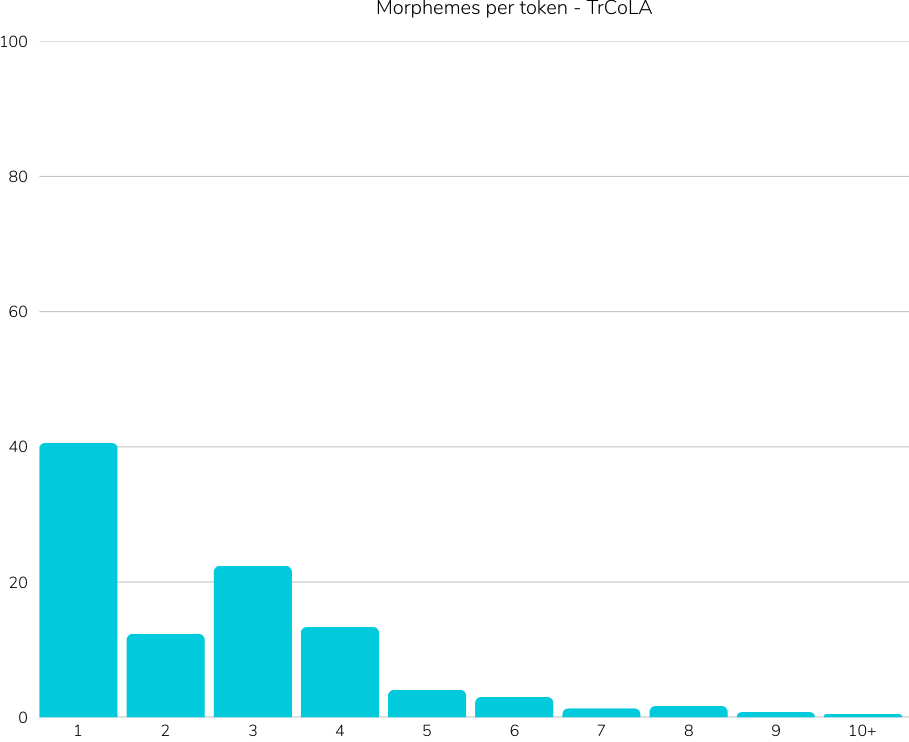
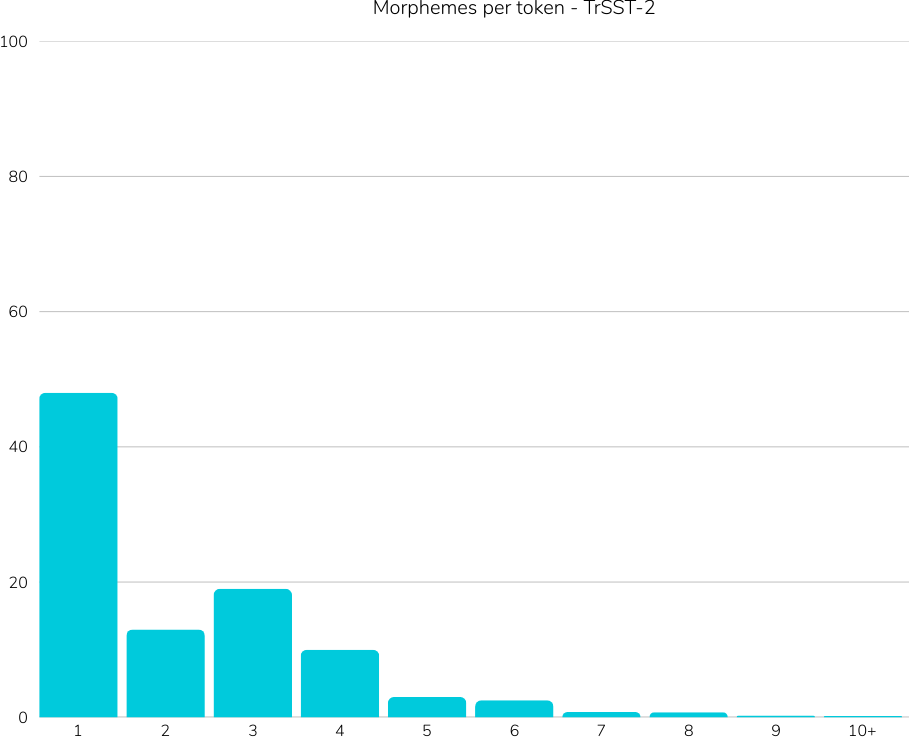
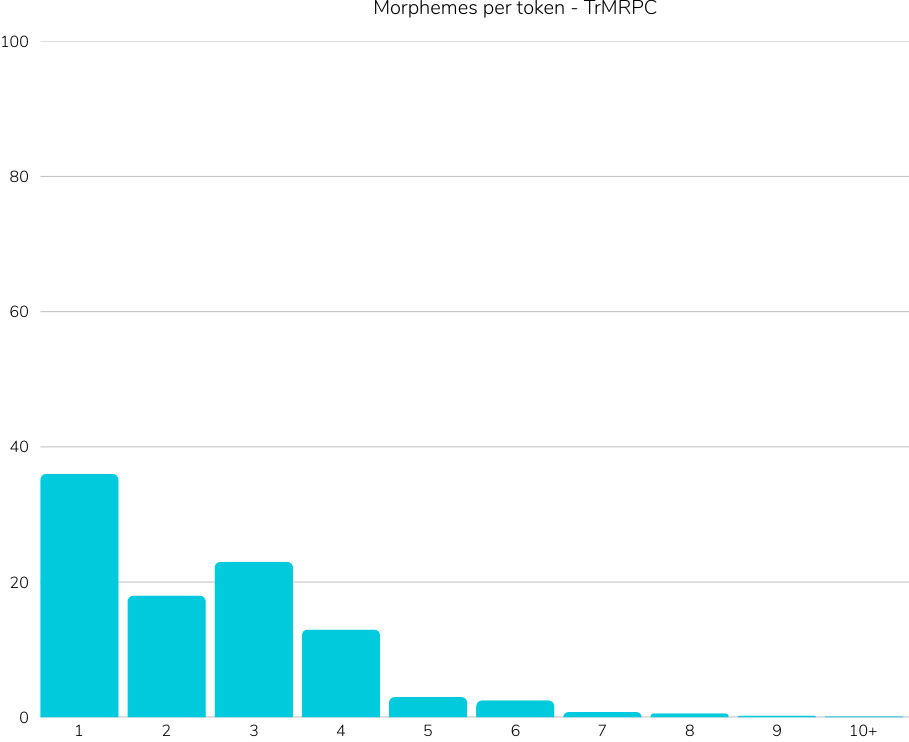
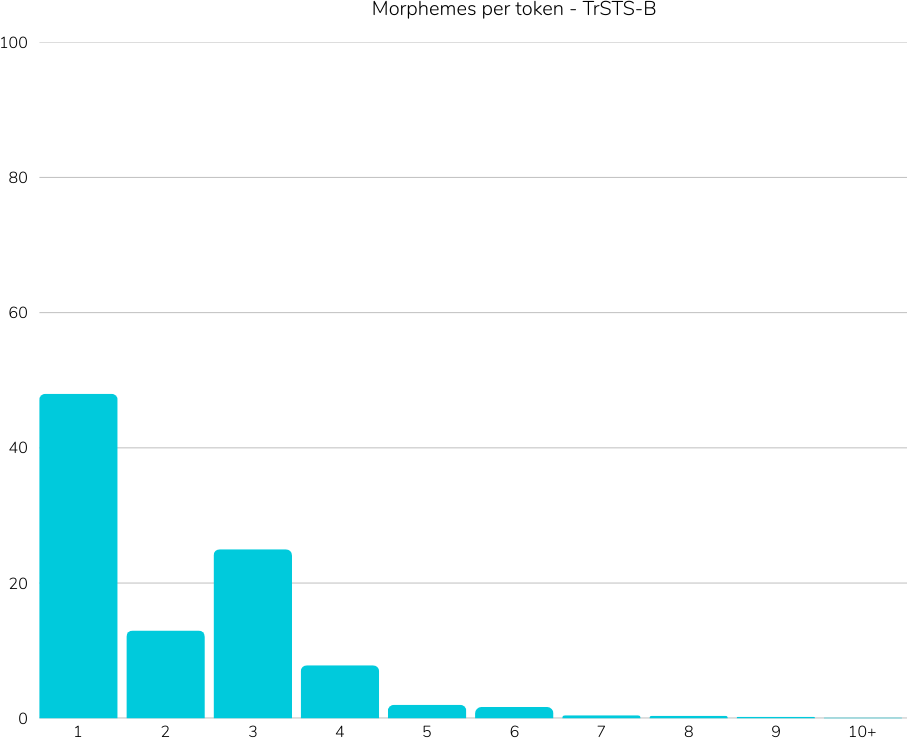
Title: Introducing TrGLUE and SentiTurca: A Comprehensive Benchmark for Turkish General Language Understanding and Sentiment Analysis
ArXiv ID: 2512.22100
Date: 2025-12-26
Authors: Duygu Altinok
📝 Abstract
Evaluating the performance of various model architectures, such as transformers, large language models (LLMs), and other NLP systems, requires comprehensive benchmarks that measure performance across multiple dimensions. Among these, the evaluation of natural language understanding (NLU) is particularly critical as it serves as a fundamental criterion for assessing model capabilities. Thus, it is essential to establish benchmarks that enable thorough evaluation and analysis of NLU abilities from diverse perspectives. While the GLUE benchmark has set a standard for evaluating English NLU, similar benchmarks have been developed for other languages, such as CLUE for Chinese, FLUE for French, and JGLUE for Japanese. However, no comparable benchmark currently exists for the Turkish language. To address this gap, we introduce TrGLUE, a comprehensive benchmark encompassing a variety of NLU tasks for Turkish. In addition, we present SentiTurca, a specialized benchmark for sentiment analysis. To support researchers, we also provide fine-tuning and evaluation code for transformer-based models, facilitating the effective use of these benchmarks. TrGLUE comprises Turkish-native corpora curated to mirror the domains and task formulations of GLUE-style evaluations, with labels obtained through a semi-automated pipeline that combines strong LLM-based annotation, cross-model agreement checks, and subsequent human validation. This design prioritizes linguistic naturalness, minimizes direct translation artifacts, and yields a scalable, reproducible workflow. With TrGLUE, our goal is to establish a robust evaluation framework for Turkish NLU, empower researchers with valuable resources, and provide insights into generating high-quality semi-automated datasets.
💡 Deep Analysis
📄 Full Content
Introducing TrGLUE and SentiTurca: A
Comprehensive Benchmark for Turkish General
Language Understanding and Sentiment Analysis
Duygu Altinok
Independent Researcher, Berlin, Germany.
Contributing authors: duygu@turkish-nlp-suite.com;
Abstract
Evaluating the performance of various model architectures, such as transformers,
large language models (LLMs), and other NLP systems, requires comprehen-
sive benchmarks that measure performance across multiple dimensions. Among
these, the evaluation of natural language understanding (NLU) is particularly
critical as it serves as a fundamental criterion for assessing model capabilities.
