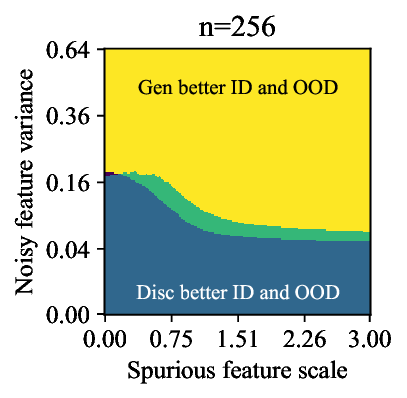
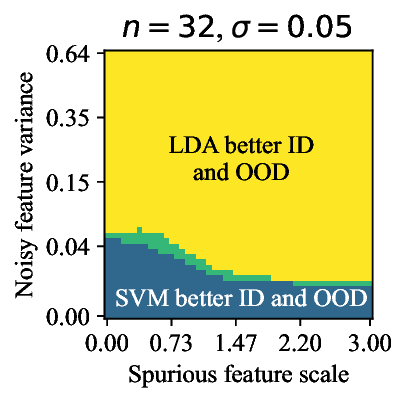
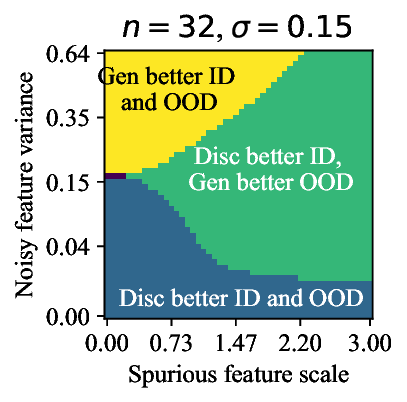
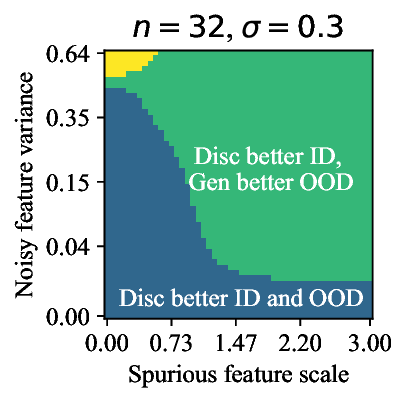
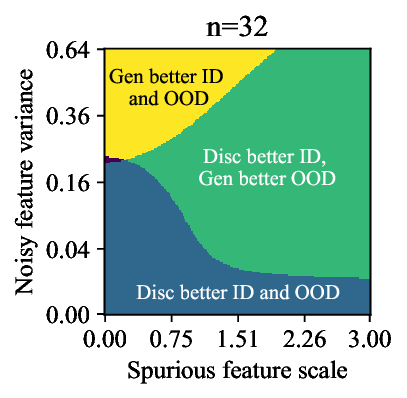
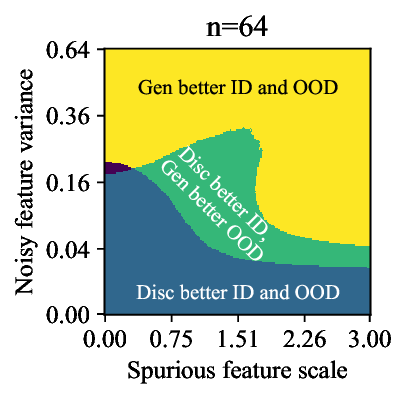
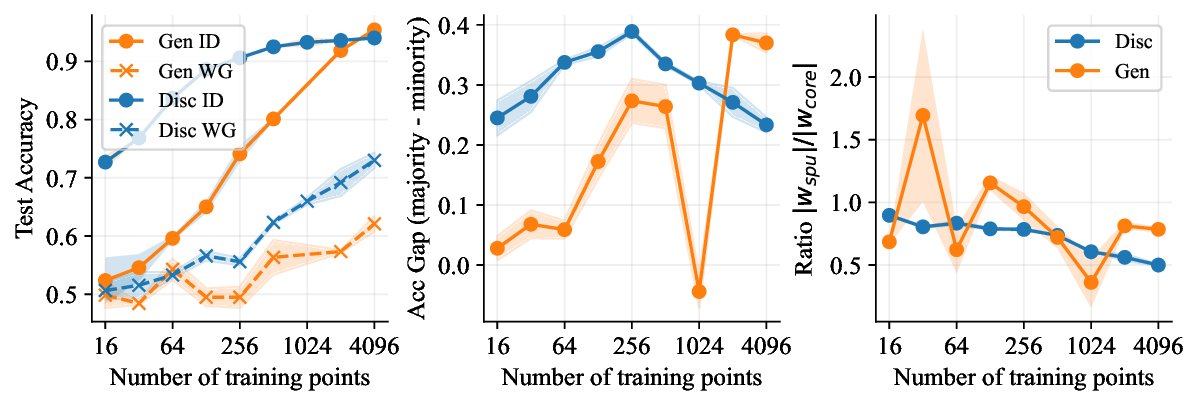
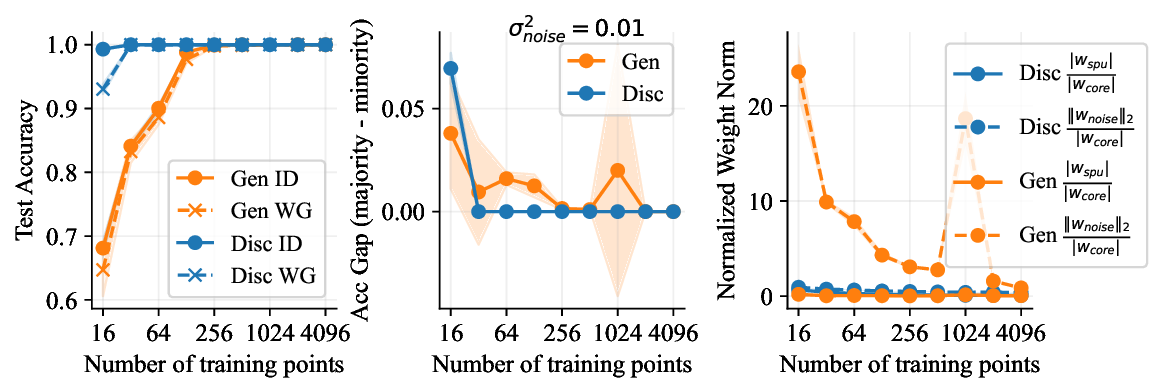
Discriminative approaches to classification often learn shortcuts that hold indistribution but fail even under minor distribution shift. This failure mode stems from an overreliance on features that are spuriously correlated with the label. We show that generative classifiers, which use class-conditional generative models, can avoid this issue by modeling all features, both core and spurious, instead of mainly spurious ones. These generative classifiers are simple to train, avoiding the need for specialized augmentations, strong regularization, extra hyperparameters, or knowledge of the specific spurious correlations to avoid. We find that diffusion-based and autoregressive generative classifiers achieve state-of-the-art performance on five standard image and text distribution shift benchmarks and reduce the impact of spurious correlations in realistic applications, such as medical or satellite datasets. Finally, we carefully analyze a Gaussian toy setting to understand the inductive biases of generative classifiers, as well as the data properties that determine when generative classifiers outperform discriminative ones. Code is at https://github.com/alexlioralexli/generative-classifiers.
Ever since AlexNet (Krizhevsky et al., 2012), classification with neural networks has mainly been tackled with discriminative methods, which train models to learn p θ (y | x). This approach has scaled well for in-distribution performance (He et al., 2016;Dosovitskiy et al., 2020), but these methods are susceptible to shortcut learning (Geirhos et al., 2020), where they output solutions that work well on the training distribution but may not hold even under minor distribution shift. The brittleness of these models has been well-documented (Recht et al., 2019;Taori et al., 2020), but beyond scaling up the diversity of the training data (Radford et al., 2021) so that everything becomes in-distribution, no approaches so far have made significant progress in addressing this problem.
