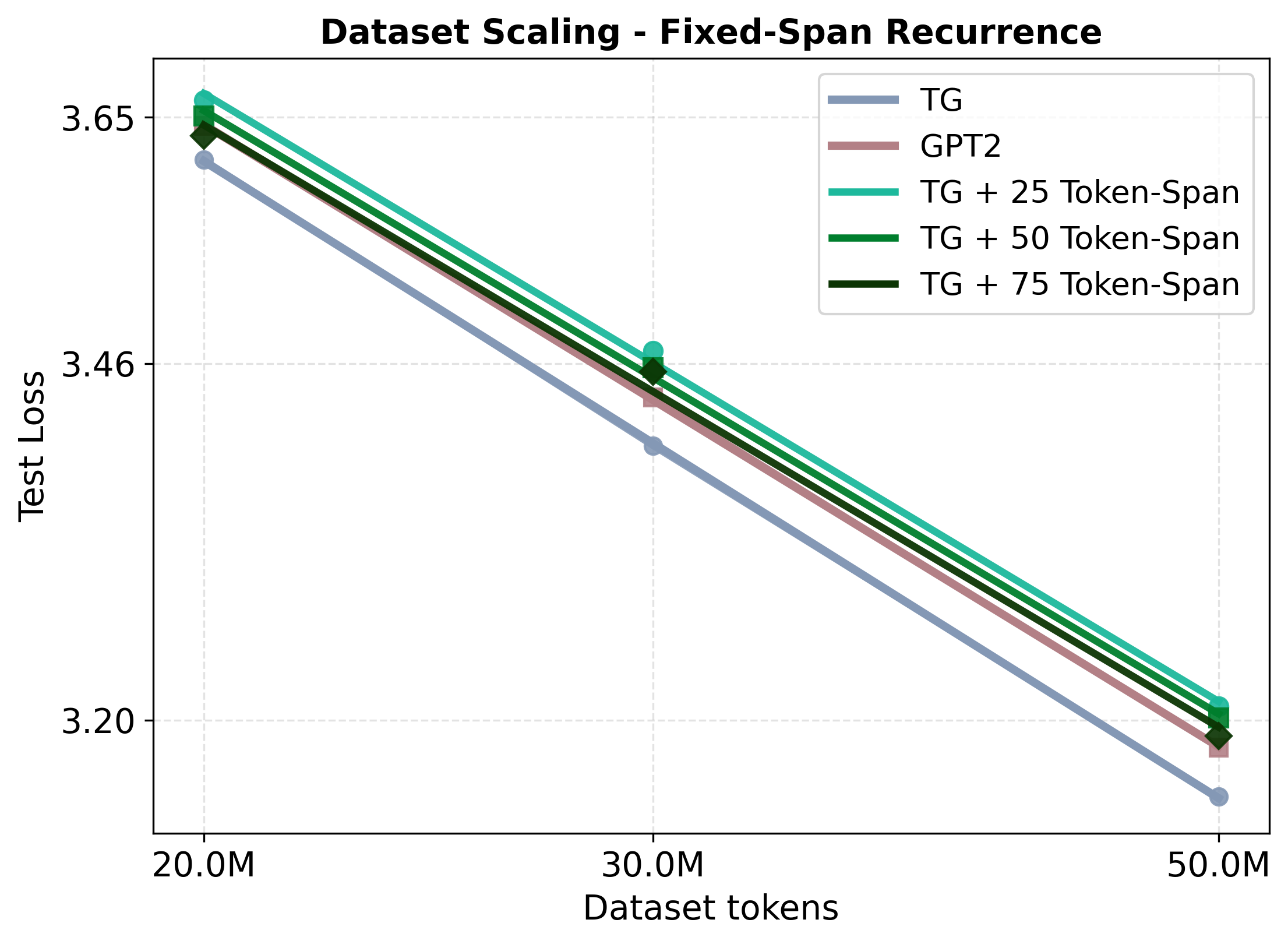
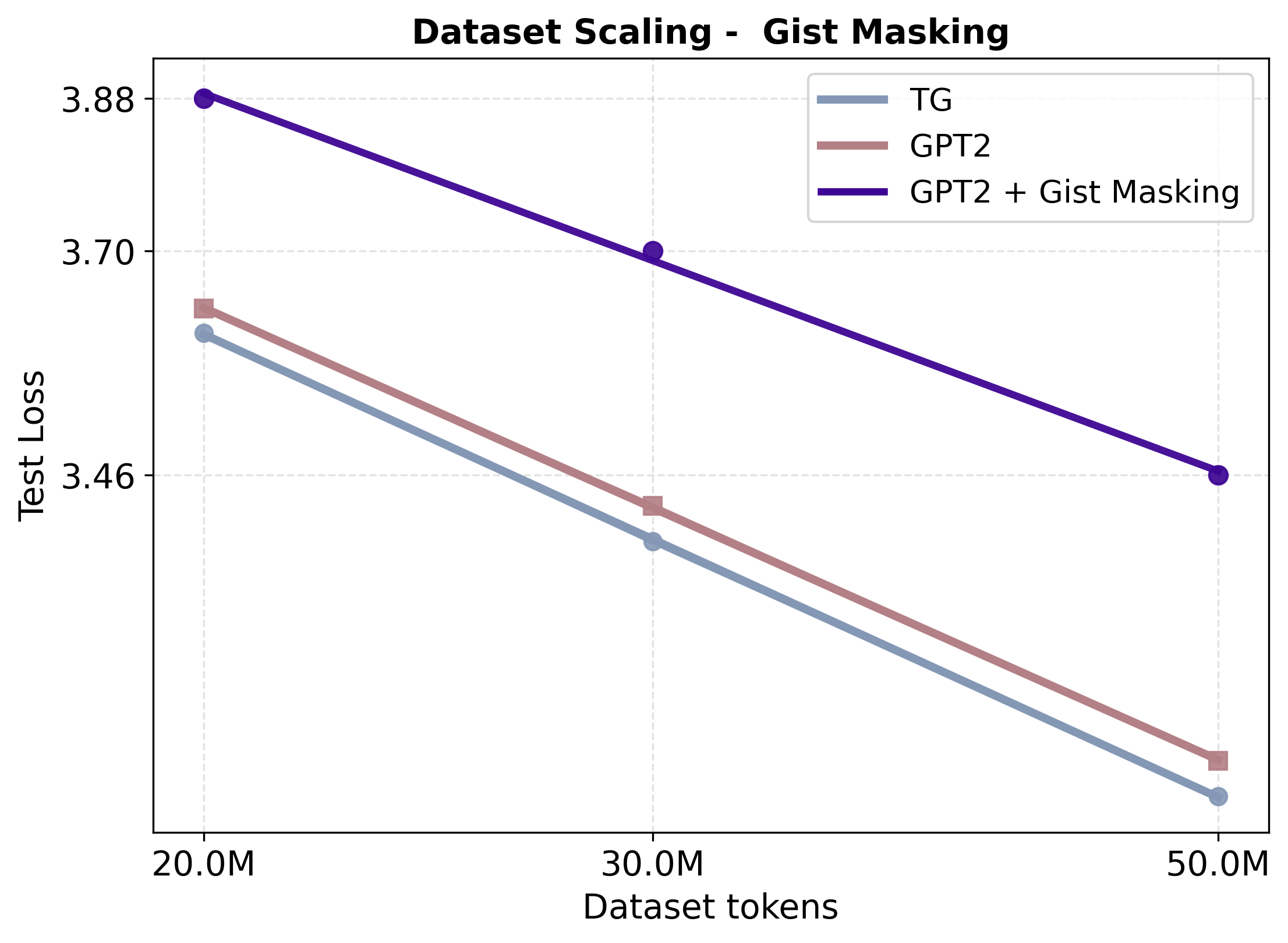
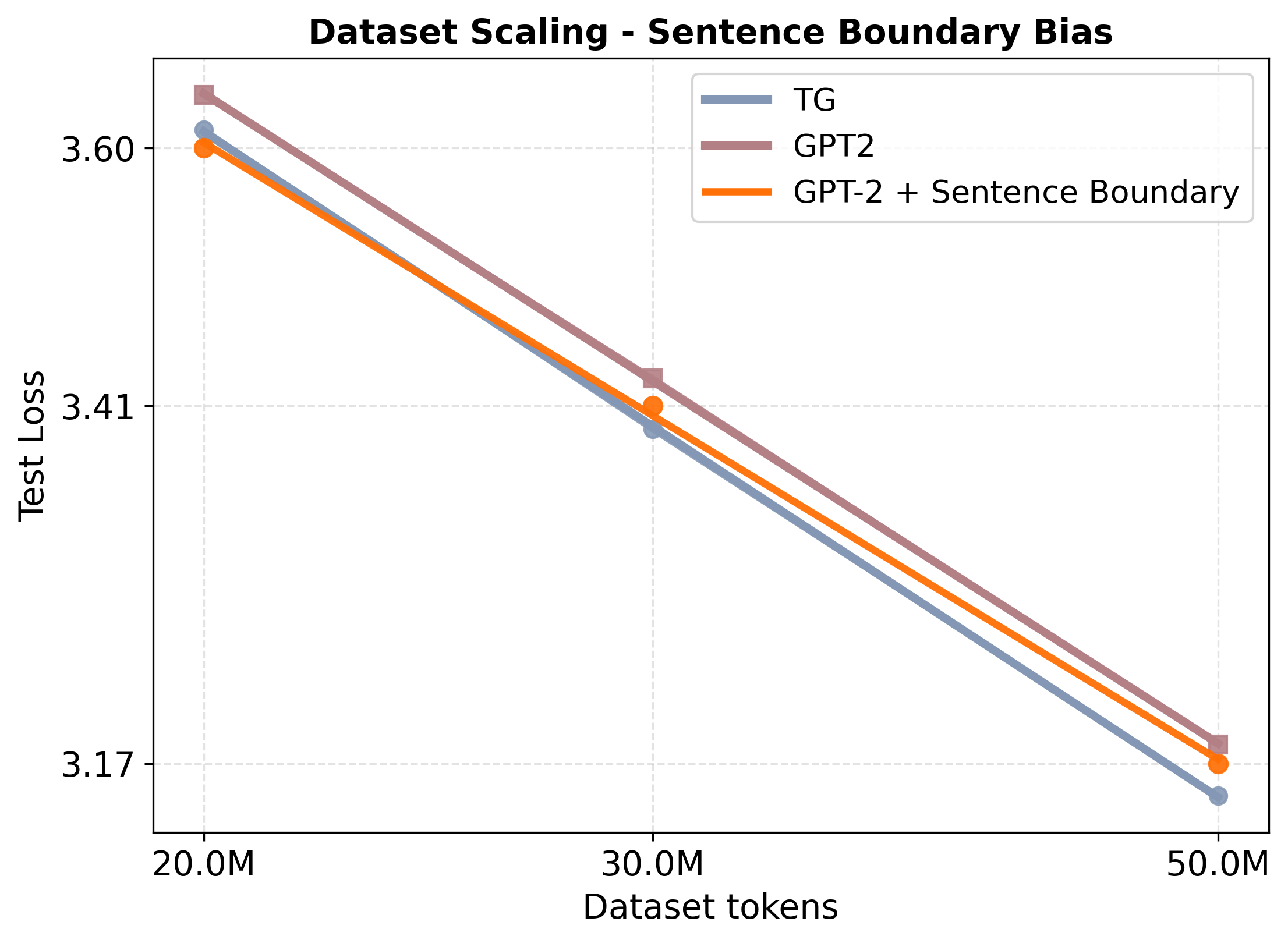
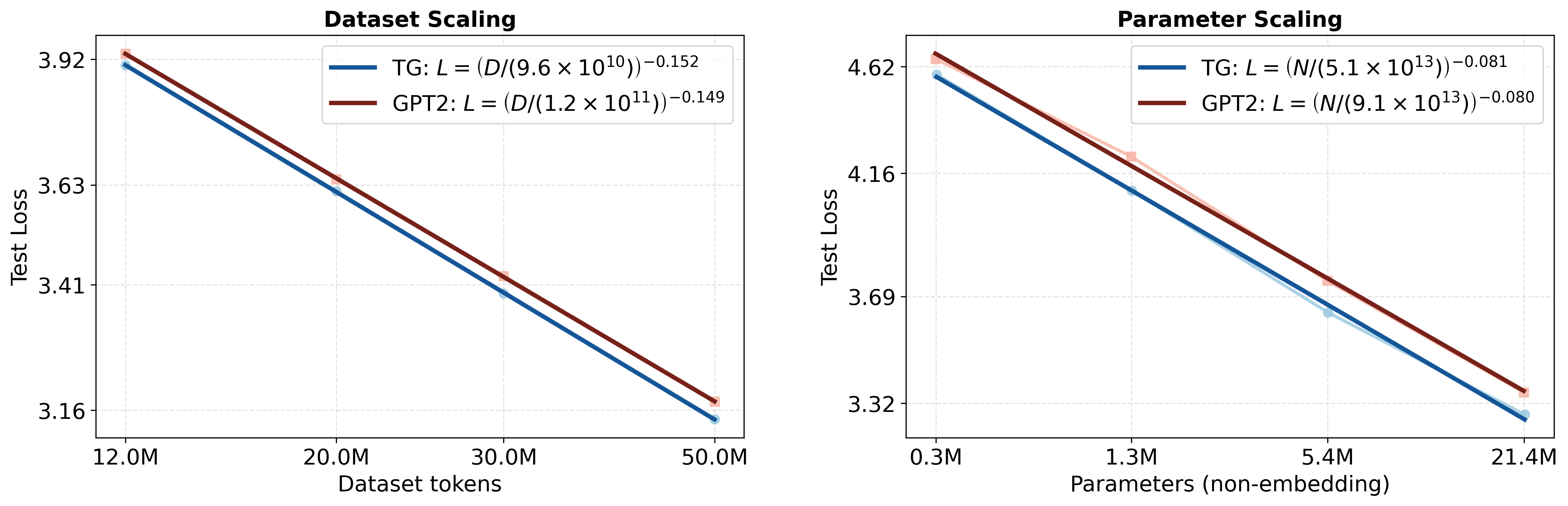
Transformer language models can generate strikingly natural text by modeling language as a sequence of tokens. Yet, by relying primarily on surface-level co-occurrence statistics, they fail to form globally consistent latent representations of entities and events, lack of which contributes to poor relational generalization (reversal curse), contextualization errors, and data inefficiency. On the other hand, cognitive science shows that human comprehension