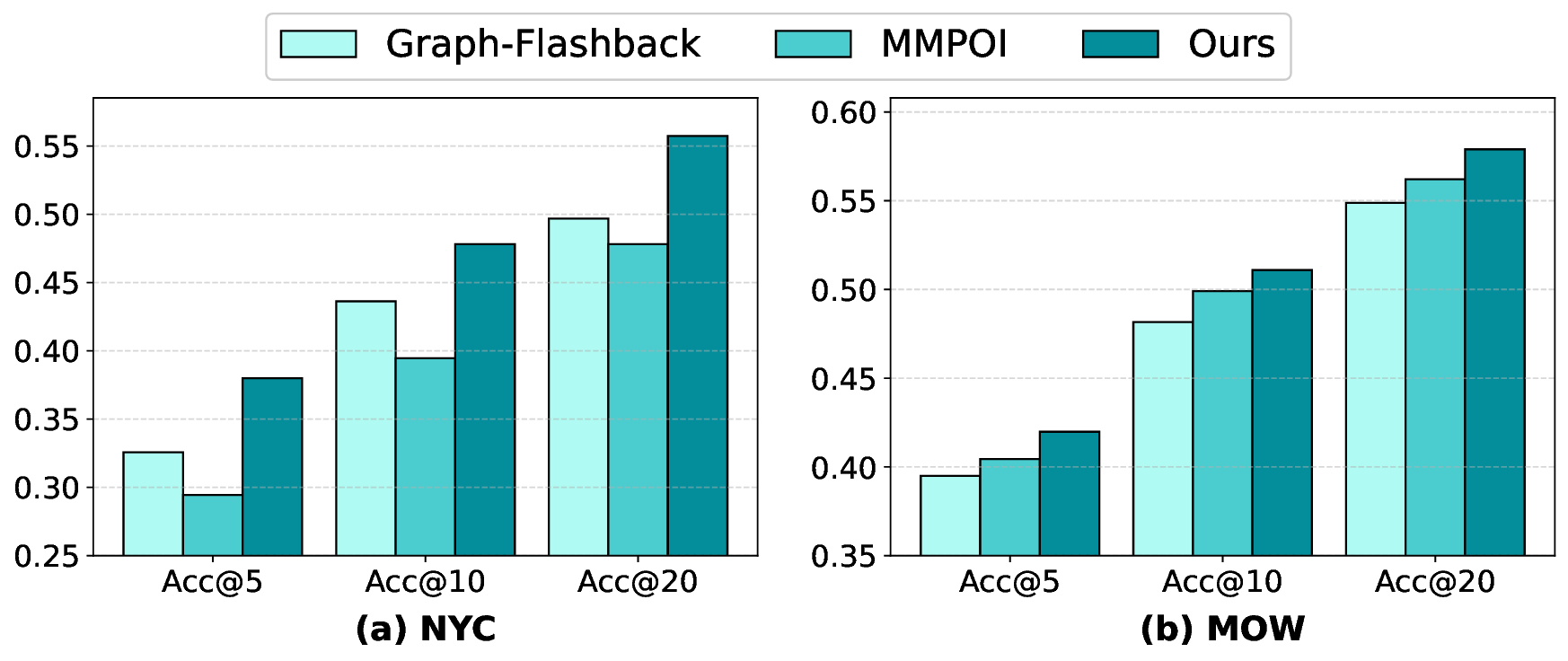
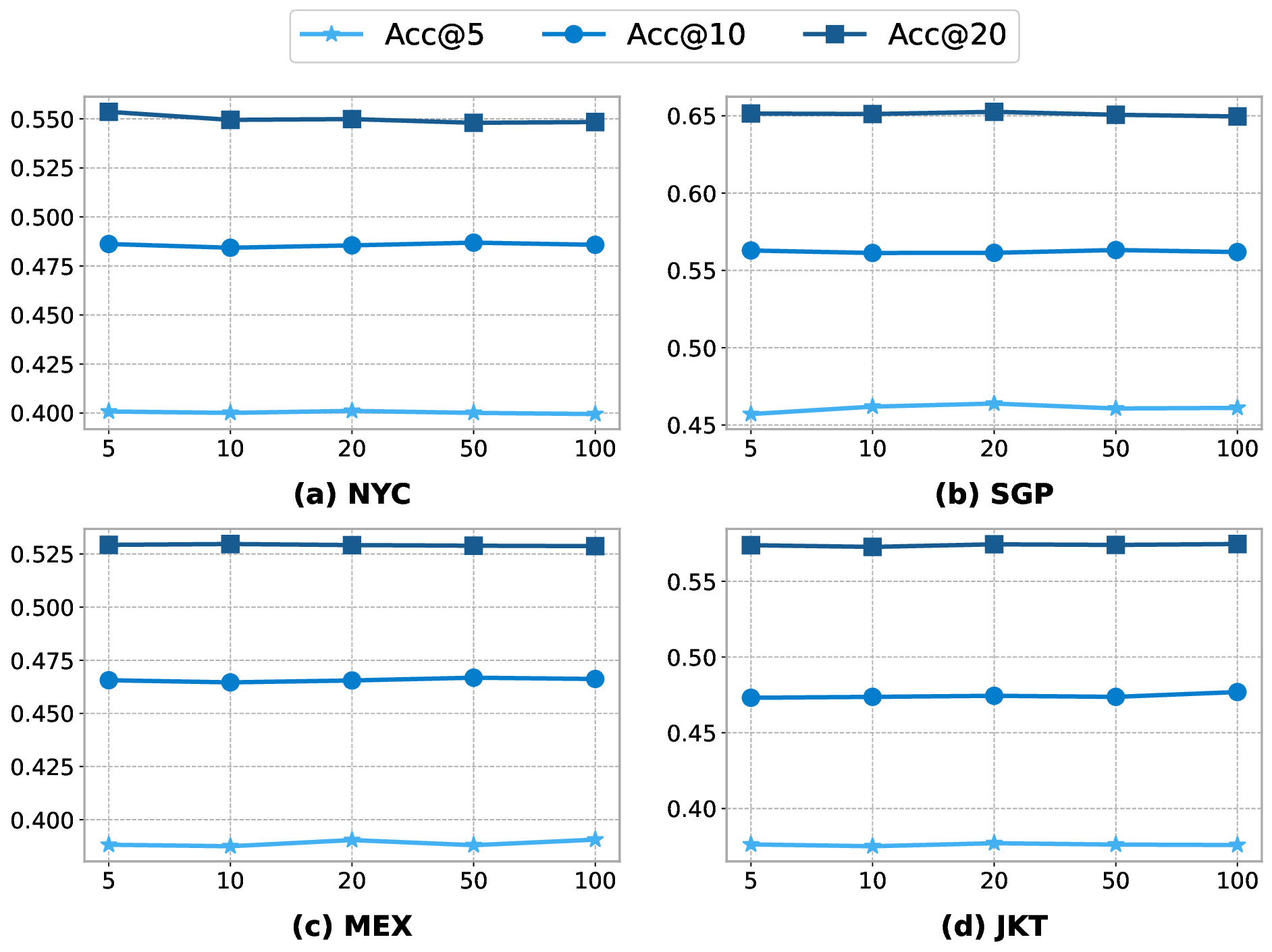
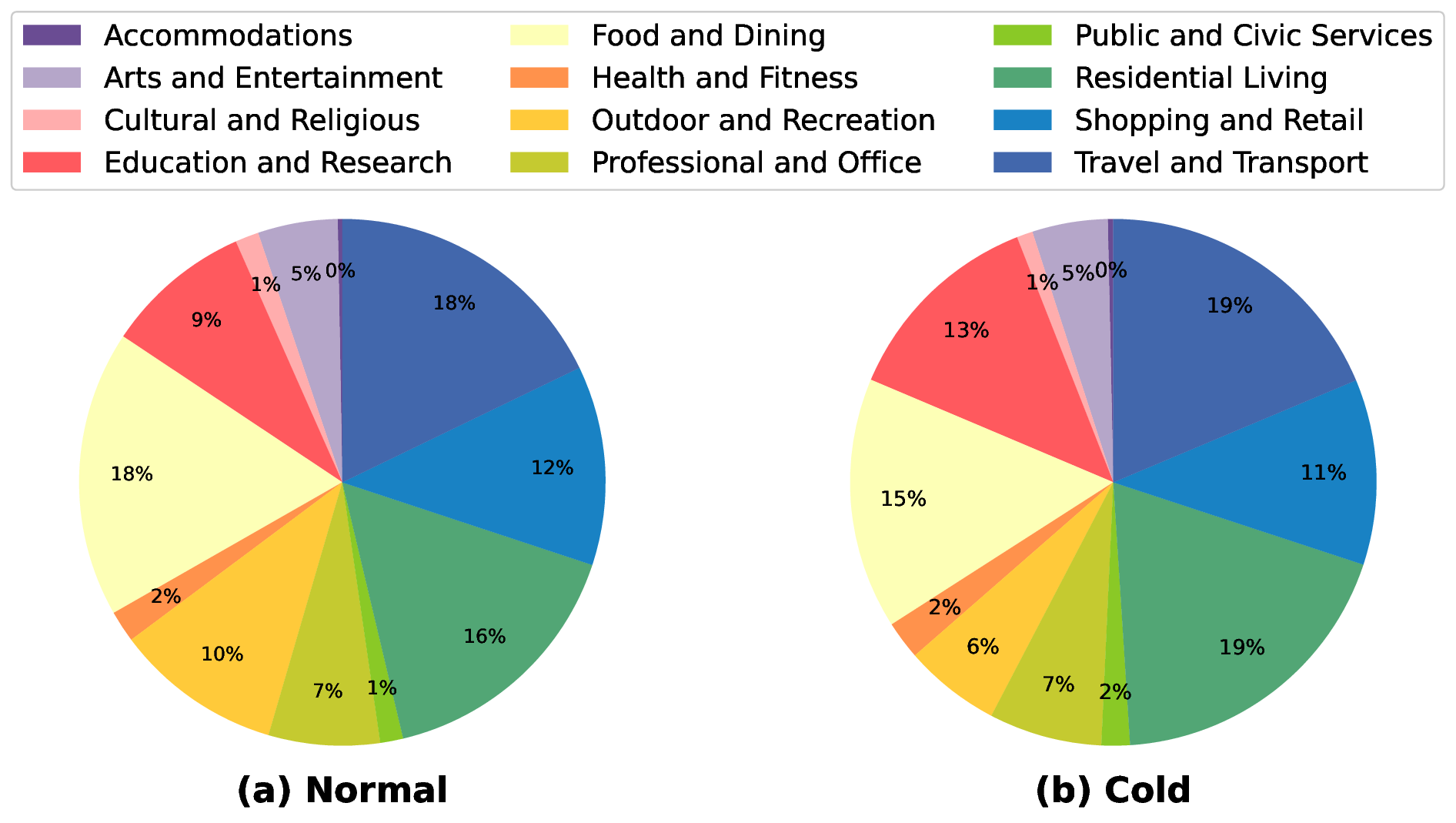
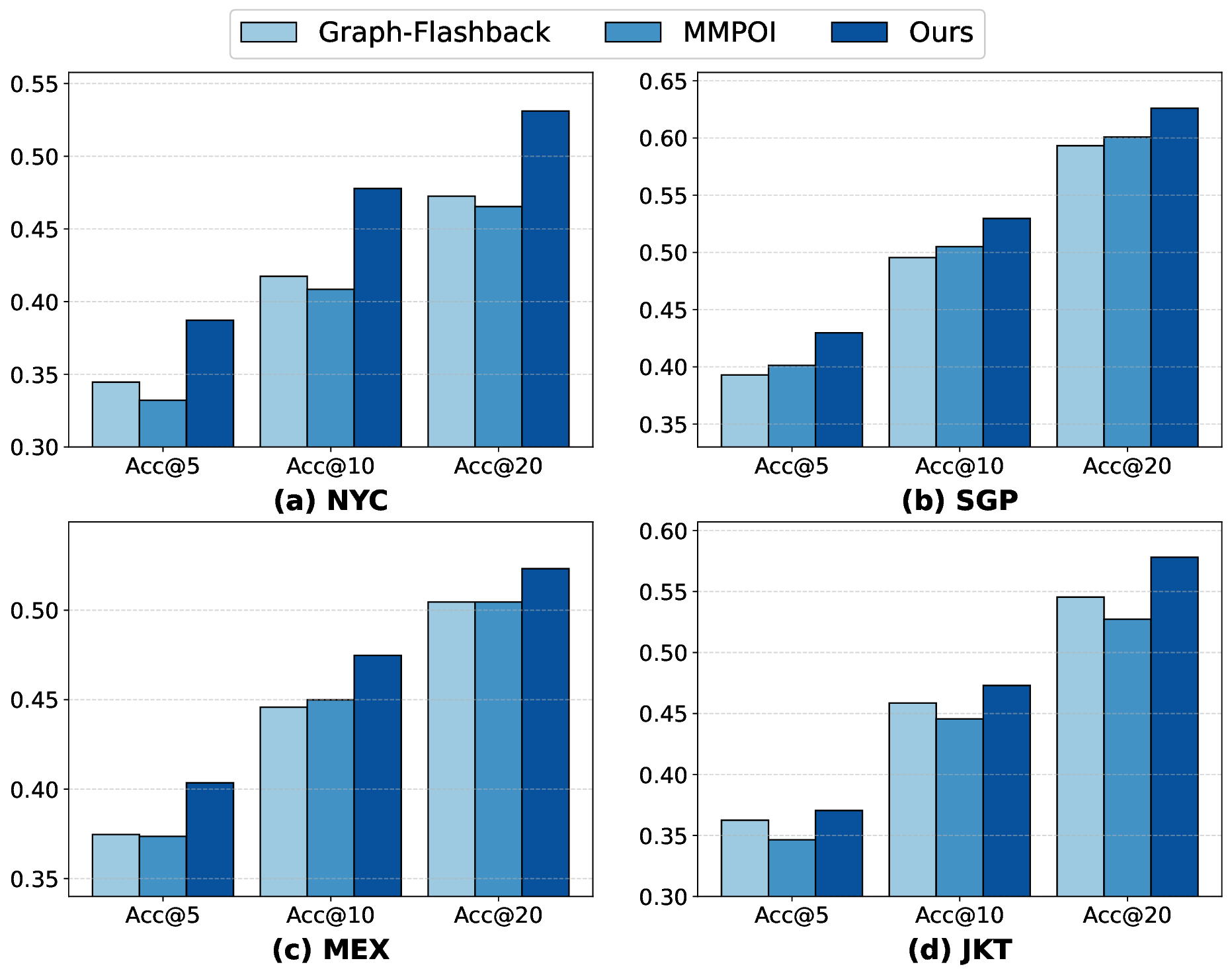
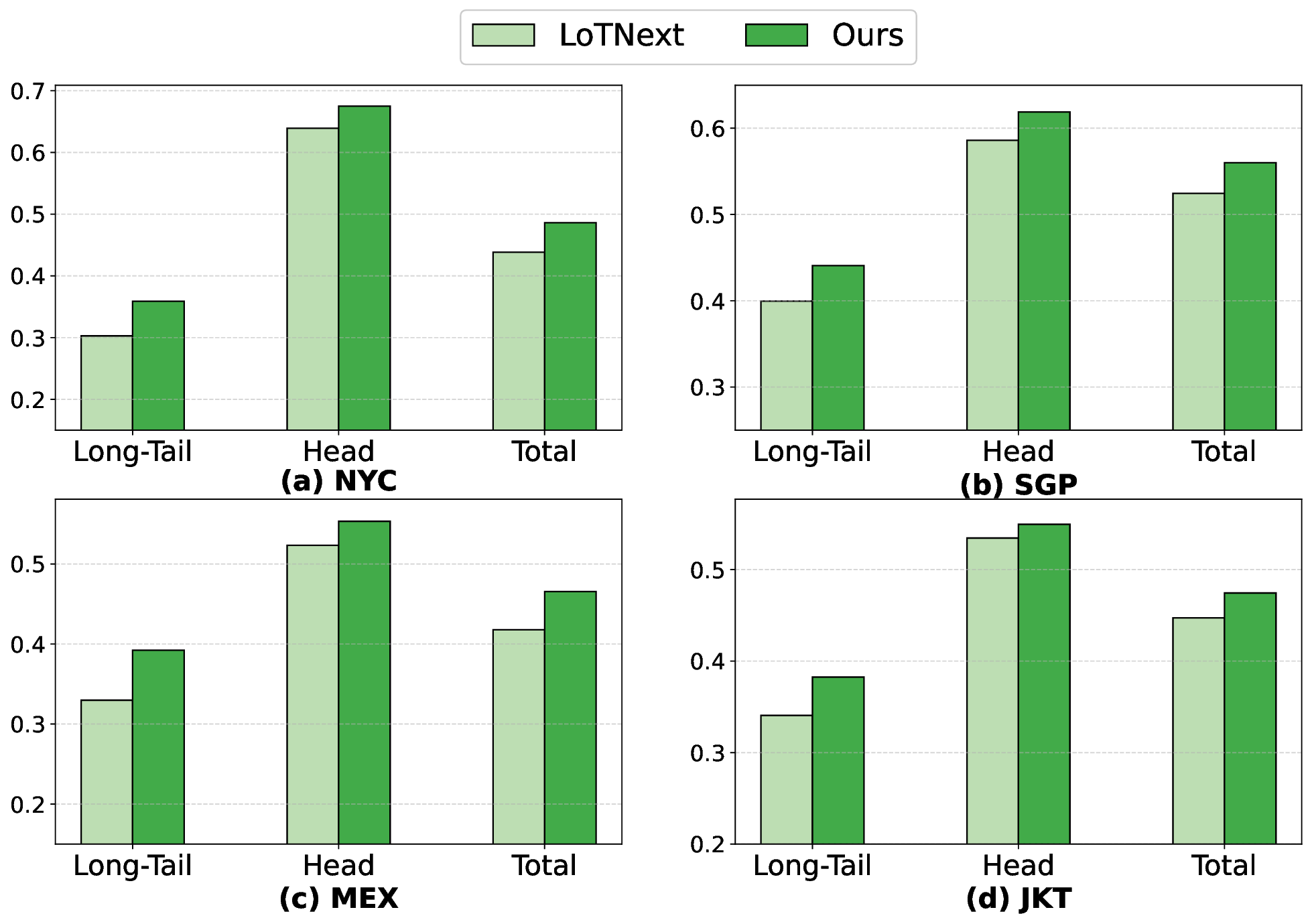
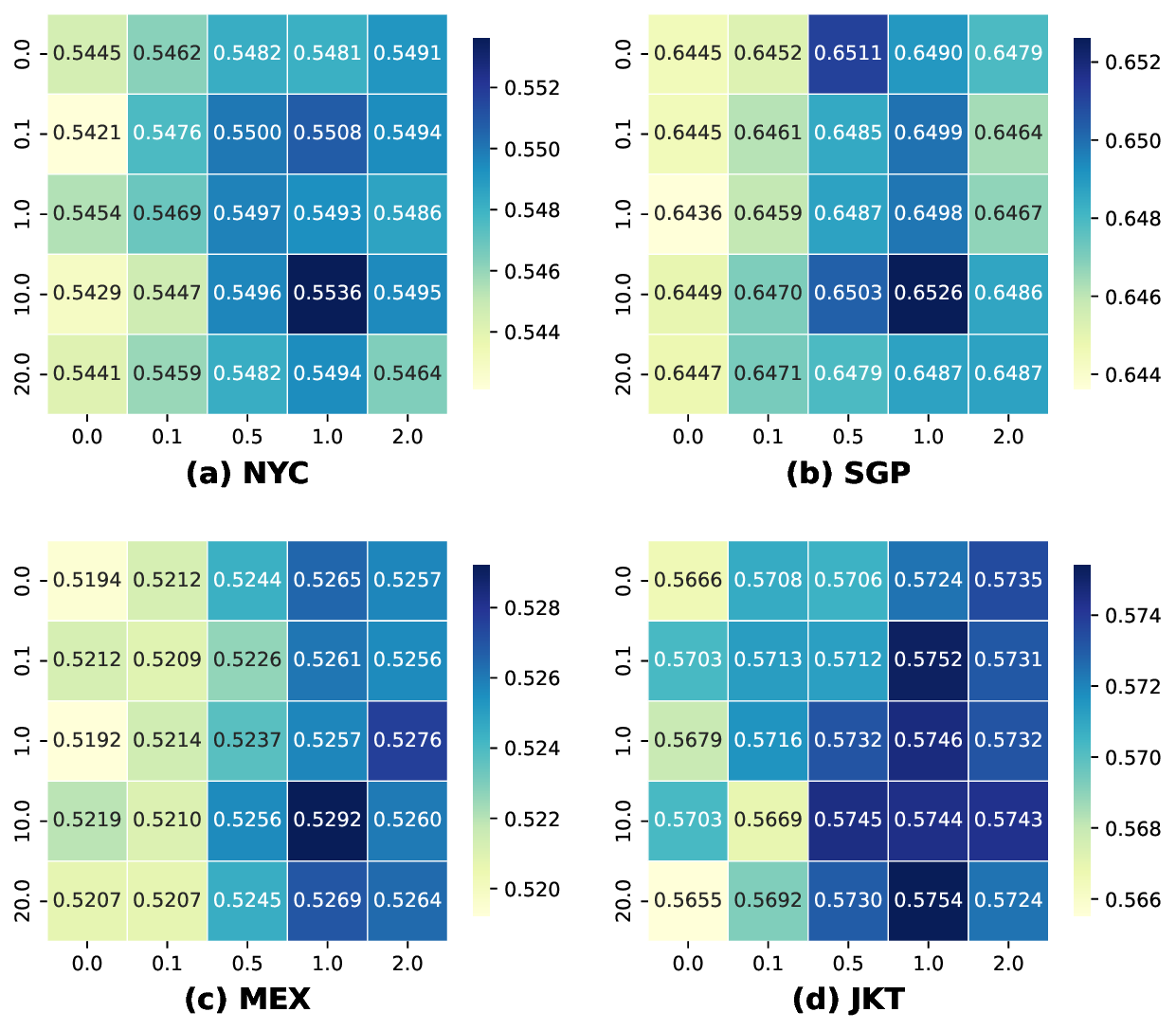
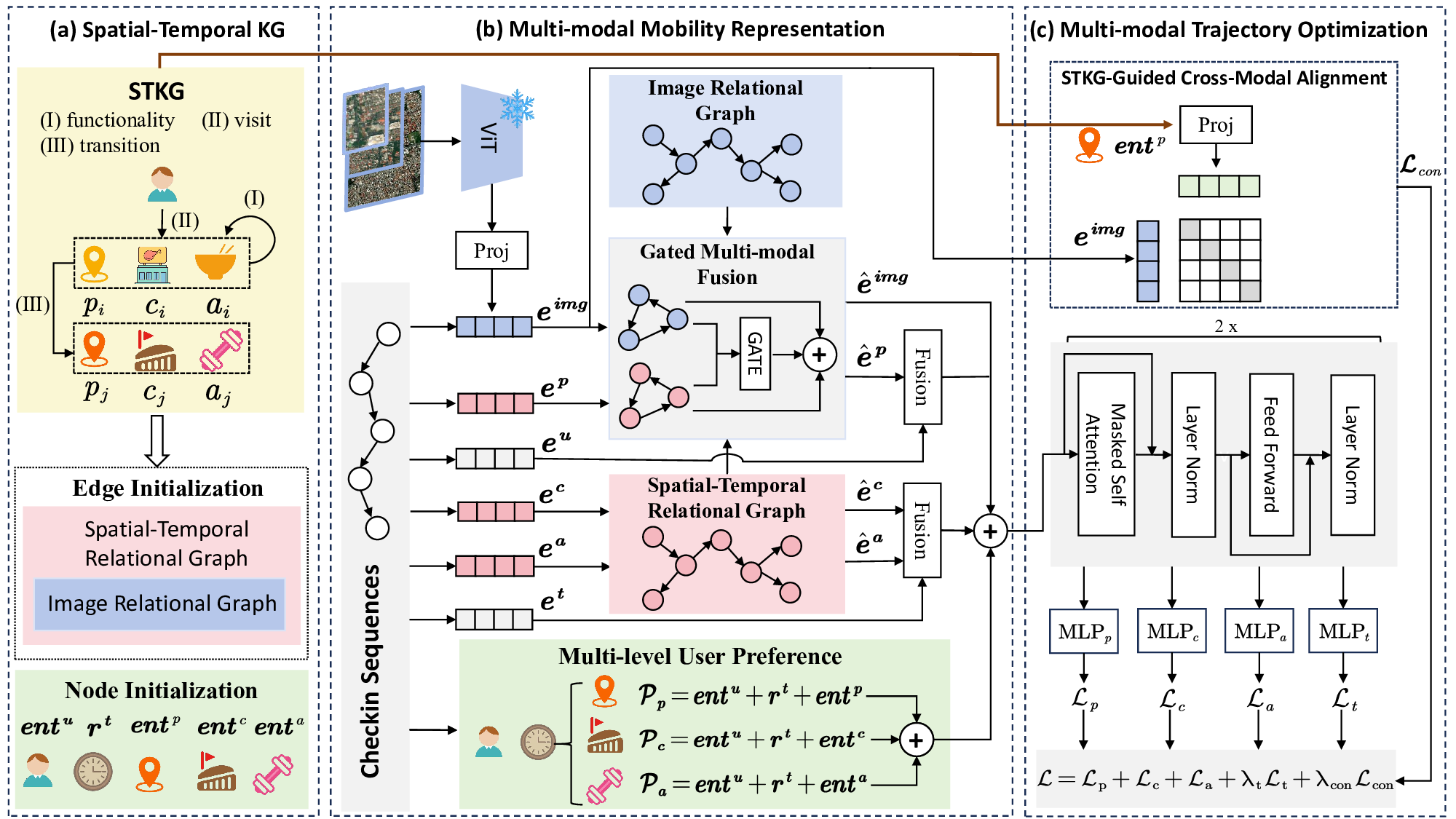
The precise prediction of human mobility has produced