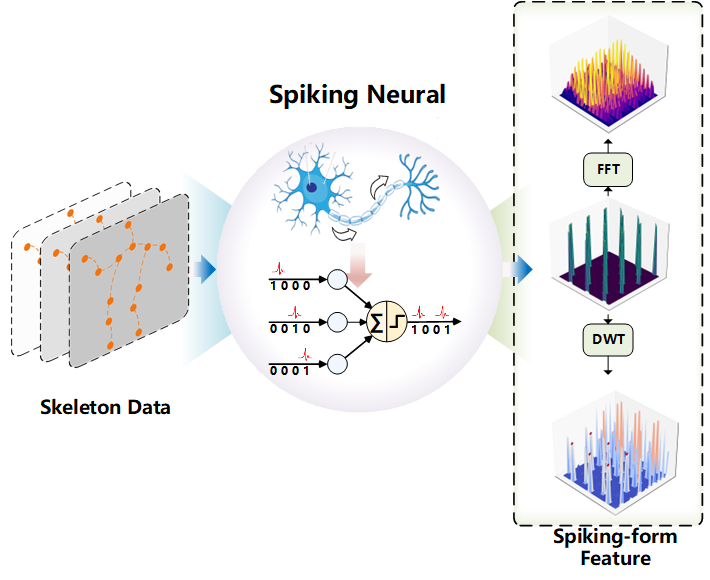
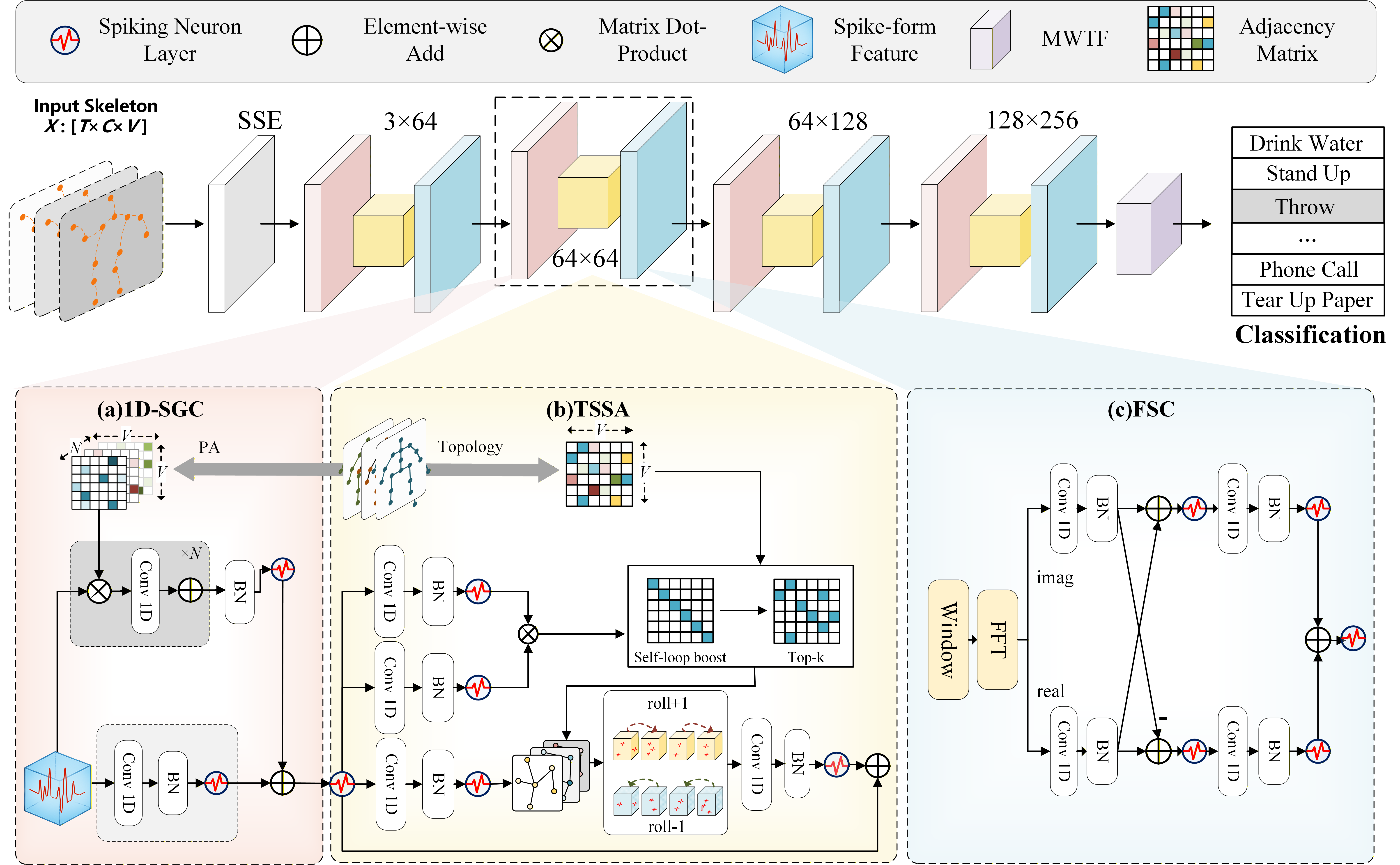
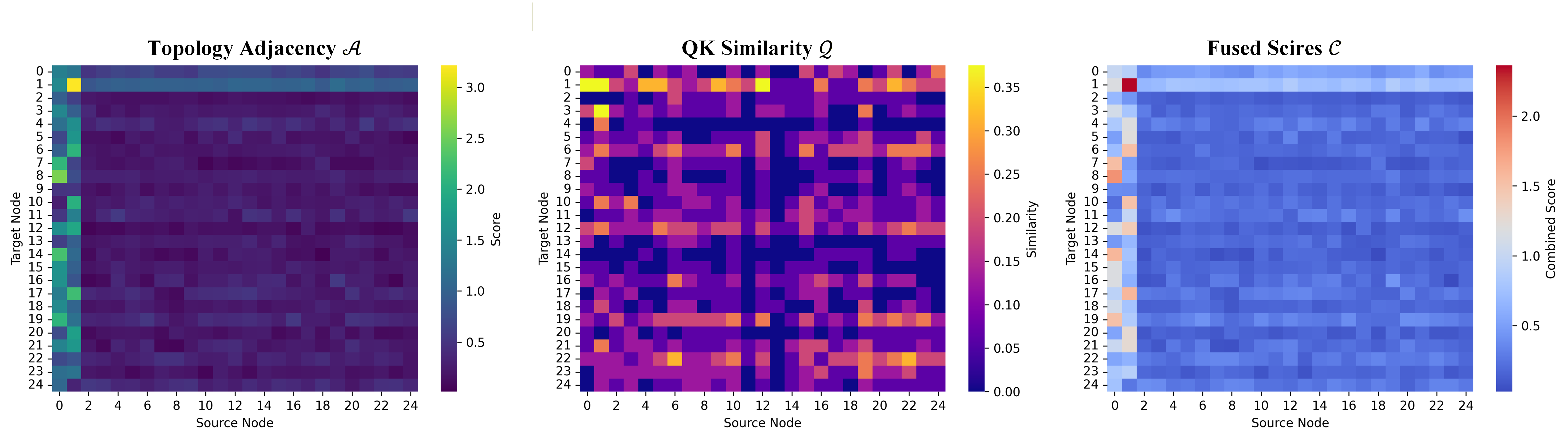
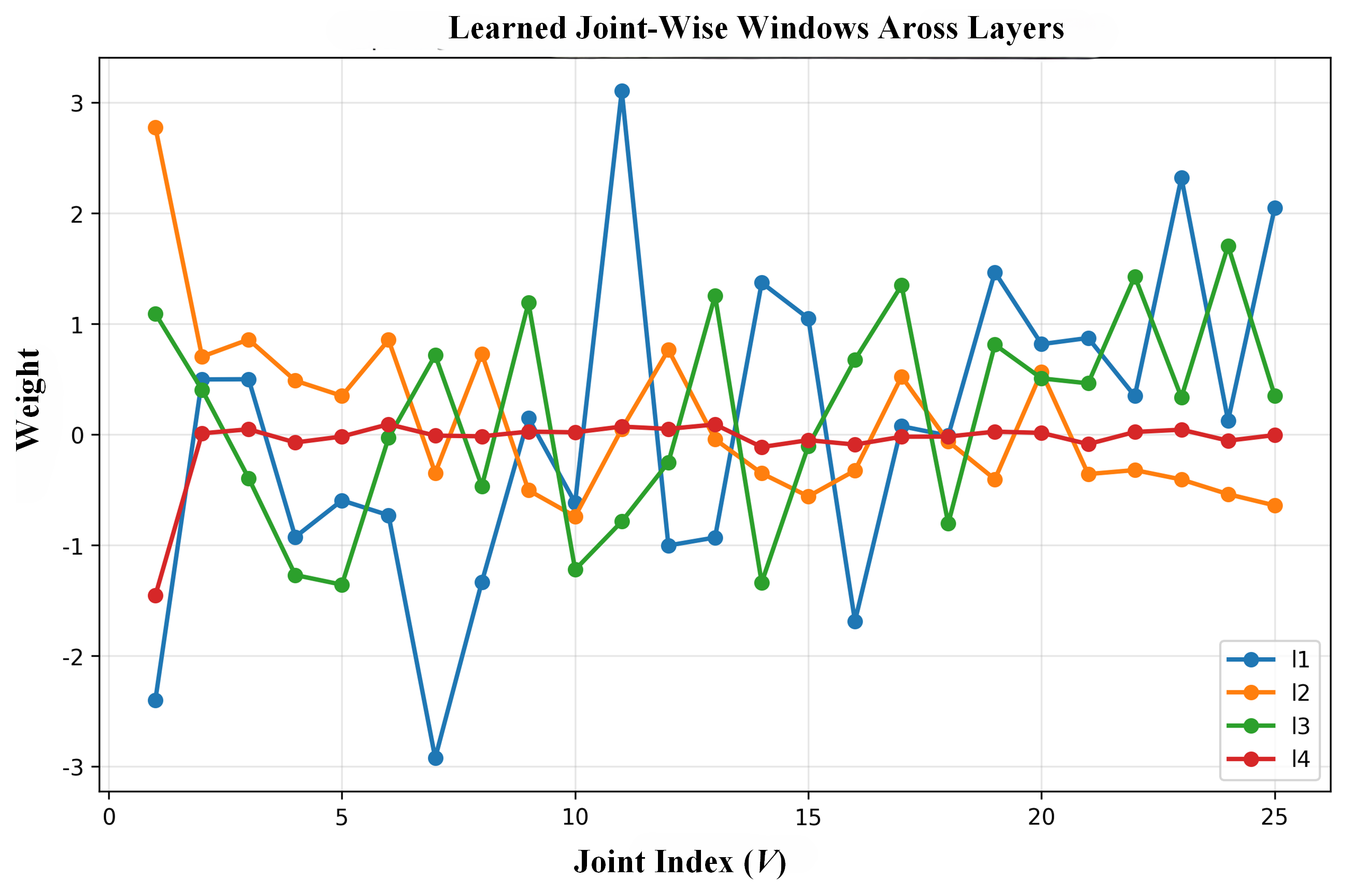
Graph Convolutional Networks (GCNs) demonstrate strong capability in modeling skeletal topology for action recognition, yet their dense floating-point computations incur high energy costs. Spiking Neural Networks (SNNs), characterized by event-driven and sparse activation, offer energy efficiency but remain limited in capturing coupled temporal-frequency and topological dependencies of human motion. To bridge this gap, this article proposes Signal-SGN++, a topology-aware spiking graph framework that integrates structural adaptivity with time-frequency spiking dynamics. The network employs a backbone composed of 1D Spiking Graph Convolution (1D-SGC) and Frequency Spiking Convolution (FSC) for joint spatiotemporal and spectral feature extraction. Within this backbone, a Topology-Shift Self-Attention (TSSA) mechanism is embedded to adaptively route attention across learned skeletal topologies, enhancing graph-level sensitivity without increasing computational complexity. Moreover, an auxiliary Multi-Scale Wavelet Transform Fusion (MWTF) branch decomposes spiking features into multi-resolution temporal-frequency representations, wherein a Topology-Aware Time-Frequency Fusion (TATF) unit incorporates structural priors to preserve topology-consistent spectral fusion. Comprehensive experiments on large-scale benchmarks validate that Signal-SGN++ achieves superior accuracy-efficiency trade-offs, outperforming existing SNN-based methods and achieving competitive results against state-of-the-art GCNs under substantially reduced energy consumption.