involves converting the input linguistic stream into compact, event-like representations that persist in memory while verbatim form is short-lived. Motivated by these cognitive findings, we introduce the Thought Gestalt (TG) Model, a recurrent transformer that models language at two levels of abstraction-tokens and sentence-level "thought" states. TG generates the tokens of one sentence at a time while cross-attending to a working memory of prior sentence representations. In TG, token and sentence representations are generated using a shared stack of transformer blocks and trained with a single objective, the next-token prediction loss: by retaining the computation graph of sentence representations written to the working memory, gradients from future token losses flow backward through cross-attention to optimize the parameters generating earlier sentence vectors. In scaling experiments, TG consistently improves data and parameter efficiency compared to matched GPT-2 runs, among other baselines, with scaling fits indicating GPT-2 requires ~5-8% more data and ~33-42% more parameters to match TG's test loss. TG also reduces errors in relational-direction generalization on a father-son reversal curse probe.
Prior work in cognitive science suggests that, in humans, language functions as a serial code for communicating underlying thoughts, rather than the constitutive medium of thought itself [1][2][3][4]. On this view, comprehension involves decoding a linguistic stream to construct a situation model-a mental representation that encodes the temporal sequences, causal relations, and entities of the described event [5,6]. Situation models support memory and later inference and are characterized as high-level conceptual representations integrated with prior knowledge rather than representations of the surface form of text [5,2].
