Generating long-range, geometrically consistent video presents a fundamental dilemma: while consistency demands strict adherence to 3D geometry in pixel space, state-of-the-art generative models operate most effectively in a camera-conditioned latent space. This disconnect causes current methods to struggle with occluded areas and complex camera trajectories. To bridge this gap, we propose WorldWarp, a framework that couples a 3D structural anchor with a 2D generative refiner. To establish geometric grounding, WorldWarp maintains an online 3D geometric cache built via Gaussian Splatting (3DGS). By explicitly warping historical content into novel views, this cache acts as a structural scaffold, ensuring each new frame respects prior geometry. However, static warping inevitably leaves holes and artifacts due to occlusions. We address this using a Spatio-Temporal Diffusion (ST-Diff) model designed for a "fill-and-revise" objective. Our key innovation is a spatio-temporal varying noise schedule: blank regions receive full noise to trigger generation, while warped regions receive partial noise to enable refinement. By dynamically updating the 3D cache at every step, WorldWarp maintains consistency across video chunks. Consequently, it achieves state-of-the-art fidelity by ensuring that 3D logic guides structure while diffusion logic perfects texture. Project page: \href{https://hyokong.github.io/worldwarp-page/}{https://hyokong.github.io/worldwarp-page/}.
Given only a single starting image (left) and a specified camera trajectory, our method generates a long and coherent video sequence. The core of our approach is to generate the video chunk-bychunk, where each new chunk is conditioned on forward-warped "hints" from the previous one. A novel diffusion model then generates the next chunk by correcting these hints and filling in occlusions using a spatio-temporal varying noise schedule. The high geometric consistency of our 200-frame generated sequence is demonstrated by its successful reconstruction into a high-fidelity 3D Gaussian Splatting (3DGS) [25] model (right). This highlights our model's robust understanding of 3D geometry and its capability to maintain long-term consistency.
Generating long-range, geometrically consistent video presents a fundamental dilemma: while consistency demands strict adherence to 3D geometry in pixel space, stateof-the-art generative models operate most effectively in a camera-conditioned latent space. This disconnect causes current methods to struggle with occluded areas and complex camera trajectories. To bridge this gap, we propose WorldWarp, a framework that couples a 3D structural anchor with a 2D generative refiner. To establish geometric grounding, WorldWarp maintains an online 3D geometric cache built via Gaussian Splatting (3DGS). By explicitly
Novel View Synthesis (NVS) has emerged as a cornerstone problem in computer vision and graphics, with transformative applications in virtual reality, immersive telepresence, and generative content creation. While traditional NVS methods excel at view interpolation, which generates new views within the span of existing camera poses [2,25,40], the frontier of the field lies in view extrapolation [16,32,33,37,55,67]. This far more challenging task involves generating long, continuous camera trajectories that extend significantly beyond the original scene, effectively synthesizing substantial new content and structure [37,55]. The ultimate goal is to enable interactive exploration of dynamic, 3D-consistent worlds from only a limited set of starting images.
The central challenge in generating long-range, cameraconditioned video lies in finding an effective 3D conditioning. Existing works have largely followed two main strategies. The first is camera pose encoding, which embeds abstract camera parameters as a latent condition [16,29,39,54,55,67]. This approach, however, relies heavily on the diversity of the training dataset and often fails to generalize to Out-Of-Distribution (OOD) camera poses, while also providing minimal information about the underlying 3D scene content [11,20,32,41,44,77]. The second strategy, which uses an explicit 3D spatial prior, was introduced to solve this OOD issue [11,20,32,77]. While these priors provide robust geometric grounding, they are imperfect, suffering from occlusions (blank regions) and distortions from 3D estimation errors [55,77]. This strategy typically employs standard inpainting or video generation techniques [11,20,32], which are ill-suited to simultaneously handle the severe disocclusions and the geometric distortions present in the warped priors, leading to artifacts and inconsistent results.
