General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a largescale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation. Project
The pursuit of general-purpose robotic systems capable of operating autonomously in unstructured, openworld environments represents a fundamental challenge in artificial intelligence [1], [2], [3], [4], [5]. This endeavor necessitates simultaneous achievement of two critical, yet often competing objectives: achieving broad generalization across diverse, unseen scenarios [6], [7] while maintaining high-precision action execution for reliable task completion [8], [9], [10]. Recent advances in Large Vision-Language Models (VLMs), pre-trained on extensive internet-scale datasets, have established a new research direction by enabling the integration of rich * Equal contribution † Project leader ‡ Corresponding author semantic knowledge derived from diverse multimodal data, thereby significantly enhancing generalization capabilities for downstream tasks. These advances have led to Vision-Language-Action (VLA) models that extend VLMs' reasoning capability to directly predict robotic actions, unifying perception, reasoning, and control, establishing a principled bridge between abstract semantic reasoning and concrete low-level physical execution [4], [6], [5], [11], [3], [12], [1], [2], [13], [7], [14], [15], [16], [17], [18].
We posit that robust embodied reasoning is an indispensable prerequisite for achieving broad generalization in unstructured, dynamically evolving environments. This capability encompasses the synthesis of spatial awareness, temporal dynamics, and causal logic to explicitly plan, monitor, and adaptively correct physical actions. Without sufficient reasoning capabilities, learned policies are prone to falling back on superficial shortcuts derived from visual-action correlations, leading to brittle performance under distribution shifts, novel object configurations, or unexpected environmental perturbations [19], [11], [20]. However, possessing strong embodied reasoning capabilities, while necessary, is fundamentally insufficient in isolation; achieving reliable task completion in real-world scenarios equally demands high-precision action execution-the ability to generate exact, fine-grained control signals that faithfully translate abstract reasoning into precise physical movements. While VLA models in principle offer a unified framework capable of both precise robotic control and advanced reasoning, empirical observations suggest a persistent tension: models optimized for strong reasoning capabilities tend to exhibit reduced action precision, while those achieving high-fidelity execution often demonstrate limited generalization [20], [12]. This limitation hinders current VLA systems from achieving robust, real-world performance where both capabilities are essential [6].
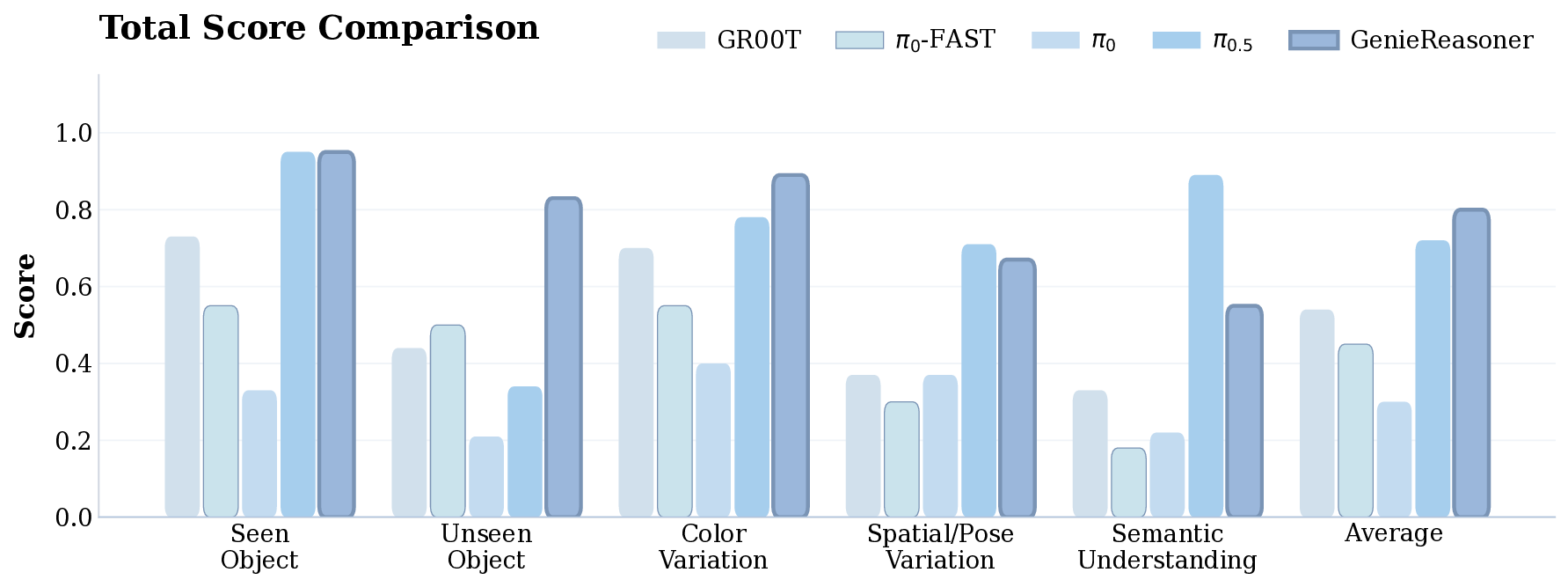
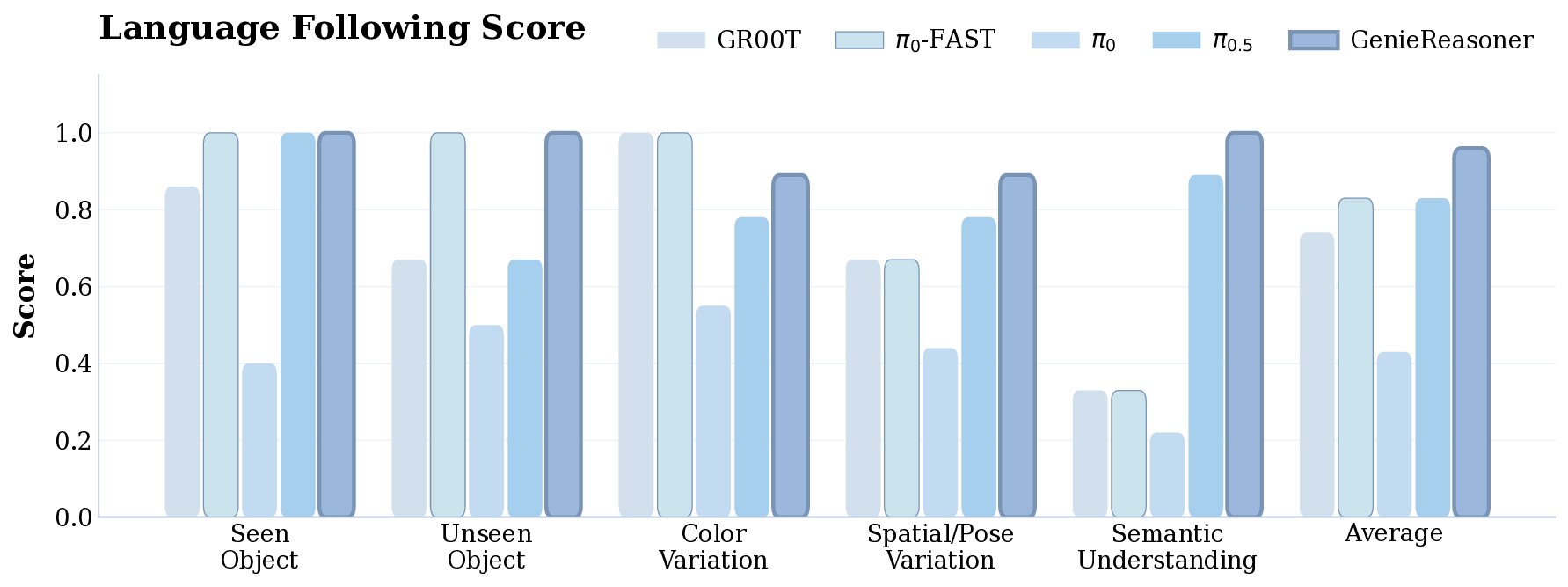
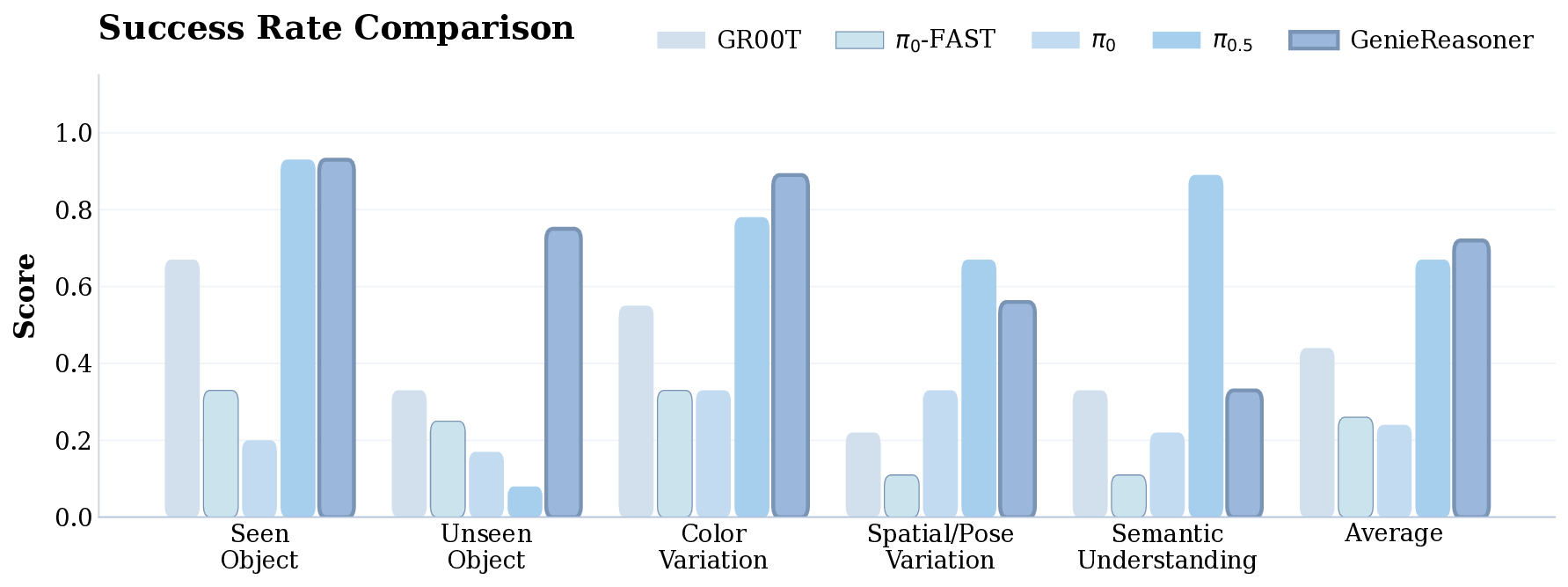
