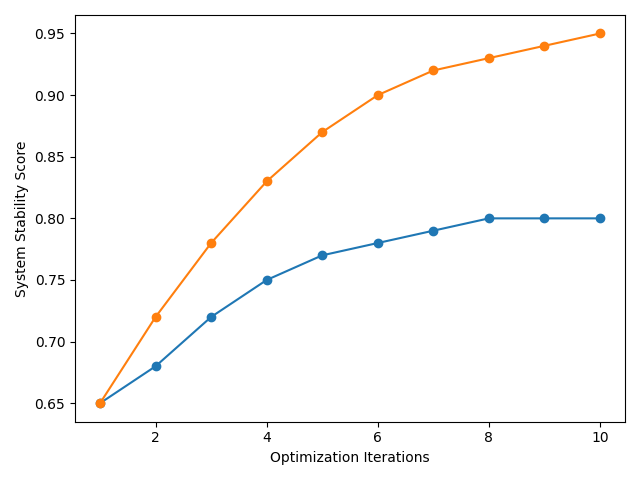
Modern cloud-native systems increasingly rely on multi-cluster deployments to support scalability, resilience, and geographic distribution. However, existing resource management approaches remain largely reactive and cluster-centric, limiting their ability to optimize system-wide behavior under dynamic workloads. These limitations result in inefficient resource utilization, delayed adaptation, and increased operational overhead across distributed environments. This paper presents an AI-driven framework for adaptive resource optimization in multi-cluster cloud systems. The proposed approach integrates predictive learning, policy-aware decisionmaking, and continuous feedback to enable proactive and coordinated resource management across clusters. By analyzing cross-cluster telemetry and historical execution patterns, the framework dynamically adjusts resource allocation to balance performance, cost, and reliability objectives. A prototype implementation demonstrates improved resource efficiency, faster stabilization during workload fluctuations, and reduced performance variability compared to conventional reactive approaches. The results highlight the effectiveness of intelligent, self-adaptive infrastructure management as a key enabler for scalable and resilient cloud platforms.
Cloud computing has evolved from isolated, single-cluster deployments into highly distributed, multi-cluster architectures designed to support scalability, resilience, and geographic diversity [1]. Modern applications increasingly span multiple clusters to meet performance requirements, ensure fault tolerance, and comply with data locality and regulatory constraints [2] . While this architectural shift improves availability and flexibility, it also introduces new challenges in coordinating resources across heterogeneous and geographically dispersed environments.
Existing cloud resource management mechanisms primarily operate within individual clusters and rely on reactive control strategies, such as threshold-based autoscaling [3]. Although effective for localized workload fluctuations, these approaches lack global awareness and are often unable to reason about inter-cluster dependencies, workload migration, or systemwide efficiency. As a result, organizations frequently experience resource fragmentation, delayed adaptation to workload changes, and increased operational overhead when managing large-scale, multi-cluster deployments [4], [5].
Artificial intelligence (AI) offers a promising foundation for addressing these limitations by enabling predictive, data-driven decision-making across distributed systems [6]. By leveraging historical telemetry, workload behavior, and runtime feedback, AI-driven approaches can anticipate demand patterns and proactively optimize resource allocation. However, many existing solutions focus on narrow optimization objectives such as anomaly detection or single-cluster autoscaling without providing a unified mechanism for coordinated, cross-cluster resource management.
Moreover, the increasing complexity of cloud-native environments introduces challenges related to stability, explainability, and control. Optimization actions that are beneficial at a local level may produce unintended consequences at the system level, particularly when multiple clusters compete for shared resources or operate under diverse policy constraints [7]. This highlights the need for intelligent coordination mechanisms that balance local autonomy with global system objectives while maintaining predictable and stable behavior [8].
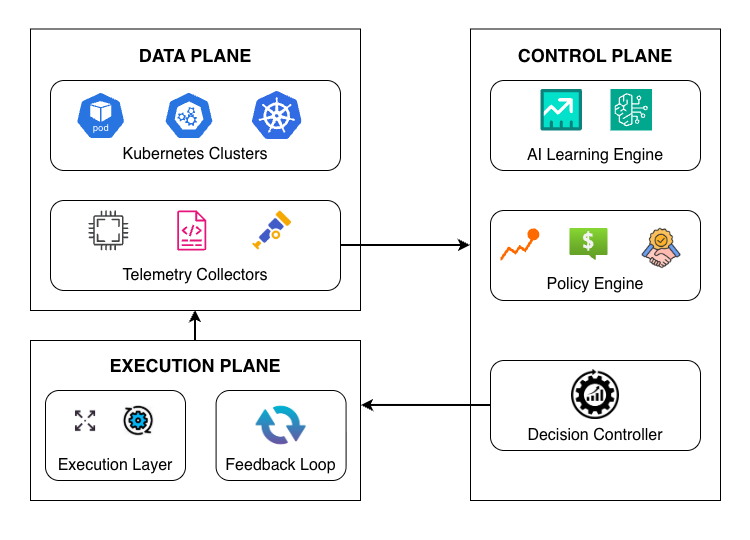
This paper introduces an AI-driven framework for adaptive resource optimization in multi-cluster cloud environments. The proposed approach integrates predictive learning, policy-aware reasoning, and continuous feedback to enable coordinated and autonomous decision-making across clusters. By combining global observability with localized execution, the framework balances performance, cost efficiency, and reliability under dynamic workload conditions. The primary contributions of this work are as follows:
• A unified architecture for AI-driven resource optimization across distributed cloud clusters. Multi-cluster cloud environments have become an essential architectural pattern for modern cloud-native systems, enabling scalability, fault tolerance, geographic distribution, and regulatory compliance. Microservices-based applications, global service delivery platforms, and data-intensive workloads increasingly rely on multiple clusters to isolate failure domains, reduce latency, and support heterogeneous infrastructure requirements [9]- [11]. While this architectural model improves flexibility and resilience, it also introduces substantial complexity in coordinating resource usage across distributed clusters.
Most existing cloud orchestration mechanisms are designed around a single-cluster abstraction. Platforms such as Kubernetes provide mature capabilities for intra-cluster scheduling, autoscaling, and self-healing, but they lack inherent mechanisms for global coordination across clusters [12]. As a result, resource management decisions are often made in isolation, based solely on local observations, limiting governance, security enforcement, and cross-cluster policy consistency [13]. This fragmented control model can lead to inefficient resource utilization, where capacity remains underutilized in some clusters while others experience congestion, performance degradation, or increased failure rates [14].
In addition, current resource optimization strategies predominantly rely on static thresholds, predefined heuristics, or manually tuned policies, which often fail to adapt to dynamic workload behavior and evolving service-level objectives [15], [16]. While these approaches are simple to implement, they struggle to adapt to evolving workload characteristics, nonstationary traffic patterns, and complex inter-service dependencies. In multi-cluster environments, these limitations are amplified, as local optimization actions may inadvertently conflict with global system objectives, leading to oscillations, delayed convergence, or unpredictable behavior.
The growing scale and dynamism of cloud-native systems motivate the need for resource management approaches that can reason be
This content is AI-processed based on open access ArXiv data.