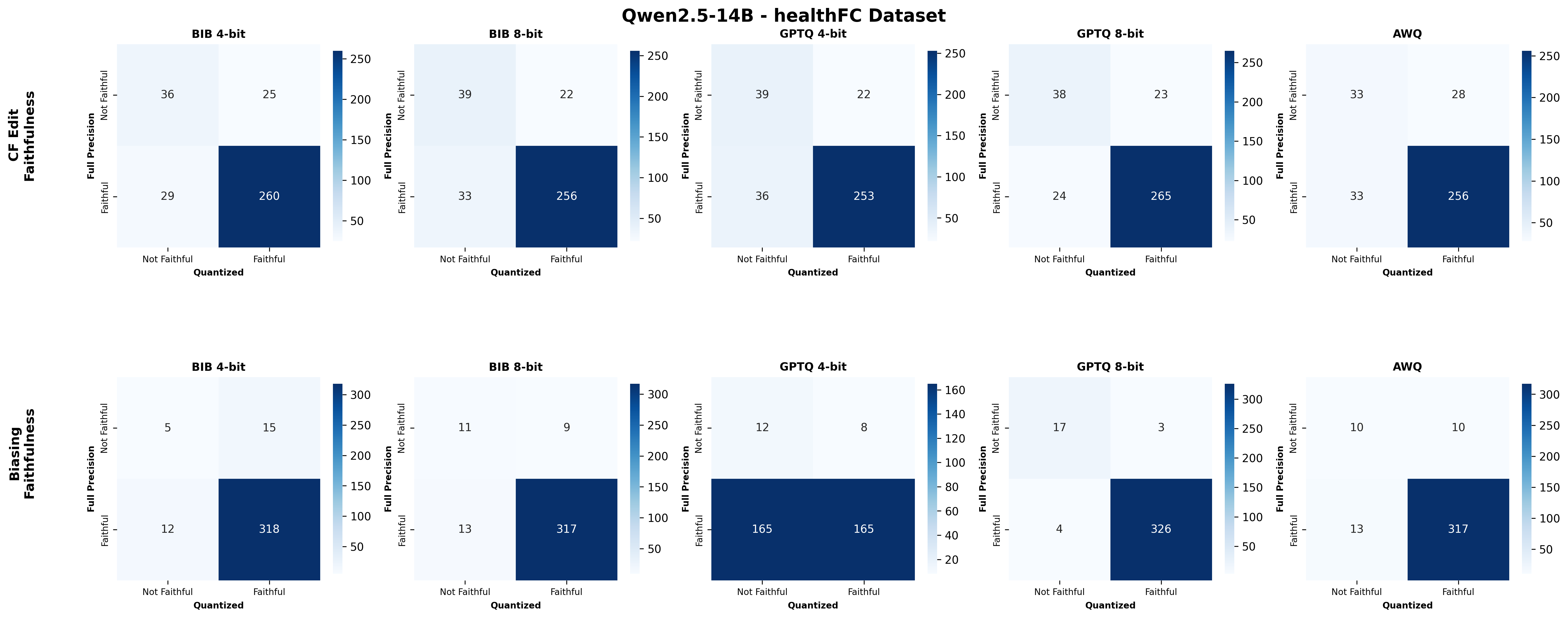
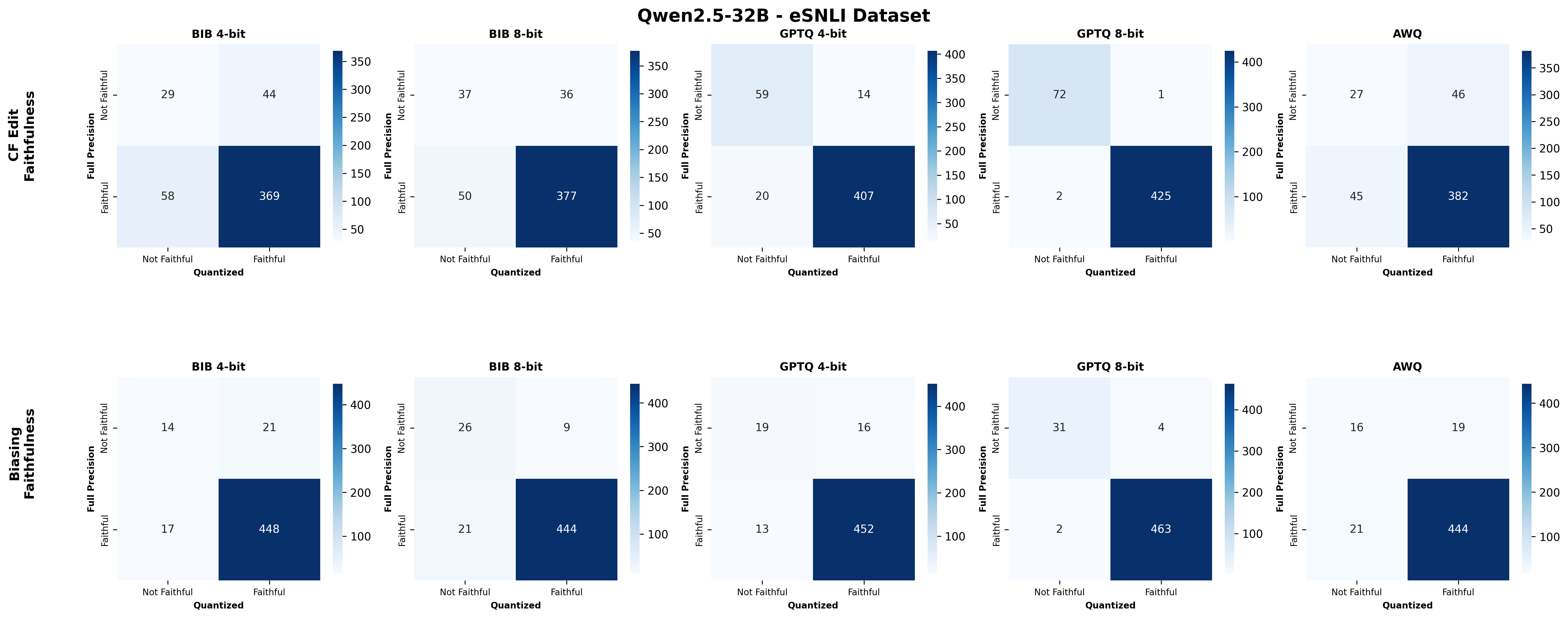
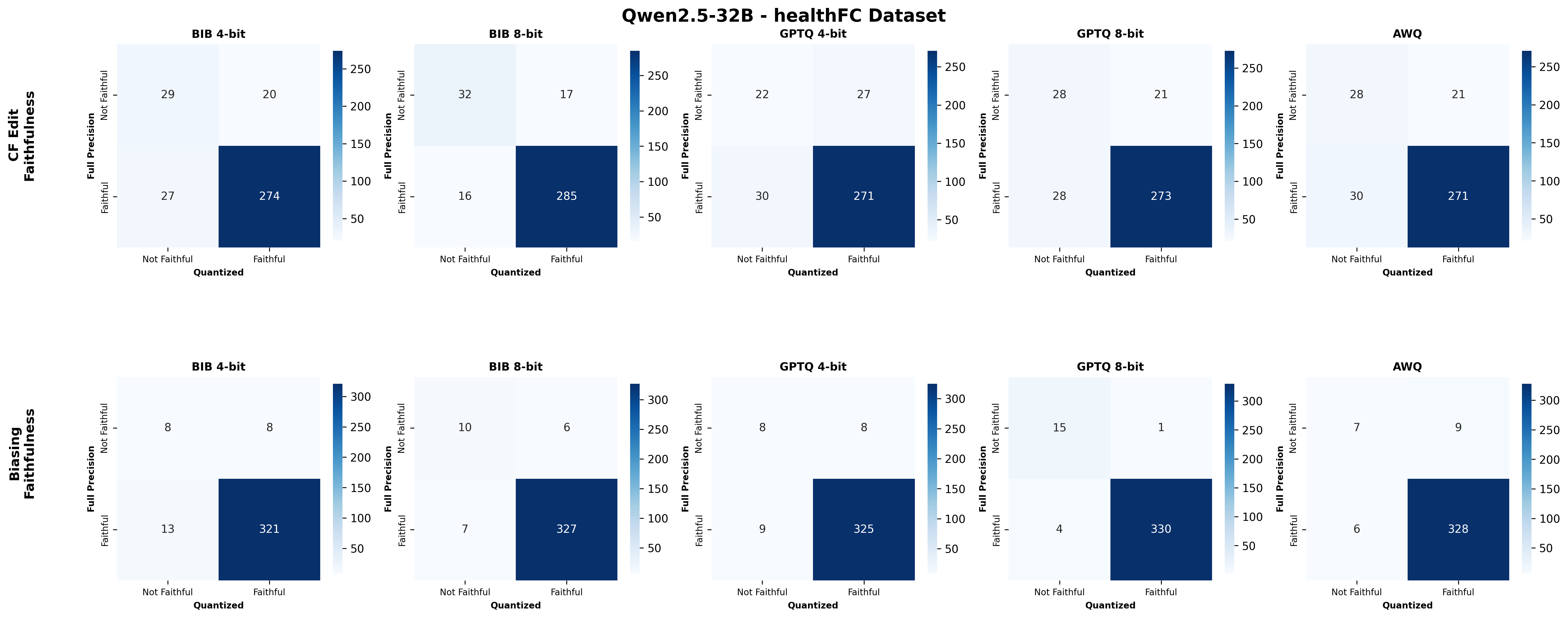
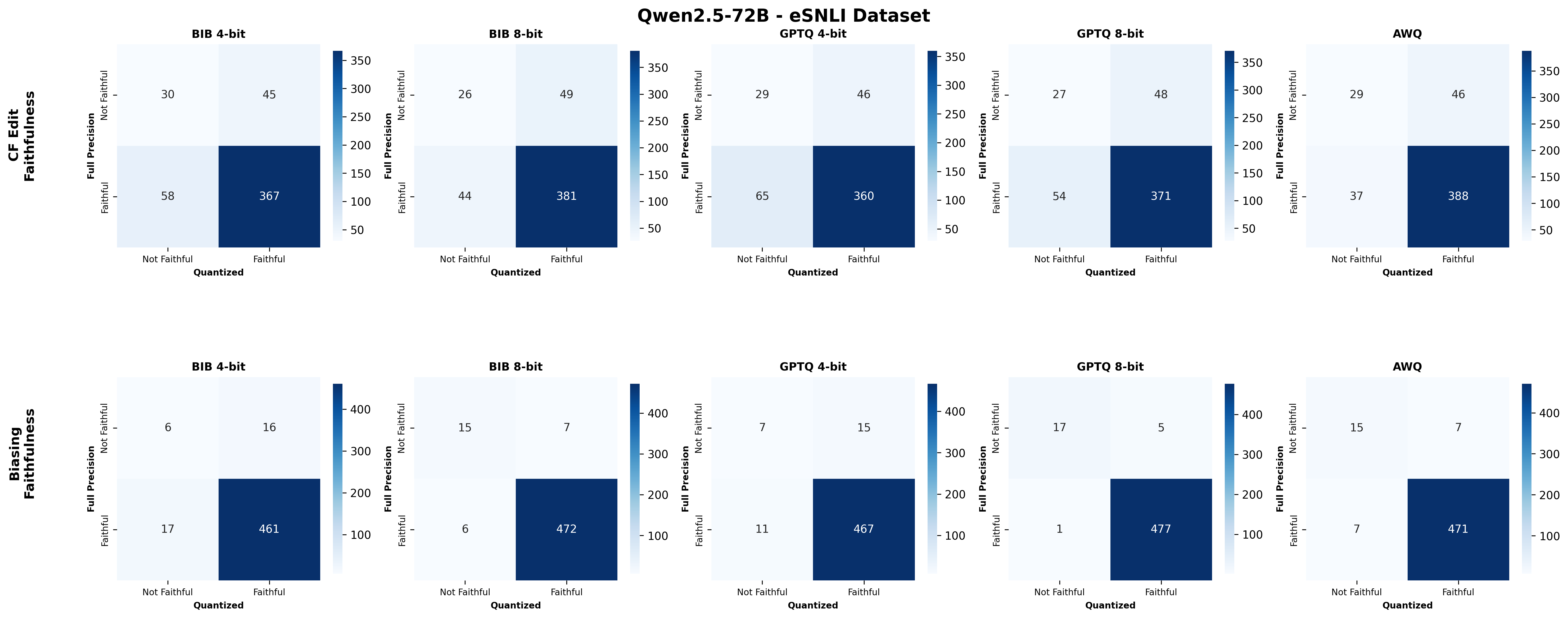
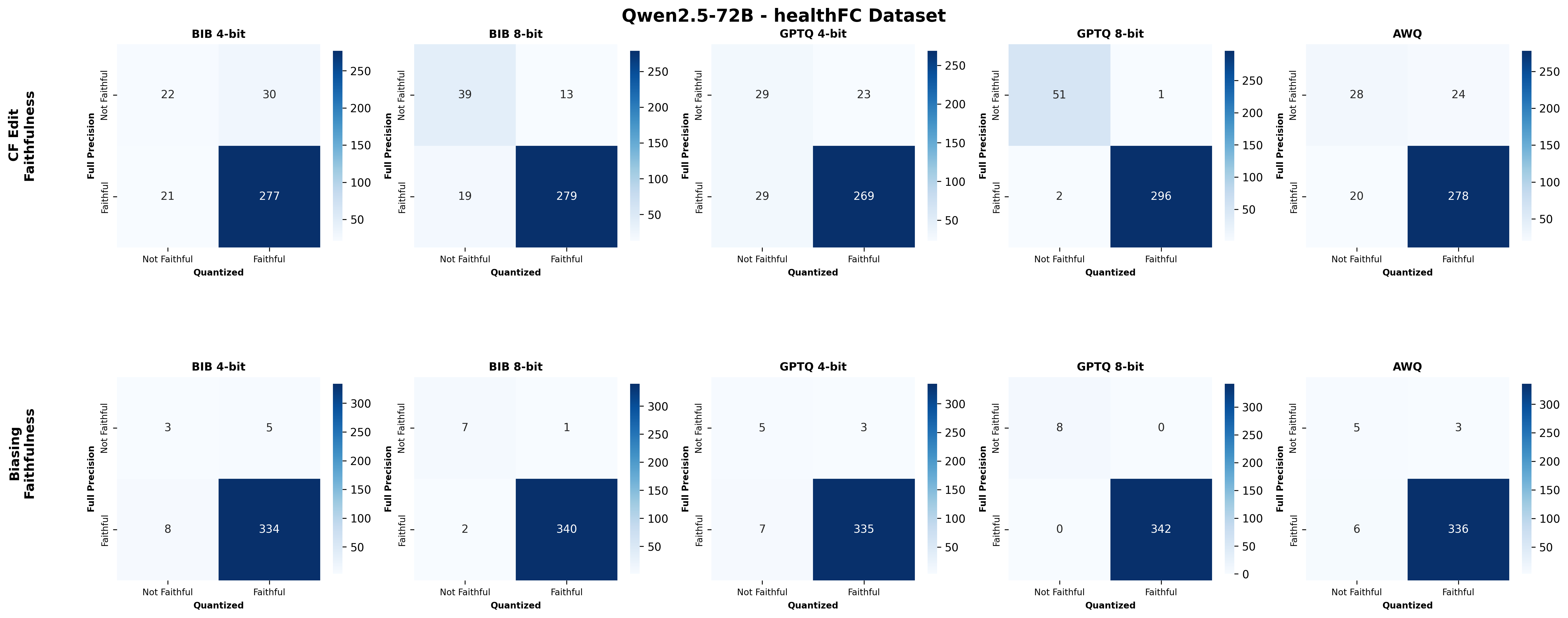
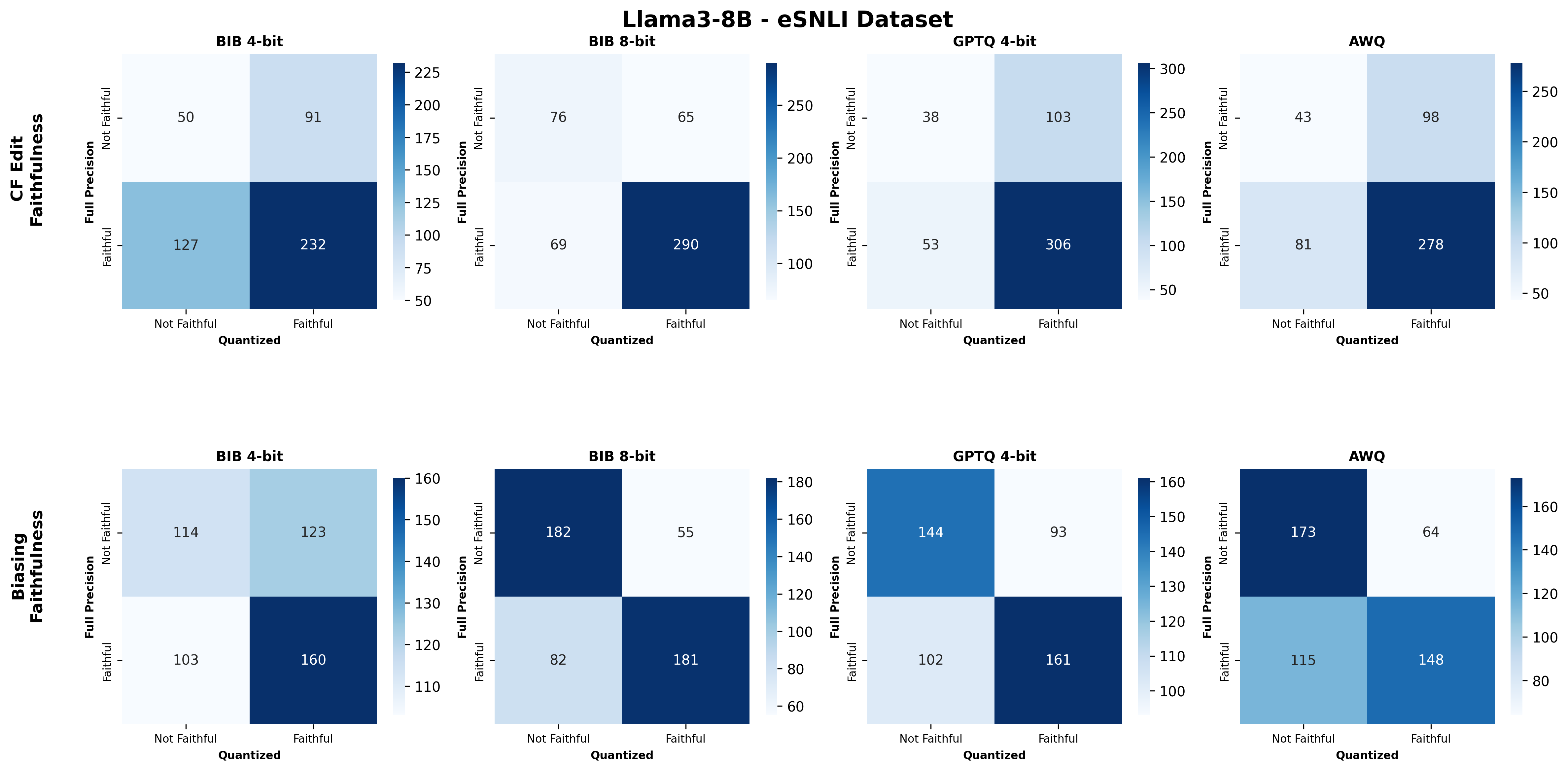
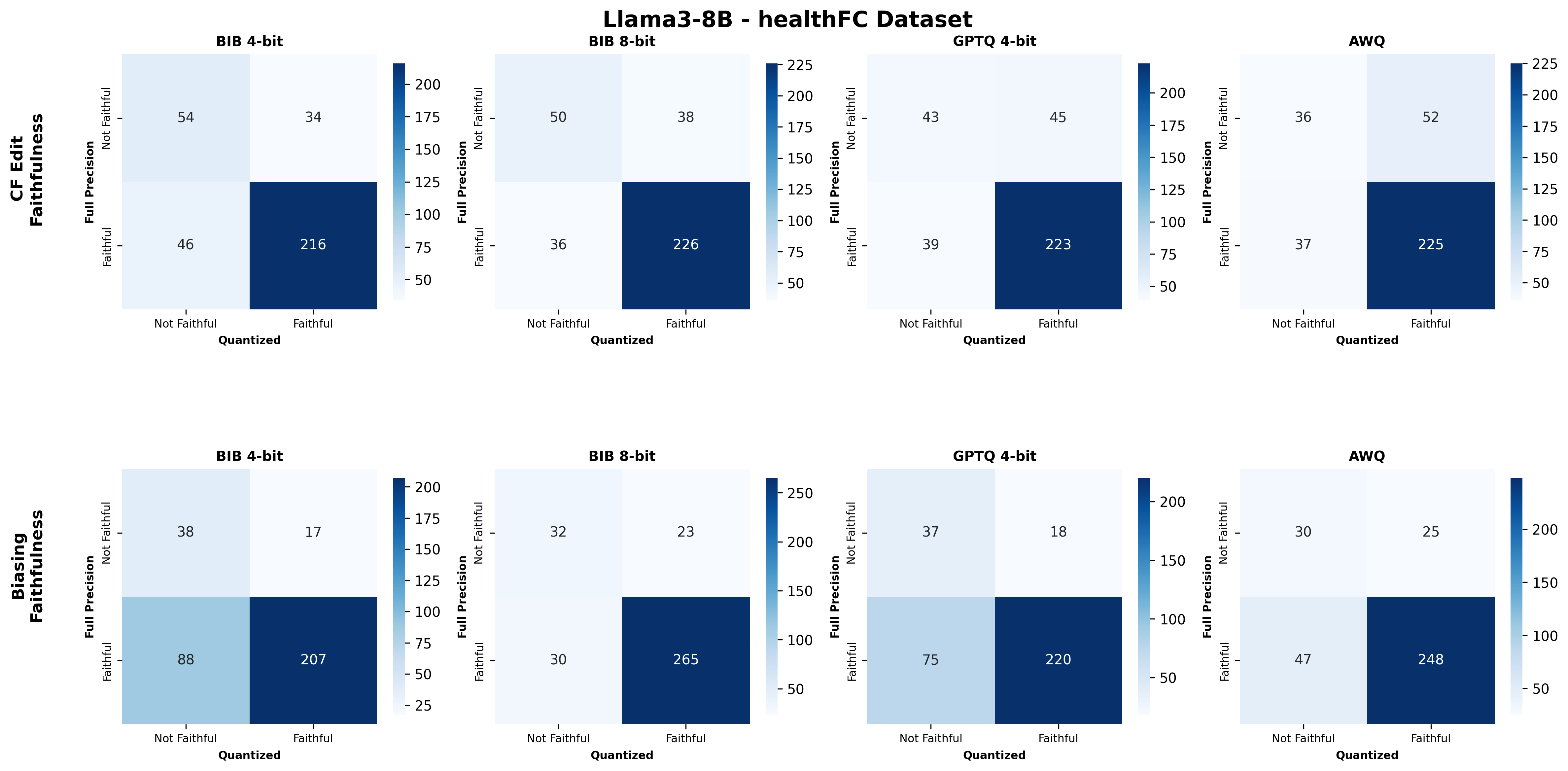
Second, we assess SE faithfulness through selfconsistency checks for counterfactuals and