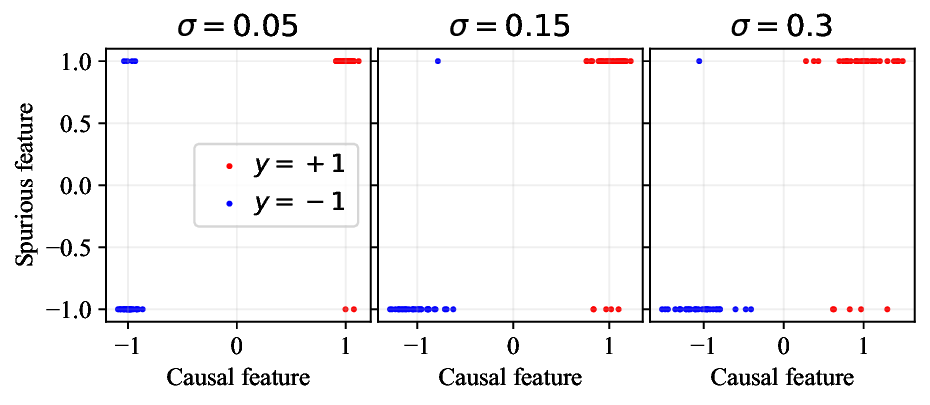
In this paper, we examine whether this issue can be solved with an alternative approach, called generative classifiers (Ng & Jordan, 2001;Yuille & Kersten, 2006;Zheng et al., 2023). This method trains a class-conditional generative model to learn p θ (x | y), and it uses Bayes’ rule at inference time to compute p θ (y | x) for classification. We hypothesize that generative classifiers may be better at avoiding shortcut solutions because their objective forces them to model the input x in its entirety. This means that they cannot just learn spurious correlations the way that discriminative models tend to do; they must eventually model the core features as well. Furthermore, we hypothesize that generative classifiers may have an inductive bias towards using features that are consistently predictive, i.e., features that agree with the true label as often as possible. These are exactly the core features that models should learn in order to do well under distribution shift.
