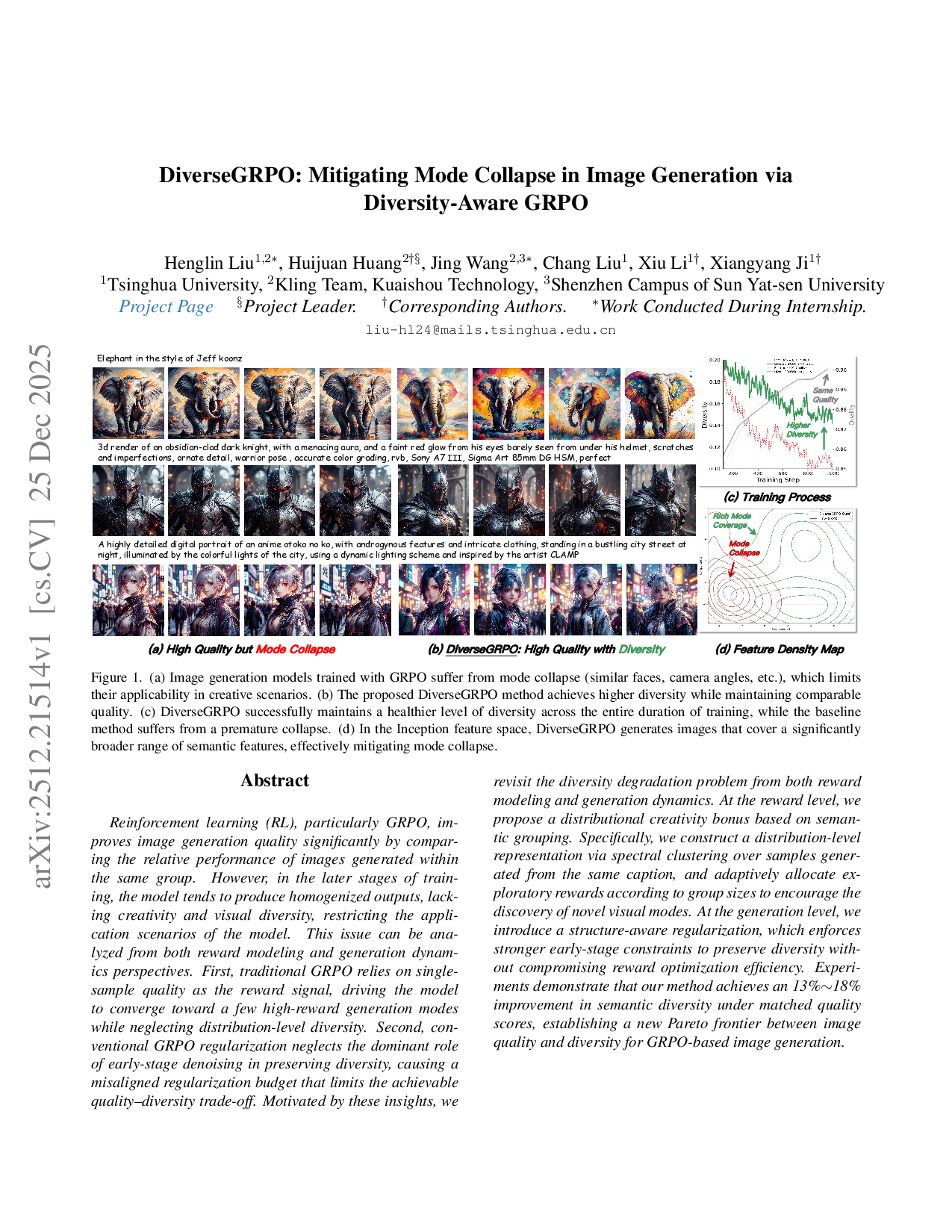
Reinforcement learning (RL), particularly GRPO, improves image generation quality significantly by comparing the relative performance of images generated within the same group. However, in the later stages of training, the model tends to produce homogenized outputs, lacking creativity and visual diversity, which restricts its application scenarios. This issue can be analyzed from both reward modeling and generation dynamics perspectives. First, traditional GRPO relies on single-sample quality as the reward signal, driving the model to converge toward a few high-reward generation modes while neglecting distribution-level diversity. Second, conventional GRPO regularization neglects the dominant role of early-stage denoising in preserving diversity, causing a misaligned regularization budget that limits the achievable quality--diversity trade-off. Motivated by these insights, we revisit the diversity degradation problem from both reward modeling and generation dynamics. At the reward level, we propose a distributional creativity bonus based on semantic grouping. Specifically, we construct a distribution-level representation via spectral clustering over samples generated from the same caption, and adaptively allocate exploratory rewards according to group sizes to encourage the discovery of novel visual modes. At the generation level, we introduce a structure-aware regularization, which enforces stronger early-stage constraints to preserve diversity without compromising reward optimization efficiency. Experiments demonstrate that our method achieves a 13\%--18\% improvement in semantic diversity under matched quality scores, establishing a new Pareto frontier between image quality and diversity for GRPO-based image generation.