Human action recognition aims to classify human activities from motion patterns, and has broad applications in humancomputer interaction, healthcare, and robotics [1]. Among various data modalities, skeleton-based action recognition has attracted particular interest because it represents the human body as a set of joints (nodes) connected by bones (edges), providing a compact, viewpoint-robust description of motion [2]. This graph-like representation allows models to focus on the underlying body structure rather than appearance variations such as clothing, background, or illumination.
Various architectures have been explored for skeleton-based action recognition, including Convolutional Neural Networks (CNNs) [3], [7], Recurrent Neural Networks(RNNs) [4]- [6], and Transformers [8]. CNN-based methods are effective at local feature extraction but struggle to simultaneously capture long-range temporal dependencies and explicit joint-to-joint relationships. RNNs and LSTMs are naturally suited for sequential data, yet they often suffer from vanishing gradients and high computational cost on long sequences. Transformers excel at modeling long-range dependencies through selfattention, but when applied directly to skeleton sequences they typically ignore the inherent topological structure of the human body, thereby limiting their ability to model fine-grained joint interactions.
To explicitly encode this body structure, Graph Convolutional Networks (GCNs) have become a dominant paradigm for skeleton-based action recognition. In GCN-based methods, the human skeleton is modeled as a graph where joints are nodes and bones are edges, enabling direct reasoning over spatial dependencies and their temporal evolution [41]. ST-GCN was the first to introduce a spatial-temporal GCN framework for skeleton-based action recognition, jointly modeling joint configurations and motion patterns [9]. Subsequent works, such as 2S-AGCN [10] and CTR-GCN [14], further enhanced performance by designing adaptive graph constructions and attention mechanisms to capture dynamic joint dependencies, while Block-GCN improved efficiency by partitioning the skeleton into subgraphs for more focused modeling of local spatial patterns [22]. These advances highlight the importance of leveraging the intrinsic skeletal topology for robust and accurate action recognition.
Despite their effectiveness, GCN-based models are computationally expensive due to their reliance on dense matrix operations and floating-point computations (FLOPs), resulting in high energy consumption, which makes them less suitable for real-time applications, particularly in resource-constrained environments such as mobile and edge devices. In contrast, Spiking Neural Networks (SNNs), as third-generation neural networks, utilize binary spike-based encoding to emulate neural dynamics. Unlike traditional artificial neural networks (ANNs) that process information continuously, SNNs operate in an event-driven manner, where neurons fire only in response to events (spikes) [18]. This sparse activation leads to significantly lower energy consumption and greater computational efficiency [19], [20].
In recent years, several SNN-based models have been introduced for various visual tasks [25]. The first significant breakthrough is Spikformer [26], which replaces traditional floatingpoint operations with binary spike-based self-attention, drasti-cally reducing energy consumption. This led to further advancements with multiple variants of spiking Transformers optimizing energy efficiency [27], [28], [30], [32]. Meanwhile, SpikingGCN combined SNNs with graph convolutions, using a Bernoulli pulse encoder to convert continuous features into discrete spikes, enabling the first integration of SNNs with graph convolutions [33]. Following this, Dy-SIGN proposed a dynamic spiking graph framework that integrates information compensation and implicit differentiation to enhance efficiency [34]. More recently, MK-SGN combined multimodal fusion, self-attention, and knowledge distillation, creating an energyefficient Spiking GCN framework for skeleton-based action recognition [35].
