Automatic text summarization has achieved high performance in high-resourced languages like English, but comparatively less attention has been given to summarization in less-resourced languages. This work compares a variety of different approaches to summarization from zero-shot prompting of LLMs large and small to fine-tuning smaller models like mT5 with and without three data augmentation approaches and multilingual transfer. We also explore an LLM translation pipeline approach, translating from the source language to English, summarizing and translating back. Evaluating with five different metrics, we find that there is variation across LLMs in their performance across similar parameter sizes, that our multilingual fine-tuned mT5 baseline outperforms most other approaches including zero-shot LLM performance for most metrics, and that LLM as judge may be less reliable on less-resourced languages.
Automatic text summarization in higher-resourced languages like English has achieved high scores in automated metrics (Al-Sabahi et al., 2018;Liu et al., 2022;Zhang et al., 2020a). However, for many lessresourced languages, the task remains challenging. While there are datasets that cover multilingual summarization in less-resourced languages (Giannakopoulos et al., 2015(Giannakopoulos et al., , 2017;;Palen-Michel and Lignos, 2023;Hasan et al., 2021), these datasets often still have relatively few examples compared to their higher-resourced counterparts.
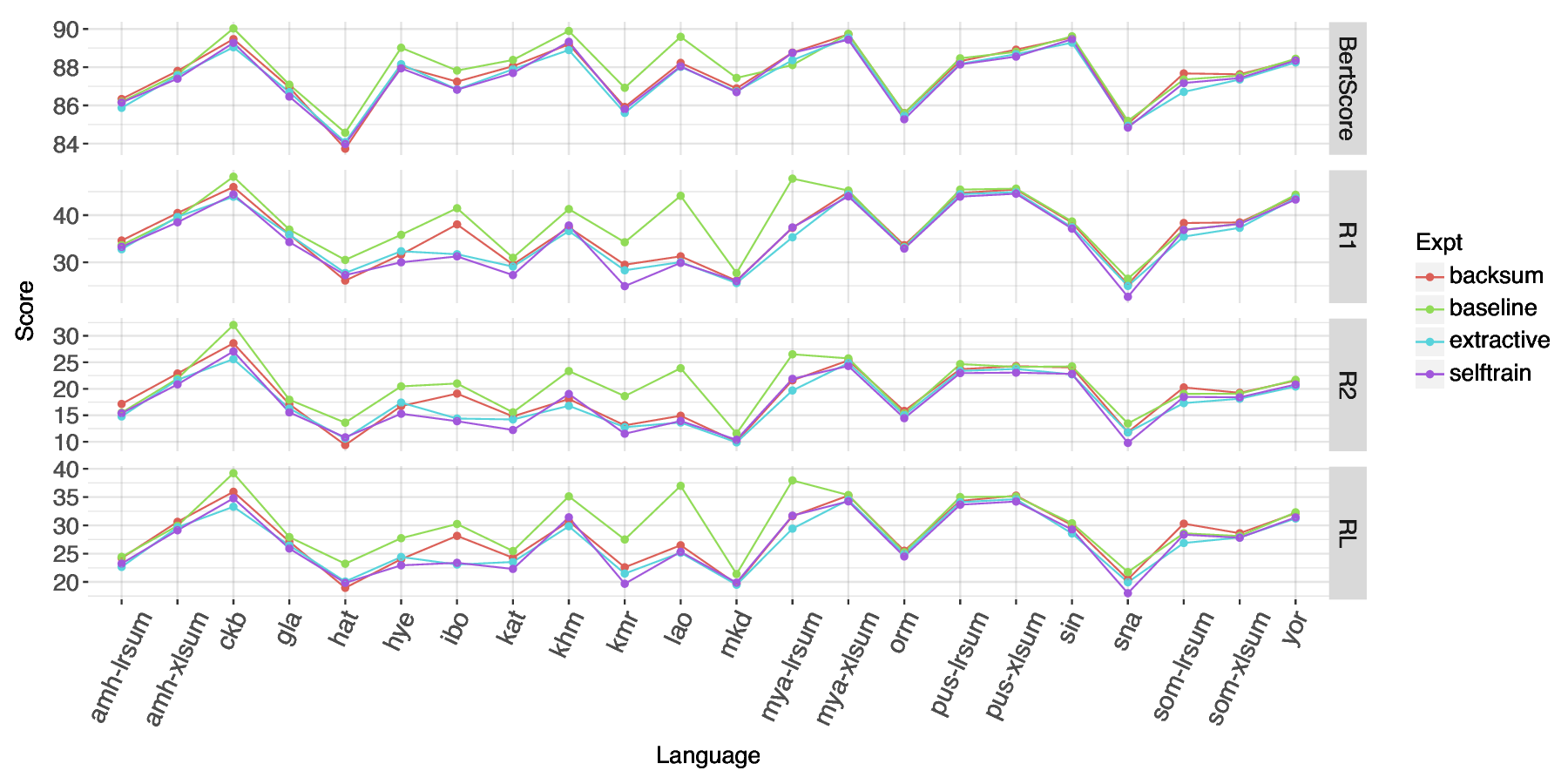
To better understand which approaches work best with less-resourced languages, we conduct a comparative study of a variety of approaches to automatic summarization. Specifically, we compare zero-shot prompting with three smaller-scale LLMs (Mixtral 8x7b, Llama 3 8b, Aya-101). Given that LLMs’ pretraining data tends to be dominated by higher-resourced languages, we also experiment with fine-tuning smaller mT5 in a variety of settings. We fine-tune mT5 per-individual language and with all available language data combined for multilingual transfer