Title: Skim-Aware Contrastive Learning for Efficient Document Representation
ArXiv ID: 2512.24373
Date: 2025-12-30
Authors: Waheed Ahmed Abro, Zied Bouraoui
📝 Abstract
Although transformer-based models have shown strong performance in word-and sentence-level tasks, effectively representing long documents, especially in fields like law and medicine, remains difficult. Sparse attention mechanisms can handle longer inputs, but are resource-intensive and often fail to capture full-document context. Hierarchical transformer models offer better efficiency but do not clearly explain how they relate different sections of a document. In contrast, humans often skim texts, focusing on important sections to understand the overall message. Drawing from this human strategy, we introduce a new selfsupervised contrastive learning framework that enhances long document representation. Our method randomly masks a section of the document and uses a natural language inference (NLI)-based contrastive objective to align it with relevant parts while distancing it from unrelated ones. This mimics how humans synthesize information, resulting in representations that are both richer and more computationally efficient. Experiments on legal and biomedical texts confirm significant gains in both accuracy and efficiency.
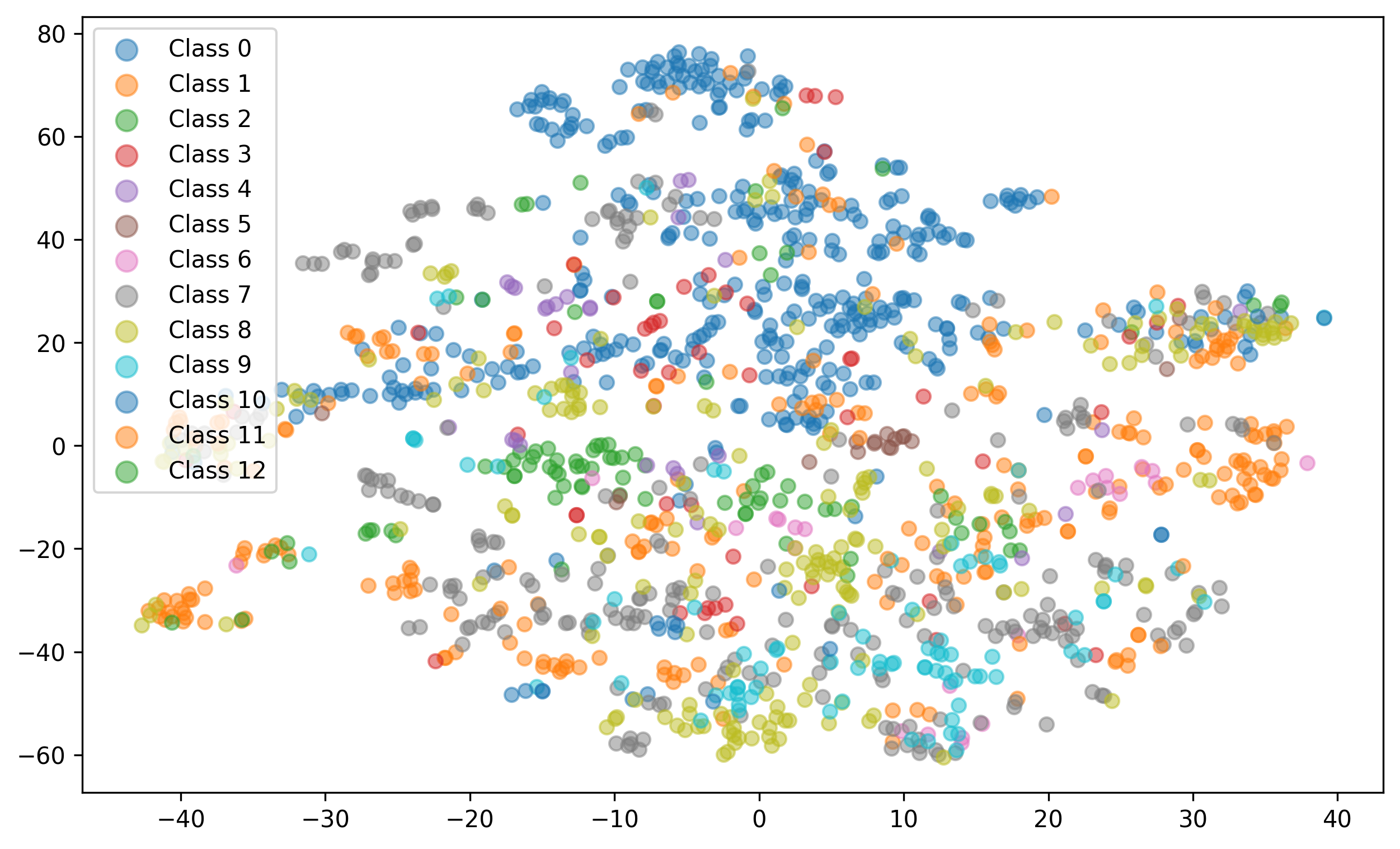
💡 Deep Analysis
📄 Full Content
Skim-Aware Contrastive Learning for Efficient Document Representation
Waheed Ahmed Abro
CDEP - UR 2471, Univ Artois, France
wahmed.abro@univ-artois.fr
Zied Bouraoui
CRIL - CNRS, Univ Artois, France
zied.bouraoui@cril.fr
Abstract
Although transformer-based models have
shown strong performance in word- and
sentence-level tasks, effectively representing
long documents, especially in fields like law
and medicine, remains difficult. Sparse atten-
tion mechanisms can handle longer inputs, but
are resource-intensive and often fail to cap-
ture full-document context. Hierarchical trans-
former models offer better efficiency but do not
clearly explain how they relate different sec-
tions of a document. In contrast, humans often
skim texts, focusing on important sections to
understand the overall message. Drawing from
this human strategy, we introduce a new self-
supervised contrastive learning framework that
enhances long document representation. Our
method randomly masks a section of the doc-
ument and uses a natural language inference
(NLI)-based contrastive objective to align it
with relevant parts while distancing it from un-
related ones. This mimics how humans synthe-
size information, resulting in representations
that are both richer and more computationally
efficient. Experiments on legal and biomedical
texts confirm significant gains in both accuracy
and efficiency.
