Title: Benchmark Success, Clinical Failure: When Reinforcement Learning Optimizes for Benchmarks, Not Patients
ArXiv ID: 2512.23090
Date: 2025-12-28
Authors: Armin Berger, Manuela Bergau, Helen Schneider, Saad Ahmad, Tom Anglim Lagones, Gianluca Brugnara, Martha Foltyn-Dumitru, Kai Schlamp, Philipp Vollmuth, Rafet Sifa
📝 Abstract
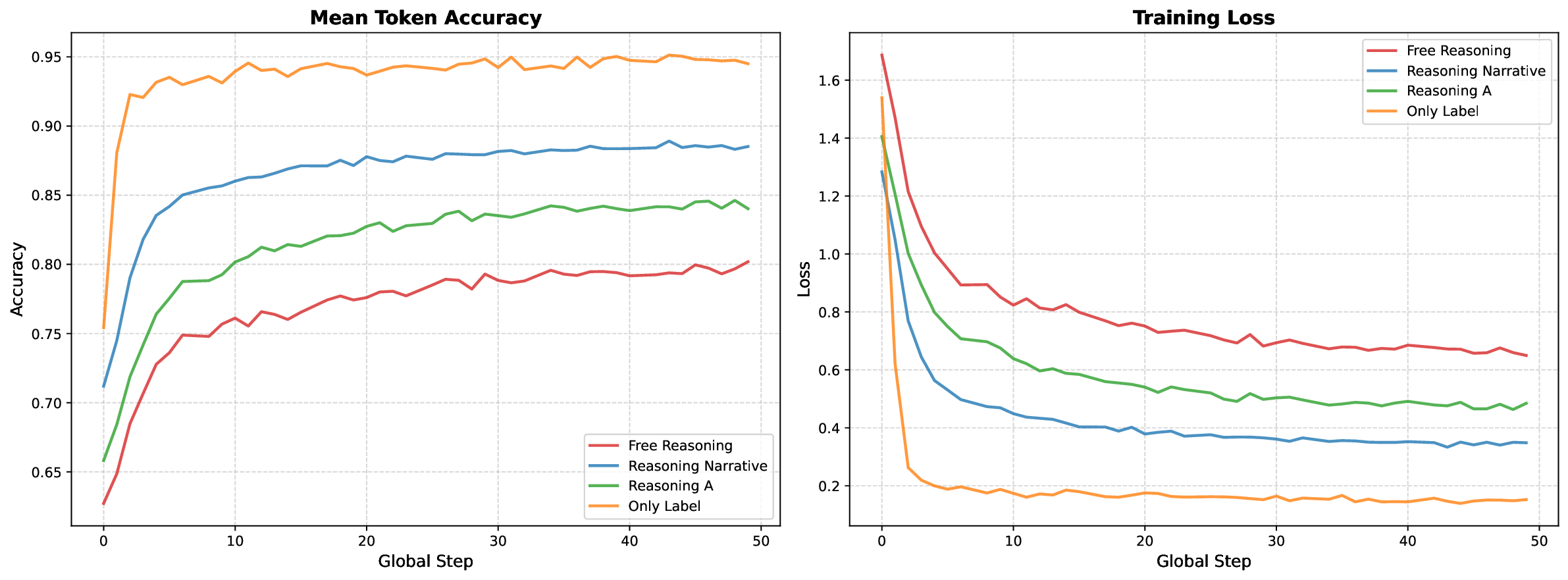
Recent Reinforcement Learning (RL) advances for Large Language Models (LLMs) have improved reasoning tasks, yet their resource-constrained application to medical imaging remains underexplored. We introduce ChexReason, a vision-language model trained via R1-style methodology (SFT followed by GRPO) using only 2,000 SFT samples, 1,000 RL samples, and a single A100 GPU. Evaluations on CheXpert and NIH benchmarks reveal a fundamental tension: GRPO recovers in-distribution performance (23% improvement on CheXpert, macro-F1 = 0.346) but degrades cross-dataset transferability (19% drop on NIH). This mirrors highresource models like NV-Reason-CXR-3B, suggesting the issue stems from the RL paradigm rather than scale. We identify a generalization paradox where the SFT checkpoint uniquely improves on NIH before optimization, indicating teacher-guided reasoning captures more institutionagnostic features. Furthermore, cross-model comparisons show structured reasoning scaffolds benefit general-purpose VLMs but offer minimal gain for medically pre-trained models. Consequently, curated supervised finetuning may outperform aggressive RL for clinical deployment requiring robustness across diverse populations.
