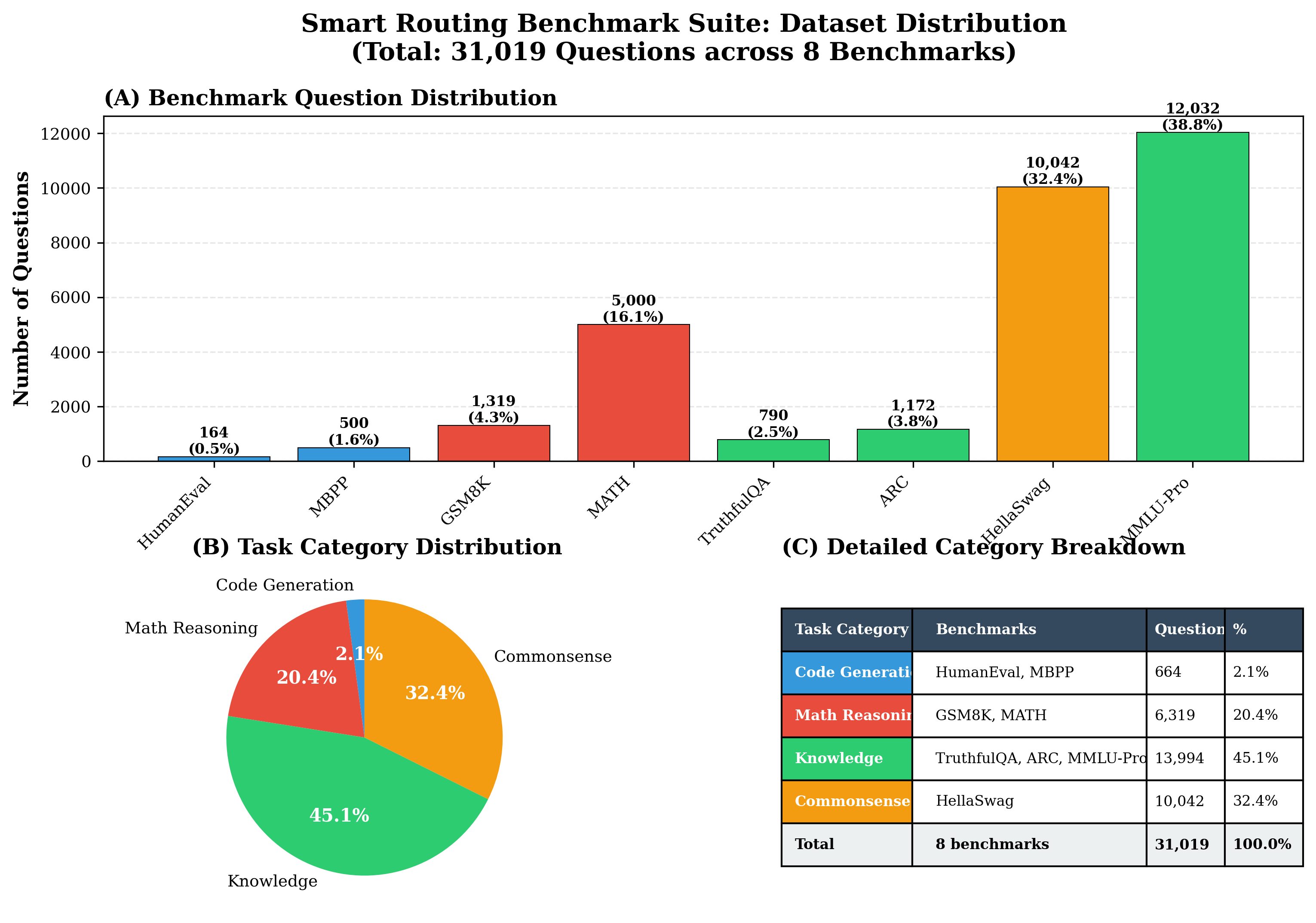
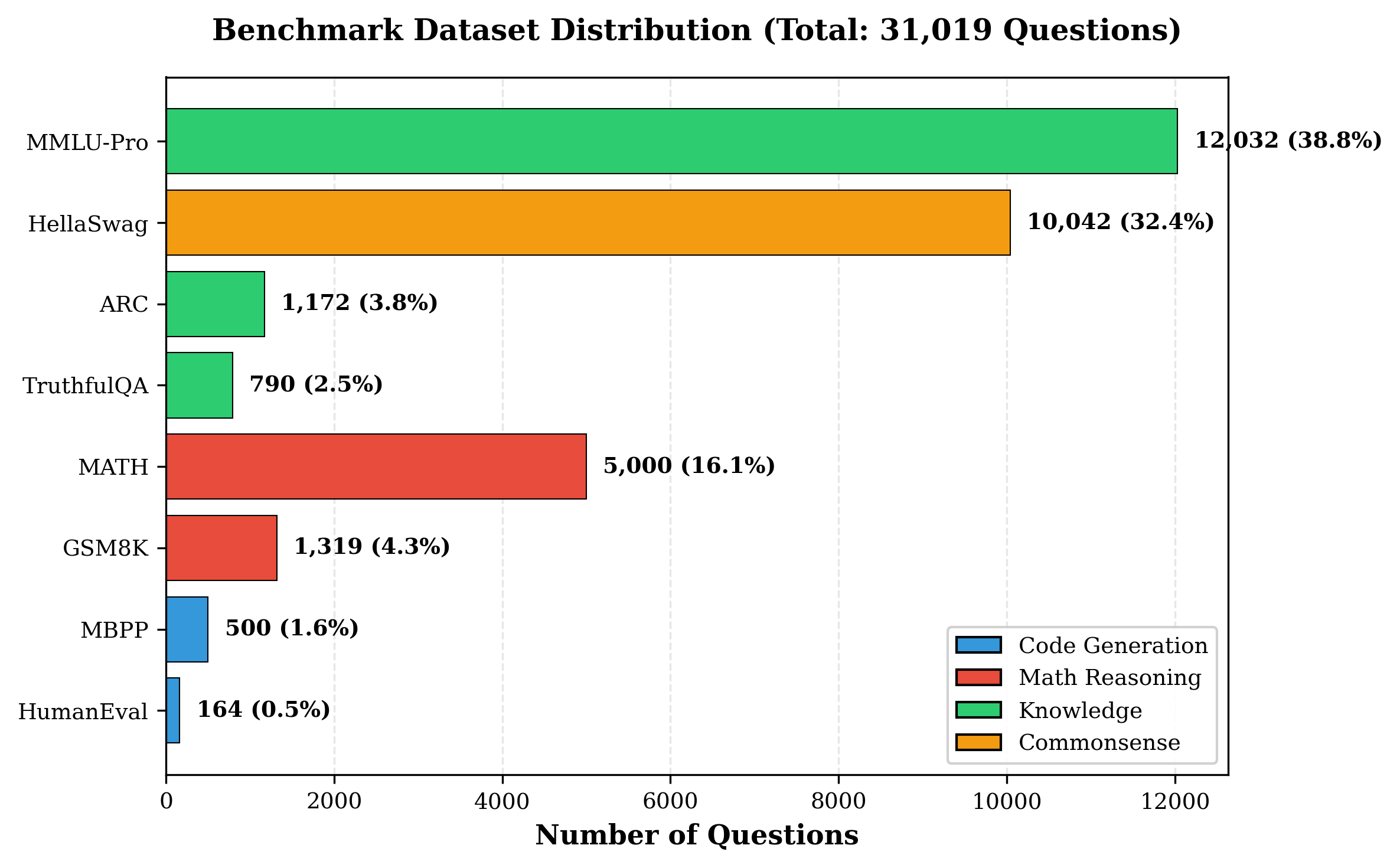
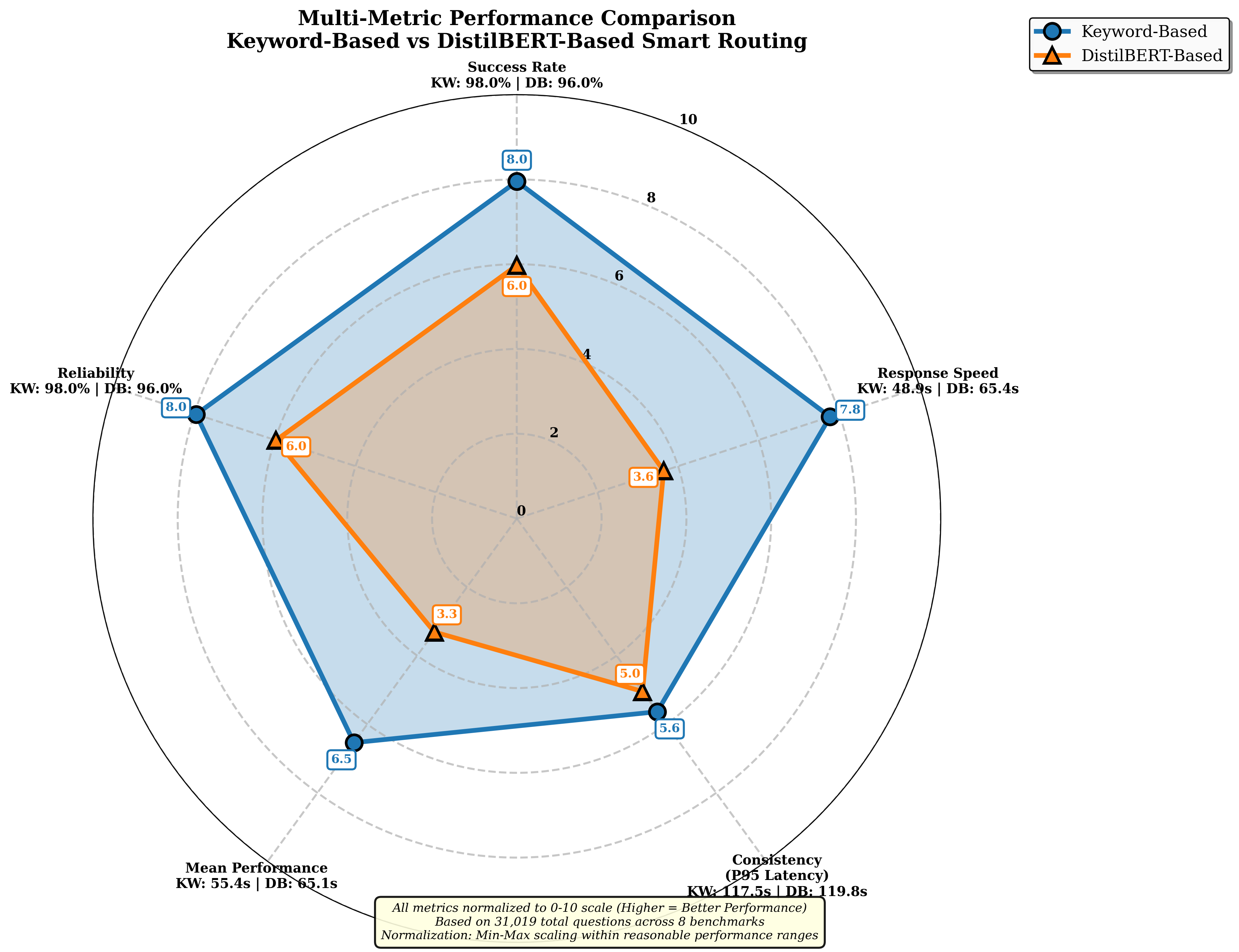
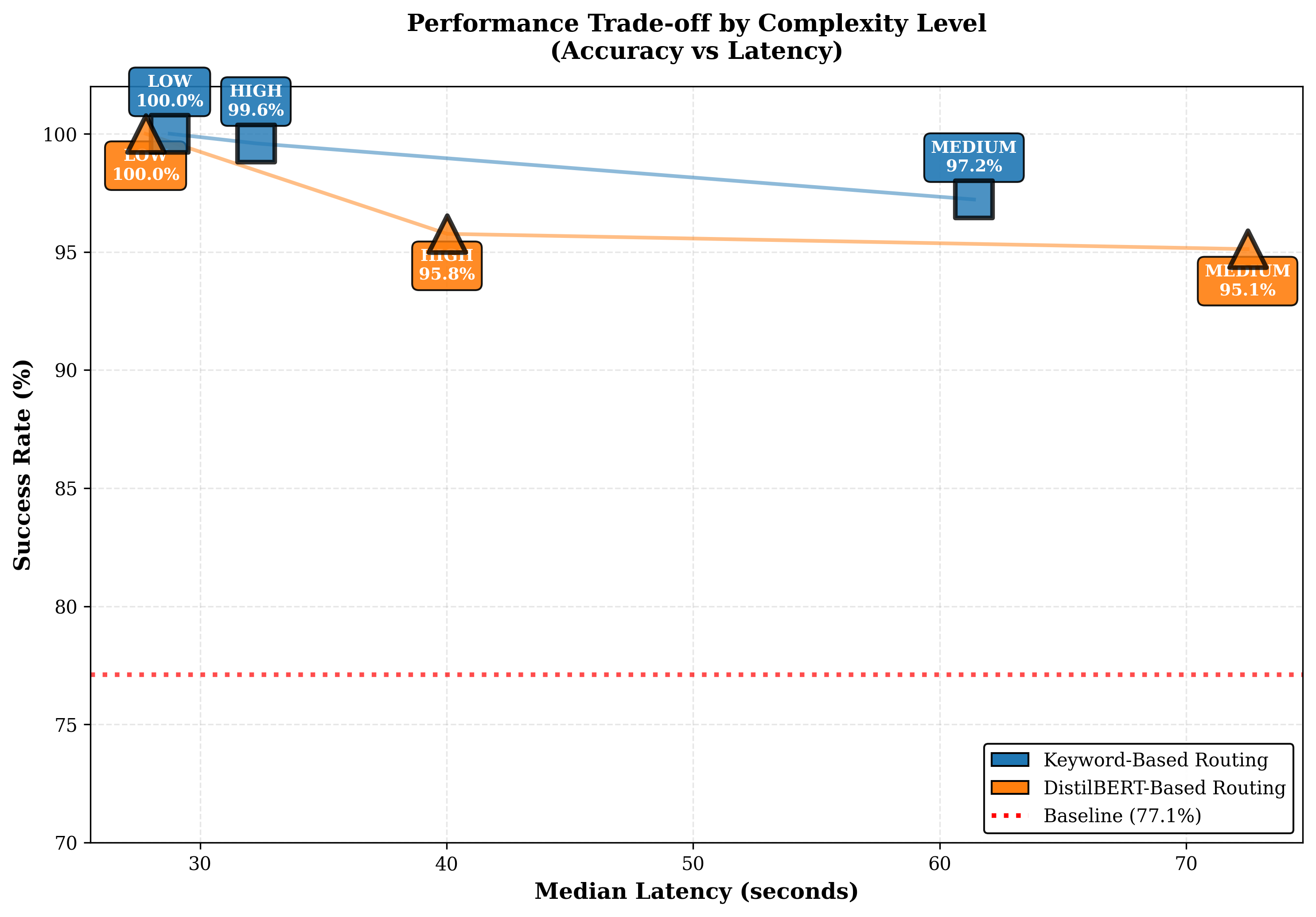
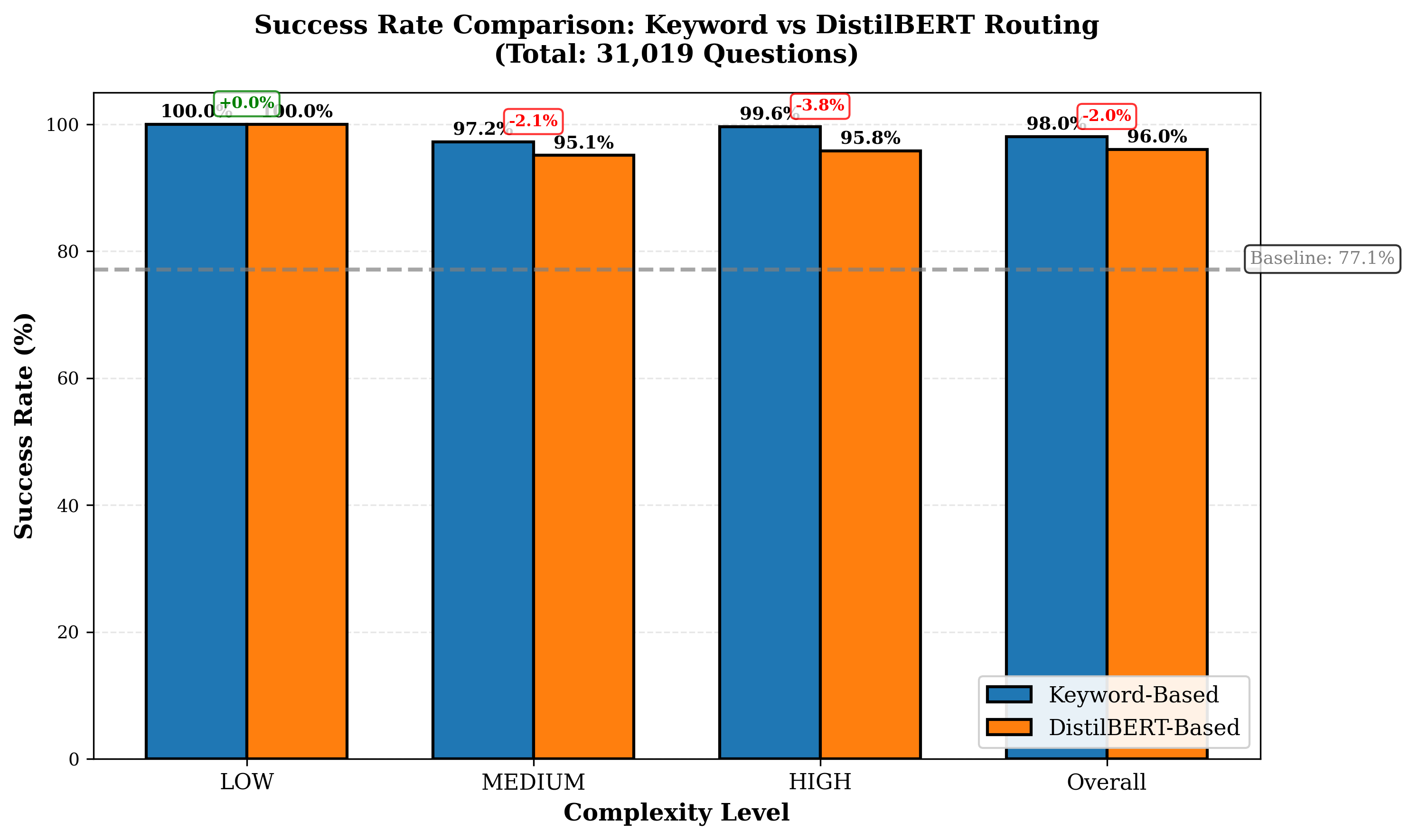
Self-hosting large language models (LLMs) is increasingly appealing for organizations seeking privacy, cost control, and customization. Yet deploying and maintaining in-house models poses challenges in GPU utilization, workload routing, and reliability. We introduce Pick and Spin, a practical framework that makes self-hosted LLM orchestration scalable and economical. Built on Kubernetes, it integrates a unified Helm-based deployment system, adaptive