1
Introduction
Since the introduction of Language Models (LMs),
the focus in NLP has been on fine-tuning large
pre-trained language models, especially for solv-
ing sentence and paragraph-level tasks. However,
accurately learning document embeddings contin-
ues to be an important challenge for several appli-
cations, such as document classification (Saggau
et al., 2023), ranking (Ginzburg et al., 2021; Izac-
ard et al., 2021), retrieval-augmented generation
(RAG) systems that demand efficient document
representation encoders (Zhang et al., 2024; Zhao
et al., 2025) and legal and medical applications like
judgment prediction (Chalkidis et al., 2019; Feng
et al., 2022), legal information retrieval (Sansone
and Sperlí, 2022), and biomedical document classi-
fication (Johnson et al., 2016; Wang et al., 2023).
Learning high-quality document representations
is a challenging task due to the difficulty in develop-
ing efficient encoders with reasonable complexity.
Most document encoders use sentence encoders
based on self-attention architectures such as BERT
(Devlin et al., 2019). However, it is not feasible to
have inputs that are too long as self-attention scales
quadratically with the input length. To process
long inputs efficiently, architectures such as Lin-
former (Wang et al., 2020), Big Bird (Zaheer et al.,
2020a), Longformer (Beltagy et al., 2020a) and
Hierarchical Transformers (Chalkidis et al., 2022a)
have been developed. Unlike quadratic scaling in
traditional attention mechanisms, these architec-
tures utilize sparse attention mechanisms or hierar-
chical attention mechanisms that scale linearly. As
such, they can process 4096 input tokens, which is
enough to embed most types of documents, includ-
ing legal and medical documents, among others.
While methods based on sparse attention net-
works offer a solution for complexity, the length
of the document remains a problem for building
faithful representations for downstream applica-
tions such as legal and medical domains. First,
fine-tuning these models for downstream tasks is
computationally intensive. Second, capturing the
meaning of the whole document remains too com-
plex. In particular, it is unclear how or to what
extent inner-dependencies between text fragments
are considered. This is because longer documents
contain more information than shorter documents,
making it difficult to capture all the relevant infor-
mation within a fixed-size representation. Addi-
tionally, documents usually cover different parts,
making the encoding process complex and may
lead to collapsed representations. This is particu-
larly true for legal and medical documents, as they
contain specialized terminology and text segments
that describe a series of interrelated facts.