Thus, it is essential to establish benchmarks that enable thorough evalua-
tion and analysis of NLU abilities from diverse perspectives. While the GLUE
benchmark has set a standard for evaluating English NLU, similar benchmarks
have been developed for other languages, such as CLUE for Chinese, FLUE
for French, and JGLUE for Japanese. However, no comparable benchmark
currently exists for the Turkish language. To address this gap, we introduce
TrGLUE, a comprehensive benchmark encompassing a variety of NLU tasks
for Turkish. In addition, we present SentiTurca, a specialized benchmark for
sentiment analysis. To support researchers, we also provide fine-tuning and eval-
uation code for transformer-based models, facilitating the effective use of these
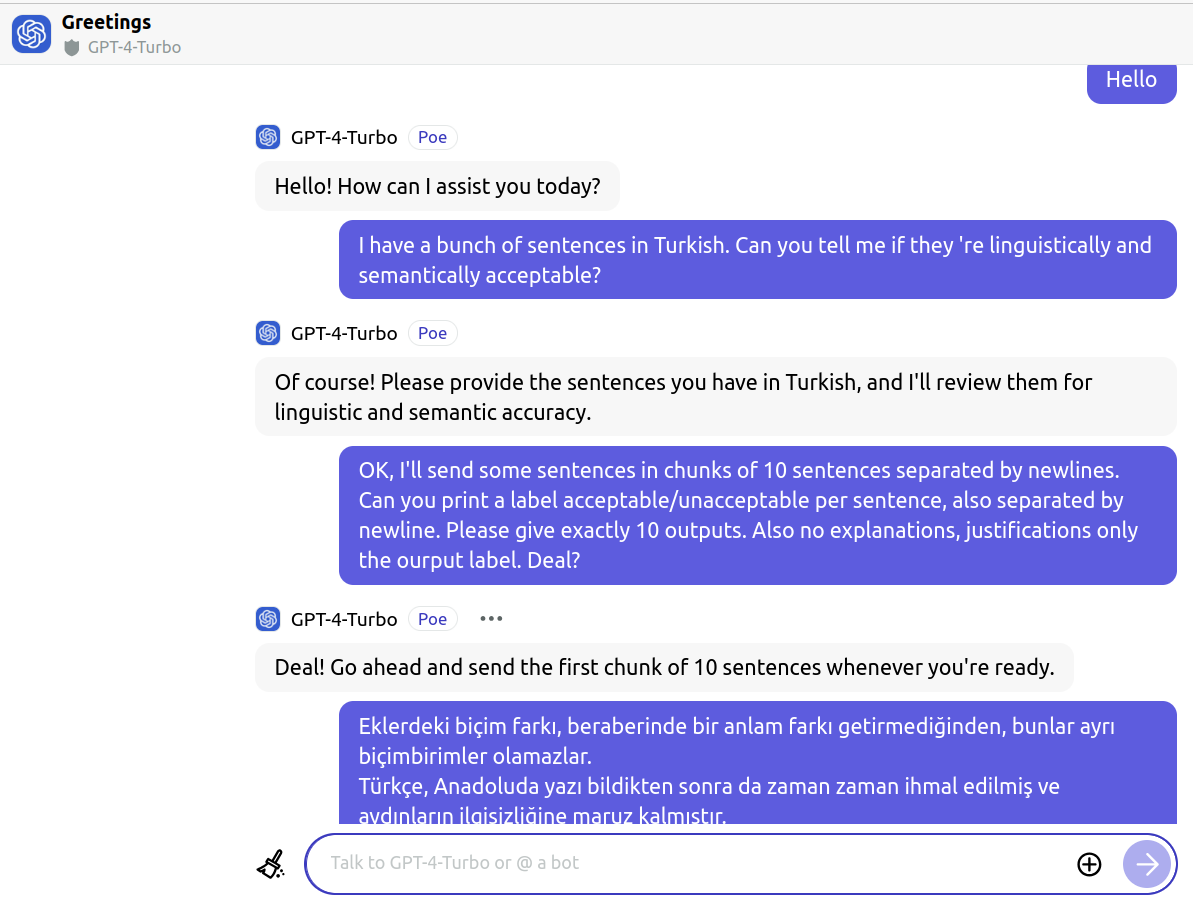
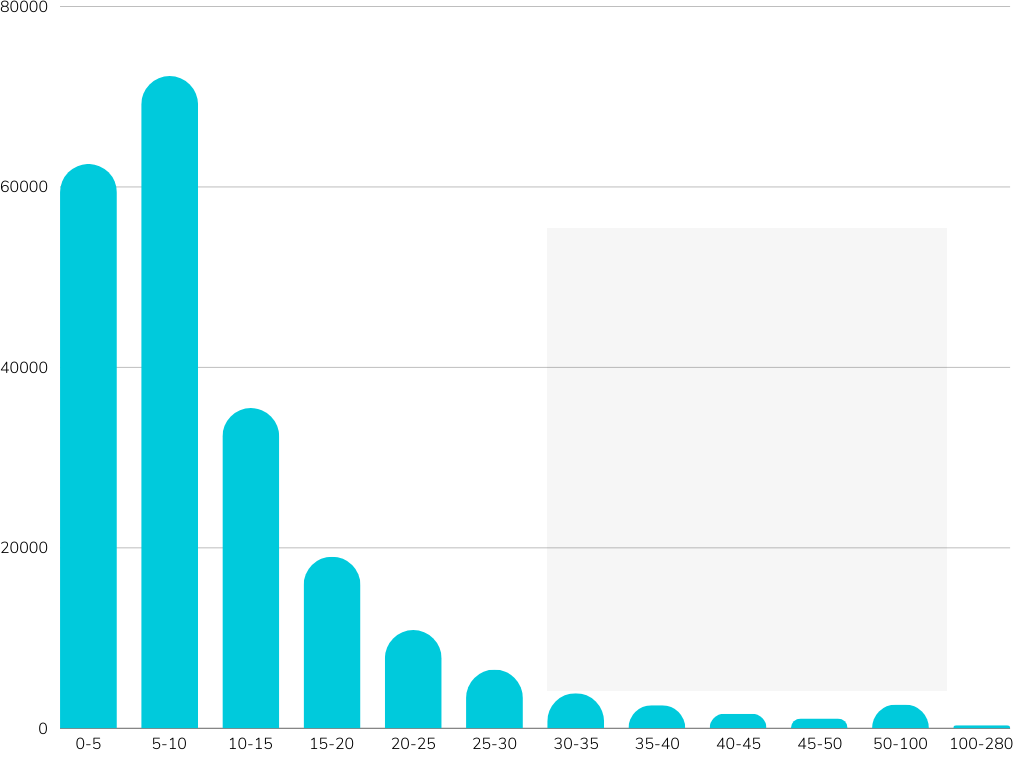
benchmarks. TrGLUE comprises Turkish-native corpora curated to mirror the
domains and task formulations of GLUE-style evaluations, with labels obtained
through a semi-automated pipeline that combines strong LLM-based annotation,
cross-model agreement checks, and subsequent human validation. This design pri-
oritizes linguistic naturalness, minimizes direct translation artifacts, and yields
a scalable, reproducible workflow. With TrGLUE, our goal is to establish a
robust evaluation framework for Turkish NLU, empower researchers with valu-
able resources, and provide insights into generating high-quality semi-automated
datasets.