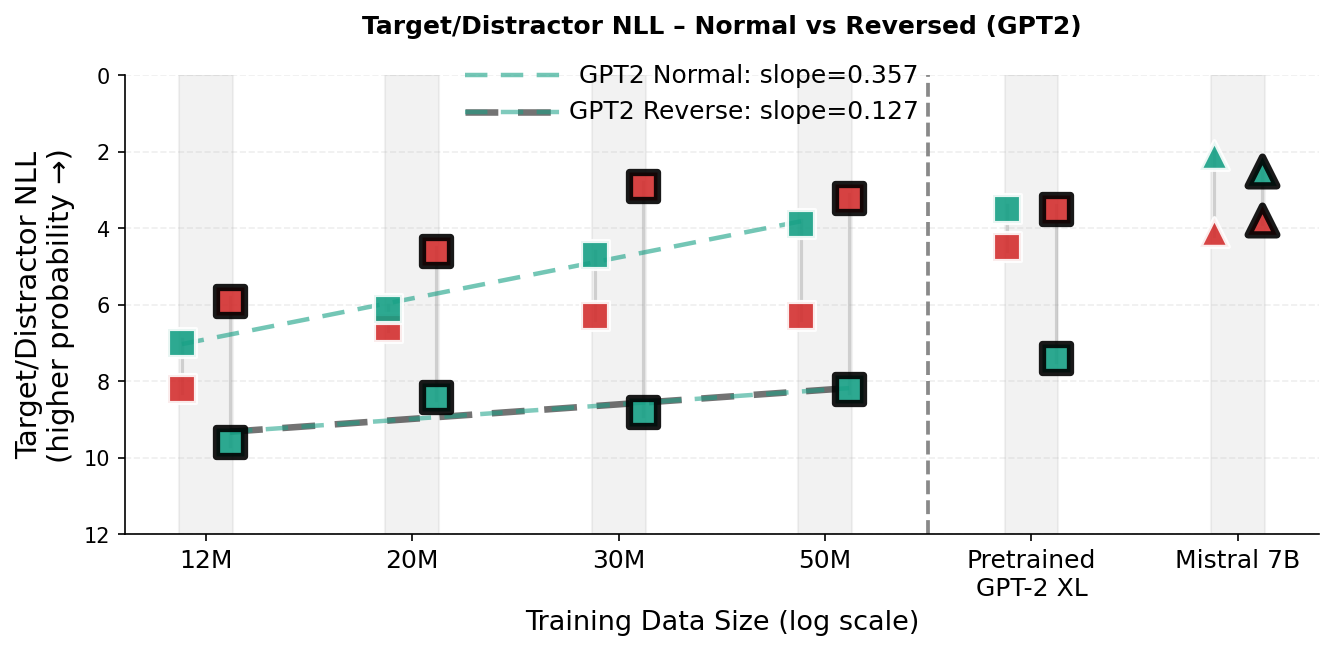
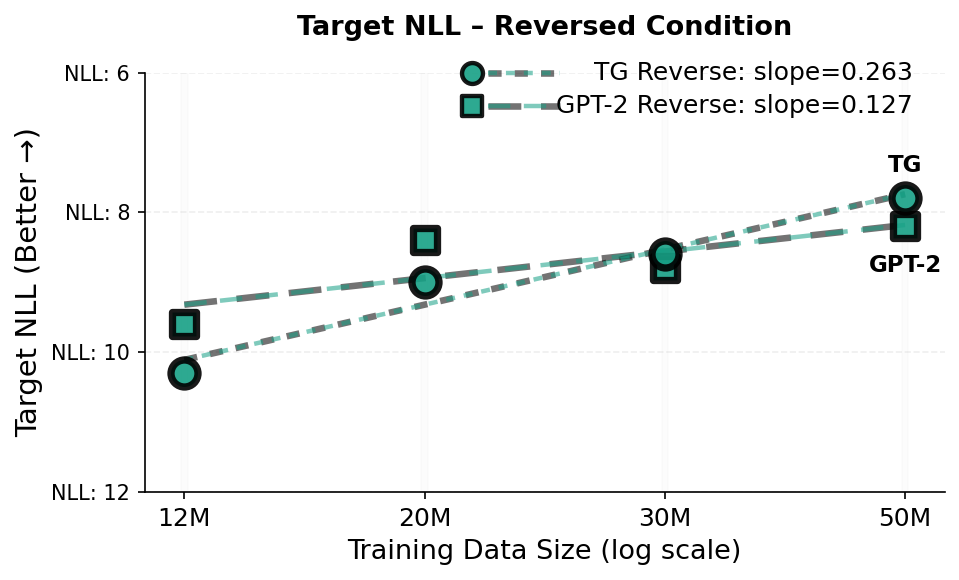
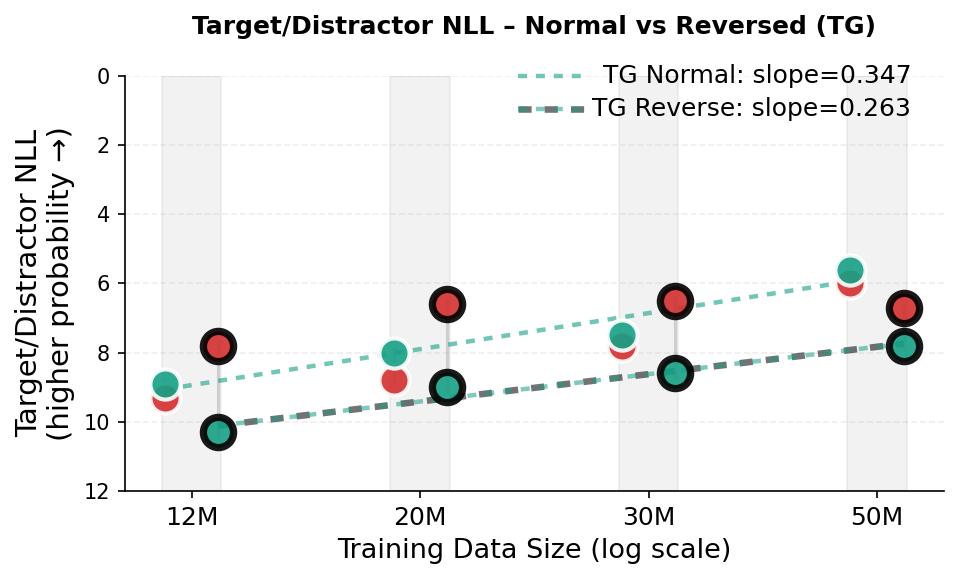
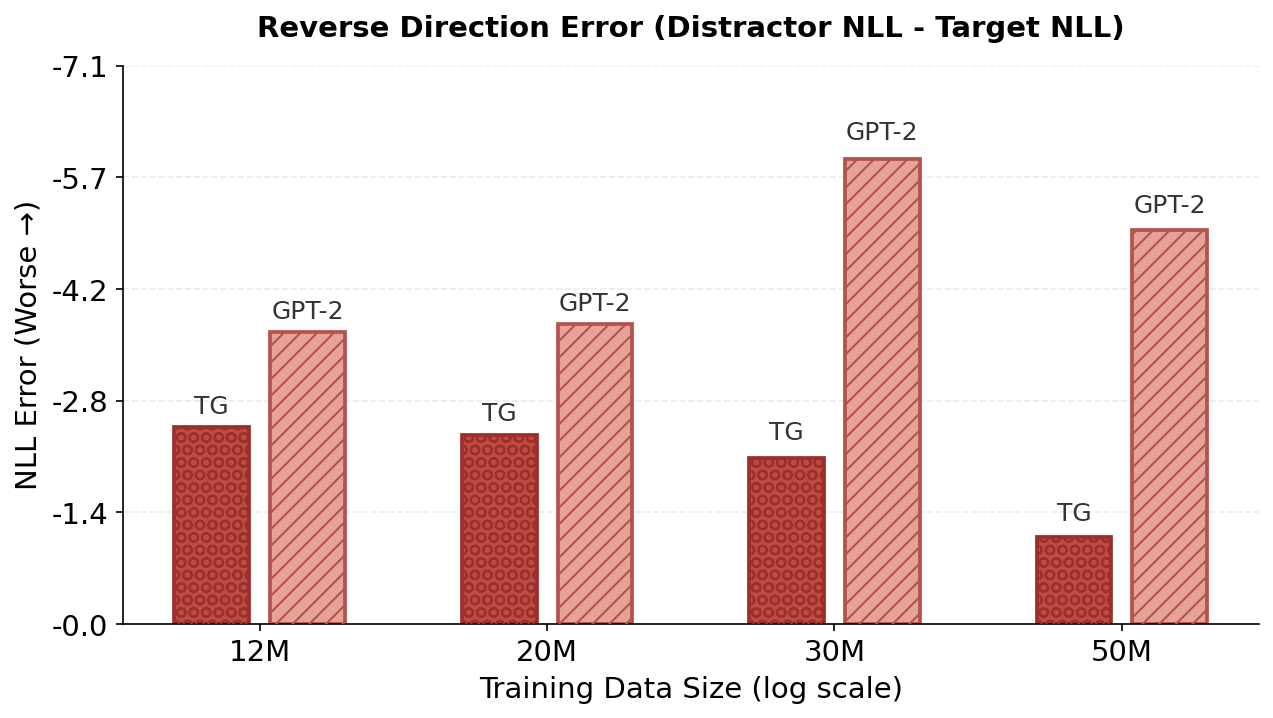
In contrast, modern Large Language Models (LLMs) learn by modeling language as a sequence of tokens and optimizing next-token prediction [7][8][9]. Although this has yielded models with remarkable fluency, a token-centric training signal can encourage brittle heuristics that capture surface-level statistical patterns rather than underlying concepts, leading to failures in generalization and compositional tasks [10][11][12]. The reversal curse is a concrete example: models trained on one relational direction (e.g., “A is B”) often fail to generalize to the inverse (“B is A”), treating the two directions of a relational fact as distinct patterns rather than a unified semantic encoding [13,14]. While Berglund et al. [13] note that the reversal curse is not observed for in-context learning in their evaluated models (e.g., , in §3. 4 we show that a substantial in-context directional asymmetry exists in smaller models at the scale of GPT-2 when a relation is queried in the opposite direction of the prompt.
Another shortcoming of standard transformer models is the contextualization errors identified by Lepori et al. [15], where in lower transformer layers, later tokens attend to earlier token representations before they have been fully contextualized to resolve ambiguities. Finally, many modern models are Figure 1: Forward/backward pass in TG. Each