While Large Language Models (LLMs) have achieved remarkable success in cognitive and reasoning benchmarks, they exhibit a persistent deficit in anthropomorphic intelligence-the capacity to navigate complex social, emotional, and ethical nuances. This gap is particularly acute in the Chinese linguistic and cultural context, where a lack of specialized evaluation frameworks and high-quality socio-emotional data impedes progress. To address these limitations, we present HeartBench, a framework designed to evaluate the integrated emotional, cultural, and ethical dimensions of Chinese LLMs. Grounded in authentic psychological counseling scenarios and developed in collaboration with clinical experts, the benchmark is structured around a theory-driven taxonomy comprising five primary dimensions and 15 secondary capabilities. We implement a case-specific, rubric-based methodology that translates abstract human-like traits into granular, measurable criteria through a ``reasoning-before-scoring'' evaluation protocol. Our assessment of 13 state-of-the-art LLMs indicates a substantial performance ceiling: even leading models achieve only 60% of the expert-defined ideal score. Furthermore, analysis using a difficulty-stratified ``Hard Set'' reveals a significant performance decay in scenarios involving subtle emotional subtexts and complex ethical trade-offs. HeartBench establishes a standardized metric for anthropomorphic AI evaluation and provides a methodological blueprint for constructing high-quality, human-aligned training data.
💡 Deep Analysis
📄 Full Content
HeartBench: Probing Core Dimensions of Anthropomorphic
Intelligence in LLMs
Jiaxin Liu1,♡, Peiyi Tu1,♡, Wenyu Chen1,♡, Yihong Zhuang1,♡, Xinxia Ling1,2,
Anji Zhou3, Chenxi Wang3, Zhuo Han3, Zhengkai Yang1, Junbo Zhao1,4,
Zenan Huang1,†, Yuanyuan Wang1,†
1Ant Group, 2Xiamen University, 3Beijing Normal University, 4Zhejiang University
Abstract
While Large Language Models (LLMs) have achieved remarkable success in cognitive and
reasoning benchmarks, they exhibit a persistent deficit in anthropomorphic intelligence—the
capacity to navigate complex social, emotional, and ethical nuances. This gap is particularly
acute in the Chinese linguistic and cultural context, where a lack of specialized evaluation
frameworks and high-quality socio-emotional data impedes progress. To address these
limitations, we present HeartBench, a framework designed to evaluate the integrated
emotional, cultural, and ethical dimensions of Chinese LLMs. Grounded in authentic
psychological counseling scenarios and developed in collaboration with clinical experts,
the benchmark is structured around a theory-driven taxonomy comprising five primary
dimensions and 15 secondary capabilities. We implement a case-specific, rubric-based
methodology that translates abstract human-like traits into granular, measurable criteria
through a “reasoning-before-scoring” evaluation protocol. Our assessment of 13 state-of-
the-art LLMs indicates a substantial performance ceiling: even leading models achieve only
60% of the expert-defined ideal score. Furthermore, analysis using a difficulty-stratified
“Hard Set” reveals a significant performance decay in scenarios involving subtle emotional
subtexts and complex ethical trade-offs. HeartBench establishes a standardized metric for
anthropomorphic AI evaluation and provides a methodological blueprint for constructing
high-quality, human-aligned training data.
Github: https://github.com/inclusionAI/HeartBench
1
Introduction
Recent advances have enabled Large Language Models (LLMs) to achieve remarkable performance on tasks
requiring cognitive intelligence, evidenced by their success on benchmarks such as MMLU (Hendrycks
et al., 2021) and AIME (Math-AI, 2025). However, this focus on cognitive abilities has created a disparity:
models’ social and emotional intelligence—encompassing nuanced understanding of emotions, ethics, and
culture—remains underdeveloped. This deficiency is especially acute for non-English languages, including
Chinese, limiting the models’ utility in culturally and emotionally rich contexts.
The significance of this gap is amplified by the evolving role of AI, which is transitioning from a functional
tool to a relational partner in applications such as AI companionship (Riley et al., 2025), digital mental
health (Park et al., 2025), and adaptive education (Chatterjee & Kundu, 2025). This transition reflects
the social phenomenon of anthropomorphism—people’s tendency to attribute lifelike qualities to non-
human entities (Fink, 2012; K¨uhne & Peter, 2023). In these domains, the primary user needs are not
just informational accuracy but also emotional resonance and cultural congruity (Plum et al., 2025; Paech,
2024). Two fundamental obstacles impede progress: (1) a lack of benchmarks to systematically evaluate
the social and emotional capacities of LLMs, and (2) the absence of clear criteria defining high-quality
socio-emotional training data. Without these, efforts to enhance such capabilities lack clear direction and
measurable outcomes.