Keywords: Turkish NLU, Turkish NLU benchmark, Turkish NLI, Turkish sentiment
analysis, Turkish sentiment analysis datasets
1
arXiv:2512.22100v1 [cs.CL] 26 Dec 2025
1 Introduction
Given the advancements in transformer models, such as BERT [1] and large language
models (LLMs) [2], it has become essential to benchmark these models from various
perspectives. Evaluating natural language understanding (NLU) is particularly impor-
tant, and having a benchmark for evaluating and analyzing NLU abilities is crucial.
The General Language Understanding Evaluation (GLUE) benchmark [3] has been
widely used for English. However, benchmarks for languages other than English have
also been developed, including CLUE for Chinese [4], FLUE for French [5], JGLUE
for Japanese [6], and KLUE for Korean [7].
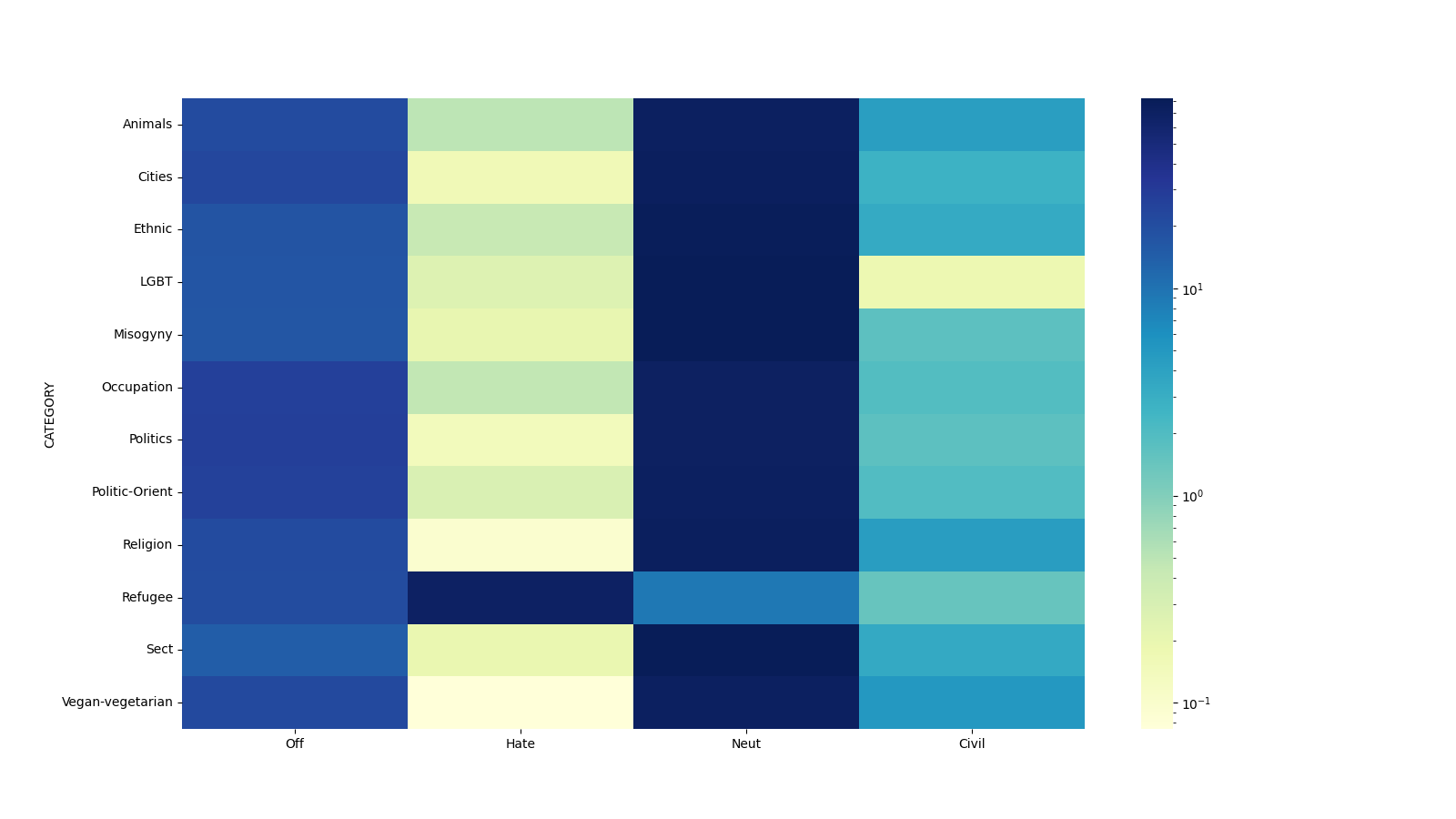
In the case of Turkish, several datasets have been created for tasks like text classifi-
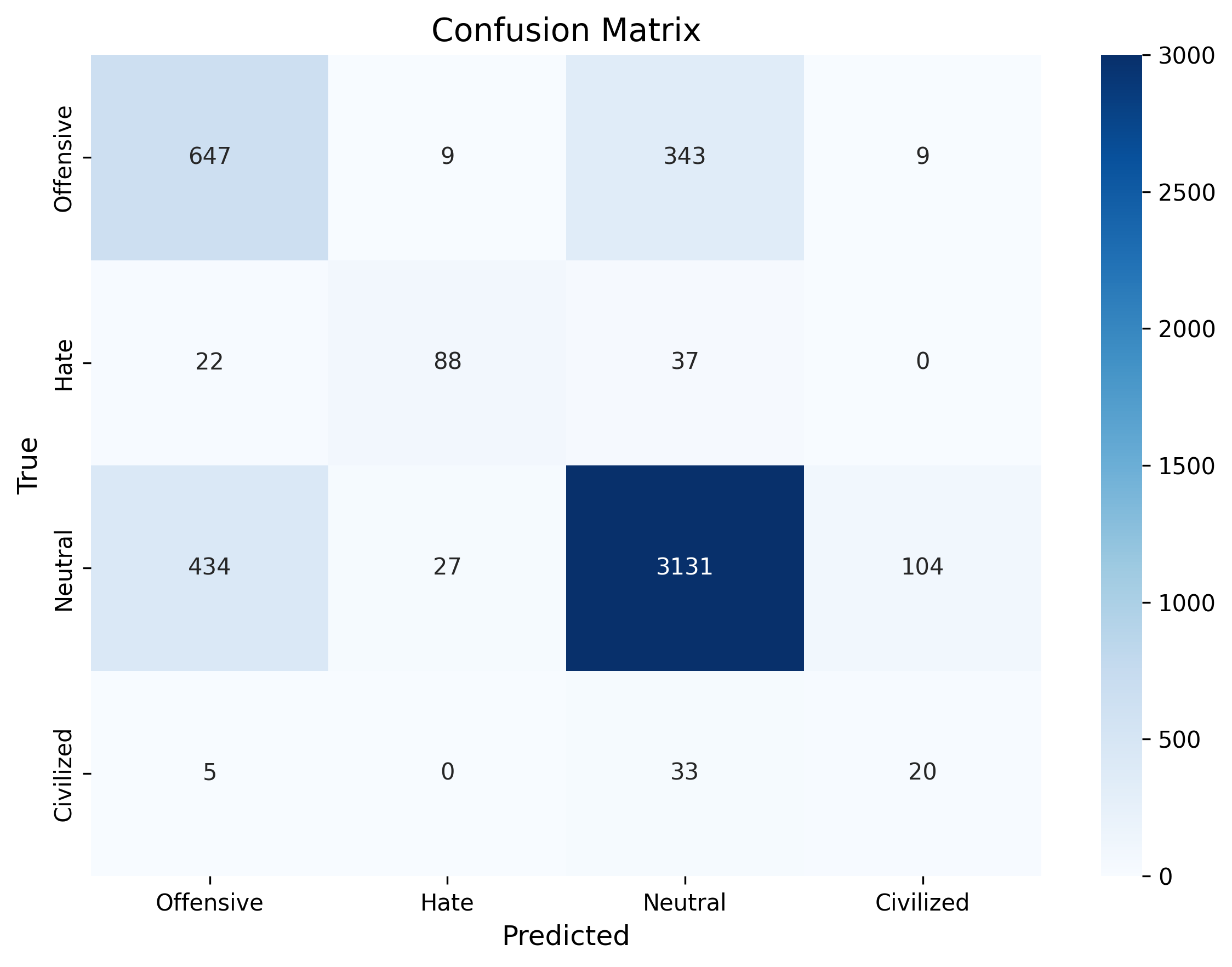
cation, sentiment analysis [8], and hate speech [9]. However, there is a lack of datasets
for paraphrase, similarity, and inference tasks, with the exception of a Semantic Tex-
tual Similarity (STS) dataset translated by Beken et al. [10]. As a result, there is
currently no standard NLU benchmark for Turkish, and the existing datasets are scat-
tered and not comprehensive. To address this gap, we have developed a centralized
and easily accessible benchmark called TrGLUE, which is hosted on Hugging Face.
Despite the availability of transformer models like BERTurk [11] and even some
LLMs, there is a scarcity of training and evaluation datasets in Turkish. Most models
are trained on OSCAR [12, 13] and/or mC4 corpora [14], which lack variability, and
the situation is even worse for evaluation datasets. BERTurk has been evaluated in
limited areas such as sequence classification, named entity recognition (NER), part-
of-speech (POS) tagging, and question answering. However, there is little information
available about the construction process or corpus statistics of the question answering
dataset used by BERTurk.
