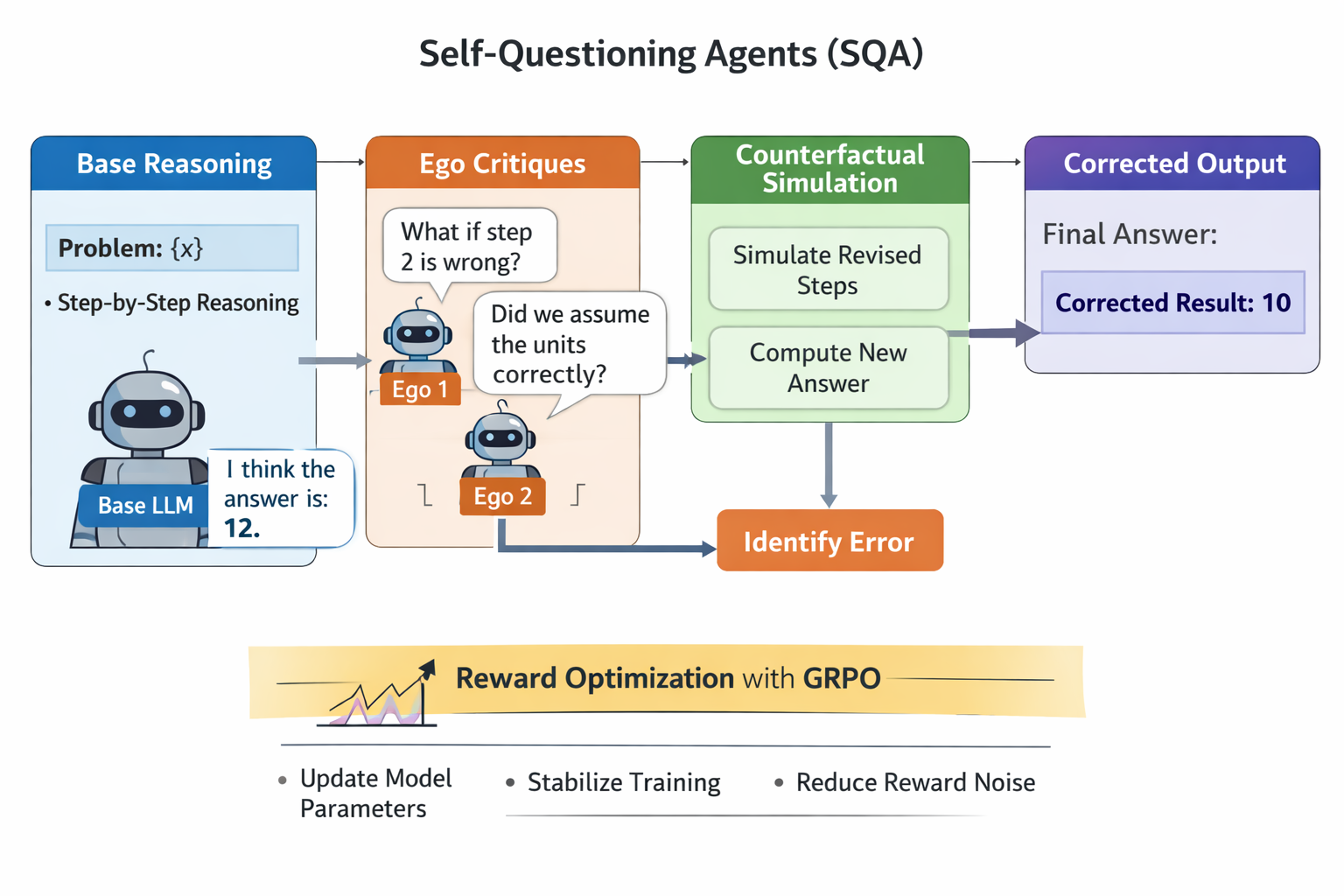
Recent advances in language model self-improvement, including self-reflection [14], step-wise verification [4, 17] , debate [5] , and self-reward optimization [6] , demonstrate that models can iteratively refine their own reasoning. However, these approaches typically depend on external critics, hand-crafted reward models, or ensemble sampling, introducing additional supervision and instability during training. We propose Counterfactual Self-Questioning (CSQ), a framework in which a single language model generates counterfactual critiques of its own reasoning and uses these internally generated trajectories as a structured policy optimization signal. CSQ decomposes learning into three stages: (1) an initial policy rollout producing a base reasoning trajectory; (2) self-questioning, where the model formulates targeted counterfactual probes conditioned on its own reasoning; and (3) counterfactual critique, where alternative trajectories expose faulty assumptions, missing constraints, or invalid steps. The resulting counterfactual trajectories provide relative feedback that can be directly integrated with policy optimization methods such as Group Relative Policy Optimization (GRPO) [10], without requiring external reward models or multiple agents. Across GSM8K [3], MATH [7] , and Minerva-style quantitative reasoning tasks [9], CSQ improves accuracy by +6.7 to +12.4 points over standard chain-ofthought prompting [16] and by +3.1 to +5.8 points over strong verification-based baselines. Ablation studies show that counterfactual self-questioning yields more diverse failure discovery, more precise error localization, and more stable training dynamics than prior self-improvement methods such as STaR [19], Self-Discover [11], and Self-Rewarding Language Models [6] . These results suggest that counterfactual self-questioning provides a scalable and stable alternative to external critics for policy optimization in language models, enabling robust reasoning improvement using internally generated training signals.