significant socioeconomic impacts, such as location recommendations and evacuation suggestions. However, existing methods suffer from limited generalization capability: unimodal approaches are constrained by data sparsity and inherent biases, while multi-modal methods struggle to effectively capture mobility dynamics caused by the semantic gap between static multi-modal representation and spatial-temporal dynamics. Therefore, we leverage multi-modal spatial-temporal knowledge to characterize mobility dynamics for the location recommendation task, dubbed as \textbf{M}ulti-\textbf{M}odal \textbf{Mob}ility (\textbf{M}$^3$\textbf{ob}). First, we construct a unified spatial-temporal relational graph (STRG) for multi-modal representation, by leveraging the functional semantics and spatial-temporal knowledge captured by the large language models (LLMs)-enhanced spatial-temporal knowledge graph (STKG). Second, we design a gating mechanism to fuse spatial-temporal graph representations of different modalities, and propose an STKG-guided cross-modal alignment to inject spatial-temporal dynamic knowledge into the static image modality. Extensive experiments on six public datasets show that our proposed method not only achieves consistent improvements in normal scenarios but also exhibits significant generalization ability in abnormal scenarios.
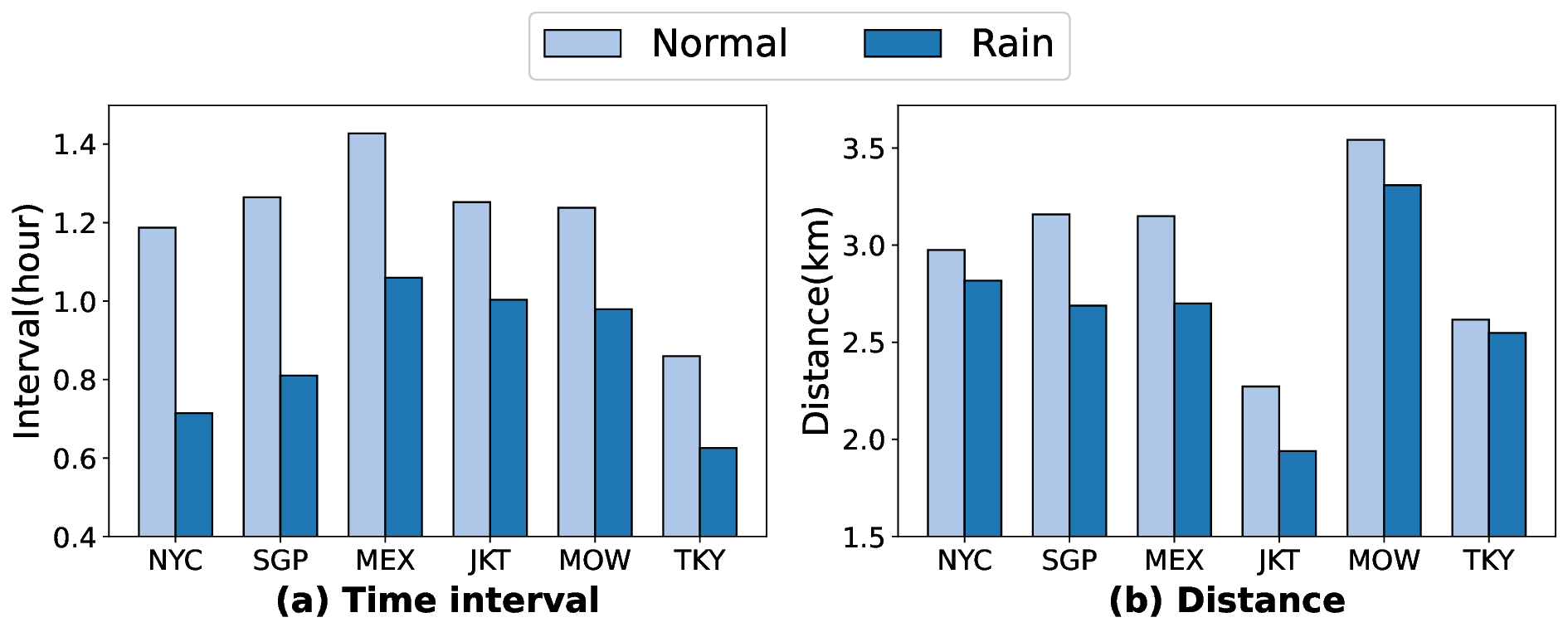
The widely adopted mobile devices have made location-based services highly accessible on the Web, allowing applications such as location search [14,42], mobile navigation [37], and location recommendation [21,45]. However, while the related check-in sequence data greatly facilitates the integration of web services into daily life, two issues lead to data sparsity: the sheer number of locations, and users' tendency to visit only a limited number of popular locations of interest. Furthermore, abnormal mobility behaviors are difficult to capture due to their scarce occurrence, such as visits to long-tail locations or during extreme weather events.