1
arXiv:2512.24373v1 [cs.CL] 30 Dec 2025
When domain experts, such as legal or medi-
cal professionals, read through documents, they
skillfully skim the text, honing in on some text
fragments that, when pieced together, provide an
understanding of the content. Inspired by this in-
tuitive process, our work focuses on developing
document encoders capable of generating high-
quality embeddings for long documents. These
encoders mimic the expert ability to distill relevant
text chunks, enabling them to excel in downstream
tasks right out of the box, without the need for
fine-tuning. We propose a novel framework for
self-supervised contrastive learning that focuses on
long legal and medical documents. Our approach
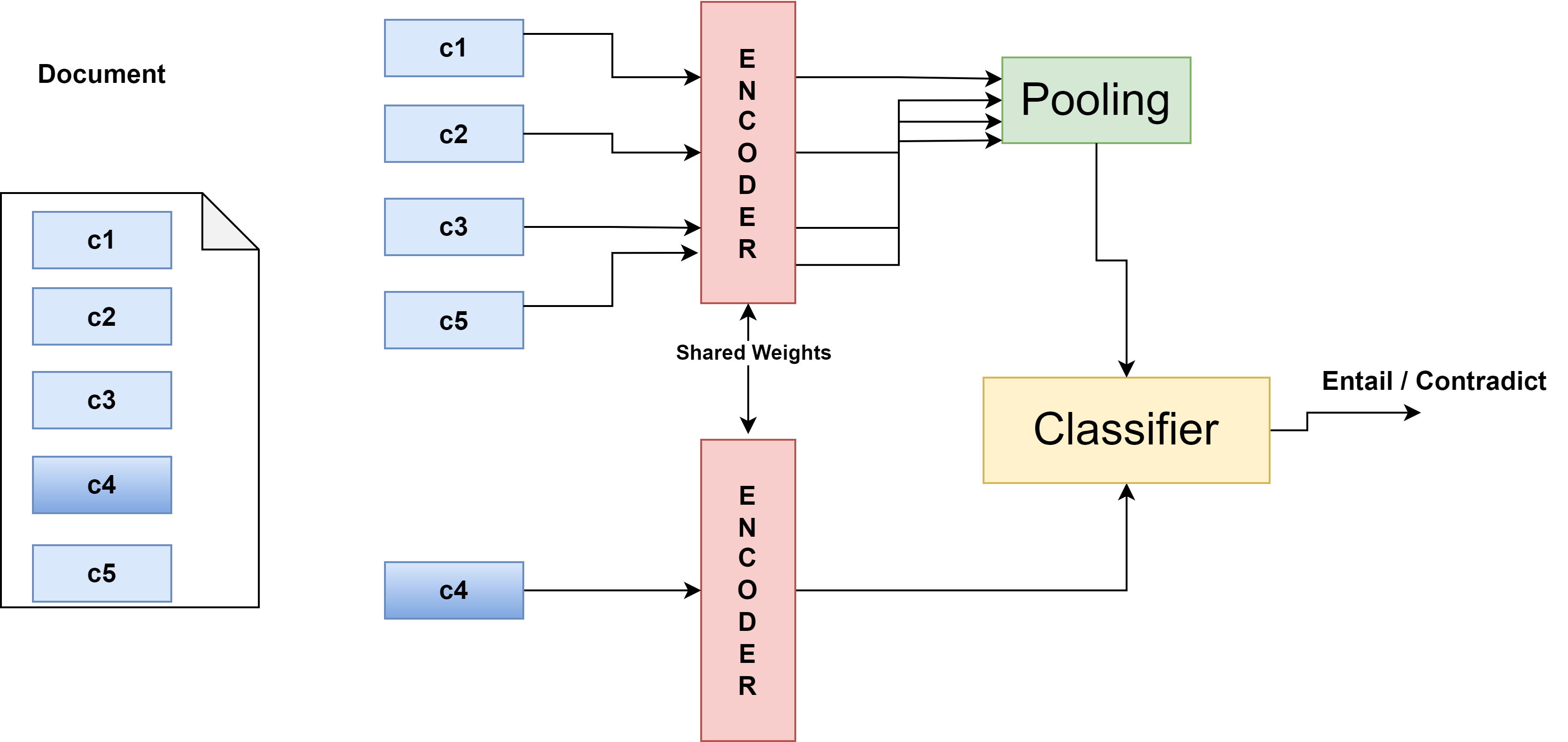
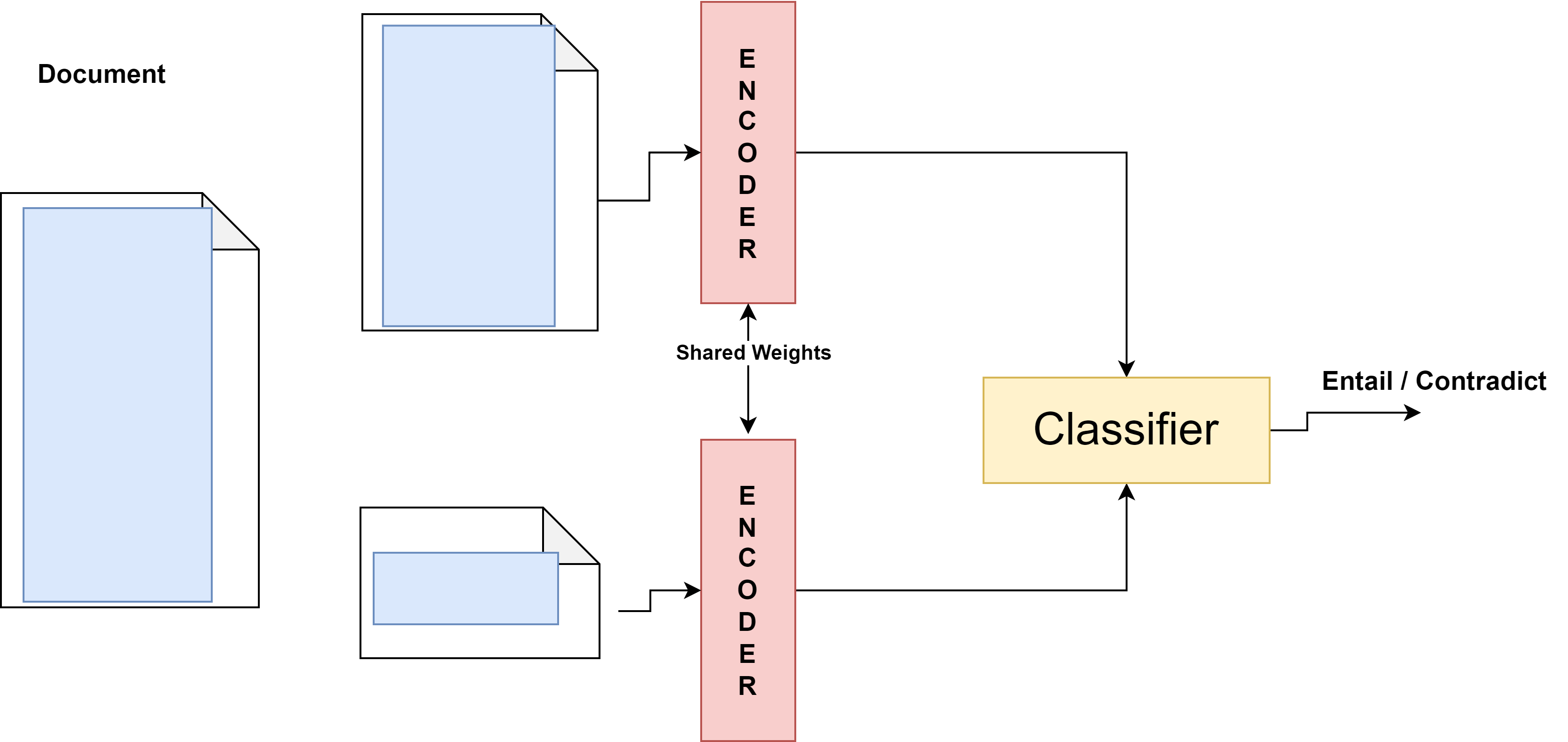
features a self-supervised Chunk Prediction En-
coder (CPE) designed to tackle the challenge of
learning document representations w