💡 Deep Analysis
📄 Full Content
Benchmark Success, Clinical Failure:
When Reinforcement Learning Optimizes for
Benchmarks, Not Patients
Armin Berger∗1,2,3, Manuela Bergau∗1,2,3, Helen Schneider1, Saad
Ahmad1, Tom Anglim Lagones4,5, Gianluca Brugnara6, Martha
Foltyn-Dumitru6, Kai Schlamp6, Philipp Vollmuth6, and Rafet
Sifa1,2
1Fraunhofer IAIS, Germany
2University of Bonn , Germany
3Lamarr Institute, Germany
4Department of Health Queensland, Australia
5Griffith University, Australia
6University Hospital Bonn, Germany
December 2025
Abstract
Recent Reinforcement Learning (RL) advances for Large Language
Models (LLMs) have improved reasoning tasks, yet their resource-constrained
application to medical imaging remains underexplored.
We introduce
ChexReason, a vision-language model trained via R1-style methodology
(SFT followed by GRPO) using only 2,000 SFT samples, 1,000 RL sam-
ples, and a single A100 GPU. Evaluations on CheXpert and NIH bench-
marks reveal a fundamental tension: GRPO recovers in-distribution per-
formance (23% improvement on CheXpert, macro-F1 = 0.346) but de-
grades cross-dataset transferability (19% drop on NIH). This mirrors high-
resource models like NV-Reason-CXR-3B, suggesting the issue stems from
the RL paradigm rather than scale. We identify a generalization para-
dox where the SFT checkpoint uniquely improves on NIH before opti-
mization, indicating teacher-guided reasoning captures more institution-
agnostic features. Furthermore, cross-model comparisons show structured
reasoning scaffolds benefit general-purpose VLMs but offer minimal gain
for medically pre-trained models. Consequently, curated supervised fine-
tuning may outperform aggressive RL for clinical deployment requiring
robustness across diverse populations.
∗These authors contributed equally and share first authorship.
1
arXiv:2512.23090v2 [cs.AI] 2 Jan 2026
1
Introduction
Recent work demonstrates that reinforcement learning (RL) can substantially
improve large language model performance, particularly in settings with a clear
reward signal and automatically verifiable outcomes (e.g., mathematics and code
generation; see, e.g., DeepSeek-R1). However, it remains less clear how reliably
these gains transfer to problems with weaker or more subjective supervision,
such as free-form natural language generation and multimodal inputs. In this
work, we investigate whether R1-style training, which combines supervised fine-
tuning (SFT) with Group Relative Policy Optimization (GRPO), can enhance
multilabel chest X-ray classification in small vision-language models under se-
vere resource constraints. We focus on chest X-ray diagnosis because it rep-
resents a clinically critical task where radiologists value both hard diagnostic
labels for rapid assessment and accompanying reasoning traces to establish trust
in model outputs. Moreover, chest X-rays benefit from large publicly available
datasets with multilabel annotations that provide natural reward signals for
reinforcement learning. While recent work has explored R1-style reasoning for
medical visual question answering, multilabel chest X-ray classification remains
less studied. A notable exception is NVIDIA’s NV-Reason-CXR-3B, which uti-
lizes extensive synthetic data and compute. Our work contrasts with this high-
resource approach by examining R1-style training under extreme constraints: 50
times less training data and 4 times less compute. This setting is particularly
relevant for practitioners who lack large-scale annotation pipelines or extensive
infrastructure but still seek to leverage reasoning-guided training for improved
diagnostic performance. Our work makes three primary contributions.
• Low-Resource R1-Style Training: We present ChexReason, trained with
only 2,000 SFT and 1,000 RL samples on a single A100 GPU, demonstrat-
ing that R1-style training is feasible without extensive resources.
• Instruction Format Sensitivity: Cross-model analysis reveals that optimal
instruction format depends on medical pre-training: structured medically
informed reasoning scaffolds benefit general-purpose VLMs while provid-
ing minimal gain for domain-specialized models.
• Benchmark-Transferability Trade-off: GRPO improves CheXpert perfor-
mance (+23%) but degrades NIH transferability (−19%), mirroring NV-
Reason-CXR-3B failures and suggesting a paradigm-level issue.
• Generalization Paradox: The SFT checkpoint uniquely improves on out-
of-distribution data, indicating teacher-guided traces capture more gener-
alizable features than reward-optimized outputs.
2
Related Work
Recent advancements in large language models have spurred significant interest
in applying reinforcement learning (RL) and chain-of-thought (CoT) reasoning
2
to medical vision-language models (VLMs), a trend motivated by the success
of general-domain approaches like DeepSeek-R1. Consequently, several studies
have explored R1-style reasoning recipes for medical visual question answering
(VQA). For instance, MedVLM-R1 [27] utilizes GRPO to improve V