scale-to-zero automation, and a hybrid routing module that balances cost, latency, and accuracy using both keyword heuristics and a lightweight DistilBERT classifier. We evaluate four models, Llama-3 (90B), Gemma-3 (27B), Qwen-3 (235B), and DeepSeek-R1 (685B) across eight public benchmark datasets, with five inference strategies, and two routing variants encompassing 31,019 prompts and 163,720 inference runs. Pick and Spin achieves up to 21.6% higher success rates, 30% lower latency, and 33% lower GPU cost per query compared with static deployments of the same models.
Large language models (LLMs) are rapidly transforming applications across domains. Instead of relying on a single general purpose model for all tasks, both research and industry are moving toward a diverse ecosystem of domain tuned models. These specialized models, trained for fields such as scientific research, finance, law, and healthcare, provide greater precision and contextual understanding within their respective areas. However, this specialization also introduces new challenges. Organizations must decide not only which model to use between general purpose and fine tuned variants but also how to deploy and manage them efficiently while maintaining data privacy and minimizing computational cost.
This challenge has led to what can be described as the self hosting dilemma. On one side, relying on commercial APIs from providers such as OpenAI, Gemini, or Claude simplifies deployment but introduces vendor lock in, unpredictable costs, and data exposure risks that are unacceptable in sensitive domains such as healthcare, finance, or the life sciences (AI 2023). On the other side, self hosting preserves privacy and institutional control but comes with operational burdens. Static, always on deployments keep GPUs active even when idle, wasting resources and increasing energy consumption and maintenance overhead (Nguyen 2025).
Although domain tuned or distilled large language models (DT-LLMs) improve efficiency for specific use cases, they remain optimized for narrow objectives and cannot generalize to all query types. In practical applications, prompts vary widely, some require reasoning, others summarization or factual recall. No single model performs best across all these dimensions in there respective domains. For example, a model fine tuned for reasoning may perform poorly on summarization or fact retrieval. This diversity creates a key challenge in managing multiple models so that each input is served by the most suitable one without wasting computational resources or increasing latency.
