Large language models (LLMs) employ a step-by-step reasoning process expressed as a chain of thought (CoT) (Wei 1 Hong Kong University of Science and Technology (Guangzhou) 2 University of Alberta. Correspondence to: Sijia Chen
.Preprint. January 1, 2026. et al., 2022) to solve complex problems. Guiding thought generation with explicit plans (Yao et al., 2022), which are step-wise and question-specific reasoning instructions, is crucial for improving practical usage and reliability of LLMs (Huang et al., 2024;2022). However, preparing such plans effectively for accurate reasoning is inherently challenging (Valmeekam et al., 2023;2024), particularly given the high diversity of problems across different tasks.
One preliminary approach to achieving this goal involves prompting LLMs to generate explicit plans using their internal knowledge (Yao et al., 2022;Wang et al., 2023a;Sun et al., 2023). However, this method is limited by errors in the plans, which arise from the inevitable hallucinations of LLMs. While leveraging external knowledge bases can help mitigate these errors (Lyu et al., 2024;Zhu et al., 2024), accessing useful information from them is time-consuming, and many tasks lack effective knowledge bases altogether. More promising recent efforts (Yao et al., 2022;Jiao et al., 2024;Qiao et al., 2024b;Brahman et al., 2024) focus on finetuning LLMs on automatically or manually synthesized samples with explicit plans. Unfortunately, LLMs fine-tuned in this manner still struggle to achieve better performance because the plans required by problems within a single task, as well as across tasks, are vast in number and highly diverse.
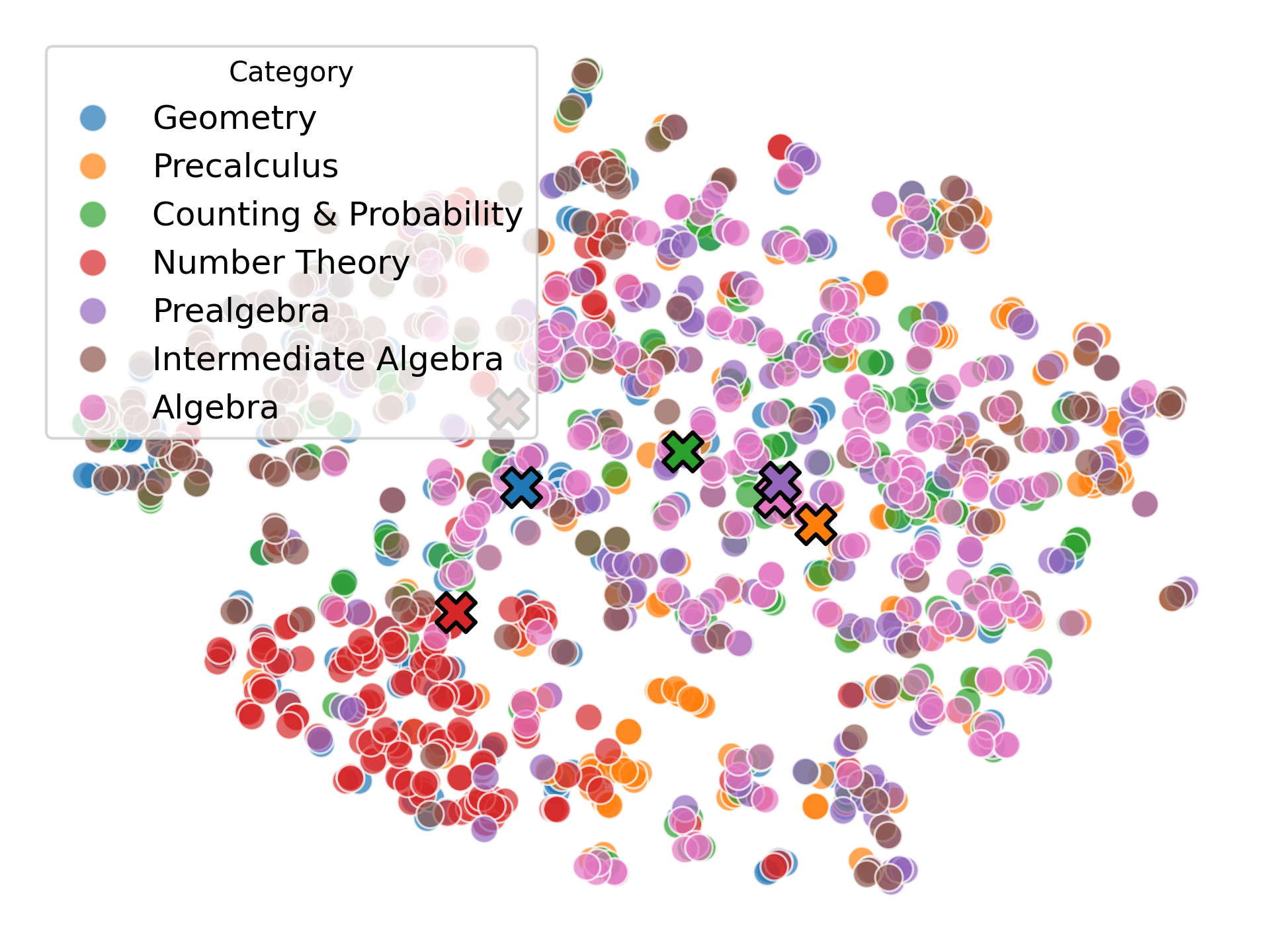
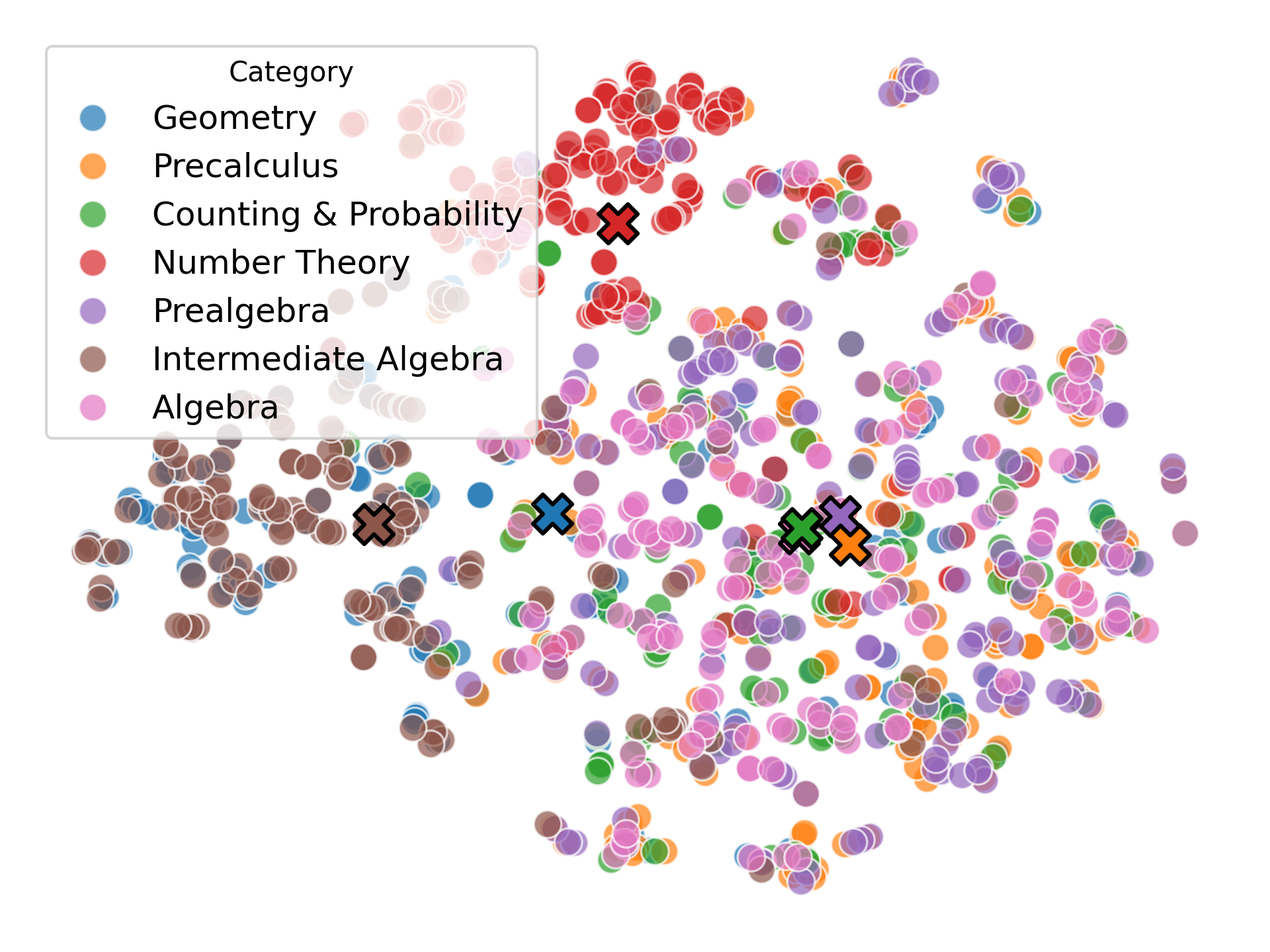
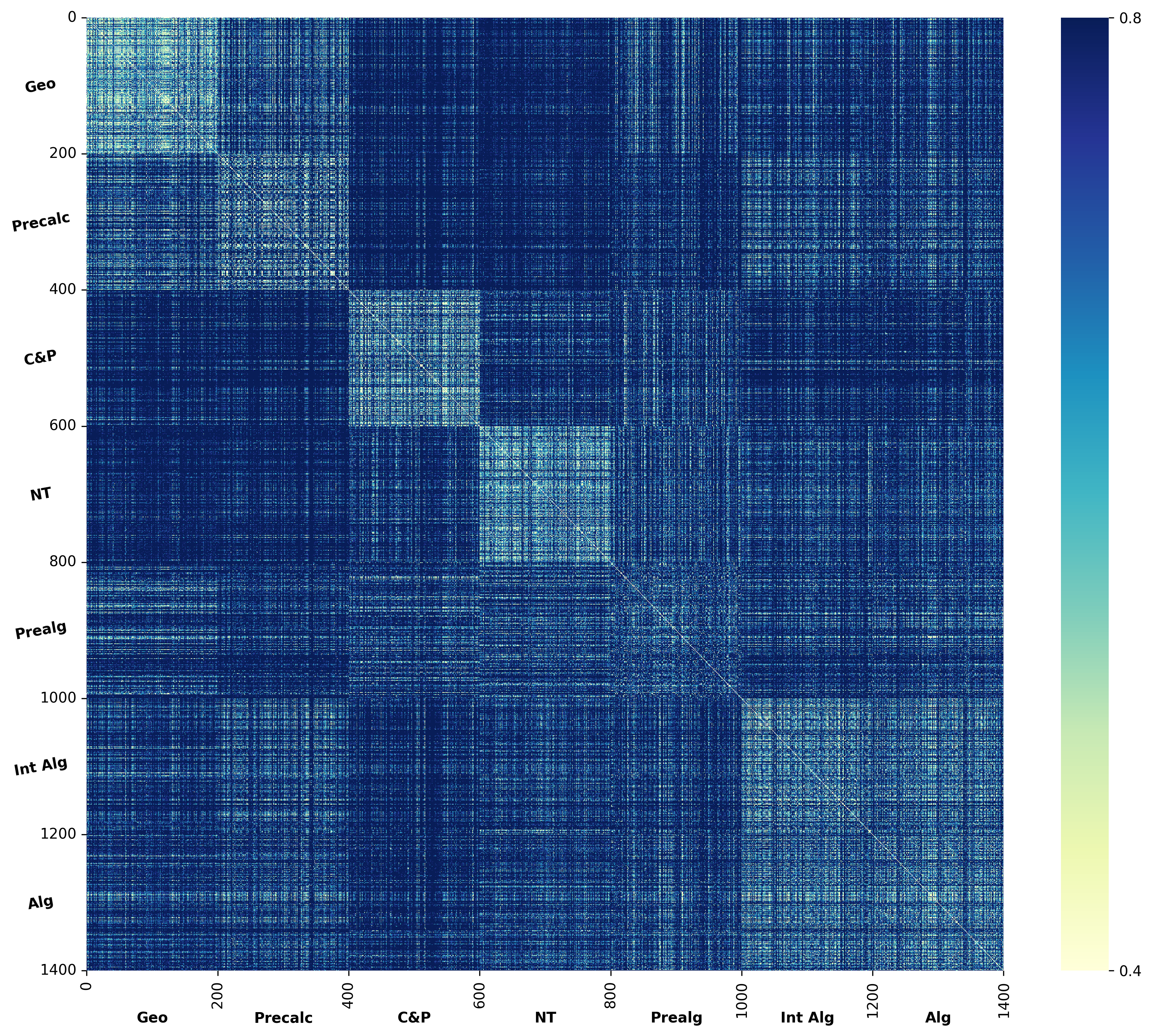
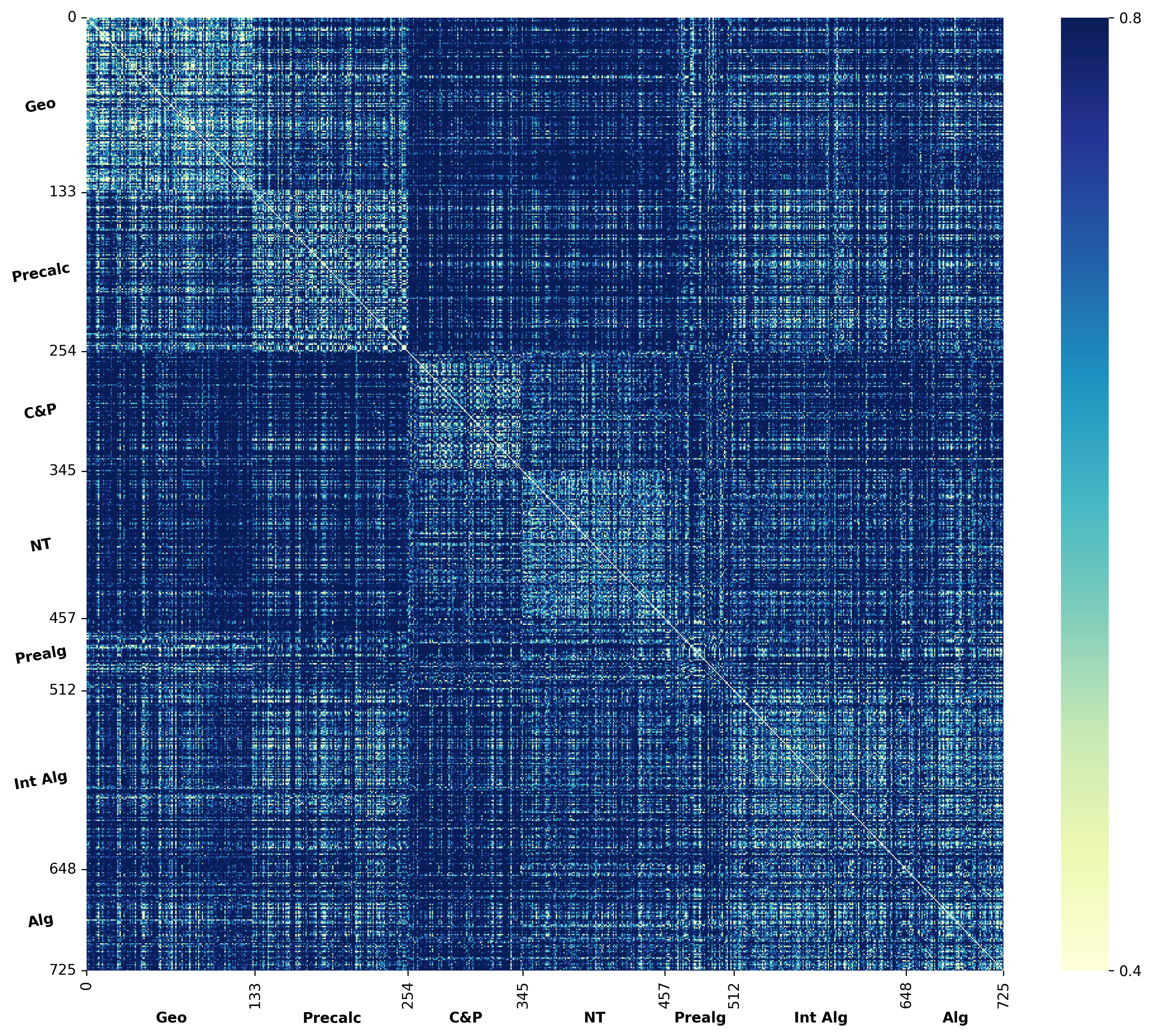
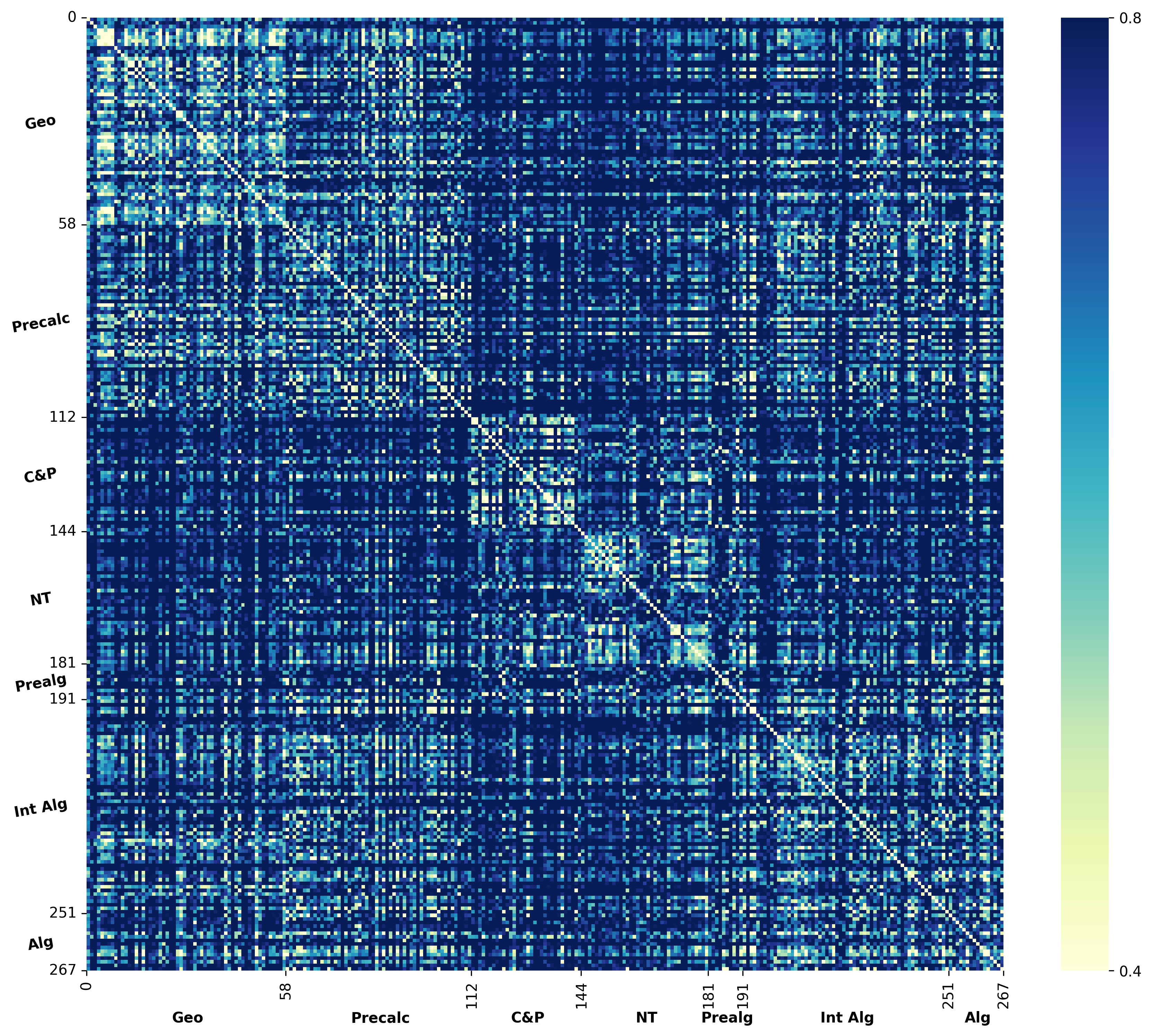
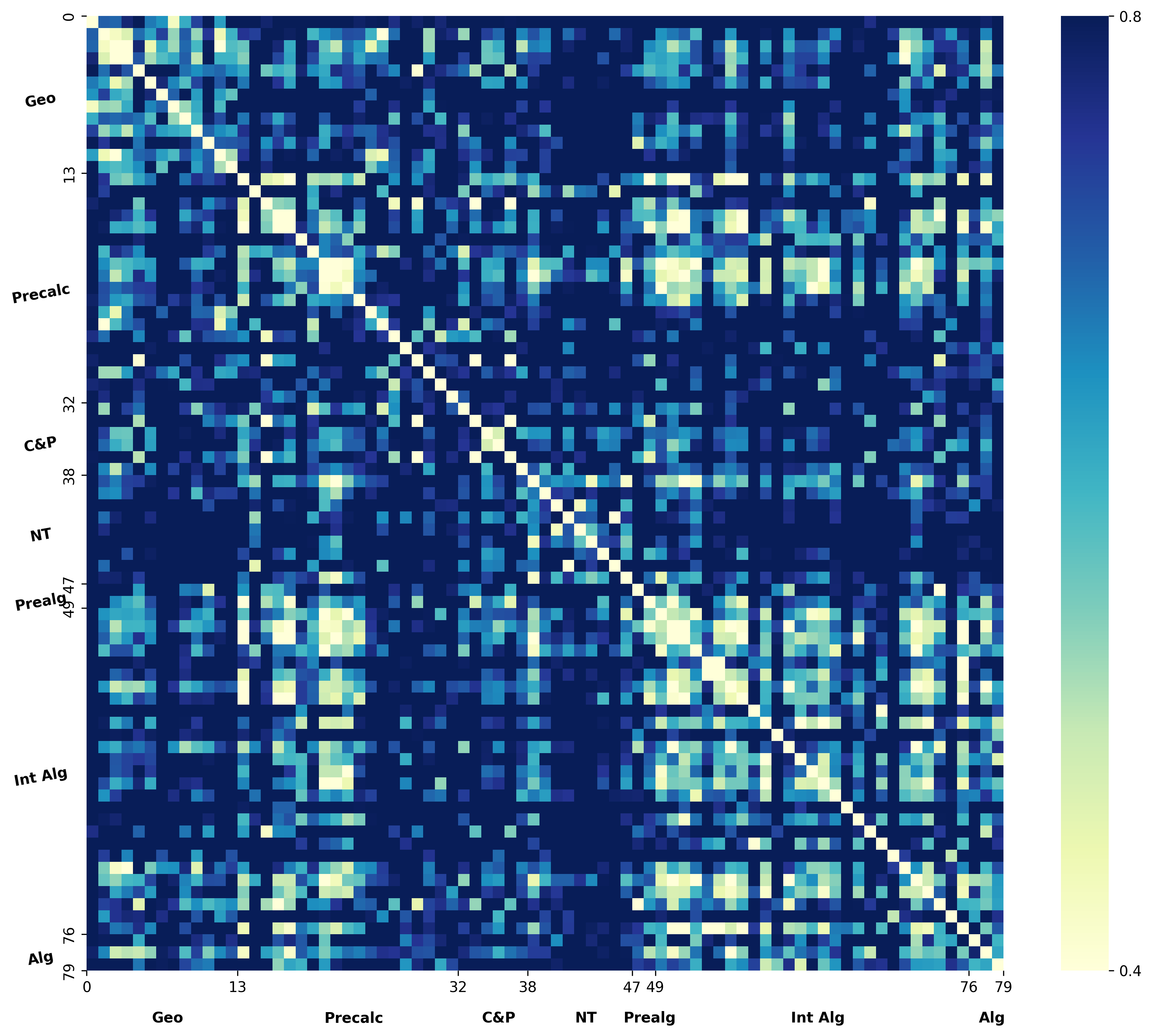
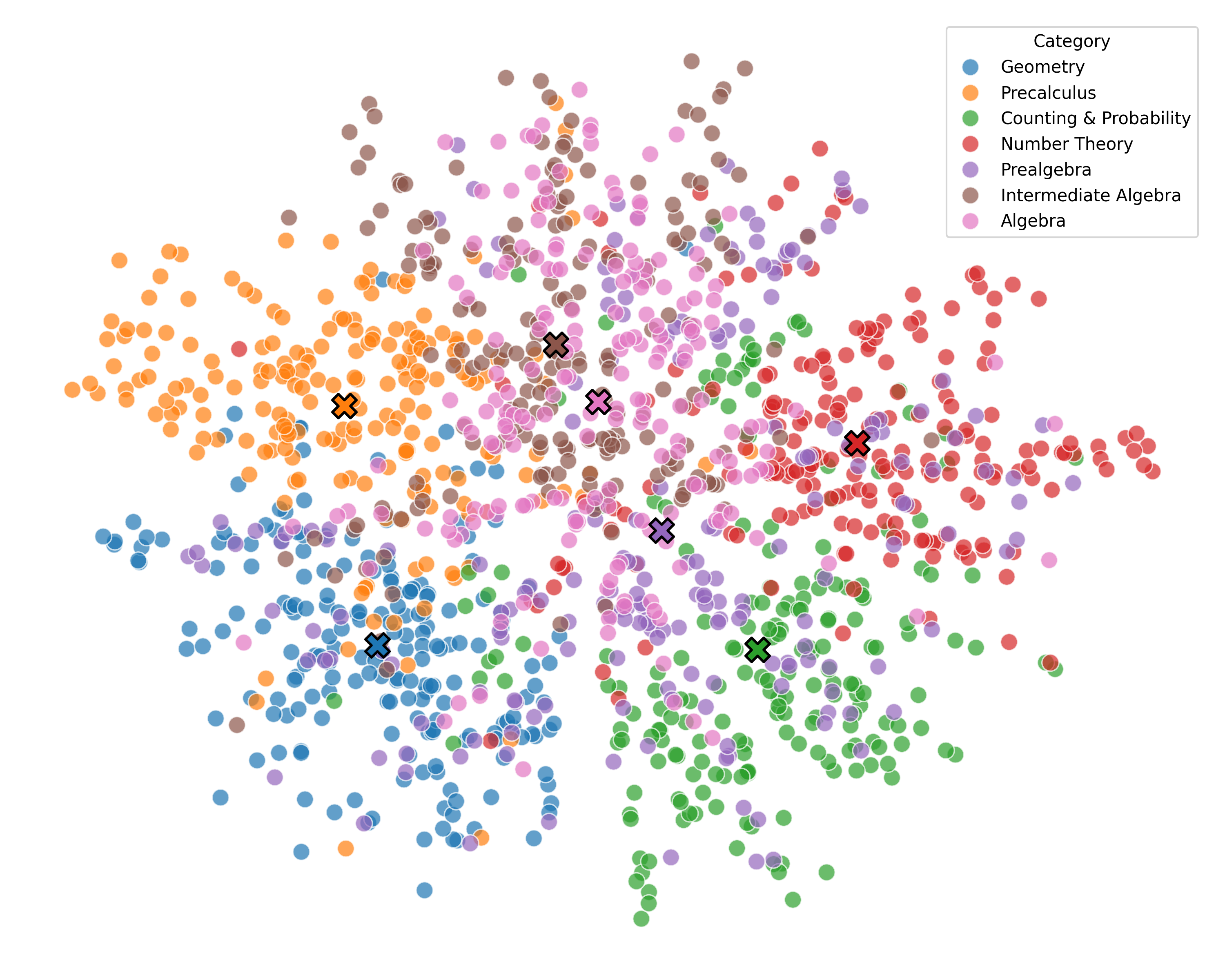
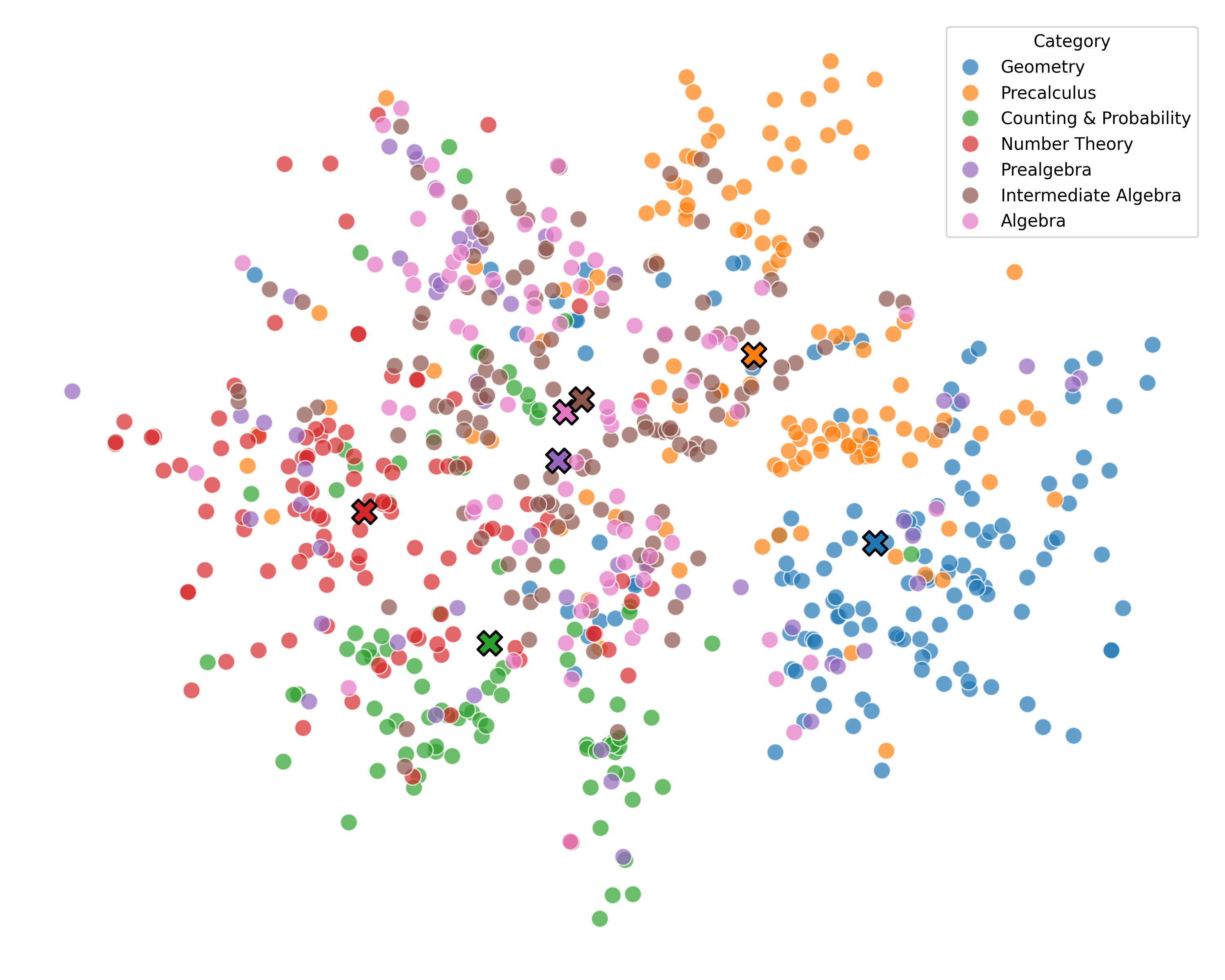
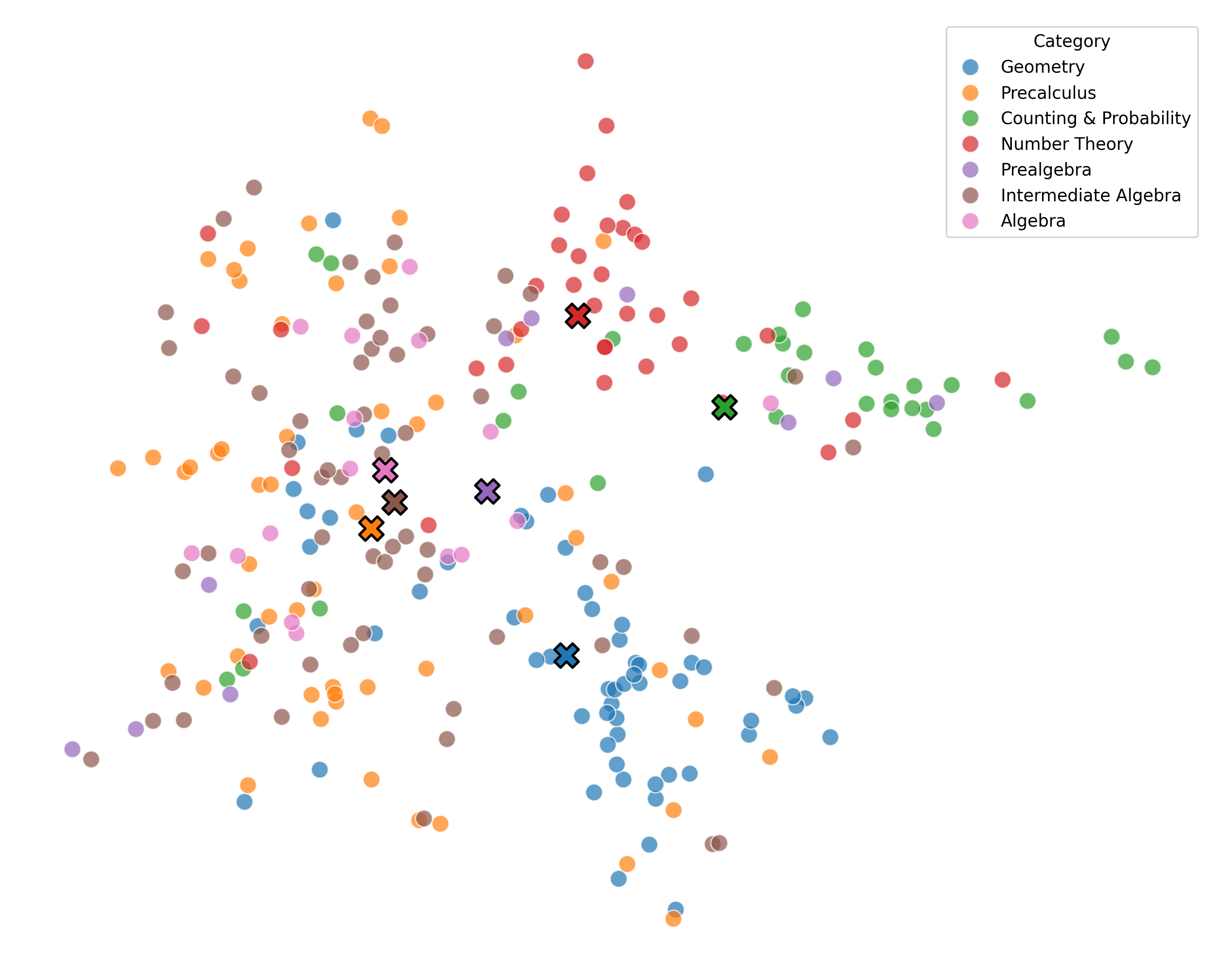