sentence step produces next-token predictions and a sentence vector, which is appended to a fixed-capacity memory without detaching its computation graph (removing the oldest memory entry if full). Next-token loss gradients flow back through memory to optimize parameters that produced earlier sentence representations (see Fig. 6 for a more detailed gradient-flow view).
trained on trillions of tokens [8], exceeding estimates of children’s language exposure by orders of magnitude (on the order of tens of millions of words [16]). These gaps motivate architectures that learn and reuse latent representations at a higher level of abstraction than tokens, i.e., models that organize information into coherent gestalts-holistic representations whose properties are not reducible to the sum of their parts [17]-that capture the underlying concepts and relations expressed by text [2,6].
In this work, we introduce the Thought Gestalt (TG) model, a recurrent transformer architecture designed to model language at two levels of abstraction: tokens and sentence-level thoughts. TG processes one sentence at a time (a “sentence step”), maintaining token-level information of only the current sentence, while context is maintained as a working memory of prior sentence representations: holistic representations, or “gestalts”, each compressing an entire sentence into a vector (Figure 1). This design is motivated by cognitive evidence that humans segment continuous streams of text into discrete events to organize memory: the verbal form is short-lived and confined to a narrow span, while earlier content is retained as stable, high-level representations of events and relations [18][19][20]. TG is also inspired by the Sentence Gestalt model [21], which incrementally maps a word sequence onto a single event representation from which role-filler structure can be decoded. TG similarly uses sentence boundaries as a structural proxy for thought boundaries. While not a one-to-one mapping, sentence boundaries serve as natural cognitive junctures where background information is integrated and concepts are updated [22,23]. Learning sentence representations is thus a first step toward building generative systems that can learn situation models and latent thought representations.
Architecturally, TG interleaves self-attention over tokens of the current sentence with cross-attention to a fixed-capacity working memory of prior sentence representations, where tokens attend causally within the current sentence and can reach prior sentences only via sentence-gestalt vectors (similar to gisting [24]). Each sentence representation is built from the contextualized hidden state at the end-of-sentence () token position (Figure 3). After each sentence step, the new sentence representation is appended to memory and the oldest entry is evicted when the memory is full. Crucially, TG retains the computation graph of sentence representations when writing to the working memory, allowing next-token p
This content is AI-processed based on open access ArXiv data.