Generative classifiers date back at least as far back as Fischer discriminant analysis (Fisher, 1936). Generative classifiers like Naive Bayes had well-documented learning advantages (Ng & Jordan, 2001) but were ultimately limited by the lack of good generative modeling techniques at the time. Today, however, we have extremely powerful generative models (Rombach et al., 2022;Brown et al., 2020), and some work is beginning to revisit generative classifiers with these new models (Li et al., 2023;Clark & Jaini, 2023). Li et al. (2023) in particular find that ImageNet-trained diffusion models exhibit the first “effective robustness” (Taori et al., 2020) without using extra data, which suggests that generative classifiers are have fundamentally different (and perhaps better) inductive biases. However, their analysis is limited to ImageNet distribution shifts and does not provide any understanding. Our paper focuses on carefully comparing deep generative classifiers against today’s V e i H S q / p 5 I W a D 1 K P B M M m A 4 0 P P e R P z P a y f o n 7 u p C O M E I e S z R X 4 i K U Z 0 U g f t C Q U c 5 c g Q x p U w f 6 V 8 w B T j a E o r m B K c + Z M X S a N S d k 7 L l d t K q X q R 1 Z E n h + S I n B C H n J E q u S Y 1 U i e c P J J n 8 k r e r C f r x X q 3 P m b R n J X N 7 J M / s D 5 / A P n R l z k = < / l a t e x i t > Di↵usion Model