as baselines. Multilingual transfer has proven to be a useful strategy for less-resourced languages (Wang et al., 2021); however, other works have shown that multilingual models have limits and given enough data, fully monolingual models can perform better (Virtanen et al., 2019;Tanvir et al., 2021).
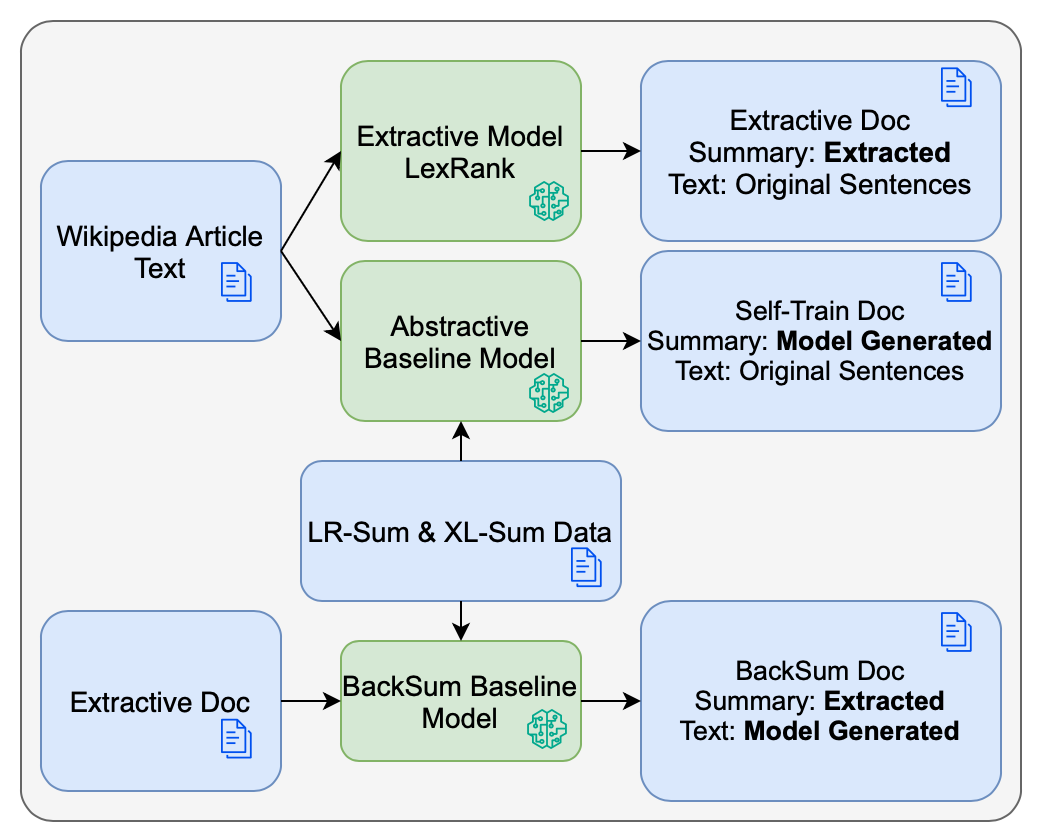
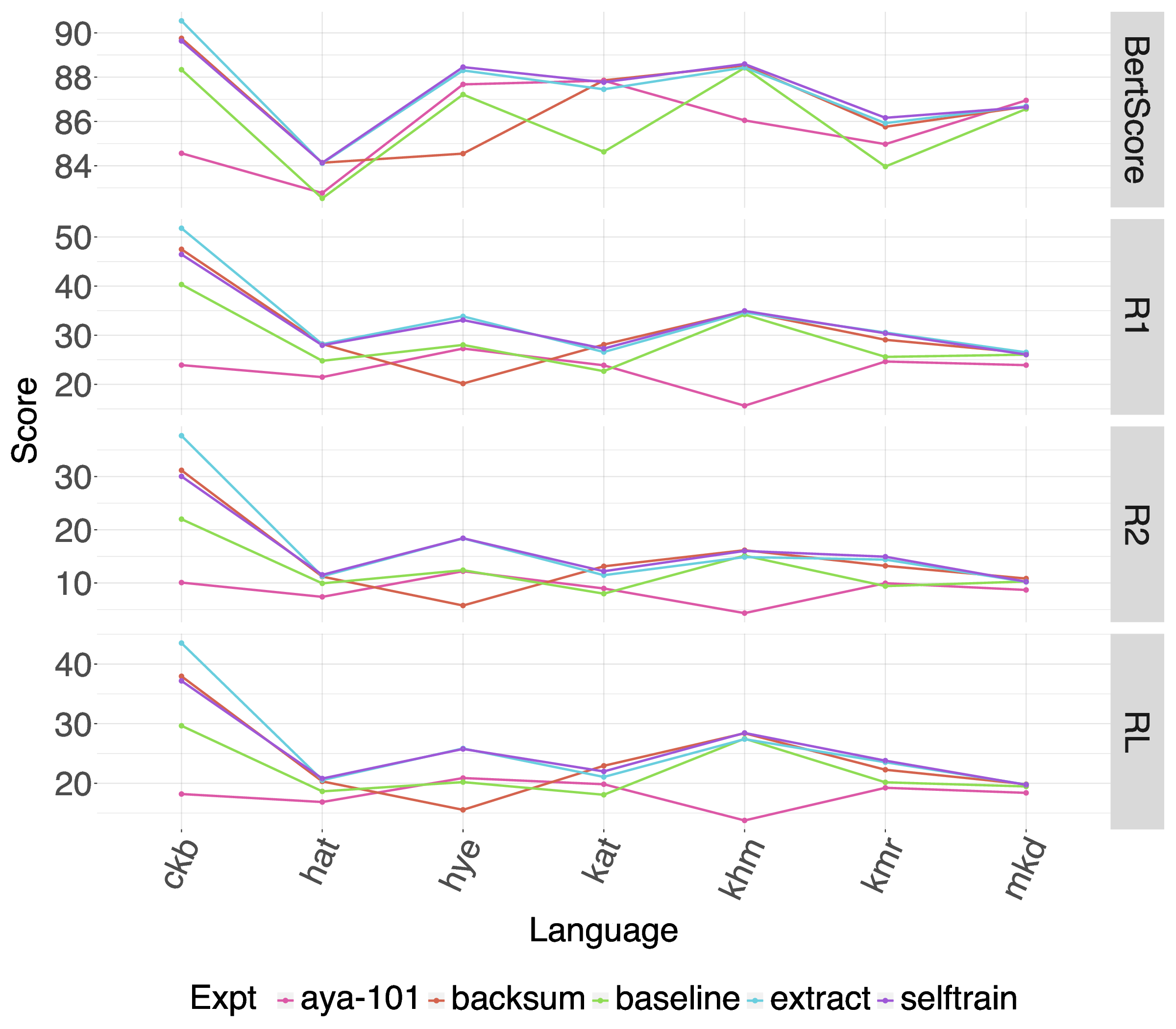
We further explore fine-tuning mT5 with synthetic data generated by leveraging extra Wikipedia data using three different approaches shown in Figure 1. While prior work has focused on comparing multilingual summarization models which take advantage of multilingual transfer with fine-tuning on a single (Palen-Michel and Lignos, 2023;Hasan et al., 2021) or the use of synthetic data for a single language only (Parida and Motlicek, 2019), this work compares the performance of multilingual pretrained models fine-tuned using data for a single language with fine-tuning that uses the combination of synthetic and real data from all languages.
