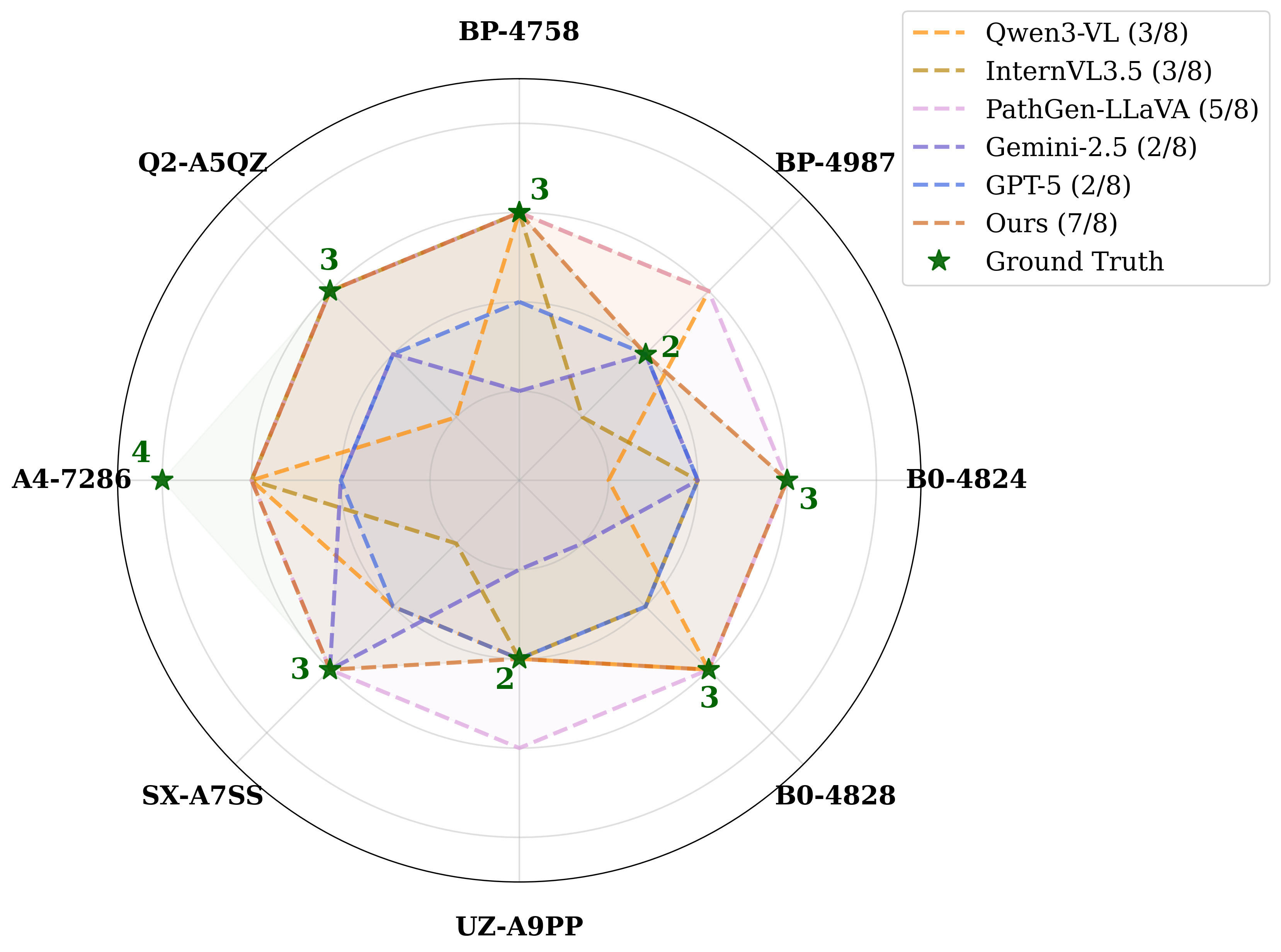
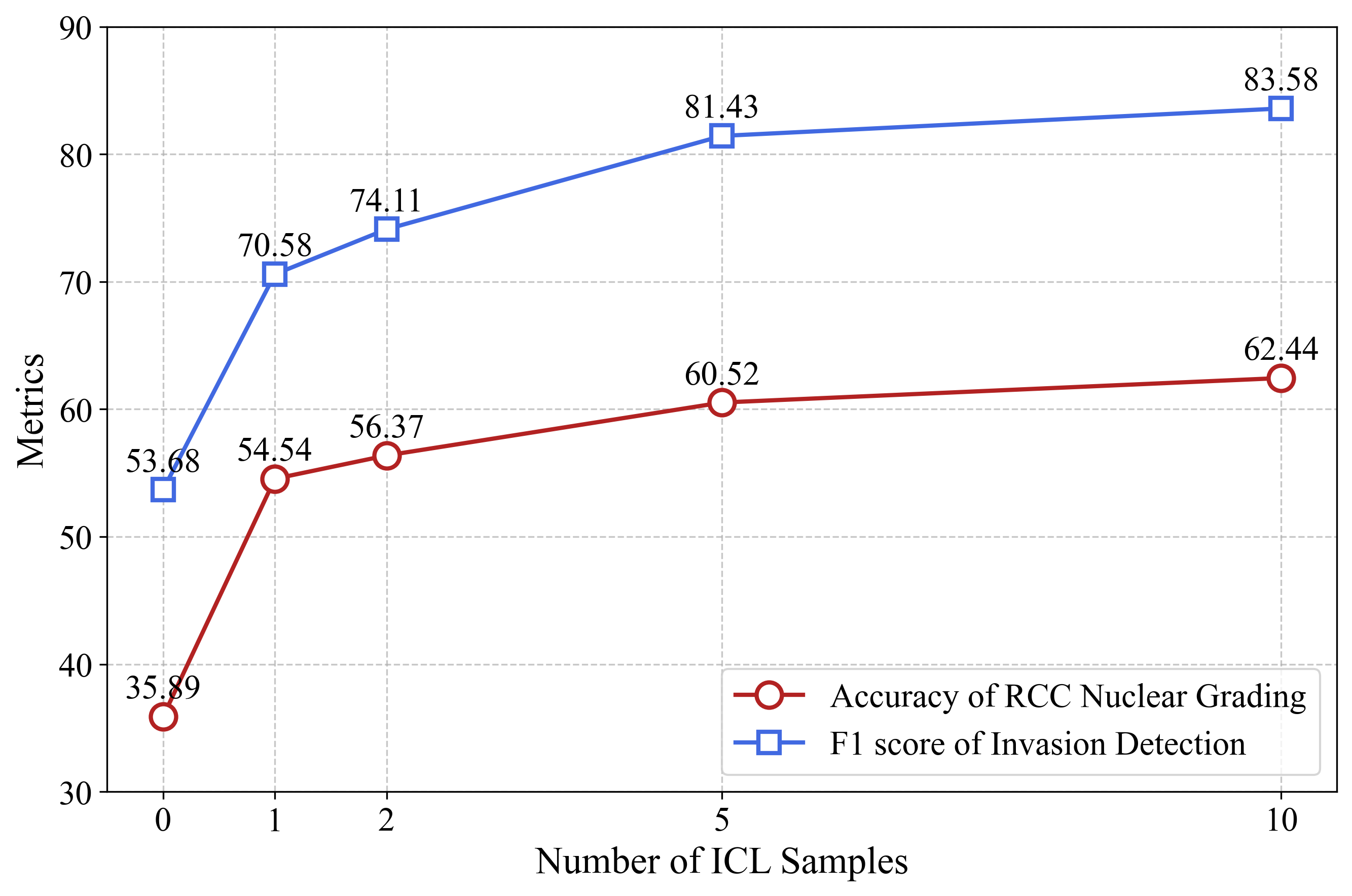
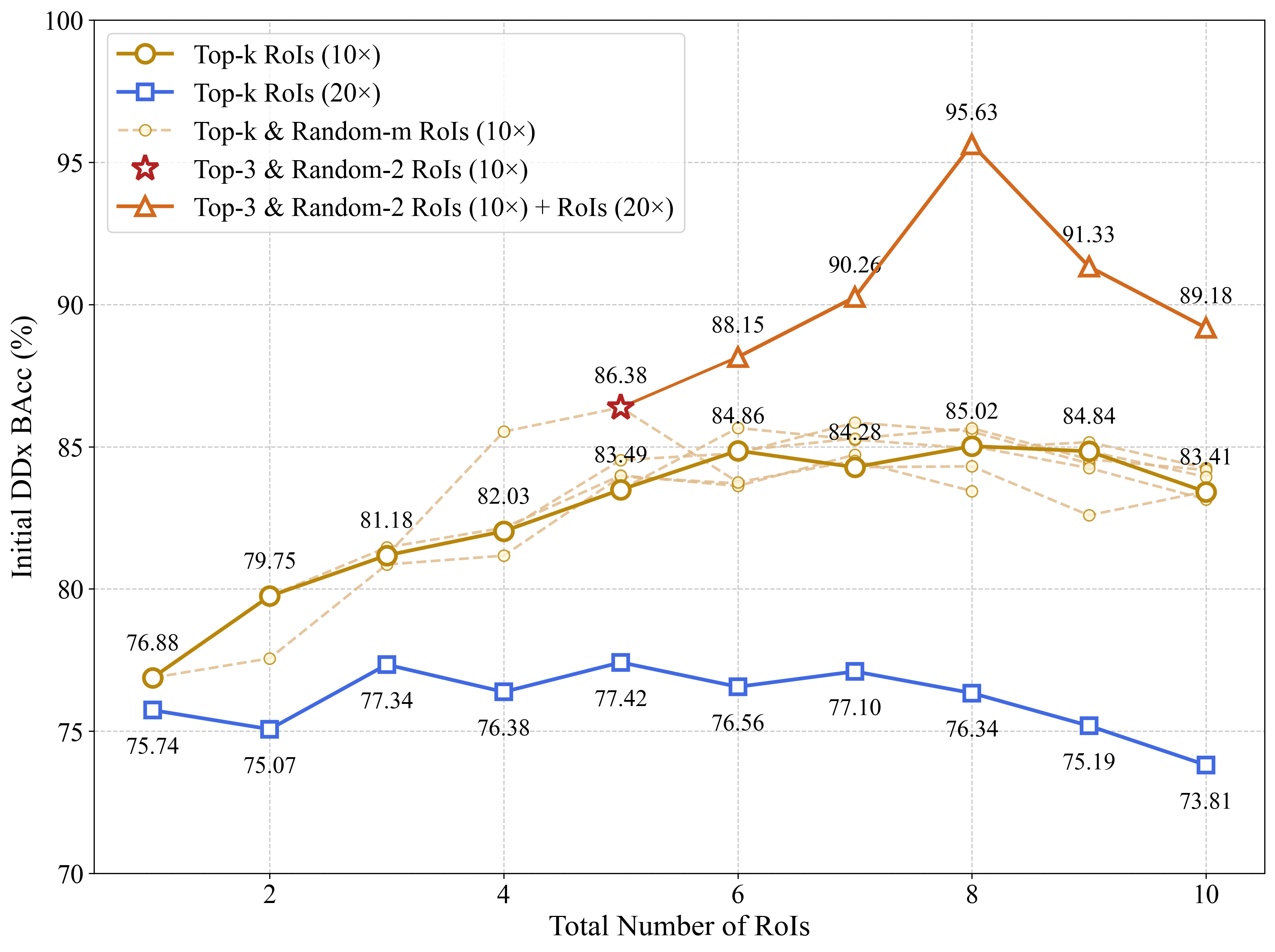
Recent pathological foundation models have substantially advanced visual representation learning and multimodal interaction. However, most models still rely on a static inference paradigm in which whole-slide images are processed once to produce predictions, without reassessment or targeted evidence acquisition under ambiguous diagnoses. This contrasts with clinical diagnostic workflows that refine hypotheses through repeated slide observations and further examination requests. We propose PathFound, an agentic multimodal model designed to support evidence-seeking inference in pathological diagnosis. PathFound integrates the power of pathological visual foundation models, visionlanguage models, and reasoning models trained with reinforcement learning to perform proactive information acquisition and diagnosis refinement by progressing through the initial diagnosis, evidence-seeking, and final decision stages. Across several large multimodal models, adopting this strategy consistently improves diagnostic accuracy, indicating the effectiveness of evidence-seeking workflows in computational pathology. Among these models, PathFound achieves state-of-the-art diagnostic performance across diverse clinical scenarios and demonstrates strong potential to discover subtle details, such as nuclear features and local invasions.