three metrics for natural language explanations. SE faithfulness exhibits modest average decline under quantization (up to 2.38%); however, larger models demonstrate greater robustness in preserving SE faithfulness ( §5.1.1). Across our experiments, no quantization method consistently excels across task performance, explanation quality, and faithfulness simultaneously. Furthermore, we observe a distinct trade-off between SE characteristics, namely quality and faithfulness, and overall task performance under quantization. Therefore, SE characteristics should be validated for specific use cases depending on whether task performance or explanation performance is prioritized ( §5.3).
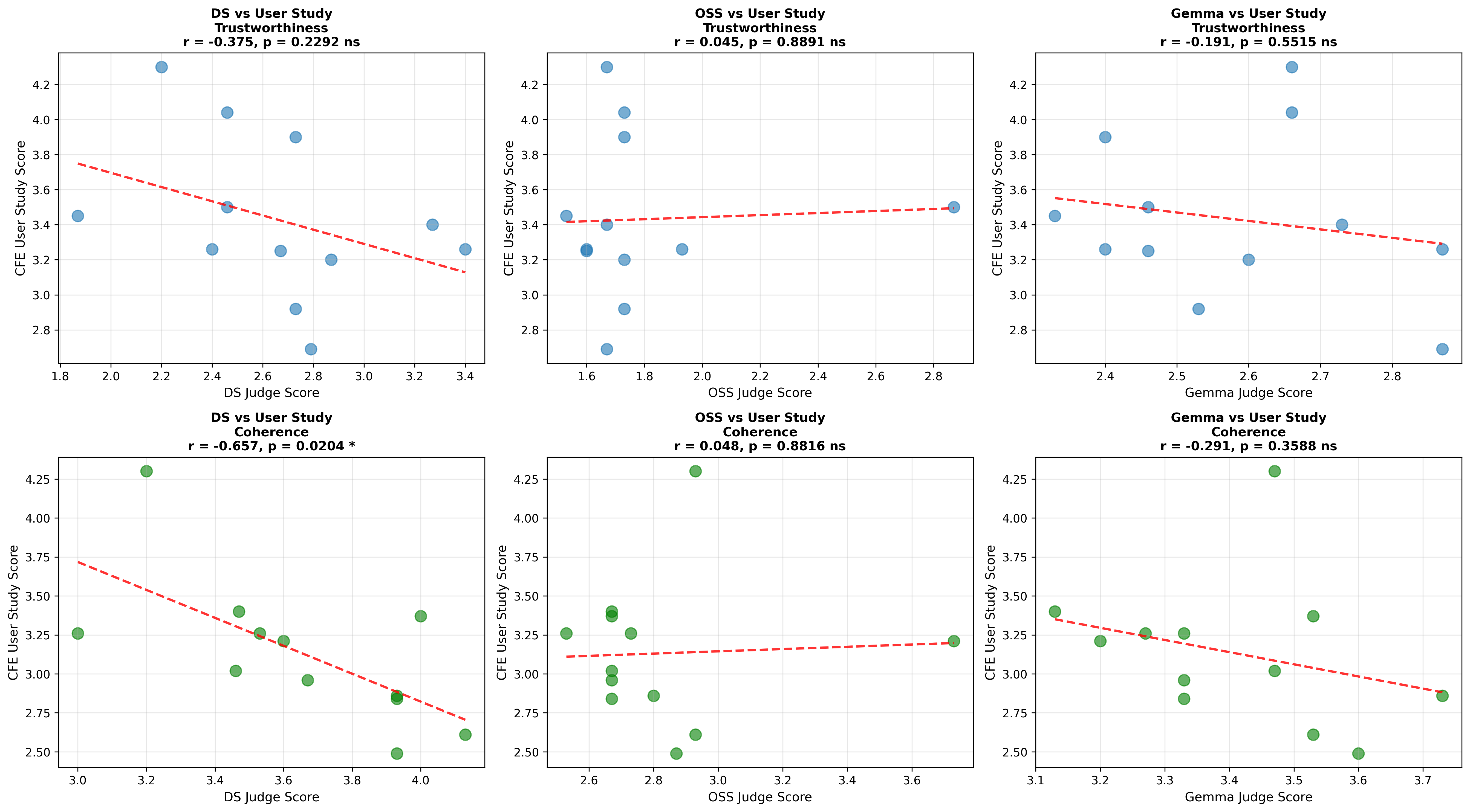
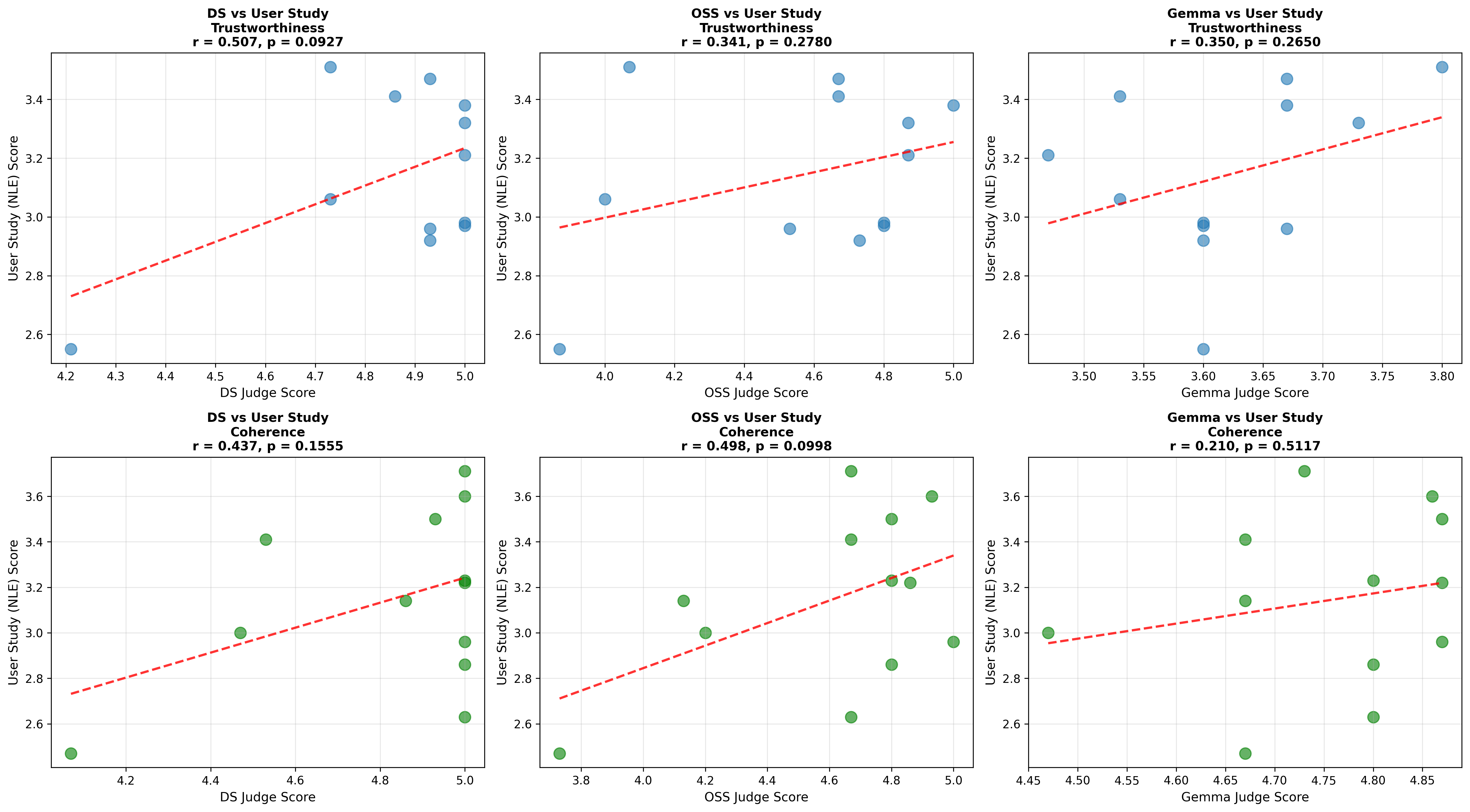