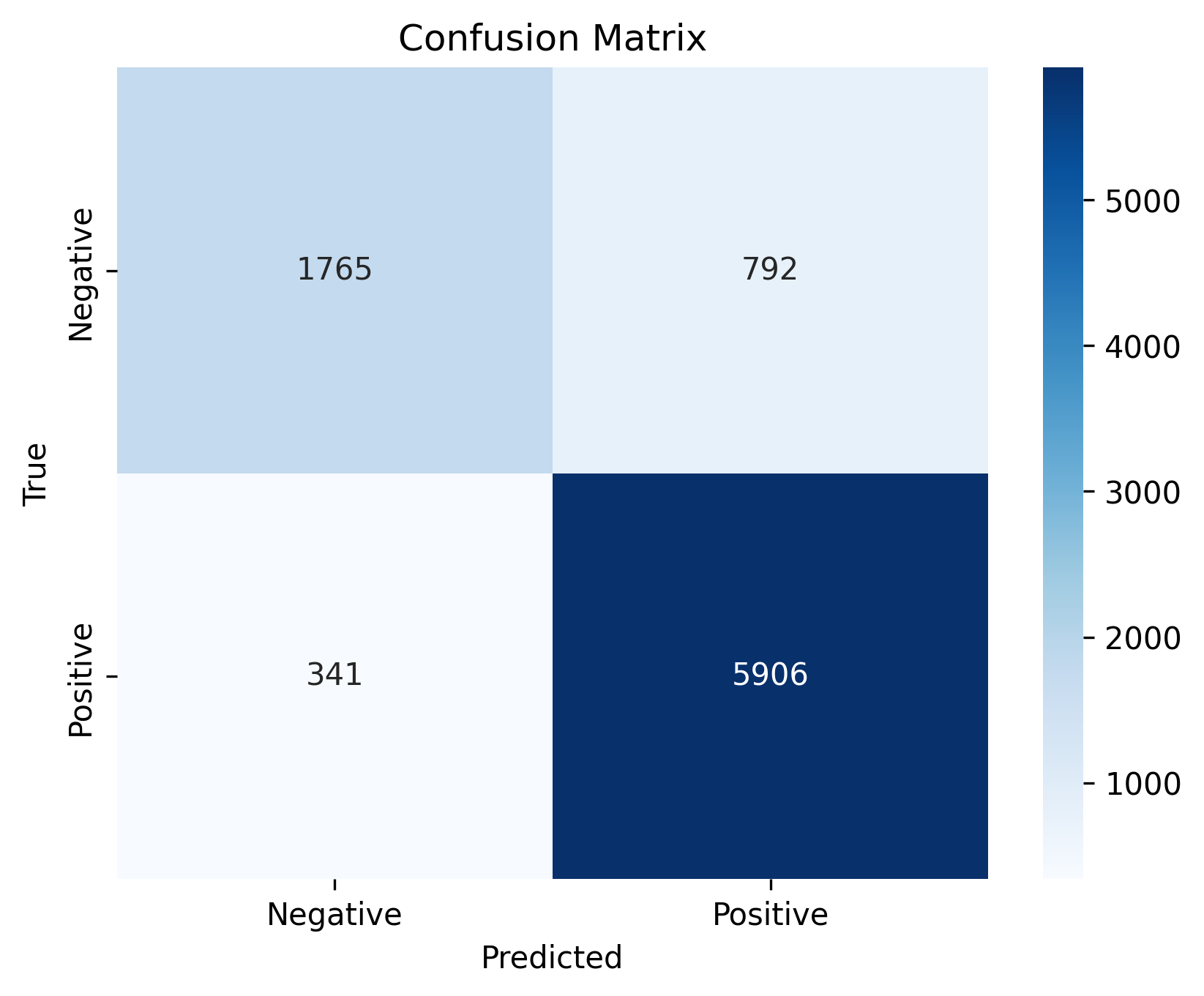
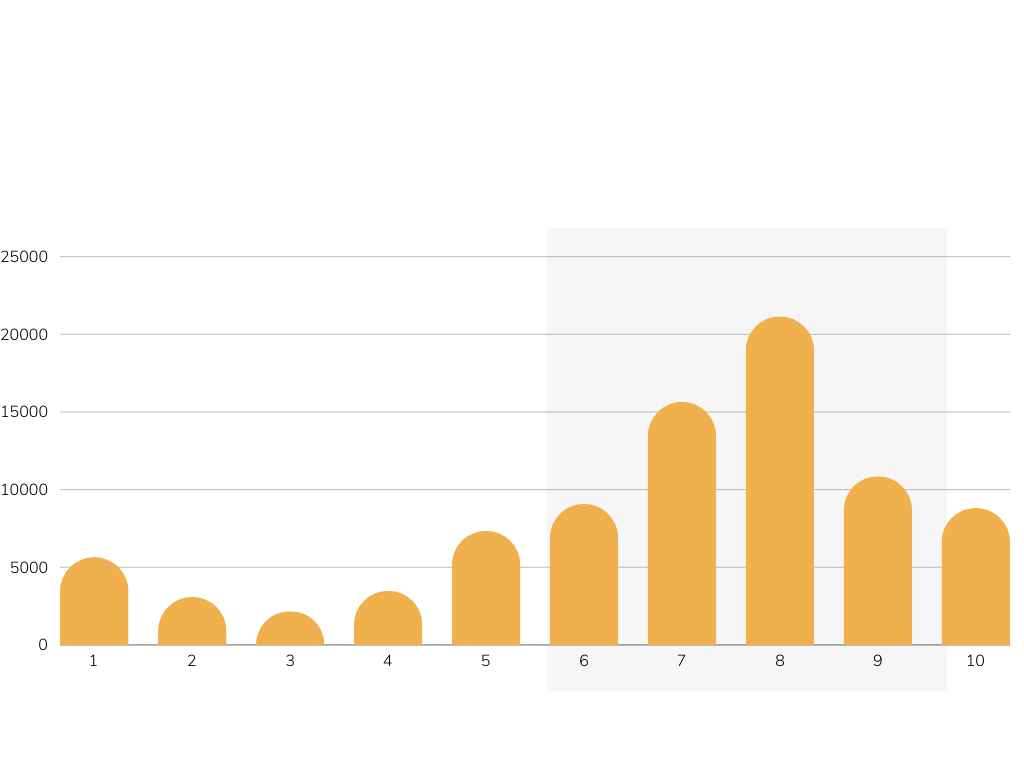
Existing evaluations in the field lack comprehensive coverage and reproducibility,
either focusing superficially on a few dimensions or relying on local datasets that are
not shared. Moreover, the absence of a standardized benchmarking dataset for Turkish
creates challenges in comparing results across different models. Another issue is using