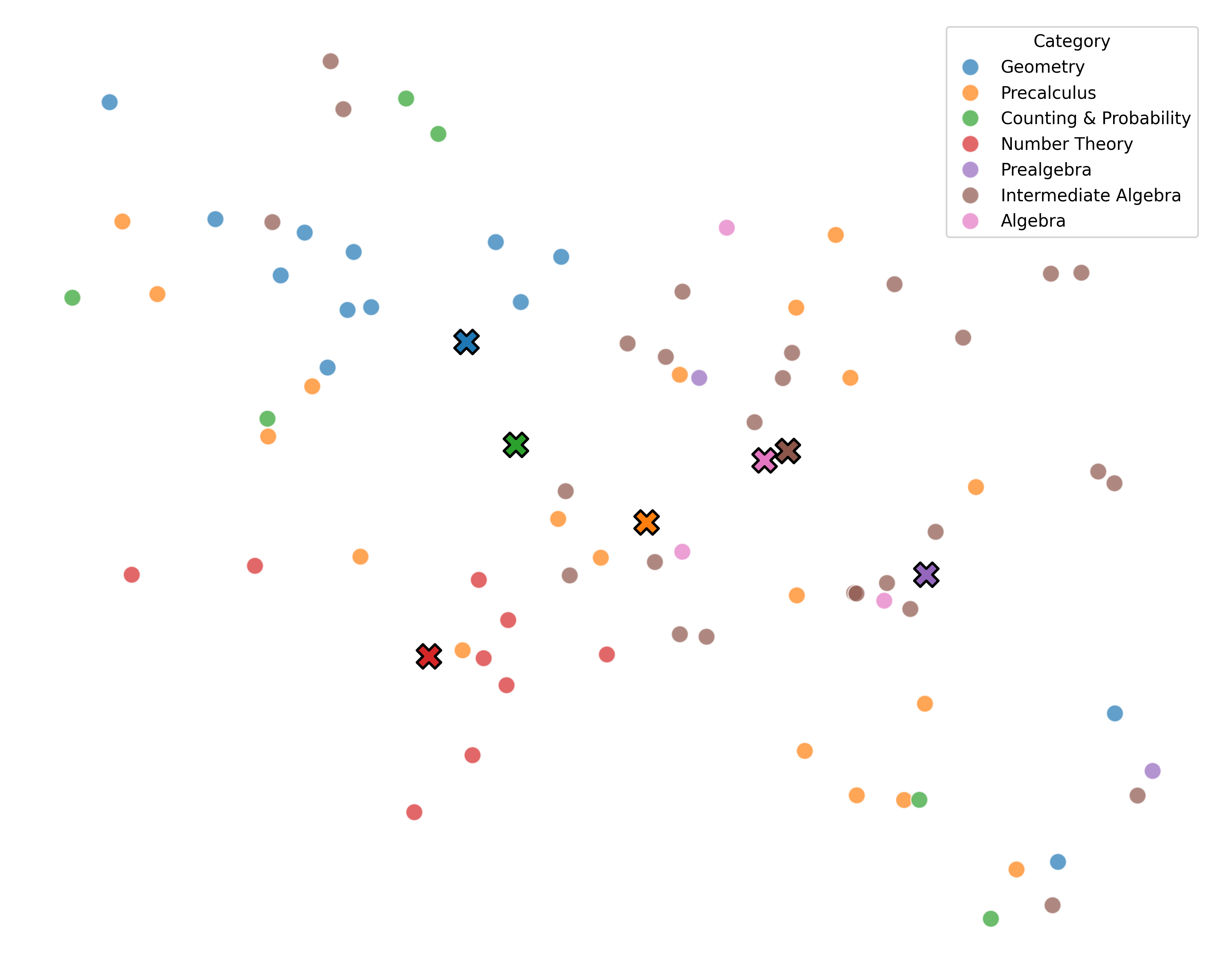
We argue that these mechanisms do not align with human wisdom, known as Implicit Cognition (IC) (Kihlstrom et al., 1995), through which we learn from experiences to summarize implicit patterns that shape our subconscious mind (Locke & Kristof, 1996), allowing us to use these patterns to solve new problems without explicitly verbalizing them. These patterns contain abstract rules that reflect high-level common knowledge, capable of generalizing across different problems. Additionally, our preliminary experiments on visualizing the representations of explicit plans distilled from CoTs of different questions