Large language models (LLMs) have achieved strong performance on mathematical and logical reasoning tasks when equipped with structured prompting techniques such as chain-of-thought [16], step-wise verification [17], and domain-specific training [9]. Despite these advances, LLM reasoning remains brittle: small errors in intermediate steps often propagate, models exhibit overconfident hallucinations, and failures are difficult to detect without external verification [4]. Improving reasoning reliability therefore requires mechanisms that expose and correct internal failure modes rather than relying solely on final-answer supervision.
Recent work explores whether LLMs can improve themselves through internally generated feedback. Approaches such as Reflexion [14], STaR [19], Self-Discover [11], debate [5], and self-rewarding language models [6] demonstrate that models can iteratively refine their reasoning. However, these arXiv:2601.00885v1 [cs.AI] 31 Dec 2025 methods typically rely on external critics, multi-agent debate, extensive sampling, or auxiliary verifier models, increasing computational cost and architectural complexity.
In contrast, human reasoning often relies on targeted counterfactual interrogation such as asking whether a particular step might be wrong and exploring the consequences before committing to a conclusion. This suggests an alternative paradigm for LLM self-improvement one based on internally generated counterfactual critique rather than external verification.
In this paper, we introduce Counterfactual Self-Questioning, a framework in which a single language model generates and evaluates counterfactual critiques of its own reasoning. Given an initial chainof-thought solution, the model produces targeted “What if this step is wrong?” probes, simulates alternative reasoning trajectories, and uses the resulting signals to refine its policy. Counterfactual critiques are generated by lightweight ego critics that share parameters with the base model and introduce no additional learned components.
Our approach differs from prior self-improvement methods in three key ways. First, critique is generated from a single policy rollout rather than from ensembles, external critics, or stored successful trajectories. Second, counterfactual reasoning is applied within the model’s own reasoning trajectory rather than at the input or data level. Third, the resulting critiques are converted into structured learning signals using Group Relative Policy Optimization (GRPO) [10], enabling stable policy updates without a learned value function.
We evaluate Counterfactual Self-Questioning on established mathematical reasoning benchmarks, including GSM8K [3], MATH [7], and Minerva-style quantitative reasoning tasks [9]. Across four model families and multiple capacity regimes, the proposed method improves accuracy over standard chain-of-thought baselines, with the largest gains observed for small and medium-sized models. Ablation studies show that one or two counterfactual critics provide the best balance between critique diversity and optimization stability.
In summary, this work makes the following contributions:
• We propose Counterfactual Self-Questioning, a verifier-free framework for improving LLM reasoning via internally generated counterfactual critique. • We introduce a simple training and inference pipeline that converts counterfactual critiques into structured policy optimization signals using GRPO. • We demonstrate consistent improvements on GSM8K, MATH, and Minerva-style tasks across multiple model sizes, with detailed analysis of stability and scaling behavior.
Our work relates to prior efforts on improving language model reasoning through self-improvement, verification, multi-agent feedback, counterfactual reasoning, and reinforcement learning with modelgenerated signals. We position Counterfactual Self-Questioning as a method for constructing an internal, trajectory-level policy optimization signal that complements existing approaches.
Self-Improvement and Iterative Reasoning: Several methods explore whether language models can improve their own reasoning using internally generated feedback. Reflexion [14] introduces memory-based self-correction, STaR [19] bootstraps improved policies from model-generated correct solutions, and Self-Discover [11] synthesizes new reasoning strategies through internal feedback.
Self-consistency sampling [15] reduces variance by aggregating multiple reasoning paths. These approaches typically rely on extensive sampling, replay buffers, or external filtering. In contrast, Counterfactual Self-Questioning generates critique from a single policy rollout by probing alternative counterfactual trajectories, avoiding reliance on large ensembles or stored solutions.
Verification, Critics, and Debate: Another line of work reduces hallucinations through explicit verification. Chain-of-Verification (CoVe) [4] and step-wise verification [17] validate intermediate reaso
This content is AI-processed based on open access ArXiv data.