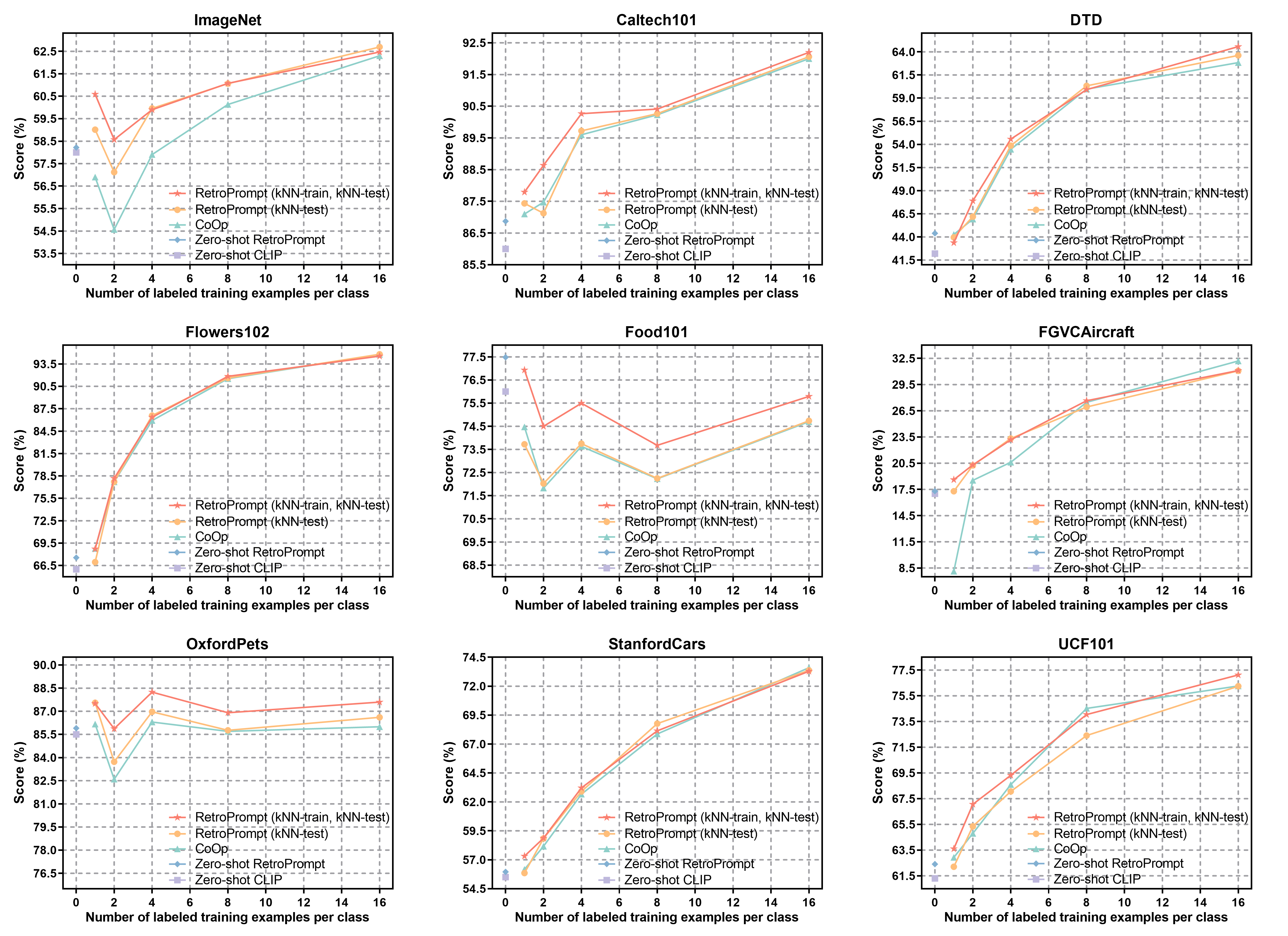
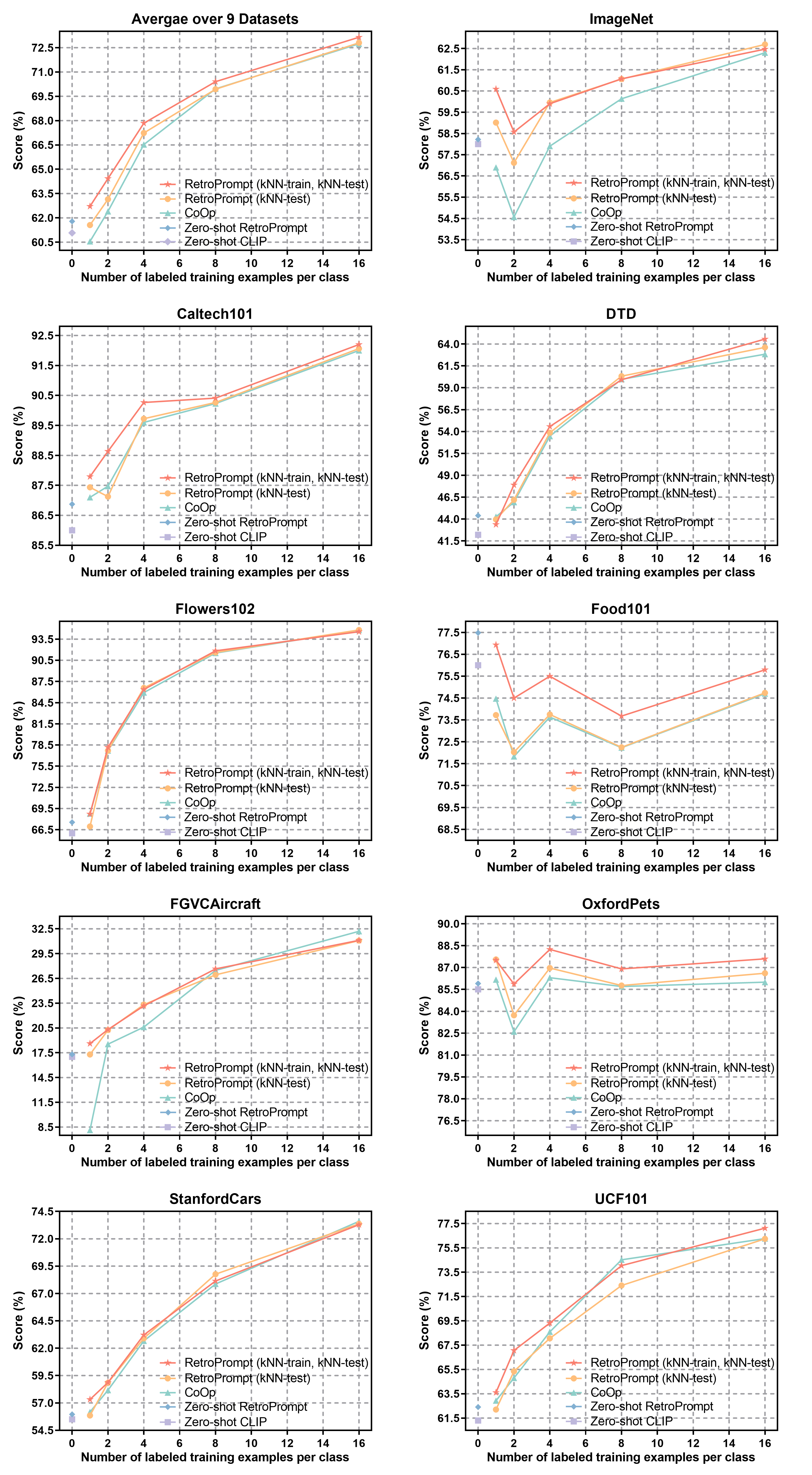
The pre-trained foundation models (PFMs) have become essential for facilitating large-scale multimodal learning. Researchers have effectively employed the ``pre-train, prompt, and predict'' paradigm through prompt learning to induce improved few-shot performance. However, prompt learning approaches for PFMs still follow a parametric learning paradigm. As such, the stability of generalization in memorization and rote learning can be compromised. More specifically, conventional prompt learning might face difficulties in fully utilizing atypical instances and avoiding overfitting to shallow patterns with limited data during the process of fully-supervised training. To overcome these constraints, we present our approach, named RetroPrompt, which aims to achieve a balance between memorization and generalization by decoupling knowledge from mere memorization. Unlike traditional prompting methods, RetroPrompt leverages a publicly accessible knowledge base generated from the training data and incorporates a retrieval mechanism throughout the input, training, and inference stages. This enables the model to actively retrieve relevant contextual information from the corpus, thereby enhancing the available cues. We conduct comprehensive experiments on a variety of datasets across natural language processing and computer vision tasks to demonstrate the superior performance of our proposed approach, RetroPrompt, in both zero-shot and few-shot scenarios. Through detailed analysis of memorization patterns, we observe that RetroPrompt effectively reduces the reliance on rote memorization, leading to enhanced generalization.