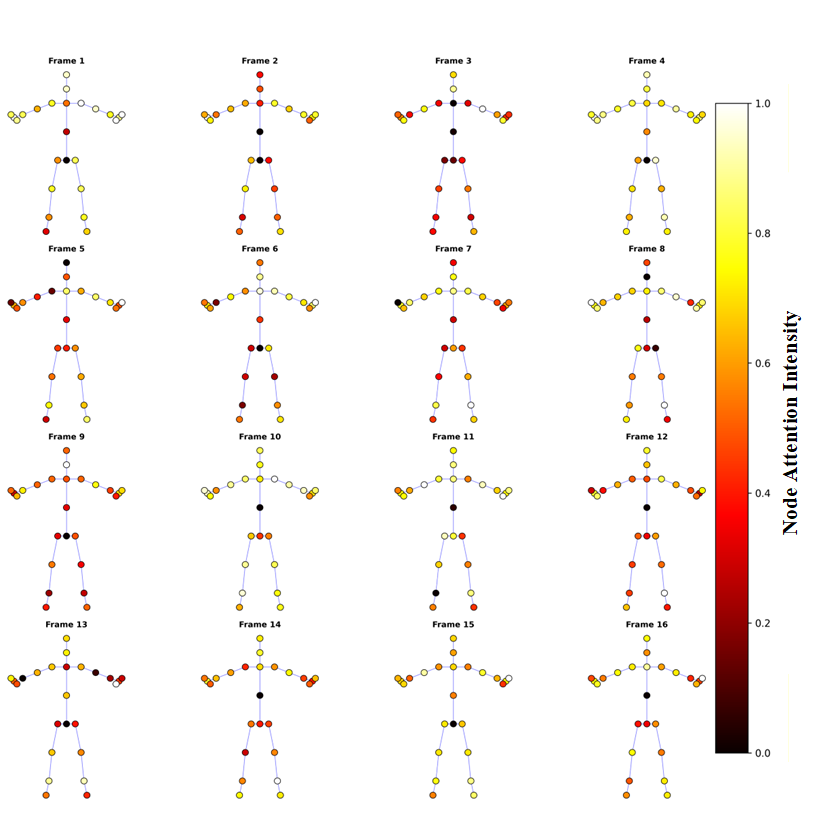
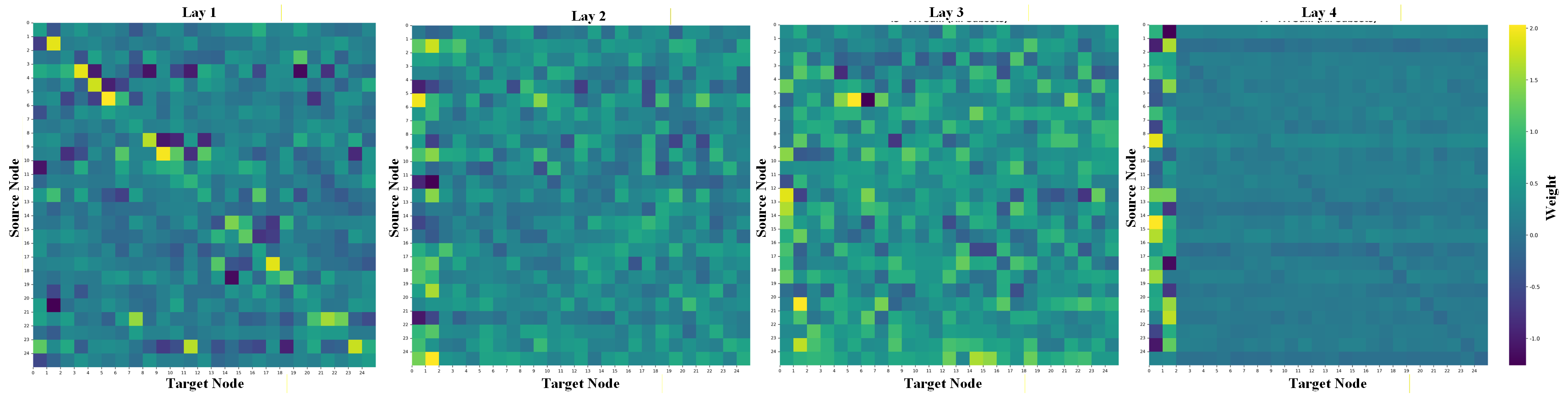
Despite these advancements, current SNN models still face significant limitations in fully capturing the dynamic topology of skeleton data. These models typically treat the entire skeleton sequence as a static image, adding a pulse step dimension, but fail to adapt to the dynamic inter-joint relationships during an action. Furthermore, while SNNs mimic neural spike activity and leverage spiking-based attention, these attention mechanisms lack the flexibility to effectively learn and adapt to the evolving joint dependencies and topological structures. Additionally, although pulse signals inherently exhibit nonstationarity and time-frequency characteristics, similar to EEG signals, current SNN models often overlook these properties [36], [37]. Consequently, this oversight results in inadequate modeling of the dynamic changes in jo
This content is AI-processed based on open access ArXiv data.