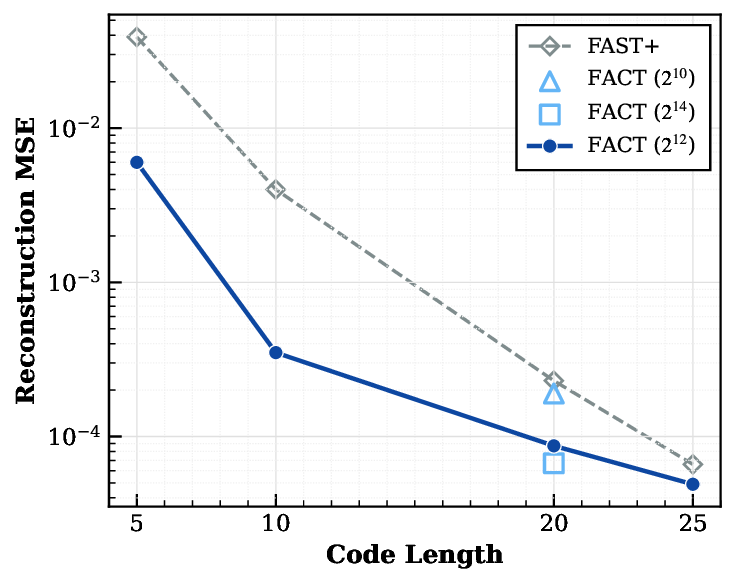
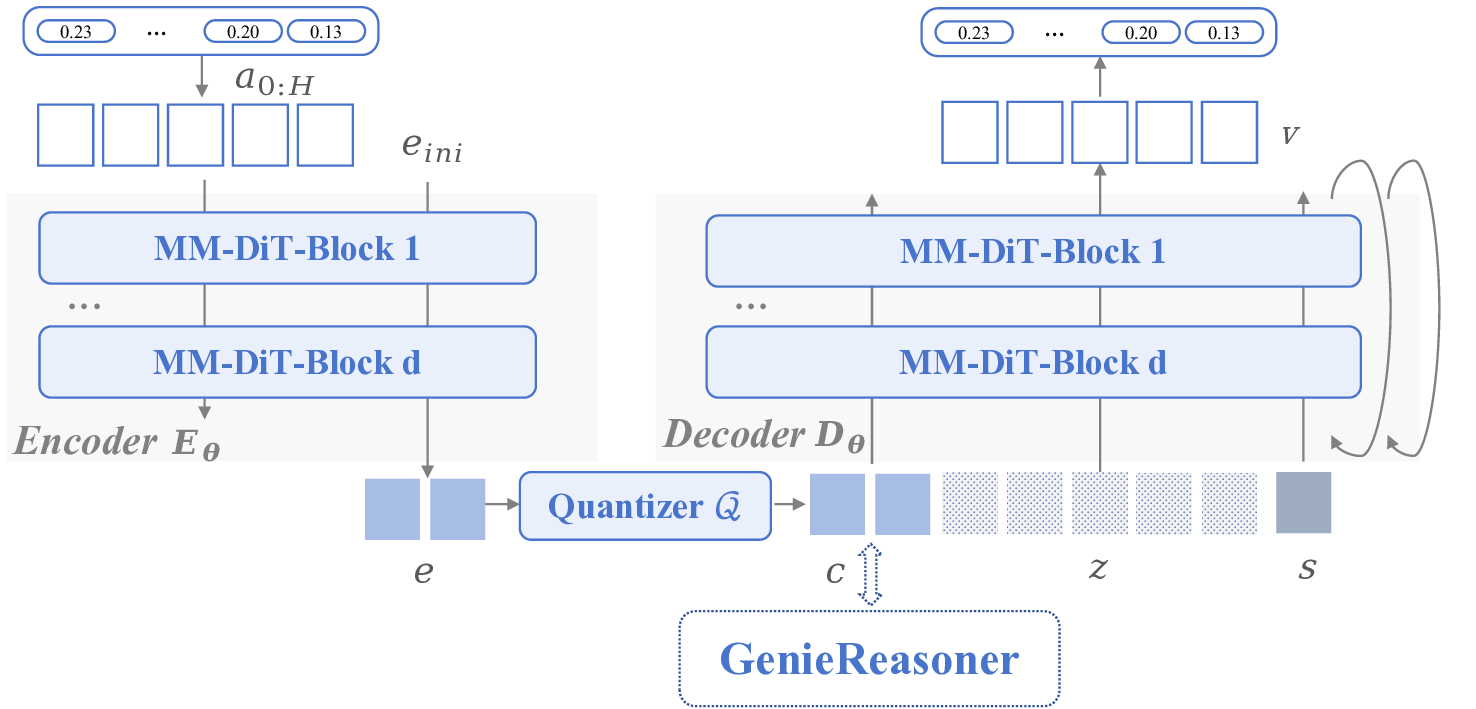
To address these issues and provide a principled diagnostic framework, we introduce the Embodied Reason-Fig. 1: We introduce the GenieReasoner system. (Left) Our system leverages large-scale general and embodied multimodal data to co-optimize high-level reasoning and low-level control within a unified autoregressive transformer. (Center) To bridge the gap between discrete planning and continuous execution, we introduce FACT, a novel action tokenizer that utilizes flow matching to reconstruct high-fidelity trajectories from quantized tokens. (Right) This unified design yields state-of-the-art results: GenieReasoner achieves a 41% accuracy improvement on our proposed ERIQ for embodied reasoning and demonstrates significantly lower reconstruction error (MSE) compared to π 0 -FAST. Consequently, our model outperforms flow-based baselines (e.g., π 0.5 ) in real-world robot manipulation tasks.