The open source ecosystem, enabled by initiatives such as LLaMA and OPT, has made high quality model weights widely available. However, efficient and affordable deployment of these models remains difficult. Each model behaves differently across tasks, and their varying computational requirements make selection and scheduling complex. Organizations must balance accuracy, responsiveness, and cost, particularly when operating within private or resource constrained environments. These challenges motivate the need for an automated system that can both select the right model for each prompt and allocate resources intelligently
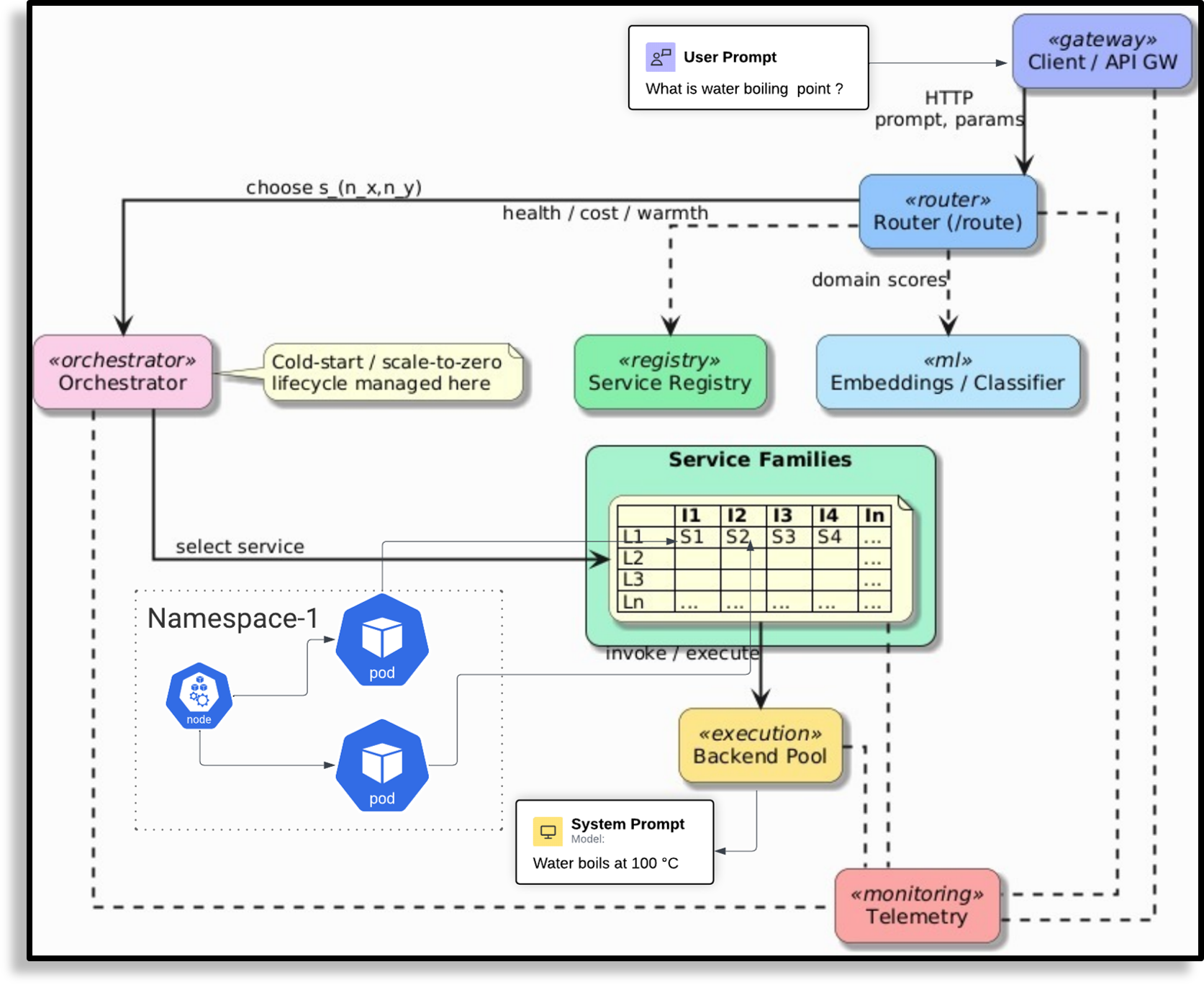
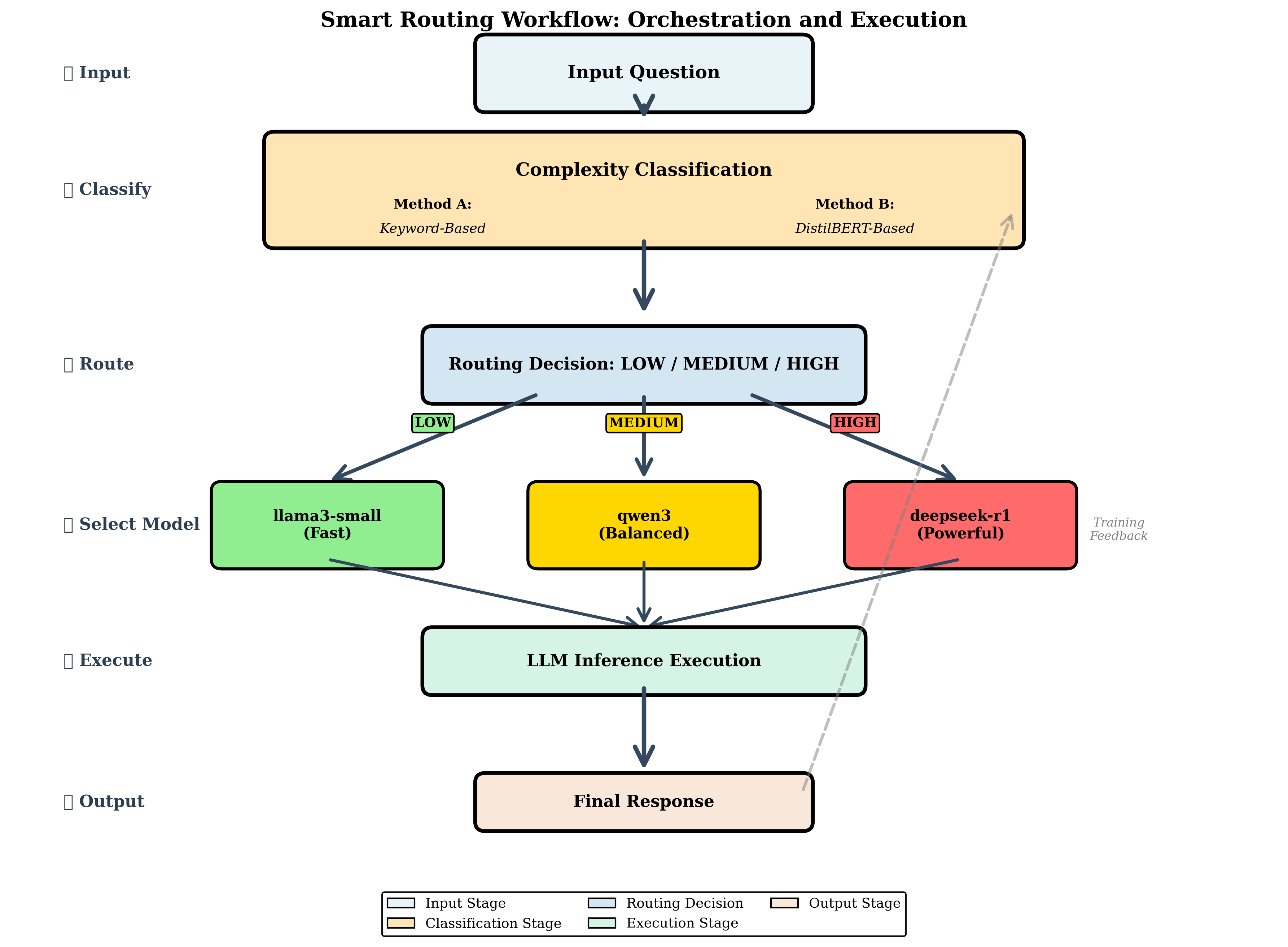
In this context, orchestration refers to the automated coordination of models and computational resources. It involves deciding which model to invoke, when to start or stop it, and how to allocate GPUs efficiently. Prior work in distributed systems defines orchestration as the automation and optimization of workflows to ensure scalability and reliability (Burns et al. 2016;Verma et al. 2015). Extending this principle to multi model inference enables a balance between accuracy, latency, and cost. Instead of keeping all models continuously active, the orchestrator routes simple queries to lightweight models and reserves larger ones for complex tasks. Idle models are scaled to zero, ensuring that GPU resources are used only when needed.
Existing research on model serving (Crankshaw et al. 2017), autoscaling (Baylor et al. 2017;Nguyen 2025), and serverless inference (Yu et al. 2022;Wang 2024) focuses on specific parts of the orchestration pipeline but does not provide an integrated solution. These systems improve efficiency within individual layers such as inference scheduling or container scaling, yet they do not coordinate model selection and resource allocation together. Tools like Helm (Contributors 2019) and Knative extend Kubernetes with declarative configuration and event driven scaling, offering strong primitives for deployment automation. However, they lack mechanisms for task aware routing or model level coordination, which are essential for managing multiple language models under shared infrastructure.