< l a t e x i t s h a 1 _ b a s e 6 4 = " g z 6 h H e q R S 3
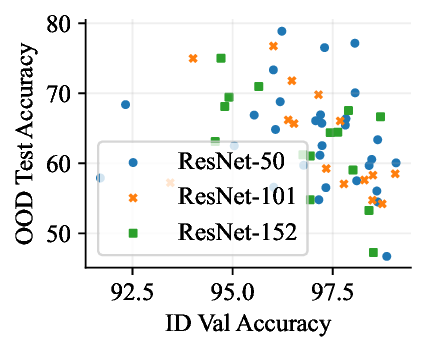
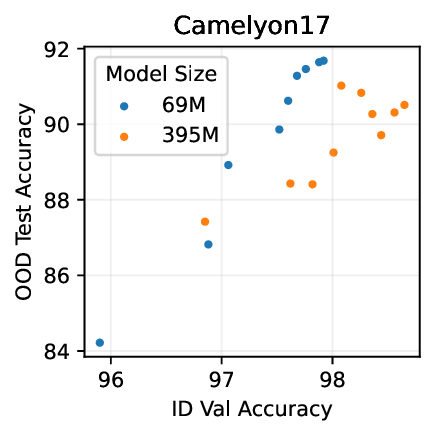
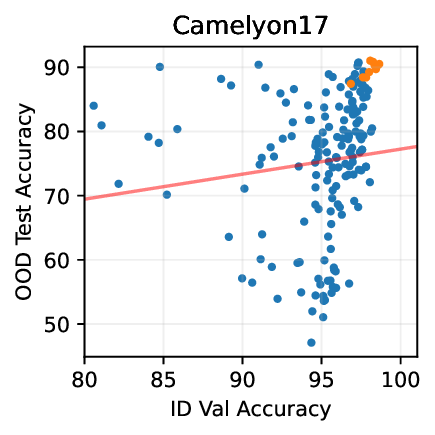
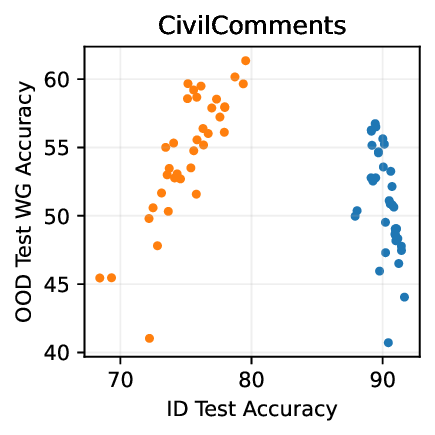
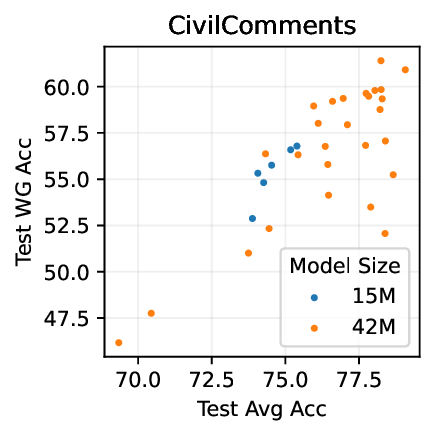
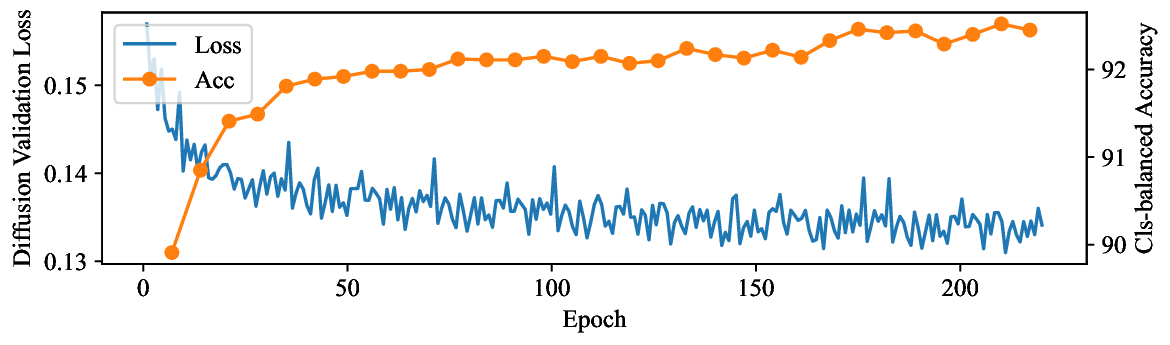
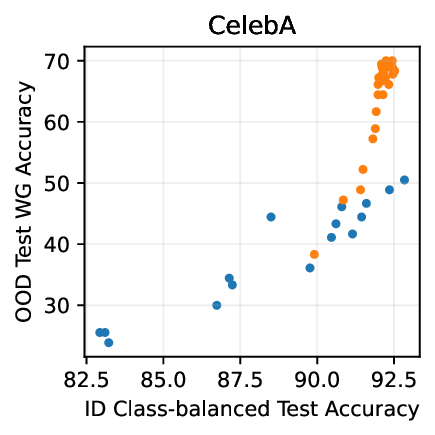
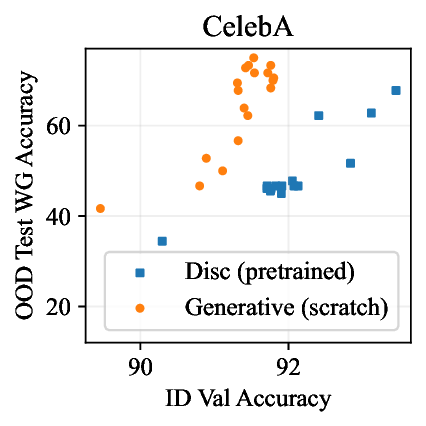
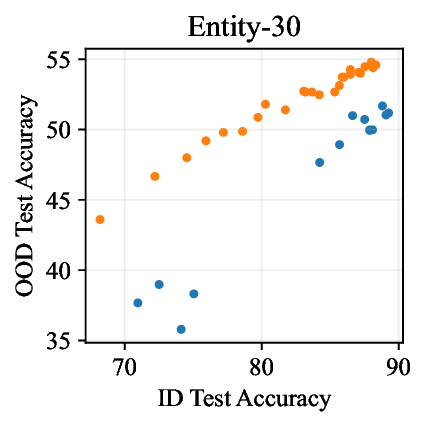
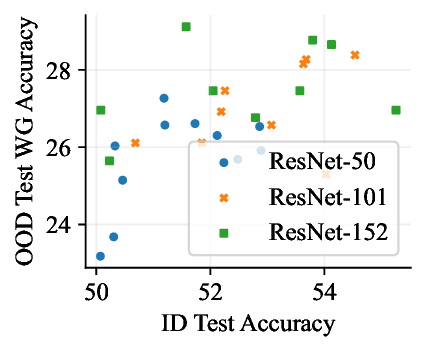
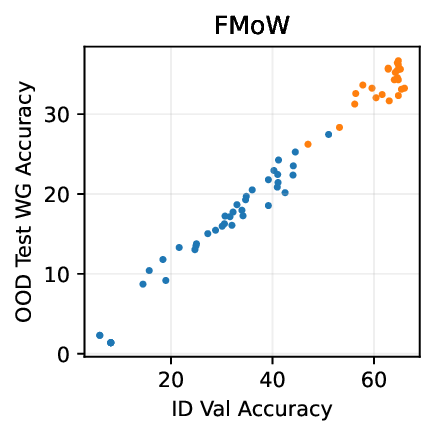
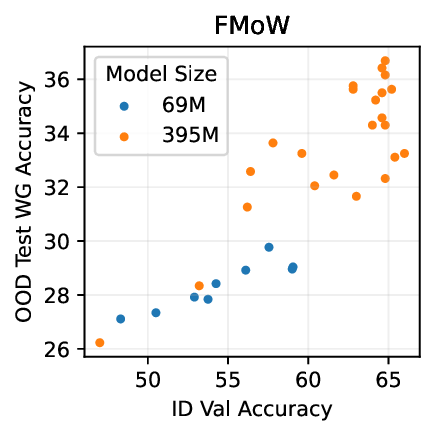
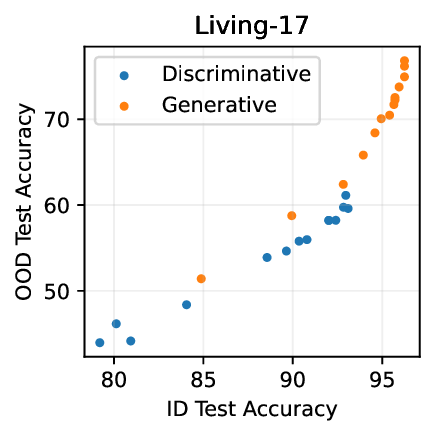
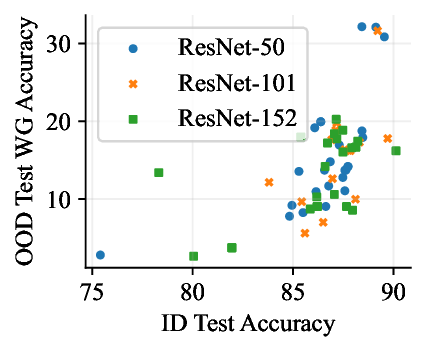
Figure 1: Generative classifiers. We repurpose today’s best generative modeling algorithms for classification. Generative classifiers predict arg max y p θ (x | y)p(y). We use diffusion-based generative classifiers on image tasks and autoregressive generative classifiers on text tasks, and find that they scale better out-of-distribution than discriminative approaches.