💡 Deep Analysis
📄 Full Content
Recent advances in pathological foundation models have substantially reshaped computational pathology. This progress can be broadly characterized by two stages: early self-supervised visual foundation models (VFMs) that learn rich morphological representations from whole-slide images (WSIs) (Xu et al., 2024;Wang et al., 2024) and cropped patches (Chen et al., 2024;Vorontsov et al., 2024;Zimmermann et al., 2024), and more recent vision-language models (VLMs) that enable increasingly flexible communication with users.
Models (Huang et al., 2023;Lu et al., 2024a) pretrained with contrastive language-image objectives, such as CLIP (Radford et al., 2021) and CoCa (Yu et al., 2022), exhibit promising zero-shot generalization to unseen categories. More recent pathological multimodal models serve as copilots (Lu et al., 2024b;Sun et al., 2025a), further extending the boundary by enabling conversational interactions and supporting diverse diagnostic-related tasks. To improve WSI analysis and pathological diagnosis, some copilots (Ghezloo et al., 2025;Chen et al., 2025;Sun et al., 2025b) incorporate navigation or planning agents that iteratively se-lect informative regions for inspection, forming an inner loop of slide observation that refines visual perception through repeated region proposal and analysis.
Despite these advances, a fundamental gap remains between current multimodal models and real-world clinical diagnostic workflows. Most existing systems still operate under a “read-once, predict-once” paradigm, in which a WSI is analyzed once to directly produce a final answer, as illustrated in Fig. 1(A). Even when iterative navigation is introduced, slide assessment primarily serves to optimize visual understanding for a fixed prediction objective, and the diagnostic conclusion itself is neither revisited nor revised.
In contrast, routine pathological diagnosis is inherently progressive and hypothesis-driven. Pathologists typically begin with a global assessment of the slide to establish an initial diagnostic hypothesis (e.g., suspecting renal cell carcinoma). This hypothesis then guides subsequent actions, including targeted re-observation of specific regions to assess fine-grained features (such as nuclear grade) and consultation of external evidence, such as immunohistochemistry (IHC) results, when ambiguity remains. Diagnosis is refined through repeated cycles of evidence gathering and hypothesis updating. Current models lack the ability to proactively revisit WSIs under different purposes, seek targeted evidence, or gradually refine conclusions when diagnostic uncertainty persists.
To bridge this gap, we propose PathFound, a large agentic multimodal model designed to align pathological diagnosis with clinical reasoning. As shown in Fig. 1(B), rather than passively answering questions from static inputs, PathFound iteratively formulates diagnostic hypotheses, actively acquires visual or external evidence, and refines its conclusions until a precise diagnosis is achieved. Contrary to previous agentic models that focus on slide navigation, PathFound elevates slide re-observation from an inner perceptual optimization step to an integral component of diagnostic reasoning, forming an outer loop that spans hypothesis formulation, evidence acquisition, and conclusion refinement.
PathFound integrates three complementary components. A slide highlighter, which is built upon pathological VFMs, condenses large WSIs into representative regions of interest (RoIs). A vision interpreter, adapted from general VLMs, then translates these RoIs into textual observations. A diagnostic reasoner, trained with reinforcement learning with verifiable rewards (RLVR) (DeepSeek-AI, 2025), orchestrates evidence acquisition, interacts with users, and manages the overall diagnostic process. During a diagnostic session, PathFound follows a structured three-stage pro-tocol to trigger the three modules, mirroring pathologists’ coarse-to-fine reasoning. The protocol begins with an exploratory stage involving all three modules to form initial diagnostic hypotheses and identify informative queries for additional evidence. With limited information in hand, it proceeds to an evidence-seeking stage that actively acquires targeted visual information by re-triggering the slide highlighter and vision interpreter, and by obtaining clinical results from external requests. Once sufficient evidence has been collected, the diagnostic reasoner concludes with a decision stage that consolidates the gathered evidence to produce a final diagnosis. This iterative design enables progressive hypothesis refinement rather than relying on a single, static inference. The code will be made public at https://github.com/hsymm/PathFound
.
Our contributions are threefold. (1) We introduce PathFound, an agentic pathological multimodal model that performs progressive, evidence-seeking diagnosis aligned with clinical practice. (2) We present a unified framework integratin