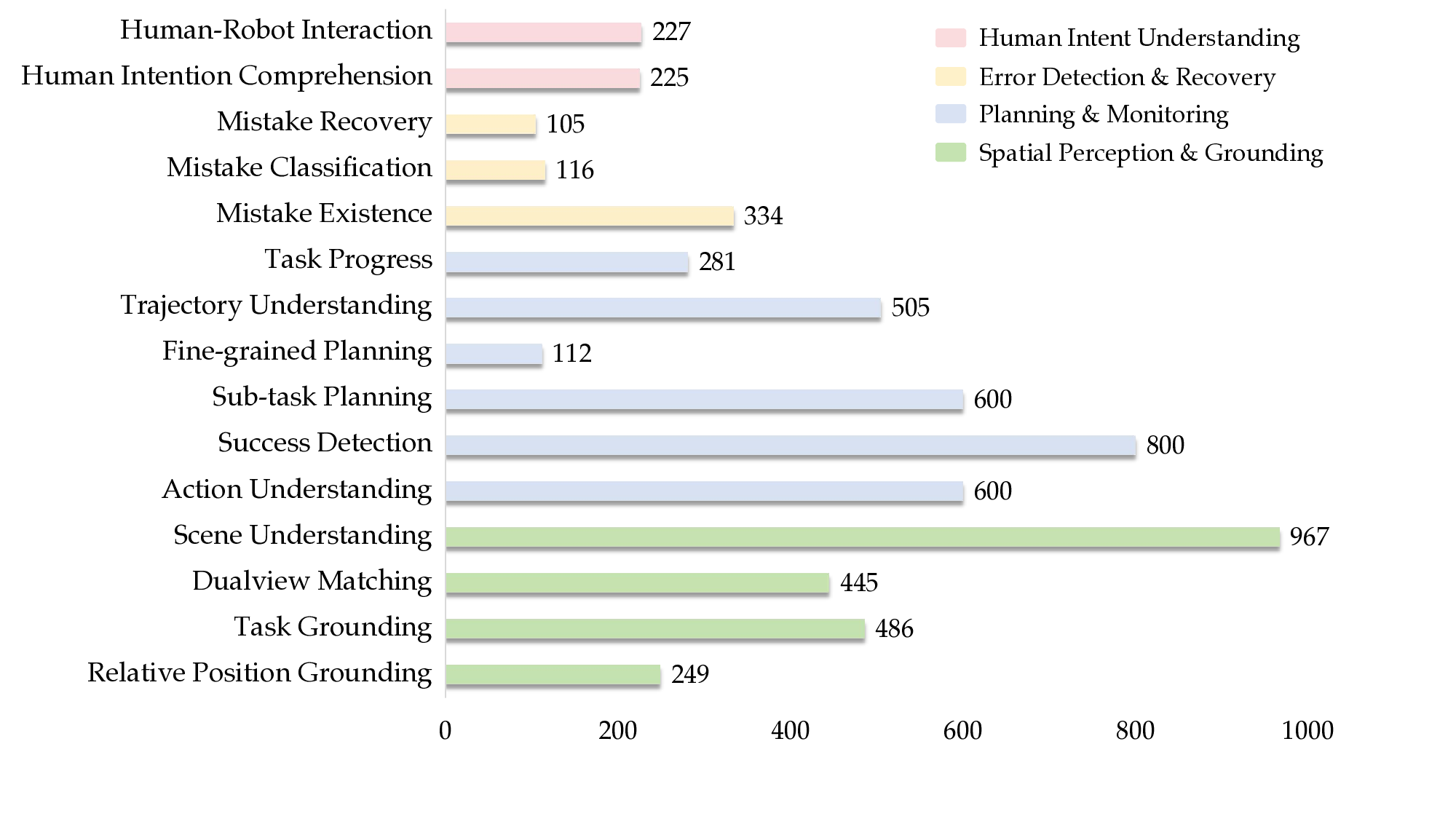
ing Intelligence Quotient (ERIQ), a large-scale benchmark for embodied reasoning in robotic manipulation. ERIQ decouples cognitive reasoning from motor control, enabling independent quantification of embodied reasoning without confounding action execution errors. ERIQ comprises 6K+ embodied question-answer pairs across four key reasoning dimensions. This scale enables comprehensive evaluation of reasoning capabilities, and provides a rich source of diverse reasoning scenarios for systematic analysis of the reasoning-generalization relationship. Empirical analysis on ERIQ reveals a strong positive correlation between VLM reasoning capabilities and end-to-end VLA generalization performance (detailed in Section V), suggesting that reasoning capabilities significantly influence generalization.
Achieving high-precision action execution requires bridging discrete semantic representations from language-centric reasoning tokens with continuous control signals for physical execution. One class of methods discretizes continuous robotic actions to enable co-training with VLM tokens. This approach faces a precision-efficiency trade-off: simple uniform binning necessitates an prohibitive number of tokens to achieve fine-grained control, consuming valuable context space [2], [3]; learned quantization (e.g., VQ-VAE [21], [22]) offers compact codes but lack
This content is AI-processed based on open access ArXiv data.