discriminative methods on a comprehensive set of distribution shift benchmarks. We additionally conduct a thorough analysis of the reasons and settings where they work. We list our contributions:
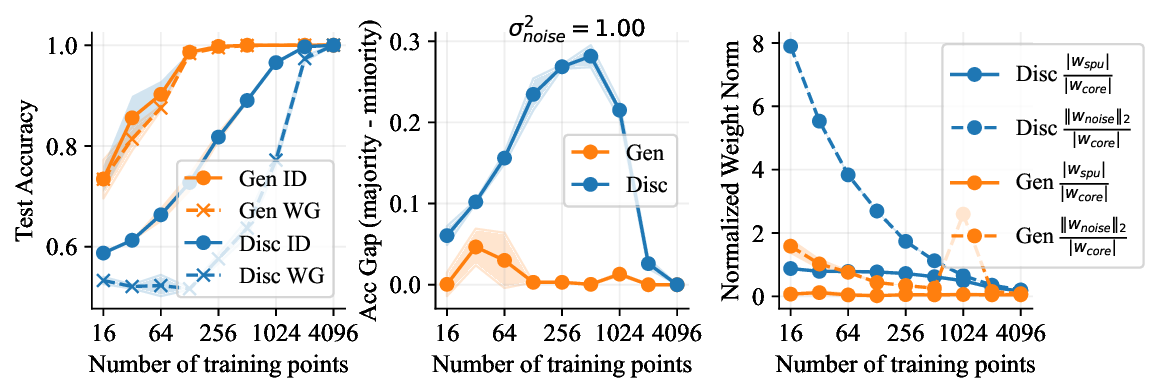
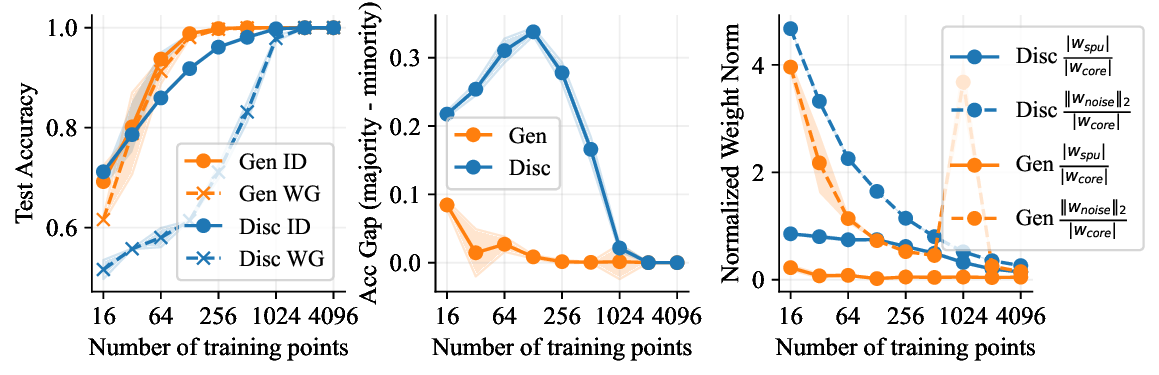
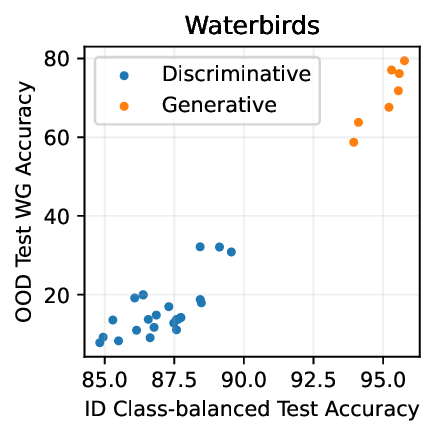
• Show significant advantages of generative classifiers on realistic distribution shifts. Generative classifiers are simple and effective compared to previous distribution shift mitigations. They utilize existing generative modeling pipelines, avoid additional hyperparameters or training stages, and do not require knowledge of the spurious correlations to avoid. We run experiments on standard distribution shift benchmarks across image and text domains and find that generative classifiers consistently do better under distribution shift than discriminative approaches. Most notably, they are the first algorithmic approach to demonstrate “effective robustness” (Taori et al., 2020), where they do better out-of-distribution than expected based on their in-distribution performance (see Figure 1, right). We also surprisingly find better in-distribution accuracy on most datasets, indicating that generative classifiers are also less susceptible to overfitting.
• Understand why generative classifiers work. We carefully test several hypotheses for why generative classifiers do better. We conclude that the generative objective p(x | y) provides more consistent learning signal by forcing the model to learn all features
This content is AI-processed based on open access ArXiv data.