reveal clear clustering for plans from the same task, along with a certain level of overlap indicating their reuse.
Therefore, this paper mimics IC by proposing a framework called iCLP, which enables any LLM to generate latent plans (LPs) in a hidden space, effectively guiding step-bystep reasoning in the language space. Our key insight for its effectiveness is that LPs, built upon summarizing experi-ences, are analogous to the subconscious mind in humans. Similar to how the subconscious mind serves as a flexible and adaptive guidance system in the brain for diverse problems (Murphy, 1963), LPs, due to their commonality and reusability for reasoning guidance, are small in scale, making them generalizable across tasks.
To construct this space, iCLP first prompts an off-the-shelf LLM to summarize explicit plans from a collection of effective CoT traces. Subsequently, iCLP borrows the encoding module of ICAE (Ge et al., 2024) to map these distilled plans into a small set of memory slots that compress their semantics; it then derives generic slot representations from a codebook learned via a vector-quantized autoencoder (Esser et al., 2021), trained end-to-end with plan reconstruction. By treating codebook indices as special tokens for the LLM, we directly obtain the latent plans, which serve as compact encodings of the plans within the learned codebook. Finally, by integrating them into the original samples, we reformulate each sample into the form: (user: question, assistant: latent plans and CoTs). Fine-tuning any LLM on these samples enables the model to internalize the intelligence of IC, empowering it to perform latent planning for reliable, step-wise reasoning.
We conduct evaluations on mathematical reasoning and code generation tasks. For accuracy, supervised fine-tuning of small LLMs, such as Qwen2.5-7B, with iCLP on datasets like MATH and CodeAlpaca yields substantial gains, achieving performance competitive with GRPO (Shao et al., 2024), which relies on reinforcement learning. For efficiency, LLMs enhanced with iCLP reduce token cost by 10% on average compared to zero-shot CoT prompting. For generality, cross-dataset evaluations show that fine-tuned models applied to AIME2024 and MATH-500 achieve more than a 10% average accuracy improvement over base models. Similarly, on HumanEval and MBPP, we observe a 9% gain. Moreover, LLMs fine-tuned with iCLP outperform all baselines, including those trained with long CoT samples and latent CoT reasoning, while maintaining interpretability.
Large language models (LLMs) have the capability to solve problems using step-by-step reasoning (Kojima et al., 2022), where each step addresses a sub-problem