Retrieval-augmented generation (RAG) is highly sensitive to the quality of selected context, yet standard top-k retrieval often returns redundant or near-duplicate chunks that waste token budget and degrade downstream generation. We present AdaGReS, a redundancy-aware context selection framework for token-budgeted RAG that optimizes a setlevel objective combining query-chunk relevance and intra-set redundancy penalties. Ada-GReS performs greedy selection under a tokenbudget constraint using marginal gains derived from the objective, and introduces a closedform, instance-adaptive calibration of the relevance-redundancy trade-off parameter to eliminate manual tuning and to adapt to candidatepool statistics and budget limits. We further provide a theoretical analysis showing that the proposed objective exhibits ε-approximate submodularity under practical embedding similarity conditions, yielding near-optimality guarantees for greedy selection. Experiments on opendomain question answering (Natural Questions) and a high-redundancy biomedical (drug) corpus demonstrate consistent improvements in redundancy control and context quality, translating to better end-to-end answer quality and robustness across settings.
Retrieval-augmented generation (RAG), first introduced by Lewis et al. (2020) (Lewis et al., 2020), has rapidly developed into a mainstream technique for enabling large language models (LLMs) to incorporate external knowledge and enhance performance on knowledge-intensive tasks. By integrating external documents or knowledge chunks with large models, RAG allows systems to dynamically access up-to-date, domain-specific information without frequent retraining, thereby improving access to up-to-date and domain-specific information without frequent retraining. Dense passage retrievers such as DPR proposed by Karpukhin et al. (2020) (Karpukhin et al., 2020), the ColBERT model by Khattab and Zaharia (2020) (Khattab and Zaharia, 2020), as well as later architectures like REALM (Guu et al., 2020) and FiD (Lewis et al., 2020), have further improved the retrieval, encoding, and fusion mechanisms of RAG in practical applications. Today, RAG is widely applied in open-domain question answering (Kwiatkowski et al., 2019), scientific literature retrieval (Lála et al., 2023), healthcare, enterprise knowledge management, and other scenarios, becoming a key paradigm for enabling LLMs to efficiently leverage external knowledge.
Despite the significant advancements brought by RAG, particularly in enhancing knowledge timeliness, factual consistency, and task adaptability for LLMs, overall performance is still highly dependent on the quality of context chunks returned by the retrieval module. A persistent challenge is how to ensure that the retrieved results are not only highly relevant to the user’s query but also exhibit sufficient diversity in content. Numerous empirical studies have found that systems tend to return overlapping or near-duplicate chunks under top-k retrieval, especially when documents are chunked densely or the corpus is highly redundant (Pradeep, Thakur, Sharifymoghaddam, Zhang, Nguyen, Campos, Craswell, and Lin, 2025) (Tang et al., 2025). Such redundancy not only wastes valuable context window (token budget) but can also obscure key information, limiting the model’s capacity for deep reasoning, comparative analysis, or multi-perspective synthesis, ultimately undermining factual accuracy and logical coherence.
For instance, in multi-hop question answering and multi-evidence reasoning tasks, if the retriever mainly returns paraphrased but essentially identical chunks, the model will struggle to acquire complete causal chains or diverse perspectives. This type of pseudo-relevance phenomenon has been shown to be an important contributor to hallucinations in RAG systems: when lacking sufficient heterogeneous evidence, the model may rely on internal priors and produce superficially coherent but externally unsupported and erroneous content (Zhang and Zhang, 2025).