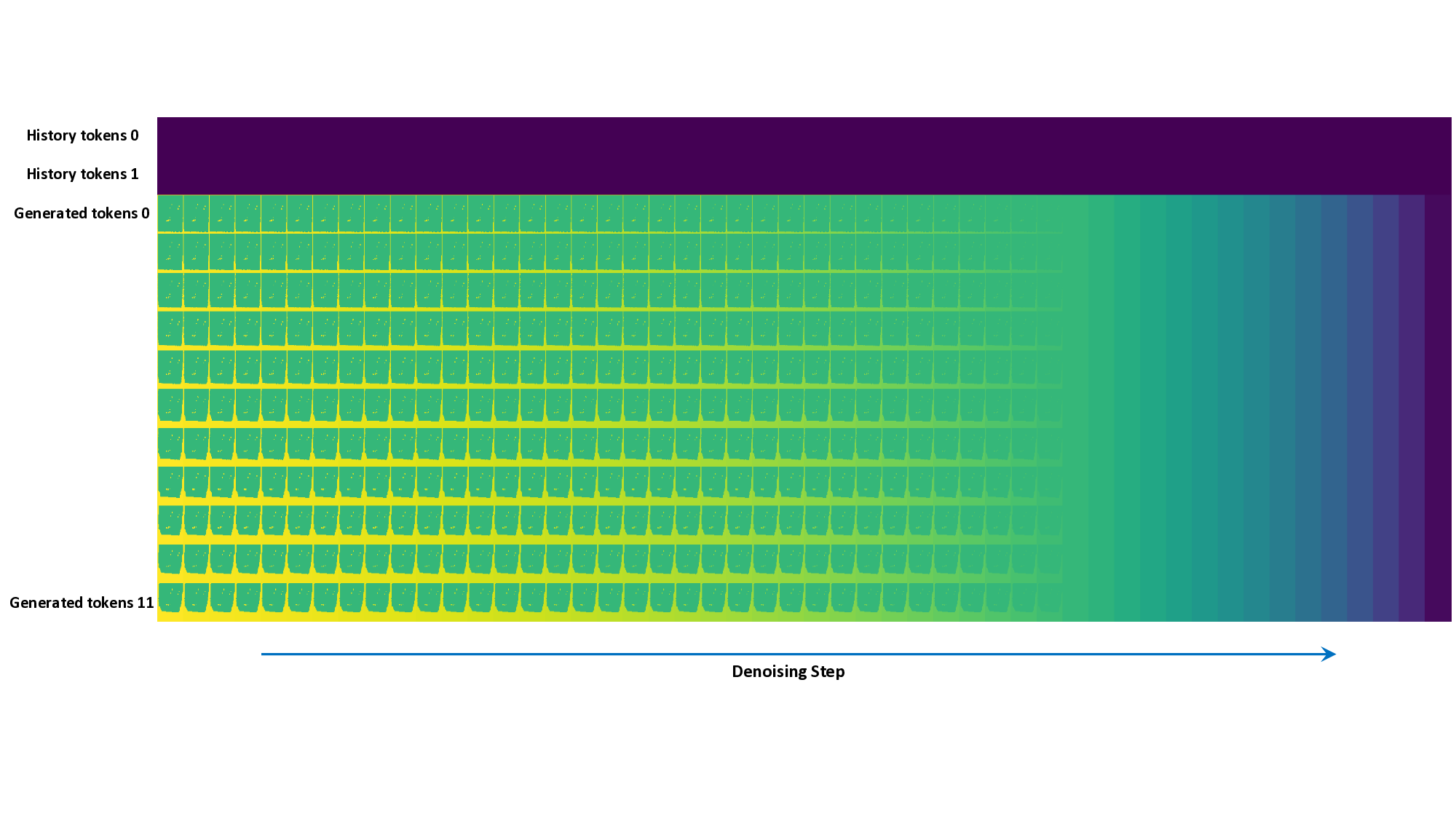
To address this critical gap, we propose WorldWarp, a novel framework that generates long-range, geometricallyconsistent novel view sequences. Our core insight is to break the strict causal chain of AR models and the static nature of explicit 3D priors. Instead, WorldWarp operates via an autoregressive inference pipeline that generates video chunkby-chunk (see Fig. 3). The key to our system is a Spatio-Temporal Diffusion (ST-Diff) model [49,60], which is trained with a powerful bidirectional, non-causal attention mechanism. This non-causal design is explicitly enabled by our core technical idea: using forward-warped images from future camera positions as a dense, explicit 2D spatial prior [9]. At each step, we build an “online 3D geometric cache” using 3DGS [25], which is optimized only on the most recent, high-fidelity generated history. This cache then renders high-quality warped priors for the next chunk, providing ST-Diff with a rich, geometrically-grounded signal that guides the generation of new content and fills occlusions.
The primary advantage of WorldWarp is its ability to avoid the irreversible error propagation that plagues prior work [55,77]. By dynamically re-estimating a short-term 3DGS cache at each step, our method continuously grounds itself in the most recent, accurate geometry, ensuring highfidelity consistency over extremely long camera paths. We demonstrate the effectiveness of our approach through extensive experiments on challenging real-world and synthetic datasets for long-sequence view extrapolation, achieving state-of-the-art performance in both geometric consistency and visual fidelity. In summary, our main contributions are: • WorldWarp, a novel framework for long-range novel view extrapolation that generates vi
This content is AI-processed based on open access ArXiv data.