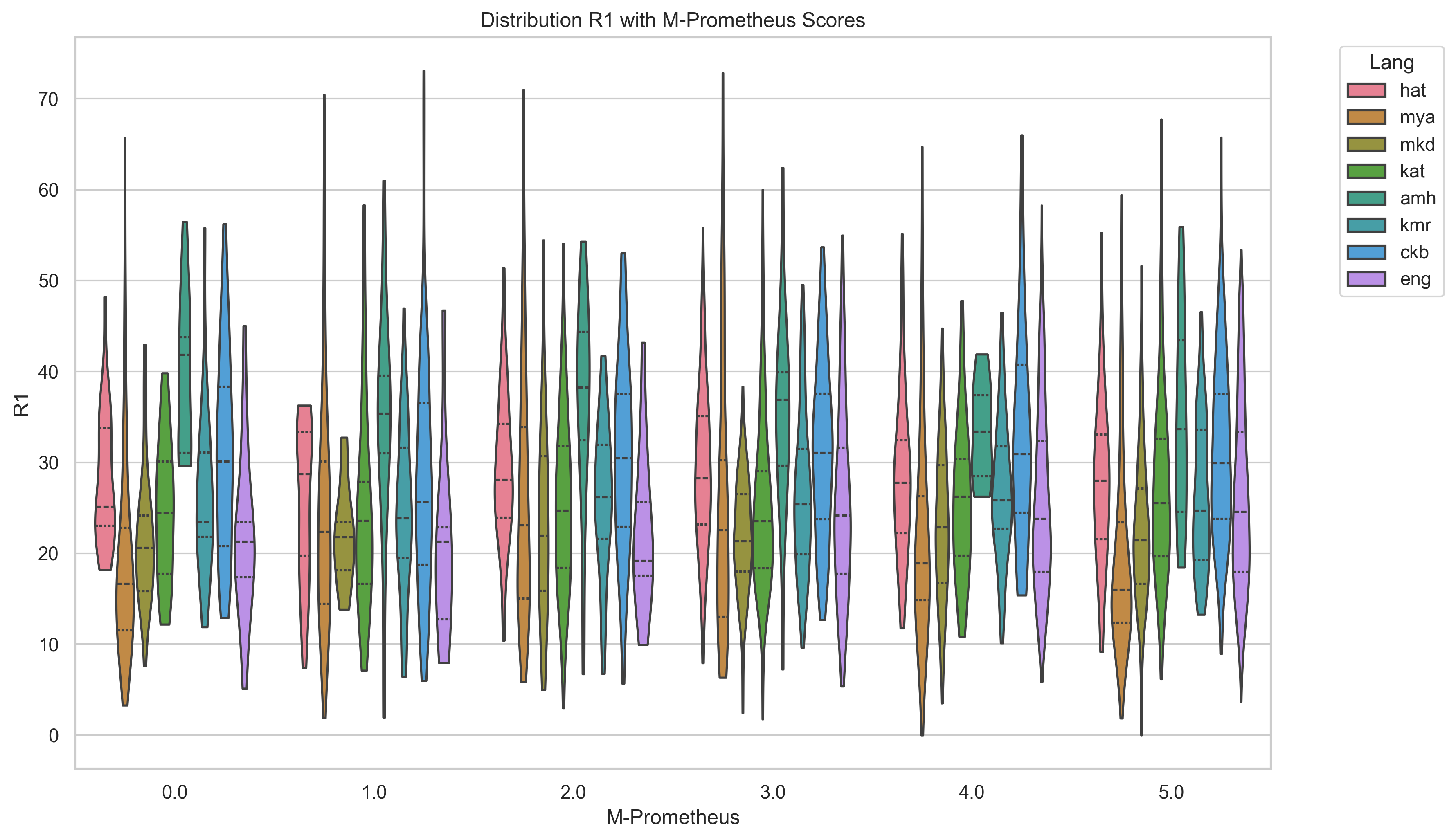
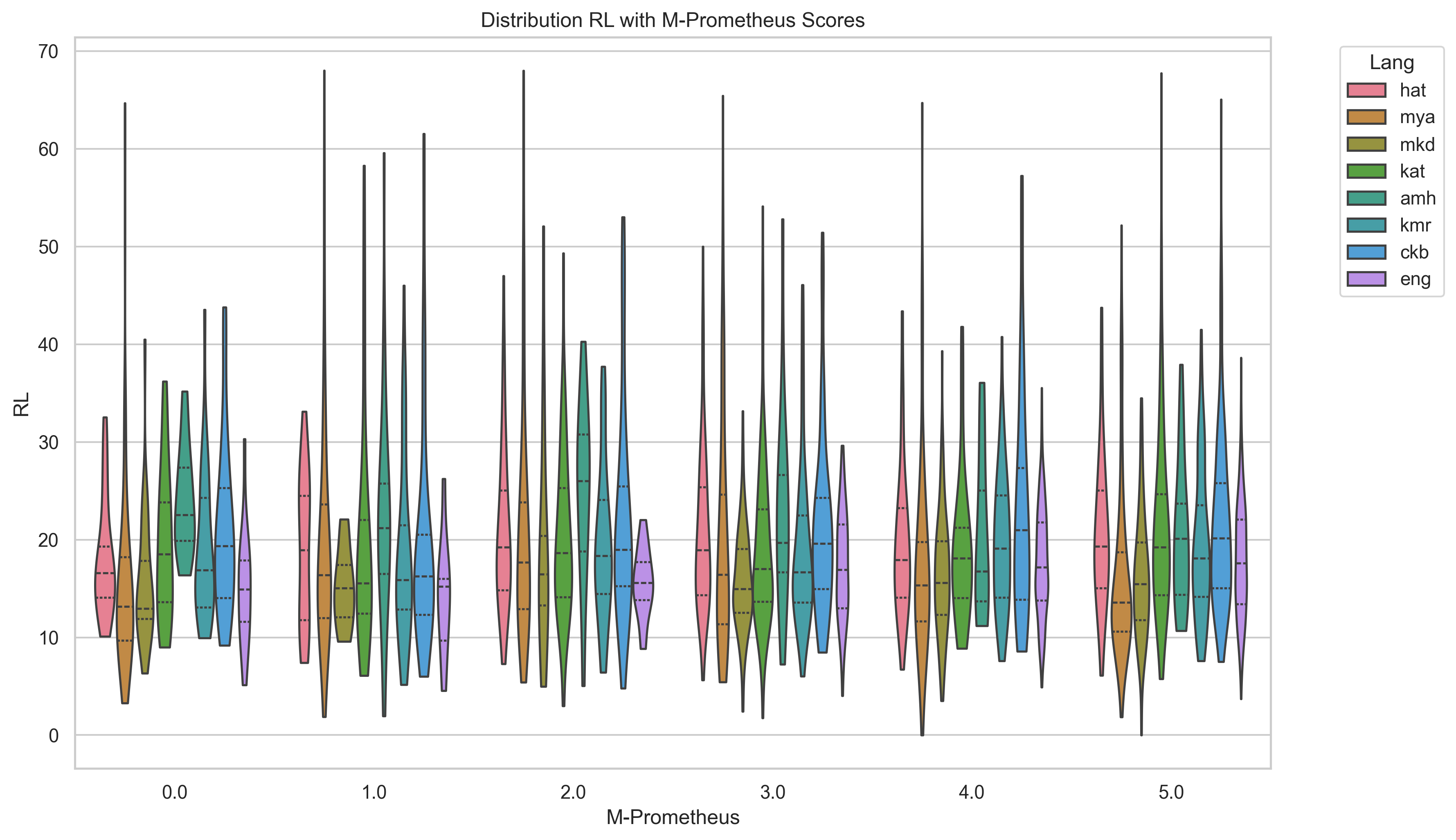
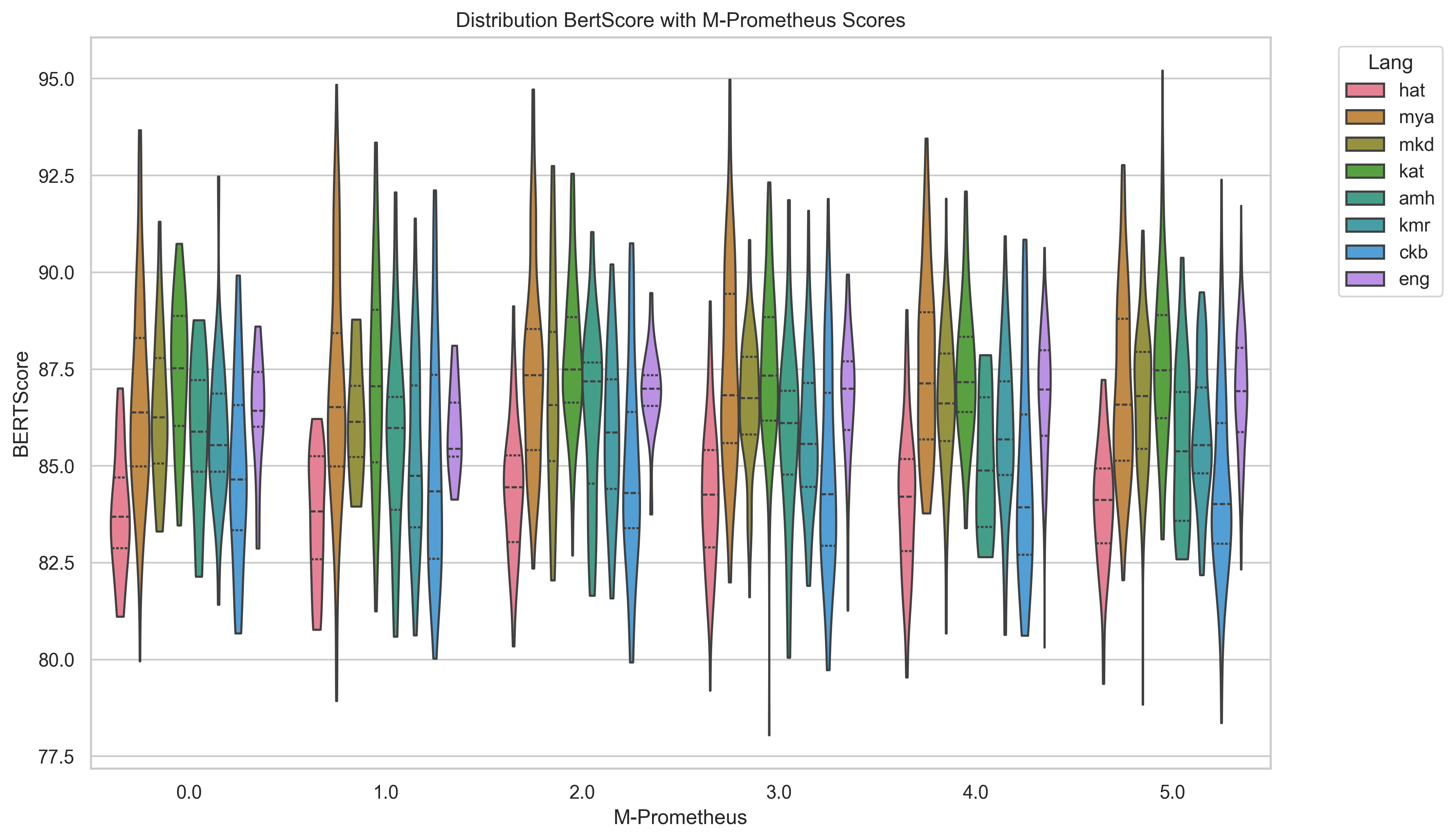
We then conduct additional experiments with three larger LLMs (Gemma-3 27b, Llama-3.3 70b, Aya-Expanse 32b). We also try a pipeline approach with these larger LLMs translating to English, summarizing in English, and translating back to the target language. We primarily evaluate with ROUGE scores and BERTScore, but with increased attention on LLM as judge evaluation (Fu et al., 2024;Kim et al., 2024;Pombal et al., 2025) we also conduct some experiments with M-Prometheus, an open multilingual LLM trained for evaluation.
Our contributions are the following: 1. A comparison of various approaches to summarization in less-resourced languages including: fine-tuning mT5 in a per-individual language and multilingual setting with and without three data augmentation strategies, zero-shot LLM inference with smaller LLMs and comparatively larger LLMs, and a pipeline approach translating from the original language to English then summarizing and translating back to the target language with LLMs.