translations instead of building from natural text data, which introduces low-quality
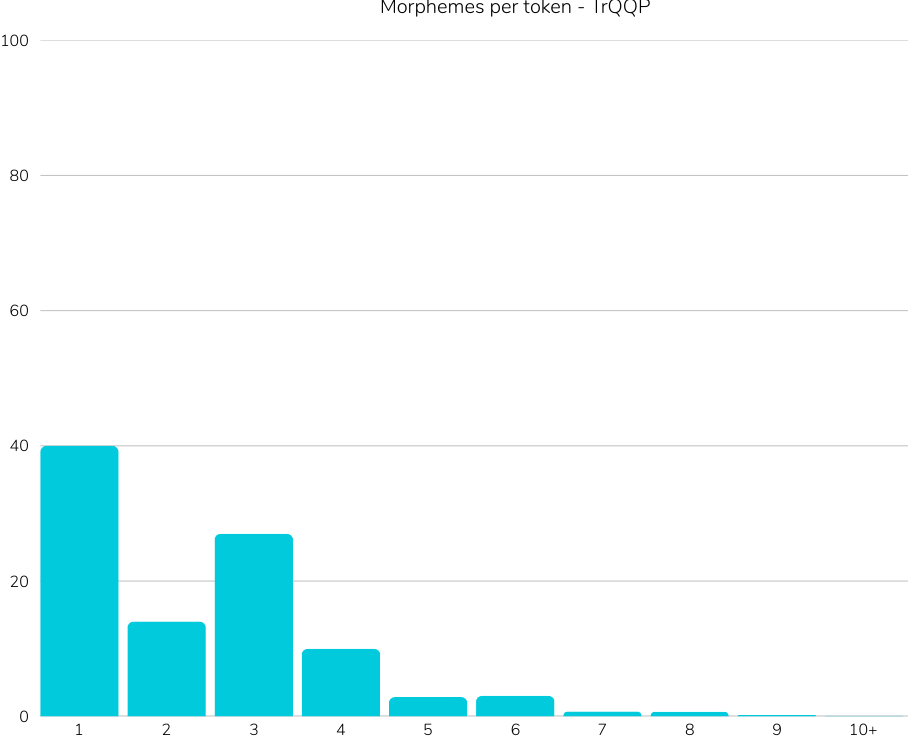
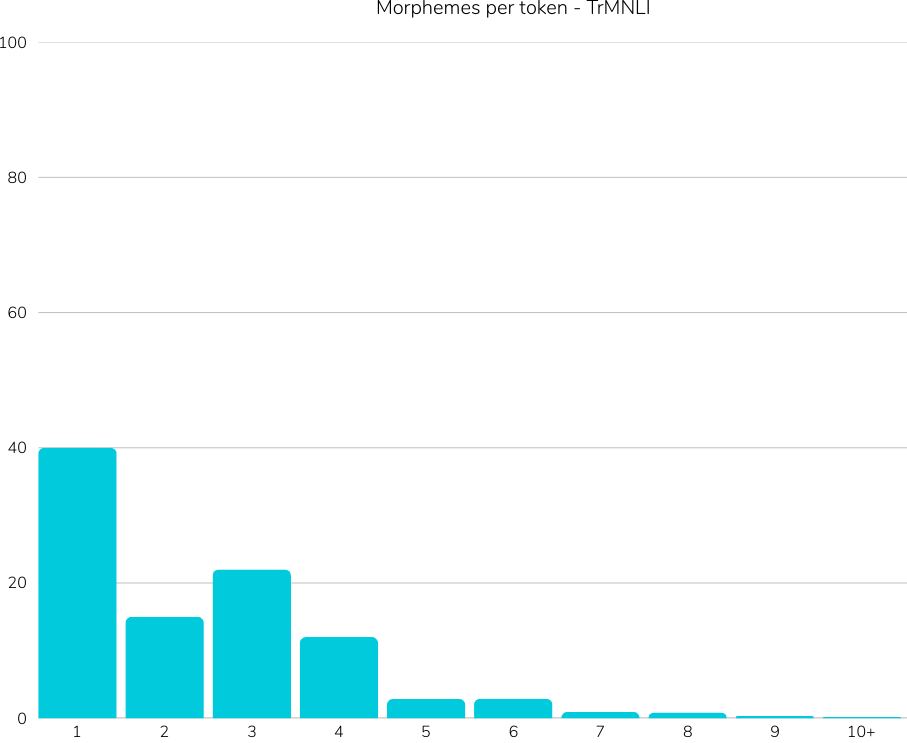
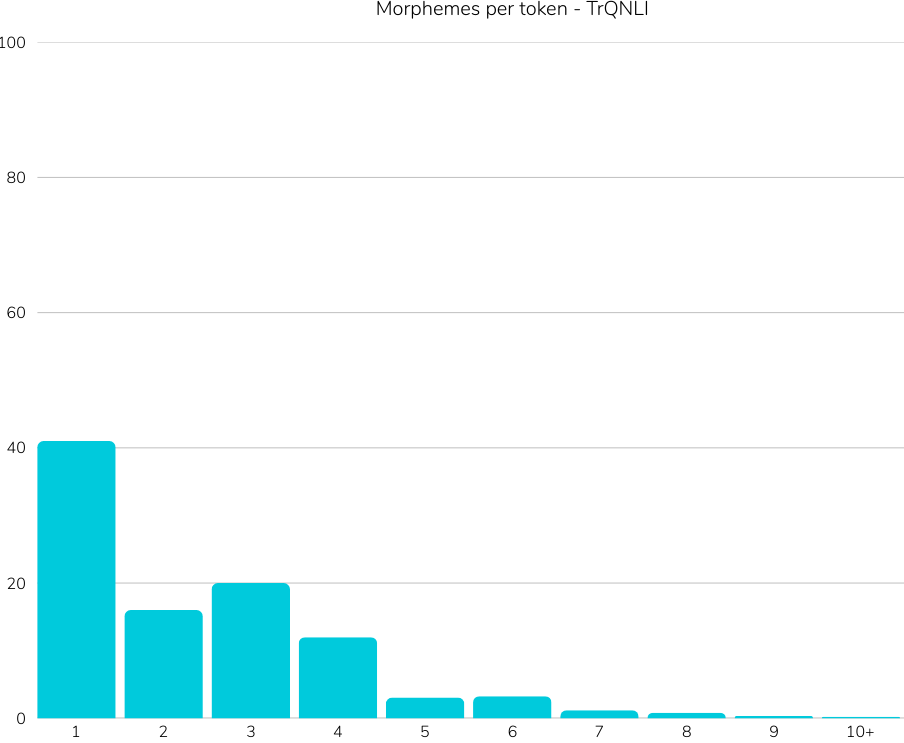
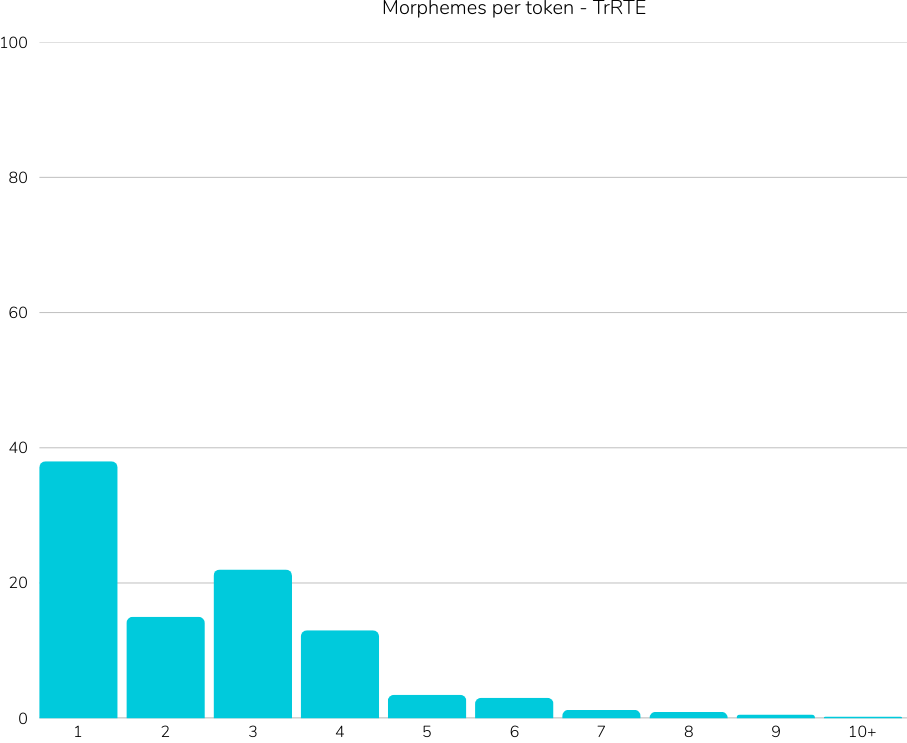
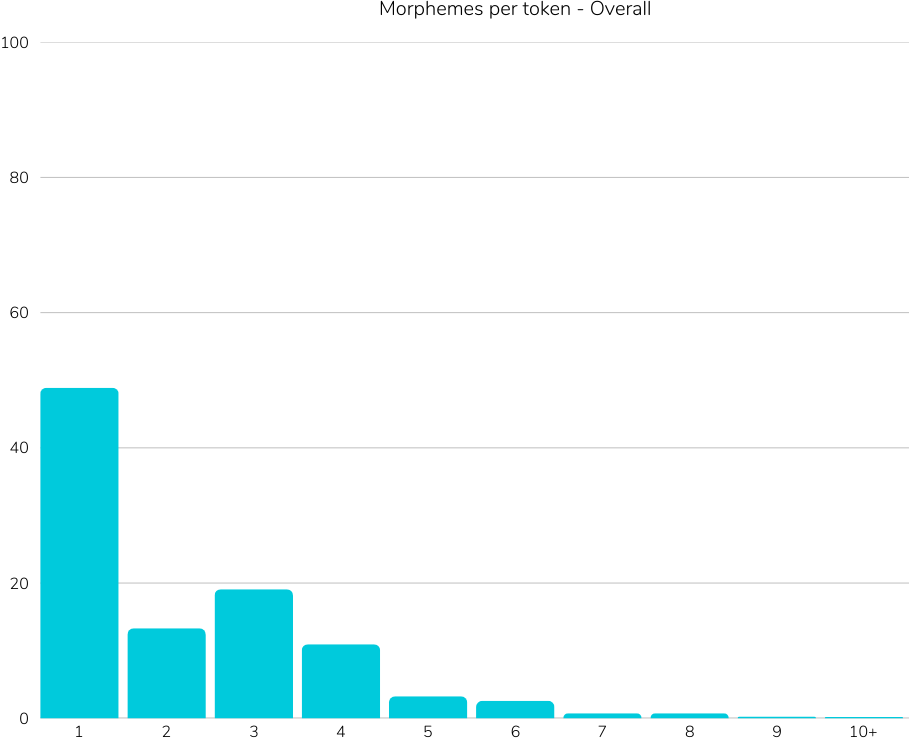
translations, cultural biases as well as not considering agglutinative nature of Turkish,
also introducing evaluation metric defects.
To address these issues, we propose the creation of the Turkish General Language
Understanding Evaluation (TrGLUE) benchmark. Similar to the widely used GLUE
benchmark for English, TrGLUE aims to establish a standardized evaluation frame-
work for Turkish NLP models. It comprises diverse tasks of text classification and
sentence pair classification, carefully designed to assess various aspects of nat