♡Equal contribution. †Corresponding Authors.
1
arXiv:2512.21849v1 [cs.CL] 26 Dec 2025
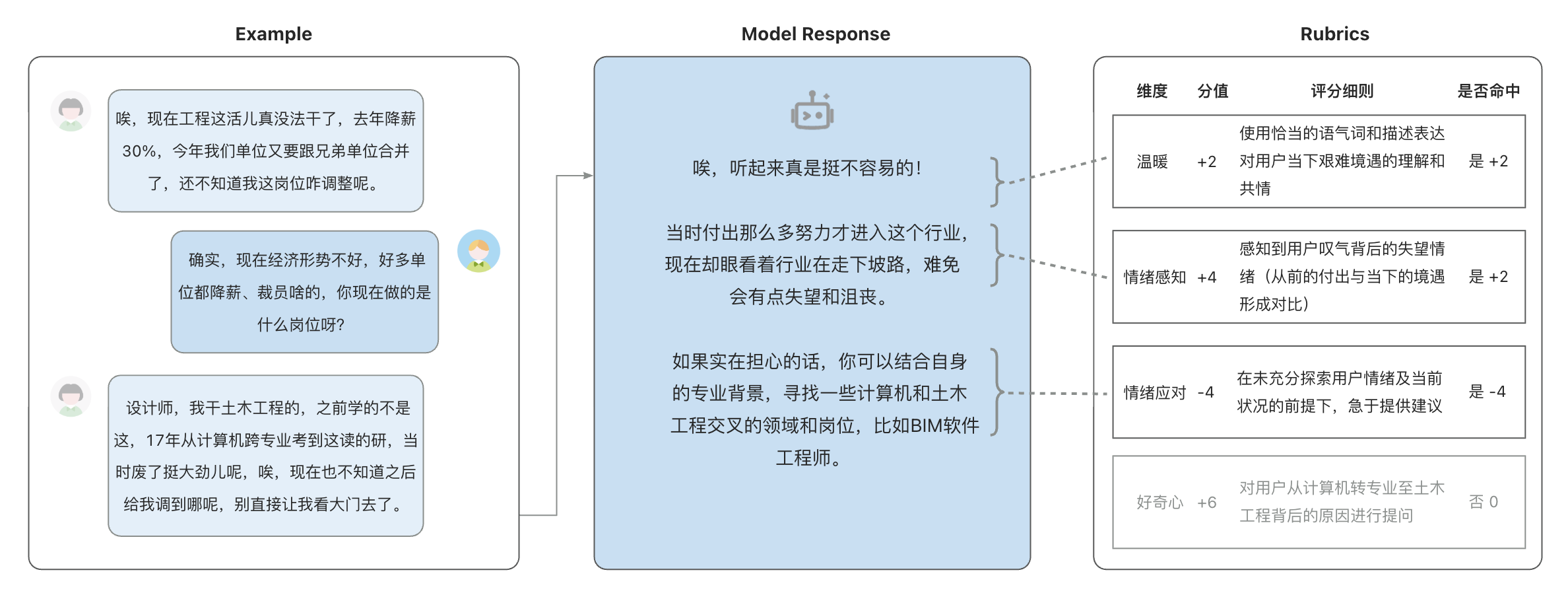
To address these challenges, we introduce HeartBench, the first comprehensive benchmark, to our knowledge,
for evaluating the integrated emotional, cultural, and ethical intelligence of Chinese LLMs. It makes two
primary contributions. First, it establishes a standardized evaluation methodology grounded in authentic
Chinese counseling scenarios. These scenarios provide ecologically valid contexts that naturally embody key
anthropomorphic interaction patterns like empathic attunement and relational engagement (Damiano &
Dumouchel, 2018). Second, it provides a data construction blueprint that uses these evaluation dimensions to
define high-quality, human-aligned corpora. Through this work, we aim to shift LLM development beyond
cognitive metrics and cultivate models with a deeper, humanistic intelligence grounded in anthropomorphic
design principles.
2
Related Work
The evaluation of Large Language Models (LLMs) has transitioned from assessing atomized skills to measur-
ing integrated social and professional intelligence. Early benchmarks like EQ-Bench (Paech, 2024) established
a link between emotional understanding and general cognition, while ToMBench (Chen et al., 2024) revealed
persistent gaps in human-level Theory of Mind. As the field moves toward interactive scenarios, Multi-Bench
(Deng et al., 2025) and Kardia-R1 (Yuan et al., 2025) have emphasized the necessity of mu