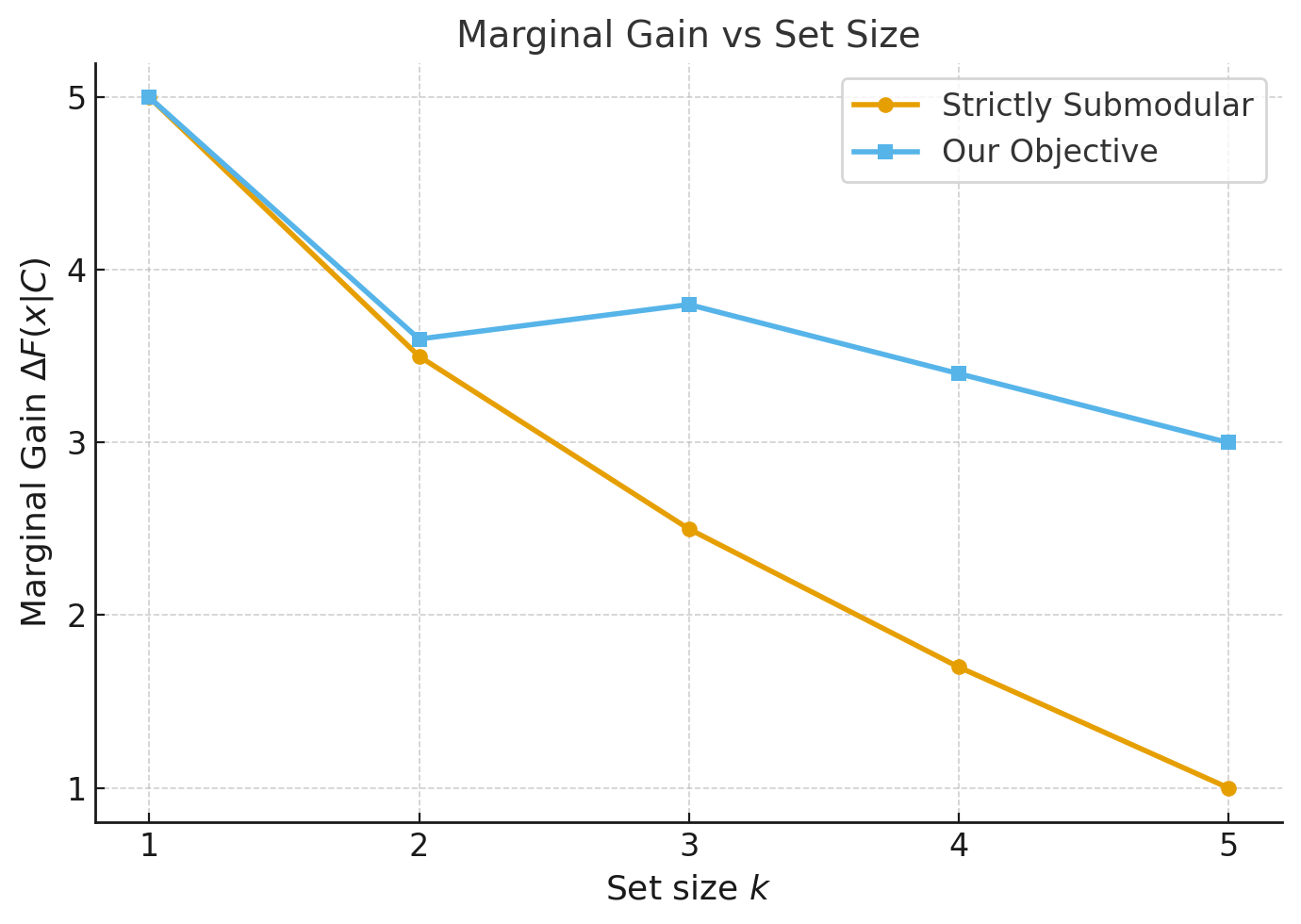
To address fragment redundancy and hallucination, Maximal Marginal Relevance (MMR) and its variants have been widely adopted in existing RAG systems as well as in emerging frameworks such as GraphRAG (Peng et al., 2024) and FreshLLM (Vu et al., 2024). By balancing relevance and diversity in the set of retrieved candidates, MMR can reduce redundancy and improve coverage. While effective in practice, these approaches still suffer from notable limitations: (1) their weight parameters are highly dependent on manual tuning and cannot dynamically adapt to the structure of different candidate pools or token budgets; (2) they only support local greedy selection, making it difficult to achieve set-level global optimality and potentially missing the best combination of chunks.
To systematically solve the issues of context redundancy, limited diversity, and cumbersome parameter tuning in RAG, this paper proposes and implements a novel context scoring and selection mechanism based on redundancy-awareness and fully adaptive weighting. Specifically, we design a set-level scoring function that not only measures the relevance between each candidate chunk and the query, but also explicitly penalizes redundancy among the selected fragments. The entire scoring process is mathematically modeled as the weighted difference between a relevance term and a redundancy term, with a tunable parameter β controlling the trade-off between them. Building on this, we further propose a dynamic and adaptive β adjustment strategy: by analyzing the average length, mean relevance, and redundancy distribution of the candidate pool, we derive a closed-form solution for the redundancy weight that adapts to different queries and budget constraints. This strategy provides a principled closed-form estimate of β, eliminating the need for manual parameter tuning or external heuristics. We also provide engineering implementations for instance-level β, as well as interfaces for fine-tuning on small validation sets and domain-specific customization, improving the method’s robustness and usability in real-world, variable scenarios.
To validate the theoretical foundation and practical effectiveness
This content is AI-processed based on open access ArXiv data.