Reinforcement learning (RL), particularly GRPO, improves image generation quality significantly by comparing the relative performance of images generated within the same group. However, in the later stages of training, the model tends to produce homogenized outputs, lacking creativity and visual diversity, restricting the application scenarios of the model. This issue can be analyzed from both reward modeling and generation dynamics perspectives. First, traditional GRPO relies on singlesample quality as the reward signal, driving the model to converge toward a few high-reward generation modes while neglecting distribution-level diversity. Second, conventional GRPO regularization neglects the dominant role of early-stage denoising in preserving diversity, causing a misaligned regularization budget that limits the achievable quality-diversity trade-off. Motivated by these insights, we revisit the diversity degradation problem from both reward modeling and generation dynamics. At the reward level, we propose a distributional creativity bonus based on semantic grouping. Specifically, we construct a distribution-level representation via spectral clustering over samples generated from the same caption, and adaptively allocate exploratory rewards according to group sizes to encourage the discovery of novel visual modes. At the generation level, we introduce a structure-aware regularization, which enforces stronger early-stage constraints to preserve diversity without compromising reward optimization efficiency. Experiments demonstrate that our method achieves an 13%∼18% improvement in semantic diversity under matched quality scores, establishing a new Pareto frontier between image quality and diversity for GRPO-based image generation.
The diversity of generated images is a key criterion for evaluating the performance of generative models. A significant loss of diversity represents a major challenge for the practical application, particularly in creative fields such as digital art, advertising, and game design, where novelty and variety are fundamental to their success.
However, reinforcement learning from human feedback (RLHF) [2,5] techniques for image generation [3], such as Flow-GRPO [21] and DanceGRPO [30], have achieved remarkable progress in aligning text-to-image generation models with human aesthetic preferences, recent studies [6,11,31] in large language model(LLM) have revealed a critical limitation of GRPO-based approaches: the degradation of generation diversity. As illustrated in Fig. 1, this phenomenon manifests as homogenized results (nearly identical character appearances and highly similar perspectives), indicating a collapse of semantic diversity. That is because the intrinsic objective of reward maximization tends to overfit the model to a narrow subset of high-reward modes, effectively encouraging the model to reproduce ‘safe’ or ‘high-score’ patterns while suppressing creative or unconventional outputs.
This observation raises a deeper question: Is diversity degradation an inevitable byproduct of reward optimization, or is it a symptom of misaligned learning objectives and generation dynamics?
We begin by examining the problem from the reward modeling perspective. As shown in Fig. 2.a, GRPO relies solely on single-sample reward signals, where the reward model assigns individual scores to each image without considering the relationships between samples. This approach leads the generative model to become ‘short-sighted’ and ‘conservative’, focusing on maximizing immediate rewards at the expense of exploration and innovation. To analyze this effect more formally, consider that the conditional generation distribution can be decomposed into K semantic modes:
, where each component π k θ represents a distinct visual mode (e.g., composition, lighting, or style), and w k is its mixture weight. Let the average reward within each mode be:
then the expected reward objective can be rewritten as J(θ) = K k=1 w k rk . During optimization, modes with larger average reward rk gain higher sampling probability, yielding the following replicator dynamics:
This equation describes a self-reinforcing selection process: modes with slightly higher average rewards continue to grow in weight, while others are gradually eliminated. At equilibrium, only the dominant high-reward mode survives:
Thus, single-sample reward optimization implicitly drives the model toward a unimodal distribution, leading to homogenized outputs and a collapse in visual diversity. Therefore, to prevent mode extinction, it is insufficient to adjust sampling strategies or model architectures; the reward itself must be redesigned to reshape the underlying dynamics. Instead of rewarding individual samples independently, we introduce a distribution-aware reward that depends on the semantic structure of the generated set for each prompt. Specifically, we construct a distribution-level representation via spectral clustering over samples generat
This content is AI-processed based on open access ArXiv data.