P RE-TRAINED Foundation Models (PFMs) have achieved dramatic empirical success in various of domains such as natural language processing [2], computer vision [3] and so on. Notably, large-scale parametric foundation models have acquired a substantial volume of knowledge from multimodal sources, serving as fundamental infrastructure by demonstrating remarkable abilities with the "pre-train, prompt, and predict" paradigm [4]. Prompt learning for PFMs has garnered growing research attention in recent years, based chiefly on few-shot data, for visual and language understanding. Typically, the "prompt" refers to a specific instruction or cue given to a machine learning model to guide it towards learning a specific task or to improve its performance on a specific task. For instance, in the realm of natural language processing [5], a prompt could be a sentence or phrase that provides context or specifies the type of output desired from the model; while in computer vision [3] or multimodal learning [6], a prompt can guide the representation learning to combine information from various modalities including images and text, enabling models to enhance their learning efficiency by providing them with explicit guidance on what information to attend to. To date, researchers have readily enjoyed themselves with the prompt learning for PFMs; evidence from emerging research has continuously proven its success in few-shot/zero-shot learning. However, recent investigations [7,8] have revealed that prompt learning with PFMs often exhibits unstable generalization in scenarios with extremely limited resources or emerging domains. This instability can be attributed, in part, to the inherent difficulty faced by parametric models in effectively learning rare or challenging patterns through rote memorization, ultimately leading to suboptimal generalization performance.
Prior work has established metaphors for conceptualizing the training-test procedures in prompt learning akin to closedbook examination and page-by-page memorization [9]. Specifically, conventional prompt learning faces challenges either rote memorizing atypical cases under full supervision or overfitting shallow patterns with limited data [10]. Recent research [11] provides evidence supporting the long-tail theory, which suggests that training instance often follows a long-tailed distribution characterized by small sub-populations containing rare examples, PFMs may predict through memorizing these outliers rather than generalizing patterns -indicating a reliance on rote memorization over truly learning representations. This reliance on memorization contrasts with the objective of effectively utilizing knowledge from varied instances to achieve robust generalization. Addressing such limitations motivates the proposed approach of augmenting prompting with context retrieval to balance memorization and generalization.
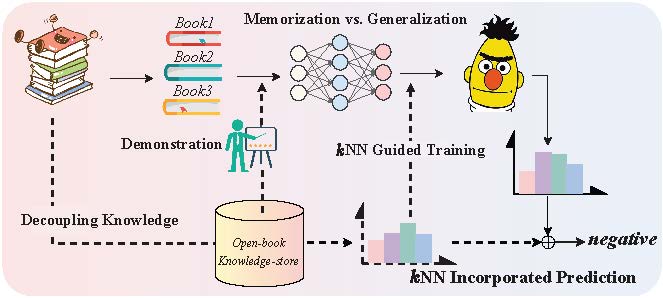
Rote memorization’s limitations encourage us to seek in-Fig. 1: Decoupling knowledge from memorization. To achieve a harmonious balance between generalization and memorization in prompt learning, we put forward a method that separates knowledge from mere memorization. Our approach involves creating a knowledge-store accessible for reference and retrieval throughout the training and inference phases.
spiration from the human learning process, especially the principle of ’learning by analogy’, and to acknowledge the wisdom in the saying, ‘The palest ink is better than the best memory’. Interestingly, humans demonstrate exceptional abilities in associative learning, harnessing profound memories to strengthen pertinent abilities, which enables them to tackle tasks with few or no prior examples. We aim to enhance prompt learning generalization by leveraging retrieval and association, inspired by observations of its limitations. Our primary viewpoint suggests that tackling these challenges can be effectively mitigated by dissociating knowledge from mere memorization through the utilization of an open-book knowledge-store derived from the training data. By referencing relevant knowledge, we can provide the model with a robust signal for striking a balance between generalization and memorization, thereby significantly mitigating the challenges mentioned above. Specifically, we propose a novel retrieval-augmented framework, called RETROPROMPT, which builds upon prompt learning (Figure 1). To decouple knowledge from pure memorization, we introduce an open-book knowledge store (K, V), composed of key-value pairs extracted from the training data, with keys representing prompt-based example embeddings and values corresponding to label words. To incorporate the retrieved knowledge into the model input, Firstly, we employ a non-parametric algorithm kNN to determine the difficulty level of instances. This is accomplished by comparing the input query with the knowledge-store and introducing a scaling factor during training to amplify the influence of challenging instance
This content is AI-processed based on open access ArXiv data.