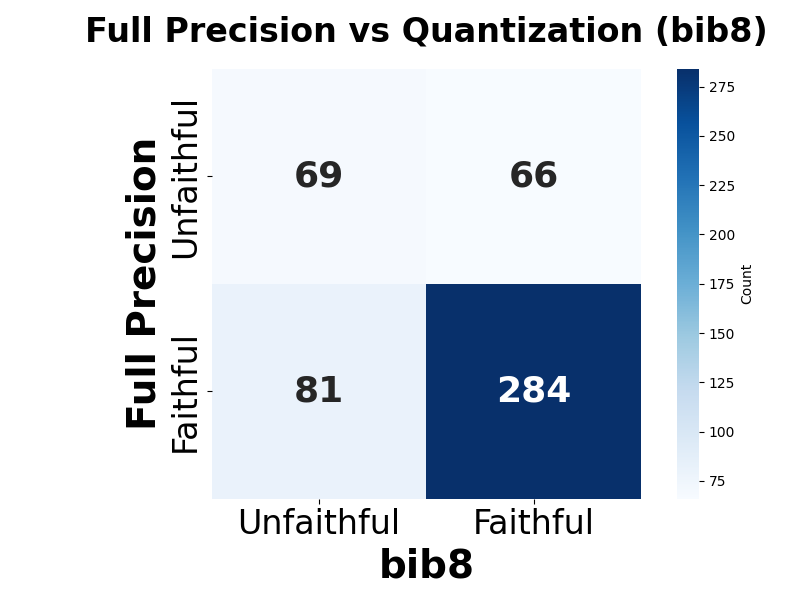
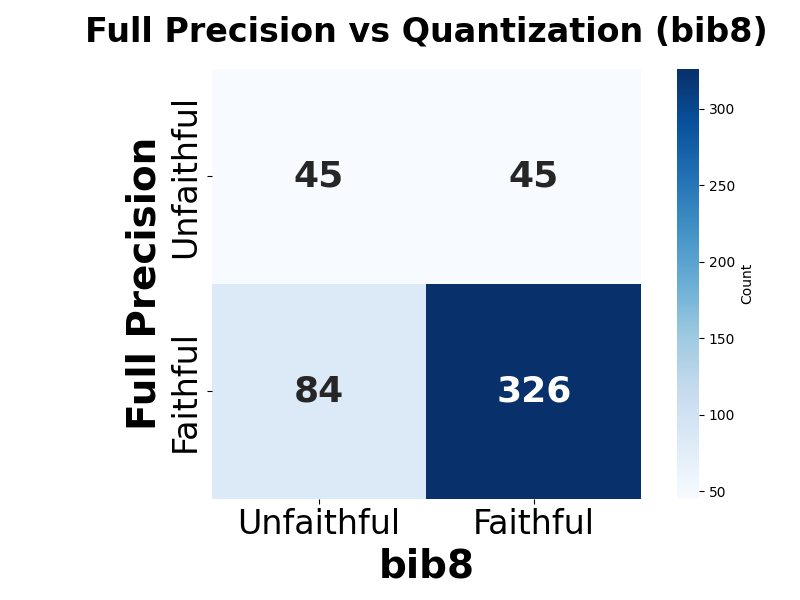
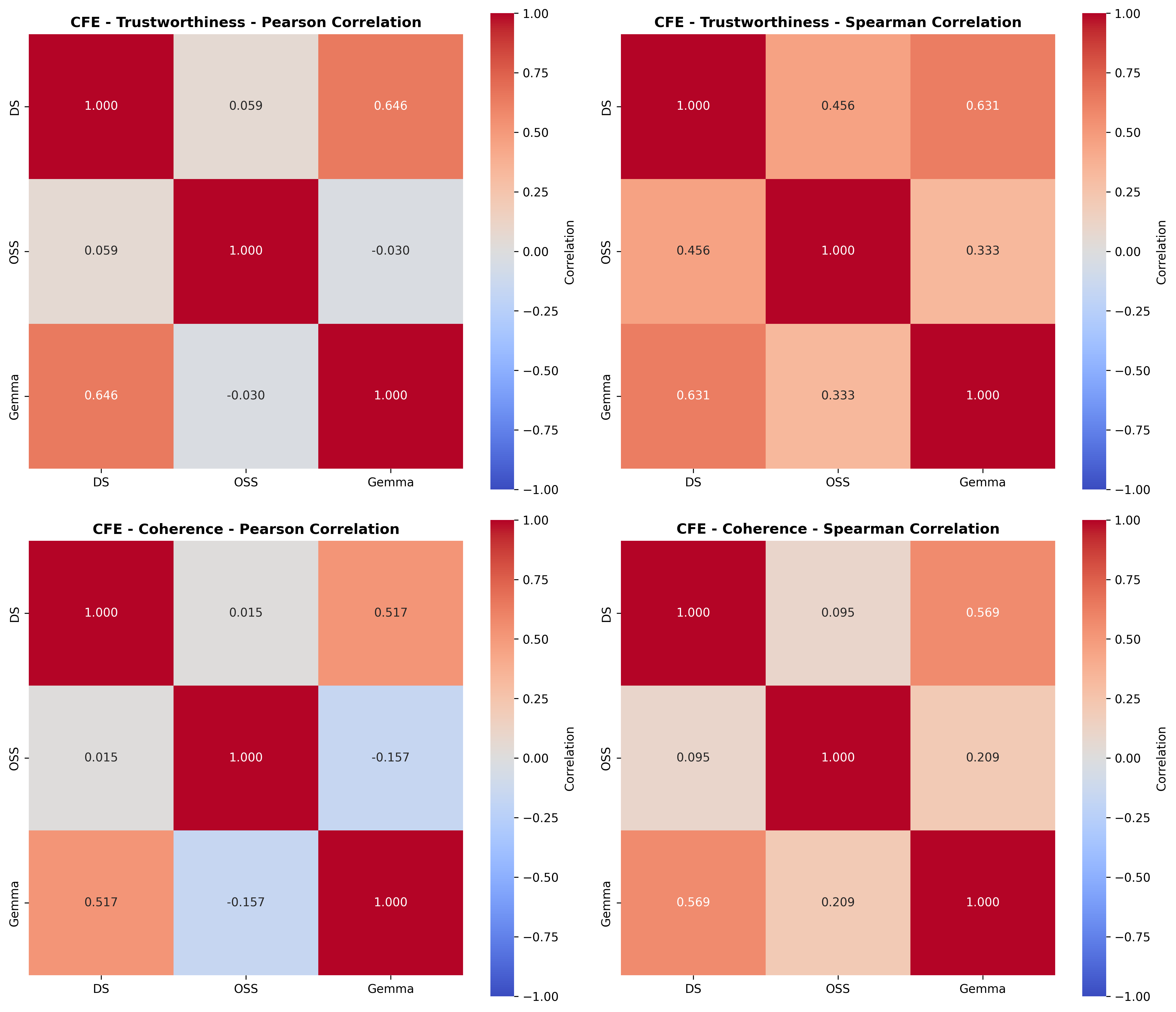
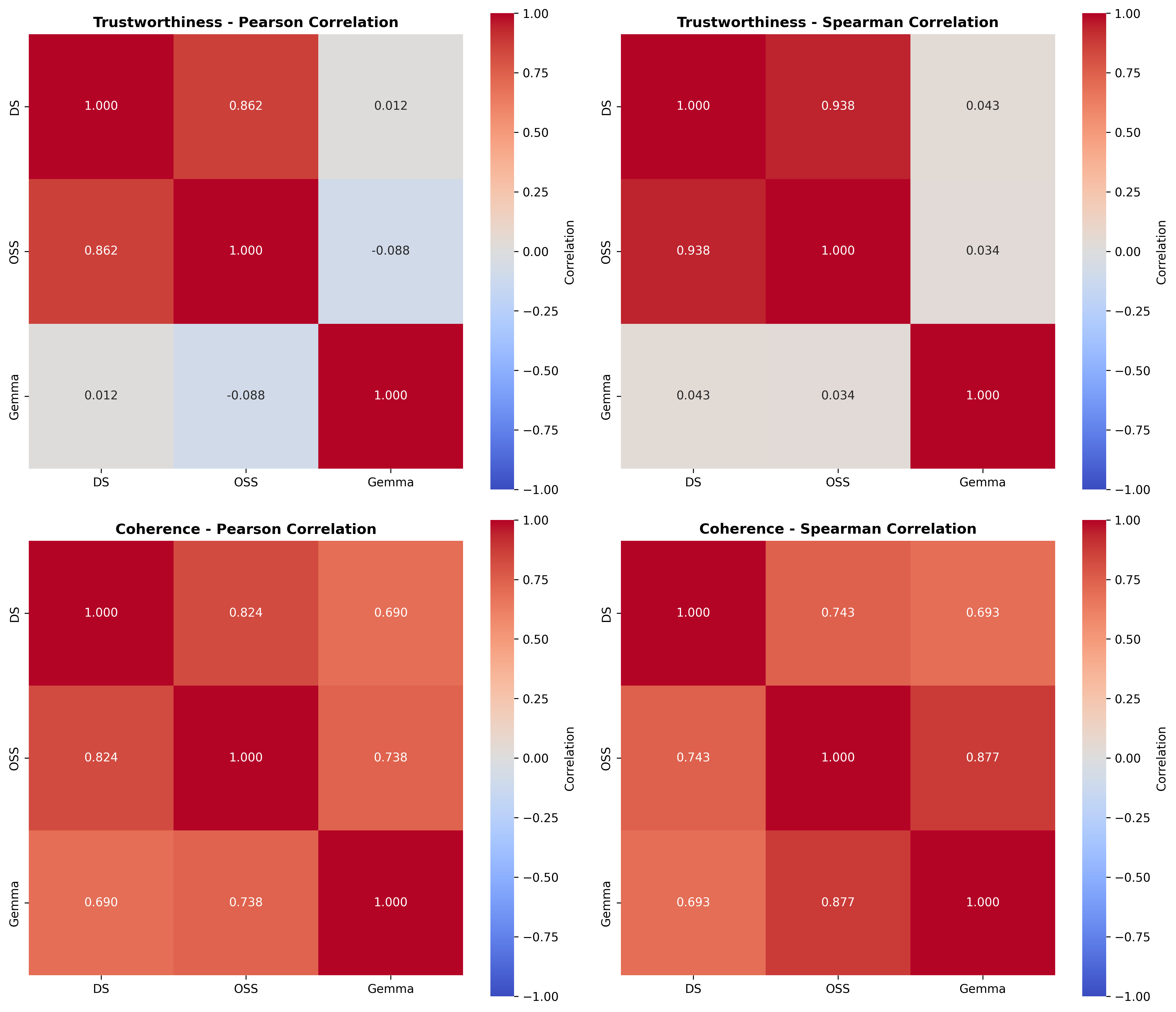
Lastly, we conduct a user study with 48 participants, evaluating trustworthiness and coherence of SEs generated by models at different bit-precision levels. Human evaluators perceive full-precision models as producing more trustworthy and coherent SEs than those produced by their quantized counterparts (Figure 1). Notably, conducting a similar LLM-as-a-Judge evaluation fails to fully capture the impact of quantization on self-explanation quality, evidenced by the weak or negative, and non-statistically significant correlation observed between human and judge model ratings ( §5.2).
In conclusion, the modest reductions in SE quality and faithfulness do not diminish quantization’s value as an effective model compression strategy. Nevertheless, for high-stakes scenarios requiring optimal explanation reliability, we recommend application-specific validation before deployment.
Quantization. The decoding stage during LLM inference is typically memory-bound, where the key-value cache (KV cache) overhead often exceeds the size of the model weights (Li et al., 2024c). Quantization techniques compress LLMs by converting model weights, activations, or the KV cache, originally in 32-bit floating-point format, into lower-precision data types (Zhu et al., 2024), e.g., 8-bit integer (Dettmers et al., 2022). These techniques can be broadly categorized into two types: quantization-aware training (QAT) and post-training quantization (PTQ). QAT requires retraining to mitigate errors introduced by quantization, whereas PTQ facilitates an ad-hoc quantization during inference without necessitating modifications to the model arc
This content is AI-processed based on open access ArXiv data.