The remarkable success of deep learning has transformed next location recommendation into a representation learning paradigm, which can be categorized into sequence-based methods and graphbased methods. Sequence-based methods design spatial-temporal modules to extract mobility representations within historical checkin sequences, including markov chain-based model [8], RNNs-based model [28,41] and attention-based model [6,7,23,30]. Graph-based methods [3, 9, 15, 24-27, 34, 40, 43] enhance location representations by sharing common patterns of locations based on spatialtemporal graphs. However, the sparsity of check-in sequences and the inherent mobility bias lead to suboptimal performance in representation learning for these unimodal approaches.
Recently, language and vision models have demonstrated advanced representations based on sufficient self-supervised learning, which inspires the progress of multi-modal learning across various domains. In e-commerce recommendation, MKGAT [29] and MMGCN [36] leverage multi-modal attributes of items together with abundant user-item interactions to construct a multi-modal graph for learning. Alignrec [22] narrows the representation distance through contrastive learning between items and their multimodal content. In location recommendation, to our knowledge, MMPOI [39] was the first to introduce multi-modality by constructing a multi-modal graph via cosine similarity. However, existing multi-modal approaches neglect the semantic gap between mobility dynamics and static multi-modal representations, thus inevitably leading to performance degradation when generalizing.
Despite the effectiveness of multi-modal pre-training representations, bridging the semantic heterogeneity between static multimodal data and dynamic human mobility remains a key challenge.
(1) How to model the dynamic relationships of locations and users in a multi-modal view? Current multi-modal methods construct static multi-modal relationships to obtain multi-modal knowledge without integrated mobility dynamics, leading to limited generalization capability in dynamic scenarios. (2) How to align multi-modal representations of locations and users to capture mobility dynamics? The inherent semantic gap between different modalities necessitates spatial-temporal-aware alignment techniques to eliminate the modality heterogeneity.
To this end, we design a Multi-Modal Mobility (M 3 ob) framework that overcomes the generalization gap by building a shared graph across multiple modalities.
To address the first challenge of modeling multi-modal dynamics, we build a spatial-temporal relational graph (STRG) to enable the sharing of spatial-temporal knowledge across modalities, which leverages the functional semantics and spatial-temporal knowledge from a large language models (LLMs)-enhanced spatialtemporal knowledge graph (STKG). The hierarchical knowledge from the STKG further enables the modeling of multi-level user preferences. For the second challenge of aligning multi-modal representations, we employ a gating mechanism to dynamically fuse spatial-temporal graph representations from different modalities, thereby mitigating modal interference. Additionally, STKG-guided cross-modal alignment is applied to reduce inter-modal discrepancies.
Our main contributions are summarized as follows: ✗ ✗ Single-level MMPOI [39] Cosine Similarity ✗ Single-level TSPN-RA [12] Quad Tree ✗ Single-level
or attention mechanisms [23,30]. For instance, LSTPM [28] employs a non-local network and a geographically dilated RNN to model long-and short-term preferences. CLSPRec [6] leverages contrastive learning on raw sequential data to effectively distinguish between long-and short-term user preferences. MCLP [30] incorporates a multi-head attention mechanism to generate arrival time embeddings as contextual information for location recommendation. However, these methods insufficiently capture the spatial-temporal transition patterns of different locations in trajectories. Graph-based models primarily utilize spatial-temporal relationships between locations and apply GNNs to enhance location representations. A line of works enhance location embeddings by constructing spatial-temporal graphs based on geographical and transitional relationships between locations [9,15,25,43]. GETNEXT [43] const
This content is AI-processed based on open access ArXiv data.