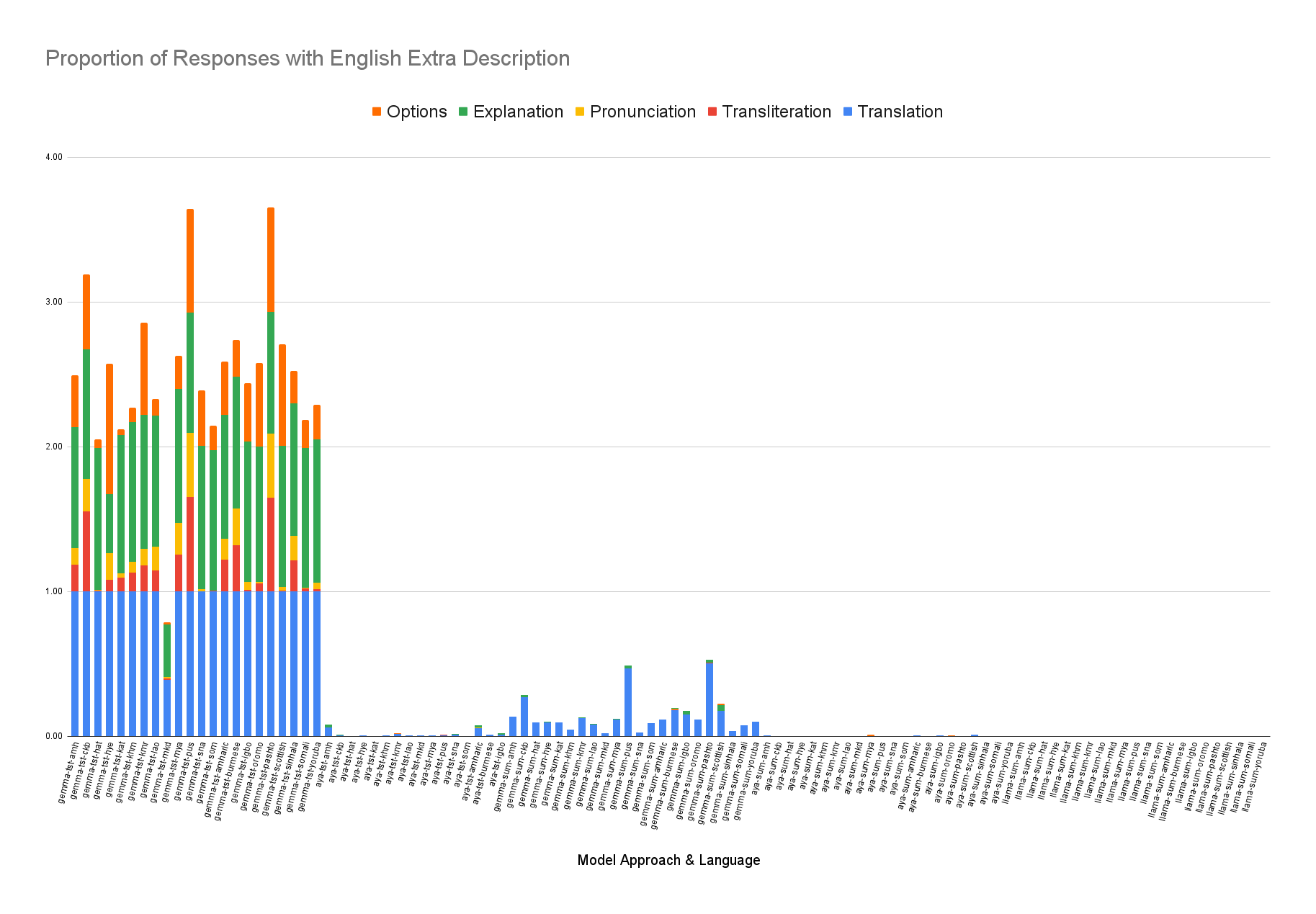
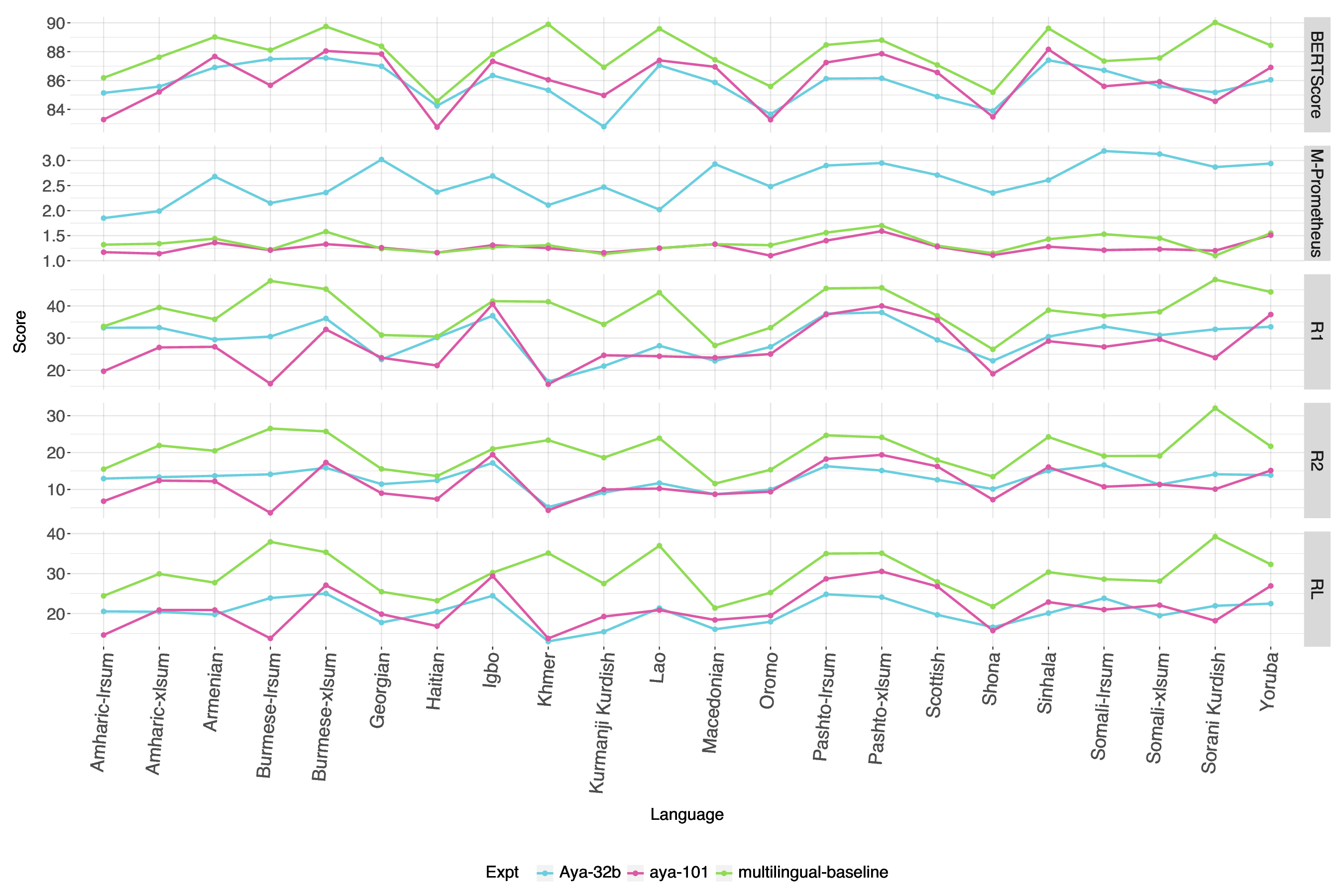
A comparison of popular summarization evaluation approaches including ROUGE-1, ROUGE-2, ROUGE-L, BERTScore, and reference-free LLM as judge using M-Prometheus, which demonstrates different evaluation methods yield somewhat different views of which models perform best.
An analysis of the English content produced by LLMs when producing summaries for lessresourced languages.
We conclude that there is some variation across LLMs in their performance across similar parameter sizes and that zero-shot LLM performance significantly lags the multilingual baseline for most metrics. We also find that data augmentation for individual language fine-tuning for mT5 showed improvement over baselines, but does not outperform fine-tuning mT5 in a multilingual transfer scenario.
Because improved methods for evaluating summarization continue to be developed and explored and because we welcome participatory research (Caselli et al., 2021), where speakers of languages have opportunity to collaborate on the design of NLP tools, upon publication we will release all candidate summaries generated as part of this work for future summarization evaluation work.
The two main approaches to automatic summarization have been extractive and abstractive methods. Extractive models select important sentences in the source article to use as summaries (Luhn, 1958;Radev et al., 2001;Christian et al., 2016). Abstractive models typically cast the problem as a sequence-to-sequence problem and apply a neural language model (Rush et al., 2015;See et al., 2017;Hsu et al., 2018;Zhang et al., 2020a). Abstractive neural models typically require larger amounts of training data to train.
Prior work on multilingual summarization has largely focused on newswire text from higher resourced languages or covers more languages but with very limited data (Scialom et al., 2020;Giannakopoulos et al., 2015Giannakopoulos et al., , 2017)). Some of the languages
This content is AI-processed based on open access ArXiv data.