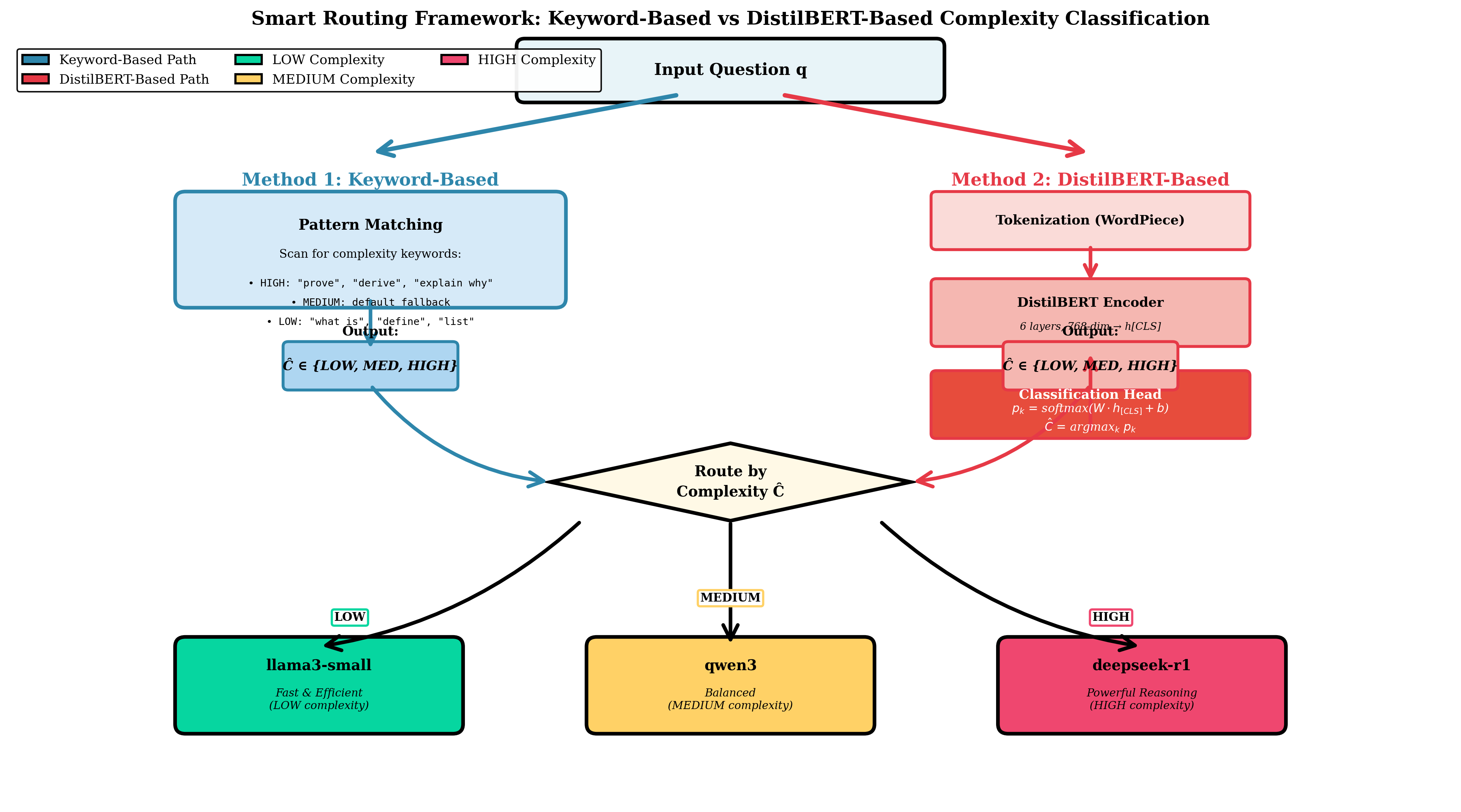
To address this gap, we propose Pick and Spin (PS), a multi model orchestration framework that integrates intelligent routing with orchestration aware scaling. The system’s name encapsulates its dual nature: Pick represents the intelligent routing layer that selects optimal models based on prompt complexity, while Spin represents the dynamic orchestration layer that manages model lifecycles, spinning resources up on demand and down when idle. PS formulates orchestration as a joint optimization problem balancing three objectives: model relevance, latency, and cost. A lightweight routing layer selects the best model for each query using rule based and semantic (DistilBERT) classifiers that estimate prompt complexity and intent. The orchestration layer manages model activation and deactivation usi
This content is AI-processed based on open access ArXiv data.